movies_qna
1.0.0
此存儲庫的目的是將OpenAI根據SQL數據庫和其他一些基於檢索的問答答案答复,並使用Langchain回答任務。
康奈爾(Cornell)的電影dialog-corpus用於此存儲庫,其預處理以及其轉換為關係SQL數據庫,並添加了相關DB約束(例如主鍵,外鍵,外國密鑰等)。
在初始語料庫(Movie-Dialog-Corpus目錄)上進行預處理,並將數據庫導出為數據庫目錄中的SQLITE數據庫。筆記本電腦可在筆記本電腦目錄中獲得,用於預處理和轉換(preprocess_and_convert_to_to_sqlite_db.ipynb)。 (可以跳過此筆記本,因為SQLite DB文件可在Repo中找到,可以在下一個筆記本中直接使用)
問答是使用Openai的Davinci模型以及Langchain進行的,筆記本中描述了該方法。 Question_answering_on_sql_database.ipynb。本筆記本使用上一個筆記本中創建的SQLite數據庫。
要從電影腳本URL獲取/刮擦數據,並使用OpenAI嵌入式創建基於FAISS的矢量數據庫索引,請參閱Notebook fetch_movie_scripts_and_create_indexes.ipynb。可以跳過此筆記本,並可以從Google Drive文件夾下載生成的文件。
要從OpenAI查詢任何查詢以後從上一個筆記本中創建的向量索引獲得相關索引後,請使用筆記本QUERYING_FROM_OPENAI_OPENAI_AFTER_RETRIEVAL_FROM_FROM_INDEXES
對於使用代理並將多個工具連接在一起並構建一個基本的問題回答系統,同時連接了SQL數據庫模塊和基於Vector的查詢在電影腳本和其他工具上,請仔細閱讀筆記本,使用_AGENTS_FOR_QA_SQL_SQL_SQL_AND_VECTORDB.IPYNB
可以通過使用sqlite數據庫(例如https://sqlitebrowser.org/)查看SQLITE數據庫文件MovieDB.db。
要在Python中查看數據庫,請以與數據庫相同的目錄運行以下代碼
import sqlite3
import pandas as pd
con = sqlite3.connect("moviesdb.db")
df = pd.read_sql_query("SELECT * from movie_titles", con)
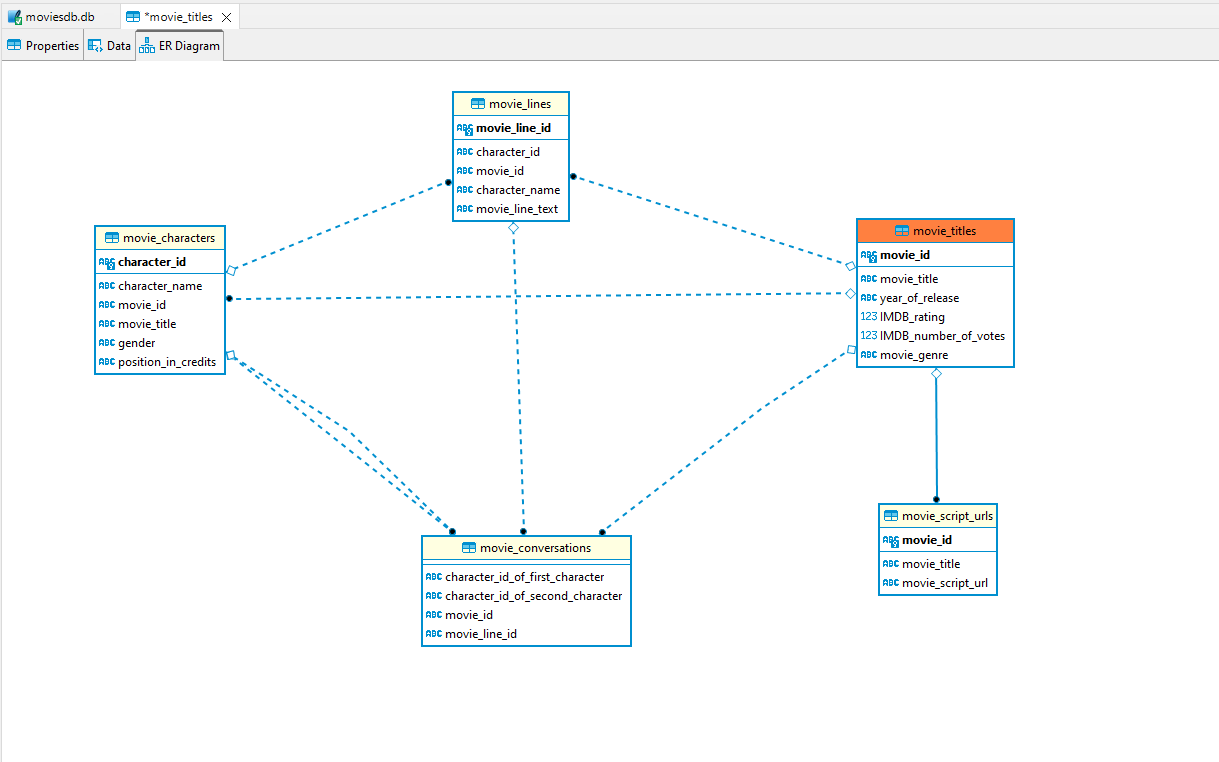
數據庫的ER圖如下: -