computer_science
1.0.0
英語| Italiano | Español| Français| বাংলা| தமிழ்| ગુજરાતી|葡萄牙| हिंदी| తెలుగు|羅姆納| العربية |尼泊爾| 簡體中文
如果您有興趣為該項目做出貢獻,請花點時間查看貢獻貢獻。 md,以獲取有關如何開始的詳細說明。非常感謝您的貢獻!
計算機科學是對計算機和計算的研究及其理論和實際應用。計算機科學將數學,工程和邏輯的原理應用於許多問題。其中包括算法公式,軟件/硬件開發和人工智能。
計算機是一種旨在執行高速數學,邏輯或數據處理操作的設備。這是一台可編程的電子機器,可以有效地組裝,存儲,關聯和處理信息。
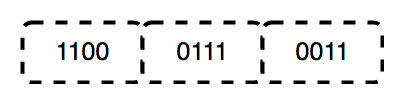
布爾邏輯是數學的一個分支,專注於真實價值觀,特別是錯誤。它使用一個二進制系統運行,其中0代表false,而1表示為true。該系統被稱為布爾代數,首先是喬治·布爾(George Boole)於1854年引入的。
| 操作員 | 姓名 | 描述 |
|---|---|---|
| 呢 | 不是 | 否定(反轉)操作數的價值。 |
| && | 和 | 如果兩個操作數都是正確的,則返回true。 |
| || | 或者 | 如果至少一個操作數為真,則返回真實。 |
| 操作員 | 姓名 | 描述 |
|---|---|---|
| () | 括號 | 允許您分組關鍵字並控制搜索條款的順序。 |
| “” | 引號 | 提供精確短語的結果。 |
| * | 星號 | 提供包含關鍵字變化的結果。 |
| ⊕ | XOR | 如果操作數不同,則返回true |
| ⊽ | 也不 | 如果所有操作數都是錯誤的,則返回為true 。 |
| ⊼ | NAND | 僅當兩個輸入的兩個值都是true時,返回false 。 |
數字電路涉及布爾信號(1和0)。它們是計算機的籌款構建塊。它們是用於創建計算機系統必不可少的處理器單元和內存單元的組件和電路。
真實表是邏輯和數字電路設計中使用的數學表。它們有助於繪製電路的功能。我們可以使用它們來幫助設計複雜的數字電路。
真實表有1列的每個輸入變量和1個最後一列,顯示了表代表的邏輯操作的所有可能結果。
有兩種類型的數字電路:組合和順序
在設計數字電路時,尤其是複雜的電路時。使用布爾代數工具來幫助設計過程很重要(例如:Karnaugh地圖)。將所有內容分解成較小的電路並檢查該較小電路所需的真實表也很重要。不要試圖立即解決整個電路,將其分解並逐漸將零件放在一起。
數字系統是用於表達數字的數學系統。一個數字系統由一組符號組成,這些符號用於表示數字和一組來操縱這些符號的規則。數字系統中使用的符號稱為數字。
二進製文件是由Gottfried Leibniz發明的基本2號系統,僅由兩個數字組成:0和1。此系統對所有二進制代碼都是基礎的,該代碼用於編碼數字數據,包括計算機處理器指令。在二進制中,數字表示狀態:0對應於“ OFF”,1對應於“ ON”。
在晶體管中,“ 0”表示沒有電流,而“ 1”表示電流在流動。這種數字的物理表示使計算機能夠有效地執行計算和操作。
二進製文件仍然是計算機的核心語言,並且由於以下幾個關鍵原因用於電子和硬件:
中央處理單元(CPU)是任何計算機中最重要的部分。 CPU發送信號以控制計算機的其他部分,幾乎就像大腦控制身體的方式一樣。 CPU是一台電子機器,可在計算機列表中使用,稱為說明。它讀取指令列表並按順序讀取每個指令(執行)。 CPU可以運行的指令列表是計算機程序。 CPU一次可以在稱為“內核”的部分上處理多個指令。具有四個內核的CPU可以一次處理四個程序。 CPU本身是由三個主要組成部分組成的。他們是:
寄存器是CPU中包含的少量高速內存。寄存器是“觸發器”的集合(用於存儲1位內存的電路)。處理器使用它們來存儲處理過程中所需的少量數據。 CPU可能有幾組被稱為“核心”的寄存器。註冊還有助於算術和邏輯操作。
算術操作是CPU對存儲在寄存器中的數值數據進行的數學計算。這些操作包括加法,減法,乘法和除法。邏輯操作是CPU對存儲在寄存器中的二進制數據進行的布爾計算。這些操作包括比較(例如測試兩個值是否相等)和邏輯操作(例如和,或,或不)。
寄存器對於執行這些操作至關重要,因為它們允許CPU快速訪問和操縱少量數據。通過將經常訪問的數據存儲在寄存器中,CPU可以避免從內存中檢索數據的較慢過程。
大量數據可以存儲在緩存中(發音為“現金”),這是一個非常快速的內存,位於與寄存器同一集成電路上。緩存用於程序運行時經常訪問的數據。甚至大量的數據可以存儲在RAM中。 RAM代表隨機訪問內存,這是一種存儲器的類型,它保存已從磁盤存儲中移動的數據和說明,直到處理器需要它為止。
緩存存儲器是一種基於芯片的計算機組件,可以使從計算機內存中檢索數據更有效。它充當臨時存儲區域,因此計算機的處理器可以輕鬆檢索數據。該臨時存儲區域(稱為緩存)比計算機的主內存源更容易獲得處理器,通常是某種形式的DRAM。
緩存內存有時稱為CPU(中央處理單元)內存,因為它通常直接集成到CPU芯片中或放置在與CPU具有單獨的總線互連的單獨芯片上。因此,處理器更容易訪問,並且能夠提高效率,因為它在物理上靠近處理器。
要靠近處理器,緩存內存需要比主內存小得多。因此,它的存儲空間較小。它也比主要內存貴,因為它是一個更複雜的芯片,可產生更高的性能。
它的尺寸和價格犧牲了,它彌補了速度。緩存存儲器的操作速度比RAM快10到100倍,只需要幾個納秒來響應CPU請求。
用於緩存內存的實際硬件的名稱是高速靜態隨機訪問存儲器(SRAM)。計算機主內存中使用的硬件的名稱是動態隨機訪問存儲器(DRAM)。
緩存內存不應與更廣泛的術語緩存相混淆。緩存是可以在硬件和軟件中都存在的臨時數據存儲。緩存內存是指允許計算機在網絡各個級別創建緩存的特定硬件組件。緩存是一種硬件或軟件,用於在計算環境中臨時存儲某些東西(通常是數據)。
RAM(隨機訪問存儲器)是一種計算機內存的形式,可以按任何順序讀取和更改,通常用於存儲工作數據和機器代碼。隨機訪問存儲器設備允許與其他直接訪問數據存儲媒體(例如硬盤,CD-RW,DVD-RW以及較舊的磁帶和鼓內的舊的磁盤和鼓的內存)相比,與其他直接訪問的數據存儲媒體相比,與其他直接訪問的數據存儲媒體相比,數據項幾乎相同的時間讀取或編寫,無論是讀取和寫入數據,而依賴於媒體的旋轉,依靠媒體的旋轉,與媒體旋轉相比,較大的時間。
在計算機科學中,指令是處理器指令集定義的處理器的單個操作。計算機程序是告訴計算機該怎麼做的說明列表。計算機所做的一切都是通過使用計算機程序來完成的。存儲在計算機內存(“內部編程”)中的程序使計算機接一個地做一件事,即使介於兩者之間也是如此。
編程語言是將字符串或視覺編程語言中的圖形程序元素轉換為各種機器代碼輸出的任何規則。編程語言是計算機編程中用於實現算法的一種計算機語言。
編程語言通常分為兩個廣泛的類別:
也有幾種不同的編程範例。編程範例是可以組織給定程序或編程語言的不同方式或樣式。每個範式都包含有關如何解決共同編程問題的某些結構,功能和意見。
編程範例不是語言或工具。您不能用範式“構建”任何東西。它們更像是許多人同意,遵循和擴展的一系列理想和準則。編程語言並不總是與特定範式聯繫在一起。有一些語言是考慮到一定的範式,並且具有比其他語言更有助於這種編程的功能(Haskell和功能性編程是一個很好的例子)。但是,還有一些“多範式”語言,您可以調整代碼以適合某個範式或其他範式(JavaScript和Python是一個很好的例子)。
在編程中,數據類型是一個分類,該分類指定變量具有哪種值類型以及可以應用於哪種類型的數學,關係或邏輯操作而不會導致錯誤。
原始數據類型是編程語言中最基本的數據類型。它們是更複雜的數據類型的基礎。原始數據類型由編程語言預定,並由保留的關鍵字命名。
非主要數據類型也稱為參考數據類型。它們是由程序員創建的,並且不是由編程語言定義的。非主要數據類型也稱為複合數據類型,因為它們由其他類型組成。
在計算機編程中,語句是一種命令性編程語言的句法單元,該語言表達了一些要執行的操作。用這種語言編寫的程序由一個或多個語句的序列形成。聲明可能具有內部組件(例如表達式)。任何編程語言中有兩種主要的語句類型,這些語句構建代碼的邏輯是必需的。
有條件陳述有兩種類型:
主要有三種類型的循環:
函數是執行特定任務的語句塊。功能接受數據,對其進行處理並返回結果或執行結果。功能主要是為了支持可重複使用的概念。寫入功能後,可以輕鬆調用它,而無需重複相同的代碼。
不同的功能語言使用不同的語法來編寫功能。
在此處閱讀有關功能的更多信息
在計算機科學中,數據結構是一種數據組織,管理和存儲格式,可實現有效的訪問和修改。更確切地說,數據結構是數據值的集合,它們之間的關係以及可以應用於數據的功能或操作。
算法是完成計算所需的一組步驟。它們是我們設備所做的工作的核心,這不是一個新概念。由於數學本身的發展,因此需要算法來幫助我們更有效地完成任務,但是今天,我們將研究一些現代計算問題,例如排序和圖形搜索,並顯示我們如何使它們更有效,以便您可以更輕鬆地找到廉價的機票或映射到Winterfell或餐廳或一家餐廳或其他東西。
算法的時間複雜性估計算法將用於某些輸入的時間。這個想法是將效率表示為參數是輸入大小的函數。通過計算時間複雜性,我們可以確定該算法是否足夠快而無需實現它。
空間複雜性是指算法/程序使用的內存空間總量,包括執行的輸入值的空間。計算算法/程序中變量佔據的空間以確定空間複雜性。
排序是按特定順序排列項目列表的過程。例如,如果您有名稱列表,則可能需要按字母順序排列它們。另外,如果您有數字列表,則可能需要將它們從最小到最大的順序放置。排序是一項常見的任務,這是我們可以以多種不同方式做的任務。
搜索是在容器內找到某個目標元素的算法。搜索算法旨在檢查元素或從存儲的任何數據結構中檢索元素。
字符串是編程中最常用,最重要的數據結構之一,該存儲庫包含一些最常用的算法,有助於更快地搜索時間改善我們的代碼。
圖形搜索是通過圖搜索以找到特定節點的過程。圖是一個數據結構,由有限的(可能是可變的)頂點,節點或點組成,以及一組無方向的圖形的無序對或有針對性圖的有序對。這些對被稱為無向圖的邊緣,弧線或線,以及用於有向圖的箭頭,有向邊,有向弧或有向線。頂點可以是圖形結構的一部分,也可以是由整數指數或參考表示的外部實體。圖是許多現實世界應用程序最有用的數據結構之一。圖用於對象之間的成對關係。例如,航空公司路線網絡是城市是頂點的圖形,而飛行路線是邊緣。圖也用於表示網絡。可以將Internet建模為計算機是頂點的圖形,並且計算機之間的鏈接是邊緣。圖形也用於LinkedIn和Facebook等社交網絡。圖表用於表示許多現實世界應用:計算機網絡,電路設計和航空安排僅命名幾個。
動態編程既是一種數學優化方法,又是計算機編程方法。理查德·貝爾曼(Richard Bellman)在1950年代開發了這種方法,並在從航空工程到經濟學的許多領域中發現了應用。在這兩種情況下,它都是指以遞歸方式將其分解為更簡單的子問題來簡化複雜的問題。儘管某些決策問題不能以這種方式分解,但跨越幾個時間點的決策通常確實會遞歸地分解。同樣,在計算機科學中,如果可以通過將問題分解為子問題,然後遞歸找到最佳解決方案來解決問題的最佳解決方案,則據說它具有最佳的子結構。動態編程是解決這些屬性問題的一種方法。將復雜的問題分解為更簡單的子問題的過程稱為“分裂和征服”。
貪婪算法是一種簡單,直觀的算法類別,可用於找到一些優化問題的最佳解決方案。它們之所以被稱為貪婪,是因為在每個步驟中,他們做出了當時似乎最好的選擇。這意味著貪婪的算法不能保證返回全球最佳解決方案,而是做出本地最佳選擇,以期找到全球最佳選擇。貪婪算法用於優化問題。如果問題具有以下屬性,則可以使用貪婪解決優化問題:在每個步驟中,我們都可以選擇目前看起來最好的選擇,並且我們可以為完整問題提供最佳的解決方案。
回溯是一種算法技術,可以通過嘗試逐步構建解決方案,一次遞增解決問題,一次刪除那些無法滿足問題的解決方案的解決方案(按時間,在這裡,將時間引用到搜索樹的任何水平)。
分支和界限是解決組合優化問題的一般技術。這是一種系統的枚舉技術,可通過使用問題的結構消除不可能是最佳的候選解決方案來減少候選解決方案的數量。
時間複雜度:它定義為預期執行特定指令集的次數,而不是所需的總時間。由於時間是一個因現象,因此時間複雜性可能會因某些外部因素而異,例如處理器速度,所使用的編譯器等。
空間複雜性:這是程序消耗的總內存空間。
兩者都計算為輸入大小(n)的函數。算法的時間複雜性以大符號表示。
算法的效率取決於這兩個參數。
時間複雜性類型:
一些常見的時間複雜性是:
o(1) :這表示恆定時間。 o(1)通常意味著算法將具有恆定的時間,無論輸入大小如何。哈希地圖是恆定時間的完美示例。
o(log n) :這表示對數時間。 o(log n)表示操作的每個實例減小。在二進制搜索樹(BST)中搜索元素是對數時間的一個很好的例子。
o(n) :這表示線性時間。 o(n)表示性能與輸入的大小成正比。簡而言之,執行這些輸入所需的輸入數量和時間將是成比例的。陣列中的線性搜索是線性時間複雜性的一個很好的例子。
o(n*n) :這表示二次時間。 o(n^2)意味著性能與所採集的輸入的平方成正比。簡而言之,執行的時間大約需要分配大小的平方英尺。嵌套環是二次時間複雜性的完美示例。
o(n log n) :這表示多項式時間複雜性。 o(n log n)表示性能是O(log n)的n倍(這是最差的複雜性)。一個很好的例子將被劃分並征服諸如合併排序之類的算法。該算法首先將o(log n)時間的集合劃分,然後征服和分類整個集合,這花費了O(n)時間 - 因此,合併排序需要O(n log n)時間。
| 演算法 | 時間複雜性 | 空間複雜性 | ||
|---|---|---|---|---|
| 最好的 | 平均的 | 最糟糕的 | 最糟糕的 | |
| 選擇排序 | ω(n^2) | θ(n^2) | o(n^2) | o(1) |
| 氣泡排序 | ω(n) | θ(n^2) | o(n^2) | o(1) |
| 插入排序 | ω(n) | θ(n^2) | o(n^2) | o(1) |
| 堆排序 | ω(n log(n)) | θ(n log(n)) | o(n log(n)) | o(1) |
| 快速排序 | ω(n log(n)) | θ(n log(n)) | o(n^2) | 在) |
| 合併排序 | ω(n log(n)) | θ(n log(n)) | o(n log(n)) | 在) |
| 水桶排序 | ω(n +k) | θ(n +k) | o(n^2) | 在) |
| radix排序 | ω(NK) | θ(nk) | o(nk) | o(n + k) |
| 計數排序 | ω(n +k) | θ(n +k) | o(n +k) | 好的) |
| 外殼排序 | ω(n log(n)) | θ(n log(n)) | o(n^2) | o(1) |
| 蒂姆排序 | ω(n) | θ(n log(n)) | o(n log(n)) | 在) |
| 樹排序 | ω(n log(n)) | θ(n log(n)) | o(n^2) | 在) |
| 立方體排序 | ω(n) | θ(n log(n)) | o(n log(n)) | 在) |
| 演算法 | 時間複雜性 | ||
|---|---|---|---|
| 最好的 | 平均的 | 最糟糕的 | |
| 線性搜索 | o(1) | 在) | 在) |
| 二進制搜索 | o(1) | o(logn) | o(logn) |
艾倫·圖靈(Alan Turing)(生於1912年6月23日,倫敦,英國。他曾在劍橋大學和普林斯頓高級研究所學習。在他的1936年開創性論文“可計算數字”中,他證明了確定數學中真相的通用算法方法,並且數學始終包含不可證明的(與未知)命題。該論文還引入了圖靈機。他認為,計算機最終將能夠與人類的思想無法區分,並提出了一個簡單的測試(請參閱圖靈測試)來評估這種能力。他關於該主題的論文被廣泛認為是人工智能研究的基礎。第二次世界大戰期間,他在密碼學上做了寶貴的工作,在打破德國為無線電通信的謎團中發揮了重要作用。戰爭結束後,他在曼徹斯特大學任教,並開始從事現在被稱為人工智能的工作。在這項開創性的工作中,圖靈被發現死在他的床上,被氰化物毒死。他的去世是因為他因同性戀行為(然後是犯罪)和12個月的激素治療而被捕。
在2009年舉行的公開競選之後,英國首相戈登·布朗(Gordon Brown)代表英國政府進行了正式的公開道歉,因為圖靈(Turing)的令人震驚的方式得到了處理。伊麗莎白二世女王在2013年授予了死後的赦免。現在,非正式地使用“艾倫·圖靈法”一詞來指代2017年英國的一項法律,該法律是追溯性赦免的男人,根據歷史法規,被宣布或定罪,該法律被歷史法規被禁止同性戀行為。
圖靈(Turing)在他的雕像和許多以他命名的東西上擁有廣泛的遺產,包括年度計算機科學創新獎。他出現在目前的英格蘭銀行50英鎊票據,該票據於2021年6月23日發布,與他的生日一致。觀眾投票的2019年BBC系列賽將他命名為20世紀最偉大的人。
軟件工程是計算機科學的分支,涉及軟件應用程序的設計,開發,測試和維護。軟件工程師應用工程原理和編程語言知識來為最終用戶構建軟件解決方案。
讓我們看一下軟件工程的各種定義:
成功的工程師知道如何使用正確的編程語言,平台和體系結構來開發從計算機遊戲到網絡控制系統的所有內容。除了構建系統外,軟件工程師還測試,改進和維護其他工程師構建的軟件。
在此角色中,您的日常任務可能包括以下內容:
軟件工程過程涉及多個階段,包括收集,設計,實施,測試和維護。通過採用紀律嚴明的軟件開發方法,軟件工程師可以創建滿足用戶需求的高質量軟件。
軟件工程的第一階段是要求收集。在此階段,軟件工程師與客戶端合作,以確定軟件的功能和非功能性要求。功能要求描述了該軟件應該做什麼,而非功能性要求描述了它應該做得如何。需求收集是一個關鍵階段,因為它為整個軟件開發過程奠定了基礎。
收集要求後,下一階段是設計。在此階段,軟件工程師為軟件的體系結構和功能創建了一個詳細的計劃。該計劃包括一個軟件設計文檔,指定軟件的結構,行為和與其他系統的交互。軟件設計文檔至關重要,因為它是實施階段的藍圖。
實施階段是軟件工程師為軟件創建實際代碼的地方。這是將設計文檔轉換為工作軟件的地方。實施階段涉及編寫代碼,對其進行編譯和測試,以確保它符合設計文檔中指定的要求。
測試是軟件工程的關鍵階段。在此階段,軟件工程師檢查以確保軟件正常運行,可靠並且易於使用。這涉及幾種類型的測試,包括單位測試,集成測試和系統測試。測試可確保該軟件按預期滿足要求和功能。
軟件工程的最後階段是維護。在此階段,軟件工程師對軟件進行更改,以糾正錯誤,添加新功能或改善其性能。維護是一個正在進行的過程,在整個軟件的一生中都將繼續進行。
數據科學通過應用計算機科學,統計數據和所考慮的域知識來從通常雜亂無章的數據中提取寶貴的見解。數據科學使用的示例包括從呼叫記錄或購買銷售記錄中的購買建議系統中得出客戶情感。
集成電路或整體電路(也稱為IC,芯片或微芯片)是半導體材料(通常是矽)上的一個小平坦零件(或“芯片”)上的一組電子電路。許多微小的MOSFET(金屬 - 氧化物 - 氧化型野外晶體管)都集成到一個小芯片中。這導致電路比由離散電子組件構建的電路小,更快且價格便宜。 IC的質量生產能力,可靠性和建築塊方法可以確保快速採用標準化IC,以代替離散的晶體管。 IC現在幾乎用於所有電子設備中,並徹底改變了電子產品的世界。現在,計算機,手機和其他家用電器是現代社會結構的不可交通的部分,這是由於現代計算機處理器和微控制器等IC的尺寸和低成本而成為可能的。
通過金屬 - 氧化物 - 矽酸鹽(MOS)半導體裝置製造的技術進步,實用了非常大的整合。自從其起源於1960年代以來,芯片的尺寸,速度和容量已經取得了巨大的進步,這是在技術進步的驅動下,越來越多的MOS晶體管適合相同尺寸的芯片 - 現代芯片在人類指甲的大小中可能具有數十億個MOS晶體管。這些進步大致遵循摩爾定律,使當今的計算機芯片具有數百萬倍的容量和數千倍,是1970年代初期計算機芯片的速度。
與離散電路相比,IC具有兩個主要優勢:成本和性能。成本很低,因為籌碼及其所有組件都是通過光刻將其作為單位印刷的,而不是一次構造一個晶體管。此外,包裝的IC所使用的材料比離散電路少得多。性能很高,因為IC的組件迅速切換,並且由於其尺寸較小和靠近而消耗的功率相對較少。 ICS的主要缺點是設計它們並製造所需的光掩膜的高成本。高初始成本意味著僅當預計高產量時,IC才在商業上可行。
現代電子組件分銷商通常會進一步將集成電路分類:
面向對象的編程是基於對象和數據概念的基本編程範式。
這是每個程序員必須遵守的標準代碼方式,以更好地可讀性和可重複使用代碼。
在此處閱讀有關這些OOP這些概念的更多信息
在計算機科學中,功能編程是一個編程範式,通過應用和組成功能來構建程序。這是一個聲明的編程範式,其中函數定義是映射值的表達式樹的樹,而不是更新程序運行狀態的命令式語句的順序。
在功能編程中,功能被視為一流的公民,這意味著它們可以綁定到名稱(包括本地標識符),作為參數傳遞並從其他功能返回,就像任何其他數據類型一樣。這允許程序以聲明性且可組合的樣式編寫,其中小功能以模塊化方式組合在一起。
功能編程有時被視為純粹功能編程的代名詞,該功能編程的子集將所有函數視為確定性的數學函數或純函數。當調用一些給定參數的純函數時,它將始終返回相同的結果,並且不能受任何可變狀態或其他副作用的影響。這與不純的過程相反,不純粹的程序(在命令式編程中常見)可能具有副作用(例如修改程序的狀態或從用戶那裡獲取輸入)。純粹功能編程的支持者聲稱,通過限制副作用,程序可以更少的錯誤,更易於調試和測試,並且更適合正式驗證程序。
功能編程起源於學術界,從lambda conculus演變,這是一種基於功能的正式計算系統。歷史上,功能性編程比當務之急的編程不那麼受歡迎,但是許多功能性語言在當今在行業和教育中都使用。
功能編程語言的一些示例是:
功能編程歷史上是從Lambda演算得出的。 Lambda演算是Alonzo Church開發的框架,用於研究功能的計算。它通常被稱為“世界上最小的編程語言”。它提供了可計算和不可計算的定義。它等同於圖靈機的計算能力,而lambda conculus可以計算的任何內容,就像圖靈機可以計算的任何內容一樣,都是可計算的。它為描述功能及其評估提供了一個理論框架。
功能編程的一些基本概念是:
純函數:這些功能具有兩個主要屬性。首先,它們總是為相同的參數產生相同的輸出,而與其他任何事物無關。其次,它們沒有副作用。即它們不會修改任何參數,本地/全局變量或輸入/輸出流。後一種屬性稱為不變性。純函數的唯一結果是它返回的值。他們是決定性的。使用功能編程完成的程序很容易調試,因為它們沒有副作用或隱藏的I/O。純函數還使得編寫並行/並發應用程序更容易。當用這種樣式編寫代碼時,智能編譯器可以做很多事情 - 它可以並行化指令,等待評估結果直到需要並記住結果,因為結果永遠不會改變,只要輸入不變。這是Python中純函數的簡單示例:
def sum ( x , y ): # sum is a function taking x and y as arguments
return x + y # returns x + y without changing the value遞歸:純粹的功能編程語言中沒有“ for”或“”循環。迭代是通過遞歸實施的。遞歸功能反復稱自己為止,直到達到基本案例為止。這是C:中的遞歸功能的一個簡單示例:
int fib ( n ) {
if ( n <= 1 )
return 1 ;
else
return ( fib ( n - 1 ) + fib ( n - 2 ));
}參考透明度:在功能程序中,曾經定義的變量不會在整個程序中更改其價值。功能程序沒有分配語句。如果我們必須存儲一些值,我們將定義一個新變量。這消除了任何副作用的機會,因為在執行的任何點都可以用其實際值替換任何變量。任何變量的狀態在任何瞬間都是恆定的。例子:
x = x + 1 # this changed the value assigned to the variable x
# Therefore, the expression is NOT referentially transparent功能是一流的,可以是更高階的:將一流的功能視為一流的變量。一類變量可以作為參數傳遞給函數,可以從函數返回或存儲在數據結構中。
可以使用稱為FunCall的LISP表單來定義功能應用程序的組合,該表格將其作為參數和一系列參數,並將其應用於這些參數:
( defun filter (list-of-elements test)
( cond (( null list-of-elements) nil )
(( funcall test ( car list-of-elements))
( cons ( car list-of-elements)
(filter ( cdr list-of-elements)
test)))
( t (filter ( cdr list-of-elements)
test))))該功能過濾器將測試應用於列表的第一個元素。如果測試返回非nil,則將元素置於應用於列表CDR的過濾器的結果上;否則,它只是返回過濾後的CDR。該功能可以與傳遞的不同謂詞一起使用,以執行各種過濾任務:
> (filter ' ( 1 3 -9 5 -2 -7 6 ) #' plusp ) ; filter out all negative numbers output: (1 3 5 6)
> (filter ' ( 1 2 3 4 5 6 7 8 9 ) #' evenp ) ; filter out all odd numbers輸出:(2 4 6 8)
等等。
變量是不變的:在功能編程中,我們無法在變量初始化後修改。我們可以創建新的變量 - 但是我們無法修改現有變量,這確實有助於在整個程序的整個運行時保持狀態。一旦我們創建一個變量並設置了其值,我們就可以完全信心知道該變量的價值將永遠不會改變。
操作系統(或簡稱OS)充當計算機用戶和計算機硬件之間的中介。操作系統的目的是提供一個環境,在該環境中,用戶可以方便有效地執行程序。操作系統是管理計算機硬件的軟件。硬件必須提供適當的機制,以確保計算機系統的正確操作,並防止用戶程序干擾系統的正確操作。一個更常見的定義是,操作系統是在計算機上始終運行的一個程序(通常稱為內核),而其他所有程序都是應用程序程序。
可以從兩個角度查看操作系統:資源管理器和擴展機器。在資源管理器視圖中,操作系統的工作是有效地管理系統的不同部分。在擴展的機器視圖中,系統的作業是為用戶提供比實際機器更方便使用的抽象。這些包括過程,地址空間和文件。操作系統的歷史悠久,從他們更換操作員到現代多編程系統。亮點包括早期批處理系統,多編程系統和個人計算機系統。由於操作系統與硬件緊密相互作用,因此對計算機硬件的某些知識對於理解它們很有用。計算機是由處理器,記憶和I/O設備建立的。這些零件是通過公共汽車連接的。構建所有操作系統的基本概念是過程,內存管理,I/O管理,文件系統和安全性。任何操作系統的核心是它可以處理的系統調用集。這些證明了操作系統的作用。
操作系統管理複雜系統的所有部分。現代計算機由處理器,記憶,計時器,磁盤,鼠標,網絡界面,打印機以及各種其他設備組成。在自下而上的視圖中,操作系統的作業是在需要它們的各種程序中提供處理器,記憶和I/O設備的有序和控制的分配。現代操作系統允許多個程序在內存中同時運行。想像一下,如果在某些計算機上運行的三個程序都試圖在同一打印機上同時打印其輸出,會發生什麼。結果將是混亂。操作系統可以通過緩衝磁盤上的打印機的所有輸出,從而為潛在的混亂帶來訂單。一個程序完成後,操作系統可以從已為打印機存儲的磁盤文件中復制其輸出,同時,另一個程序可以繼續生成更多的輸出,卻忽略了輸出不去打印機的事實(尚未)。當計算機(或網絡)具有多個用戶時,需要更多地管理和保護內存,I/O設備以及其他資源,因為用戶可能會互相干擾。此外,用戶通常不僅需要共享硬件,還需要共享信息(文件,數據庫等)。簡而言之,操作系統的這種觀點認為,其主要任務是跟踪哪些程序正在使用哪些資源來授予資源請求,說明使用情況並調解來自不同程序和用戶的矛盾請求。
機器語言級別的大多數計算機的體系結構都是原始的,而且編程尷尬,尤其是對於輸入/輸出。為了使這一點更具體,請考慮大多數計算機上使用的現代SATA(串行ATA)硬盤。程序員必須知道使用磁盤。從那時起,該界面已進行了多次修訂,並且比2007年更複雜。沒有理智的程序員願意在硬件級別處理此磁盤。取而代之的是,一塊稱為磁盤驅動程序的軟件處理硬件,並提供了一個接口來讀寫磁盤塊,而無需介紹詳細信息。操作系統包含許多用於控制I/O設備的驅動程序。但是,對於大多數應用來說,即使這個水平也太低了。因此,所有操作系統都為使用磁盤:文件提供了另一層抽象。使用此抽象,程序可以創建,編寫和讀取文件,而無需處理硬件如何工作的混亂細節。該抽像是管理所有這些複雜性的關鍵。好的抽象將幾乎不可能的任務變成了兩個易於管理的任務。第一個是定義和實施抽象。第二個是使用這些抽象來解決手頭的問題。
第一代(1945 - 55年) :在巴巴奇(Babbage)災難性的努力之前,直到第二次世界大戰時代,建造數字計算機幾乎沒有取得進展。在愛荷華州立大學,約翰·阿塔納索夫(John Atanasoff)教授和他的研究生剋利福德·貝里(Clifford Berry)創建了今天被認為是第一台運營數字計算機的東西。柏林的Konrad Zuse大約在同一時間使用機電繼電器構建了Z3計算機。我是由哈佛大學的霍華德·艾肯(Howard Aiken),英格蘭布萊奇利公園(Bletchley Park)的科學家團隊以及威廉·莫赫利(William Mauchley)和他的博士生J. Presper Eckert創建的。
第二代(1955-65) :晶體管在1950年代中期的發明徹底改變了這種情況。計算機變得足夠可靠,可以將它們製造並出售給向客戶付款,假設他們將繼續工作足夠長的時間以進行一些有意義的工作。這些機器現在已知,大型機被鎖定在巨大的,尤其是空調的計算機室中,並擁有合格的運營商團隊來管理它們。只有龐大的企業,重要的政府實體或機構才能負擔數百萬美元的價格。
第三代(1965-80) :與第二代計算機相比,該計算機是由單個晶體管構造的,IBM 360是第一個使用(小規模)IC(集成電路)的主要計算機線。結果,它提供了很大的價格/績效優勢。這是一個即時的打擊,所有其他大型製造商都迅速接受了可互操作計算機系列的概念。所有軟件,包括OS/360操作系統,都應該與原始設計中的所有型號兼容。它必須在龐大的系統上運行,該系統經常替換7094秒以進行重型計算和天氣預報,以及小型系統,這些系統經常僅替換1401秒以將卡轉移到膠帶上。這兩個具有很少有外圍設備的系統的系統都需要很好地與其進行功能。它必須在專業和學術環境中發揮作用。最重要的是,它必須對這些應用程序中的每一個有效。
第四代(1980年至今) :個人計算機時代始於創建LSI(大規模集成)電路,處理器,在矽的正方形厘米上具有數千個晶體管。儘管最初稱為微型計算機的個人計算機在PDP-11級的微型計算機的架構中並沒有發生顯著變化,但價格確實有很大差異。
第五代(1990年) :自1940年代漫畫偵探迪克·特雷西(Dick Tracy)以來,人們就渴望成為一種便攜式通信小工具,開始與他的“雙向廣播腕錶”交談。 1946年,一部真正的手機首次亮相,重約40公斤。 1970年代首次亮相的第一部真正的便攜式手機,非常輕巧,大約一公斤。它被開玩笑地稱為“磚”。很快,每個人都大聲疾呼。
大型機操作系統:在高端是大型機的操作系統,那些仍在主要公司數據中心中發現的室大型計算機。這些計算機在I/O容量方面與個人計算機不同。具有1000個磁盤和數百萬千兆位數據的大型機並不罕見。具有這些規格的個人計算機將羨慕其朋友。大型機也使某種捲土重來的速度作為高端網絡服務器,用於大規模電子商務網站的服務器以及用於企業對企業交易的服務器。大型機的操作系統旨在一次處理許多工作,其中大多數需要大量的I/O。他們通常提供三種服務:批處理,交易處理和分時度假
服務器操作系統:一個級別是服務器操作系統。他們在服務器上運行,這些服務器要么是非常大的個人計算機,工作站,甚至是大型機。他們一次通過網絡為多個用戶提供服務,並允許用戶共享硬件和軟件資源。服務器可以提供打印服務,文件服務或Web服務。互聯網提供商運行許多服務器機器來支持其客戶,網站使用服務器存儲網頁並處理傳入請求。典型的服務器操作系統是Solaris,FreeBSD,Linux和Windows Server 201X。
多處理器OS :獲得大聯盟計算能力的越來越常見的方法是將多個CPU連接到單個系統中。根據它們的確切連接方式以及共享的內容,這些系統被稱為並行計算機,多計算機或多處理器。他們需要特殊的操作系統,但通常這些是服務器操作系統的變化,具有通信,連接和一致性的特殊功能。
個人計算機操作系統:下一個類別是個人計算機操作系統。現代所有人都支持多編程,通常在啟動時啟動了數十個程序。他們的工作是為單個用戶提供良好的支持。它們被廣泛用於文字處理,電子表格,遊戲和互聯網訪問。常見的示例是Linux,FreeBSD,Windows 7,Windows 8和Apple的OSX。個人計算機操作系統眾所周知,可能幾乎不需要引入。許多人甚至都不知道存在其他種類。
嵌入式操作系統:嵌入式系統運行在控制設備的計算機上,這些設備通常不被視為計算機,並且不接受用戶安裝的軟件。典型的例子是微波爐,電視機,汽車,DVD記錄器,傳統手機和MP3播放器。將嵌入式系統與掌上電腦區分開來的主要屬性是確定沒有不受信任的軟件會在其上運行。您不能將新應用程序下載到微波爐烤箱中 - 所有軟件都在ROM中。這意味著在應用程序之間不需要保護,從而簡化了設計。嵌入式Linux,QNX和VXWorks之類的系統在該域中很受歡迎。
智能卡OS :最小的操作系統在帶有CPU芯片的信用卡大小的智能卡設備上運行。它們具有非常嚴重的處理能力和記憶約束。有些是由插入讀者中的聯繫人提供動力的,但是非接觸式智能卡具有電感能力,極大地限制了他們可以做的事情。有些人只能處理單個功能,例如電子付款,而另一些可以處理多個功能。這些通常是專有系統。一些智能卡面向爪哇。這意味著智能卡上的ROM為Java Virtual Machine(JVM)提供了解釋器。 Java小程序(小程序)將下載到卡上,並由JVM解釋器解釋。這些卡中的一些可以同時處理多個Java小程序,從而導致多編程以及需要安排它們。當同時出現兩個或多個小程序時,資源管理和保護也成為一個問題。這些問題必須由卡上存在的(通常非常原始的)操作系統處理。
內存一詞是指允許短期數據訪問的計算機中的組件。您可以將此組件識別為DRAM或動態隨機訪問存儲器。您的計算機通過訪問存儲在其短期內存中的數據來執行許多操作。此類操作的一些示例包括編輯文檔,加載應用程序和瀏覽互聯網。系統的速度和性能取決於計算機上安裝的內存量。
如果您有桌子和檔案櫃,則桌子代表計算機的內存。您需要立即使用的物品放在辦公桌上,以方便訪問。但是,由於尺寸的限制,不能將太多存儲在桌子上。
儘管內存是指短期數據的位置,但存儲是計算機中的組件,可長期存儲和訪問數據。通常,存儲以固態驅動器或硬盤驅動器的形式出現。儲物可容納您的應用程序,操作系統和文件。計算機需要從存儲系統中讀取和寫入信息,因此存儲速度確定您的系統可以啟動,加載和訪問您保存的內容的速度。
當桌子代表計算機的內存時,文件櫃代表您的計算機的存儲空間。它擁有需要保存和存儲的項目,但不一定需要立即訪問。檔案櫃的大小意味著它可以容納許多東西。
內存和存儲之間的一個重要區別是,當計算機關閉計算機時,內存會清除。另一方面,無論您多久關閉計算機,存儲仍然保持完整。因此,在辦公桌和歸檔櫃類比中,離開辦公室時留下的任何文件都會被扔掉。您的檔案櫃中的所有內容都將保留下來。
計算機系統的核心是內存,該記憶是程序運行和存儲數據的空間。但是,當您正在運行的程序和您使用的數據超過計算機內存的物理容量時會發生什麼?這是虛擬內存介入的地方,充當計算機內存的明智擴展並增強其功能。
虛擬內存的定義和目的:
虛擬內存是操作系統採用的一種內存管理技術來克服物理內存的局限性(RAM)。它對軟件應用程序產生了一種幻想,它們可以訪問比計算機上的物理安裝的內存量。從本質上講,它使程序能夠利用計算機物理RAM範圍之外的內存空間。
虛擬內存的主要目的是啟用有效的多任務處理和較大程序的執行,同時保持系統的響應能力。它通過在物理RAM和輔助存儲設備(例如硬盤驅動器或SSD)之間創建無縫的交互來實現這一目標。
虛擬內存如何擴展可用的物理內存:
將虛擬內存視為連接計算機RAM及其二級存儲(磁盤驅動器)的橋樑。運行程序時,部分將加載到更快的物理內存(RAM)中。但是,並非可以立即使用該程序的所有部分。
虛擬內存通過移動沒有從RAM到輔助存儲的程序的部分移動程序來利用這種情況,從而在RAM中為積極使用的零件創建了更多空間。此過程對用戶和運行程序透明。再次需要移動的零件時,它們會換回RAM,而其他較少的活性零件可能會移至輔助存儲空間。
該數據進出物理內存的動態交換由操作系統管理。即使程序大於可用的RAM,它也可以運行,因為操作系統智能地決定了RAM中需要的數據以獲得最佳性能。
總而言之,虛擬內存充當虛擬化層,該層通過暫時傳輸程序的部分以及RAM和輔助存儲之間的數據來擴展可用的物理內存。此過程可確保計算機可以同時處理較大的任務和眾多程序,同時保持有效的性能和響應能力。
在計算中,文件系統或文件系統(通常縮寫為FS)是操作系統用於控制數據如何存儲和檢索的方法和數據結構。沒有文件系統,放置在存儲介質中的數據將是一個大量數據,無法分辨出一個數據停止的位置,下一步開始的數據或在檢索它的時間時所在的任何數據位置。通過將數據分為零件並給每個零件一個名稱,可以很容易地隔離和識別數據。從命名基於紙張的數據管理系統的名稱中獲取,每個數據組稱為“文件”。用於管理數據組及其名稱組的結構和邏輯規則稱為“文件系統”。
有多種文件系統,每個文件系統都具有獨特的結構和邏輯,速度,靈活性,安全性,大小等等。一些文件系統被設計用於特定應用程序。例如,ISO 9660文件系統專為光盤設計。
文件系統可以使用各種媒體在許多類型的存儲設備上使用。截至2019年,硬盤驅動器一直是關鍵的存儲設備,並預計在可預見的將來仍然如此。使用的其他介質包括SSD,磁性磁帶和光盤。在某些情況下,例如使用TMPF,計算機的主內存(隨機訪問存儲器,RAM)會創建一個臨時文件系統,以供短期使用。
某些文件系統用於本地數據存儲設備;其他人則通過網絡協議(例如NFS,SMB或9p客戶端)提供文件訪問。某些文件系統是“虛擬”,這意味著根據請求(例如procfs and sysfs)計算所提供的“文件”(稱為虛擬文件),或者只是映射到用作備份存儲的其他文件系統中。文件系統管理有關這些文件的文件內容和元數據的訪問。它負責安排存儲空間;關於物理存儲介質的可靠性,效率和調整是重要的設計考慮因素。
文件系統存儲並組織數據,可以將其視為存儲設備中包含的所有數據的一種索引。這些設備可以包括硬盤驅動器,光學驅動器和閃存驅動器。
文件系統指定命名文件的約定,包括名稱中的最大字符數,可以使用哪些字符,在某些系統中,文件名稱後綴可以使用多長時間。在許多文件系統中,文件名不是對病例敏感的。
與文件本身一起,文件系統包含元數據目錄中的文件的大小及其屬性,位置和層次結構之類的信息。元數據還可以識別驅動器上可用存儲的免費塊以及可用的空間。
文件系統還包括一種格式,以通過目錄結構指定文件的路徑。將文件放在目錄中 - 或Windows OS中的文件夾中 - 或在樹結構中所需的位置進行子目錄。 PC和移動OS具有文件系統,其中將文件放置在層次樹結構中。
在存儲介質上創建文件和目錄之前,應將分區放置到位。分區是操作系統單獨管理的硬盤或其他存儲空間的區域。一個文件系統包含在主要分區中,有些OS允許在一個磁盤上進行多個分區。在這種情況下,如果一個文件系統損壞,則不同分區中的數據將是安全的。
有幾種類型的文件系統,所有這些類型都具有不同的邏輯結構和屬性,例如速度和大小。文件系統的類型可能因OS和該操作系統的需求而有所不同。 Microsoft Windows,Mac OS X和Linux是三個最常見的PC操作系統。移動OS包括Apple iOS和Google Android。
主要文件系統包括以下內容:
文件分配表(FAT)由Microsoft Windows OS支持。脂肪被認為是簡單可靠的,並在傳統文件系統之後進行建模。 Fat是在1977年設計的軟盤,但後來改編成硬盤。雖然有效且與大多數當前OS兼容,但脂肪不能匹配更現代的文件系統的性能和可擴展性。
全局文件系統(GFS)是Linux OS的文件系統,它是共享磁盤文件系統。 GFS可直接訪問共享塊存儲,可用作本地文件系統。
GFS2是一個更新版本,其原始GF中未包含的功能,例如更新的元數據系統。根據GNU通用公共許可條款,GFS和GFS2文件系統都可以作為免費軟件提供。
層次文件系統(HFS)是用於與MAC操作系統一起使用的。 HFS也可以稱為Mac OS標準,由Mac OS擴展為繼承。 HF最初針對軟盤和硬盤引入,更換了原始的Macintosh文件系統。它也可以在CD-ROM上使用。
NT文件系統(也稱為新技術文件系統(NTFS))是Windows NT 3.1 OS的Windows產品的默認文件系統。 Improvements from the previous FAT file system include better metadata support, performance, and use of disk space. NTFS is also supported in the Linux OS through a free, open-source NTFS driver. Mac OSes have read-only support for NTFS.
Universal Disk Format (UDF) is a vendor-neutral file system for optical media and DVDs. UDF replaces the ISO 9660 file system and is the official file system for DVD video and audio, as chosen by the DVD Forum.
Cloud computing is a type of Internet-based computing that provides shared computer processing resources and data to computers and other devices on demand. It also allows authorized users and systems to access applications and data from any location with an internet connection.
It is a model for enabling ubiquitous, convenient, on-demand network access to a shared pool of configurable computing resources (eg, networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction.
Cloud computing is a big shift from how businesses think about IT resources. Here are seven common reasons organizations are turning to cloud computing services:
Cloud computing eliminates the capital expense of buying hardware and software and setting up and running on-site data centers—the racks of servers, the round-the-clock electricity for power and cooling, and the IT experts for managing the infrastructure. It adds up fast.
Most cloud computing services are provided self-service and on demand, so even vast amounts of computing resources can be provisioned in minutes, typically with just a few mouse clicks, giving businesses a lot of flexibility and taking the pressure off capacity planning.
The benefits of cloud computing services include the ability to scale elastically. In cloud speak, that means delivering the right amount of IT resources—for example, more or less computing power, storage, and bandwidth—right when it is needed and from the right geographic location.
On-site data centers typically require a lot of "racking and stacking"—hardware setup, software patching, and other time-consuming IT management chores. Cloud computing removes the need for many of these tasks, so IT teams can spend time on achieving more important business goals.
The biggest cloud computing services run on a worldwide network of secure data centers, which are regularly upgraded to the latest generation of fast and efficient computing hardware. This offers several benefits over a single corporate data center, including reduced network latency for applications and greater economies of scale.
Cloud computing makes data backup, disaster recovery, and business continuity easier and less expensive because data can be mirrored at multiple redundant sites on the cloud provider's network.
Many cloud providers offer a broad set of policies, technologies, and controls that strengthen your security posture overall, helping protect your data, apps, and infrastructure from potential threats.
Machine learning is the practice of teaching a computer to learn. The concept uses pattern recognition, as well as other forms of predictive algorithms, to make judgments on incoming data. This field is closely related to artificial intelligence and computational statistics.
In this, machine learning models are trained with labelled data sets, which allow the models to learn and grow more accurately over time. For example, an algorithm would be trained with pictures of dogs and other things, all labelled by humans, and the machine would learn ways to identify pictures of dogs on its own. Supervised machine learning is the most common type used today.
Practical applications of Supervised Learning –
In Unsupervised machine learning, a program looks for patterns in unlabeled data. Unsupervised machine learning can find patterns or trends that people aren't explicitly looking for. For example, an unsupervised machine learning program could look through online sales data and identify different types of clients making purchases.
Practical applications of unsupervised Learning
The disadvantage of supervised learning is that it requires hand-labelling by ML specialists or data scientists and requires a high cost to process. Unsupervised learning also has a limited spectrum for its applications. To overcome these drawbacks of supervised learning and unsupervised learning algorithms, the concept of Semi-supervised learning is introduced. Typically, this combination contains a very small amount of labelled data and a large amount of unlabelled data. The basic procedure involved is that first, the programmer will cluster similar data using an unsupervised learning algorithm and then use the existing labelled data to label the rest of the unlabelled data.
Practical applications of Semi-Supervised Learning –
This trains machines through trial and error to take the best action by establishing a reward system. Reinforcement learning can train models to play games or train autonomous vehicles to drive by telling the machine when it made the right decisions, which helps it learn over time what actions it should take.
Practical applications of Reinforcement Learning -
Natural language processing is a field of machine learning in which machines learn to understand natural language as spoken and written by humans instead of the data and numbers normally used to program computers. This allows machines to recognize the language, understand it, and respond to it, as well as create new text and translate between languages. Natural language processing enables familiar technology like chatbots and digital assistants like Siri or Alexa.
Practical applications of NLP:
Neural networks are a commonly used, specific class of machine learning algorithms. Artificial neural networks are modelled on the human brain, in which thousands or millions of processing nodes are interconnected and organized into layers.
In an artificial neural network, cells, or nodes, are connected, with each cell processing inputs and producing an output that is sent to other neurons. Labeled data moves through the nodes or cells, with each cell performing a different function. In a neural network trained to identify whether a picture contains a cat or not, the different nodes would assess the information and arrive at an output that indicates whether a picture features a cat.
Practical applications of Neural Networks:
Deep learning networks are advanced neural networks with multiple layers. These layered networks can process vast amounts of data and adjust the "weights" of each connection within the network. For example, in an image recognition system, certain layers of the neural network might detect individual facial features like eyes, nose, or mouth. Another layer would then analyze whether these features are arranged in a way that identifies a face.
Practical applications of Deep Learning:
Web Technology refers to the various tools and techniques that are utilized in the process of communication between different types of devices over the Internet. A web browser is used to access web pages. Web browsers can be defined as programs that display text, data, pictures, animation, and video on the Internet. Hyperlinked resources on the World Wide Web can be accessed using software interfaces provided by Web browsers.
The part of a website where the user interacts directly is termed the front end. It is also referred to as the 'client side' of the application.
The backend is the server side of a website. It is part of the website that users cannot see and interact with. It is the portion of software that does not come in direct contact with the users. It is used to store and arrange data.
A computer network is a set of computers sharing resources located on or provided by network nodes. Computers use common communication protocols over digital interconnections to communicate with each other. These interconnections are made up of telecommunication network technologies based on physically wired, optical, and wireless radio-frequency methods that may be arranged in a variety of network topologies.
The nodes of a computer network can include personal computers, servers, networking hardware, or other specialized or general-purpose hosts. They are identified by network addresses and may have hostnames. Hostnames serve as memorable labels for the nodes, rarely changed after the initial assignment. Network addresses serve for locating and identifying the nodes by communication protocols such as the Internet Protocol.
Computer networks may be classified by many criteria, including the transmission medium used to carry signals, bandwidth, communications protocols to organize network traffic, the network size, the topology, traffic control mechanism, and organizational intent.
There are two primary types of computer networking:
OSI stands for Open Systems Interconnection . It was developed by ISO – ' International Organization for Standardization 'in the year 1984. It is a 7-layer architecture with each layer having specific functionality to perform. All these seven layers work collaboratively to transmit the data from one person to another across the globe.
The lowest layer of the OSI reference model is the physical layer. It is responsible for the actual physical connection between the devices. The physical layer contains information in the form of bits. It is responsible for transmitting individual bits from one node to the next. When receiving data, this layer will get the signal received and convert it into 0s and 1s and send them to the Data Link layer, which will put the frame back together.
The functions of the physical layer are as follows:
The data link layer is responsible for the node-to-node delivery of the message. The main function of this layer is to make sure data transfer is error-free from one node to another over the physical layer. When a packet arrives in a network, it is the responsibility of the DLL to transmit it to the host using its MAC address.
The Data Link Layer is divided into two sublayers:
The packet received from the Network layer is further divided into frames depending on the frame size of the NIC(Network Interface Card). DLL also encapsulates the Sender and Receiver's MAC address in the header.
The Receiver's MAC address is obtained by placing an ARP(Address Resolution Protocol) request onto the wire asking, “Who has that IP address?” and the destination host will reply with its MAC address.
The functions of the Data Link layer are :
The network layer works for the transmission of data from one host to the other located in different networks. It also takes care of packet routing, ie, the selection of the shortest path to transmit the packet from the number of routes available. The sender & receiver's IP addresses are placed in the header by the network layer.
The functions of the Network layer are :
The Internet is a global system of interconnected computer networks that use the standard Internet protocol suite (TCP/IP) to serve billions of users worldwide. It is a network of networks that consists of millions of private, public, academic, business, and government networks of local to global scope that is linked by a broad array of electronic, wireless, and optical networking technologies. The Internet carries an extensive range of information resources and services, such as the interlinked hypertext documents and applications of the World Wide Web (WWW) and the infrastructure to support email.
The World Wide Web (WWW) is an information space where documents and other web resources are identified by Uniform Resource Locators (URLs), interlinked by hypertext links, and accessible via the Internet. English scientist Tim Berners-Lee invented the World Wide Web in 1989. He wrote the first web browser in 1990 while employed at CERN in Switzerland. The browser was released outside CERN in 1991, first to other research institutions starting in January 1991 and to the general public on the Internet in August 1991.
The Internet Protocol (IP) is a protocol, or set of rules, for routing and addressing packets of data so that they can travel across networks and arrive at the correct destination. Data traversing the Internet is divided into smaller pieces called packets.
A database is a collection of related data that represents some aspect of the real world. A database system is designed to be built and populated with data for a certain task.
Database Management System (DBMS) is software for storing and retrieving users' data while considering appropriate security measures. It consists of a group of programs that manipulate the database. The DBMS accepts the request for data from an application and instructs the operating system to provide the specific data. In large systems, a DBMS helps users and other third-party software store and retrieve data.
DBMS allows users to create their databases as per their requirements. The term "DBMS" includes the use of a database and other application programs. It provides an interface between the data and the software application.
Let us see a simple example of a university database. This database maintains information concerning students, courses, and grades in a university environment. The database is organized into five files:
To define DBMS:
Here are the important landmarks from history:
Here are the characteristics and properties of a Database Management System:
Here is the list of some popular DBMS systems:
Cryptography is a technique to secure data and communication. It is a method of protecting information and communications through the use of codes so that only those for whom the information is intended can read and process it. Cryptography is used to protect data in transit, at rest, and in use. The prefix crypt means "hidden" or "secret", and the suffix graphy means "writing".
There are two types of cryptography:
Cryptocurrency is a digital currency in which encryption techniques are used to regulate the generation of units of currency and verify the transfer of funds, operating independently of a central bank. Cryptocurrencies use decentralized control as opposed to centralized digital currency and central banking systems. The decentralized control of each cryptocurrency works through distributed ledger technology, typically a blockchain, that serves as a public financial transaction database. A defining feature of a cryptocurrency, and arguably its most endearing allure, is its organic nature; it is not issued by any central authority, rendering it theoretically immune to government interference or manipulation.
In theoretical computer science and mathematics, the theory of computation is the branch that deals with what problems can be solved on a model of computation using an algorithm, how efficiently they can be solved, or to what degree (eg, approximate solutions versus precise ones). The field is divided into three major branches: automata theory and formal languages, computability theory, and computational complexity theory, which are linked by the question: "What are the fundamental capabilities and limitations of computers?".
Automata theory is the study of abstract machines and automata, as well as the computational problems that can be solved using them. It is a theory in theoretical computer science. The word automata comes from the Greek word αὐτόματος, which means "self-acting, self-willed, self-moving". An automaton (automata in plural) is an abstract self-propelled computing device that follows a predetermined sequence of operations automatically. An automaton with a finite number of states is called a Finite Automaton (FA) or Finite-State Machine (FSM). The figure on the right illustrates a finite-state machine, which is a well-known type of automaton. This automaton consists of states (represented in the figure by circles) and transitions (represented by arrows). As the automaton sees a symbol of input, it makes a transition (or jump) to another state, according to its transition function, which takes the previous state and current input symbol as its arguments.
In logic, mathematics, computer science, and linguistics, a formal language consists of words whose letters are taken from an alphabet and are well-formed according to a specific set of rules.
The alphabet of a formal language consists of symbols, letters, or tokens that concatenate into strings of the language. Each string concatenated from symbols of this alphabet is called a word, and the words that belong to a particular formal language are sometimes called well-formed words or well-formed formulas. A formal language is often defined using formal grammar, such as regular grammar or context-free grammar, which consists of its formation rules.
In computer science, formal languages are used, among others, as the basis for defining the grammar of programming languages and formalized versions of subsets of natural languages in which the words of the language represent concepts that are associated with particular meanings or semantics. In computational complexity theory, decision problems are typically defined as formal languages and complexity classes are defined as the sets of formal languages that can be parsed by machines with limited computational power. In logic and the foundations of mathematics, formal languages are used to represent the syntax of axiomatic systems, and mathematical formalism is the philosophy that all mathematics can be reduced to the syntactic manipulation of formal languages in this way.
Computability theory, also known as recursion theory, is a branch of mathematical logic and computer science that began in the 1930s with the study of computable functions and Turing degrees. Since its inception, the field has expanded to encompass the study of generalized computability and definability. In these areas, computability theory intersects with proof theory and effective descriptive set theory, reflecting its broad and interdisciplinary nature.
In theoretical computer science and mathematics, computational complexity theory focuses on classifying computational problems according to their resource usage and relating these classes to each other. A computational problem is a task solved by a computer. A computation problem is solvable by a mechanical application of mathematical steps, such as an algorithm.
A problem is regarded as inherently difficult if its solution requires significant resources, whatever the algorithm used. The theory formalizes this intuition by introducing mathematical models of computation to study these problems and quantifying their computational complexity, ie, the number of resources needed to solve them, such as time and storage. Other measures of complexity are also used, such as the amount of communication (used in communication complexity), the number of gates in a circuit (used in circuit complexity), and the number of processors (used in parallel computing). One of the roles of computational complexity theory is to determine the practical limits on what computers can and cannot do. The P versus NP problem, one of the seven Millennium Prize Problems, is dedicated to the field of computational complexity.
Closely related fields in theoretical computer science are the analysis of algorithms and computability theory. A key distinction between the analysis of algorithms and computational complexity theory is that the former is devoted to analyzing the number of resources needed by a particular algorithm to solve a problem, whereas the latter asks a more general question about all possible algorithms that could be used to solve the same problem. More precisely, computational complexity theory tries to classify problems that can or cannot be solved with appropriately restricted resources. In turn, imposing restrictions on the available resources is what distinguishes computational complexity from computability theory: the latter theory asks what kinds of problems can, in principle, be solved algorithmically.
DevOps is a set of practices, tools, and cultural philosophies that automate and integrate the processes between software development (Dev) and IT operations (Ops). The primary goal is to foster a culture of collaboration, automate processes across teams, and deliver high-quality software efficiently, reducing the time between committing a change to a system and the change being placed into production.
In essence, DevOps integrates all aspects of development (coding, building, testing, and releasing) with operations (deployment, monitoring, and maintenance) into a unified, automated pipeline. It builds on the principles of Agile development, but extends them into the operational phase of software deployment.
Sifat ? | Yuvraj Chauhan ? | Rajesh kumar halder ? | Ishan Mondal ? | Apoorva08102000 ? | Apoorva .S.梅塔 ? |
Imran Biswas ? | Subrata Pramanik | Samuel Favarin | sahooabhipsa10 | Sahil Rao | KK Chowdhury |
Manas Baroi | 阿迪蒂 ? | Syed Talib Hossain | Jai Mehrotra | Shuvam Bag | Abhijit Turate |
Jayesh Deorukhkar | JC Shankar | Subrata Pramanik | Imam Suyuti | genius_koder | Altaf Shaikh |
Rajdeep Das | Vikash Patel | Arvind Srivastav | Manish Kr Prasad | MOHIT KUMAR KUSHWAHA | DryHitman |
Harsh Kulkarni | Atreay Kukanur | Sree Haran | Auro Saswat Raj | Aiyan Faras | Priyanshi David |
Ishan Mondal | Nikhil Shrivastava | deepshikha2708 | L.RISHIWARDHAN | Rahul RK | Nishant Wankhade |
pritika163 | Anjuman Hasan | Astha Varshney | Gcettbdeveloper | Elston Tan | Shivansh Dengla |
David Daniels | ayushverma14 | Pratik Rai | Yash | pranavyatnalkar | Jeremia Axel |
Akhil Soni | Zahra Shahid | Mihir20K | 阿曼 | Mauricio Allegretti | Bruno-Vasconcellos-Betella |
Febi Arifin | Dineshwar Doddapaneni | Dheeraj_Soni | Ojash Kushwaha | Laleet Borse | Wahaj Raza |
WahajRaza1 | Ravi Lamkoti | The One and Only Uper | AdarshBajpai67 | Deepak Kharah | sairohit360 |
sairohitzl | Raval Jinit | Vovka1759 | Nijin | Avinil Bedarkar | FercueNat |
Yash Khare | Ayush Anand | DharmaWarrior | Hitarth Raval | Wiem Borchani | Kamden Burke |
denschiro | Nishat | Mohammed Faizan Ahmed | Manish Agrahari | Katari Lokeswara rao | Zahra Shahid |
Glenn Turner | Vinayak godse | Satyajeetbh | Paidipelly Dhruvateja | helloausrine | SourabhJoshi209 |
Stefan Taitano | Abu Noman Md. Sakib | Rishi Mathur | Darky001 | Himanshu | Kusumita Ghose |
Yashvi Patel | ArshadAriff | ishashukla183 | jhuynh06 ? | Andrew Asche | J. Nathan Allen ? |
Sayed Afnan Khazi | Technic143 ? | Pin Yuan Wang | Bogdan Otava | Vedeesh Dwivedi ? | Tsig |
Brandon Awan ? | Sanya Madre | 史蒂文 | Garrett Crowley | Francesco Franco ? | Alexander Little ? |
Subham Maji ? | SK Jiyad ? | exrol ? | Manav Mittal ? | Rathish R ? | Anubhav Kulshreshtha ? |
薩爾薩克 | architO21 ? | Nikhil Kumar Jha | Kundai Chasinda ? | Rohan kaushal ? | Aayush Kumar |
Vladimir Cucu ? | Mohammed Ali Alsakkaf (Binbasri) ? | 伺服器 ? | Amritanshu Barpanda ? | aheaton22 ? | Masumi Kawasaki ? |
aslezar | Yash Sajwan ? | Abhishek Kumar ? | jakenybo ? | Fangzhou_Jiang ? | Nelson Uprety ? |
Kevin Garfield ? | xaviermonb ? | AryasCodeTreks | khouloud HADDAD AMAMOU | Walter March ? | Nivea Hanley |
納 | Shaan Rehsi ? | mjung1 | Joshua Latham ? | Pietro Bartolocci ? | Naveen Prajapati |
Billy Marcus Wright | Raquel-James | Teddy ASSIH | Md Nayeem ? |


