movies_qna
1.0.0
此存储库的目的是将OpenAI根据SQL数据库和其他一些基于检索的问答答案答复,并使用Langchain回答任务。
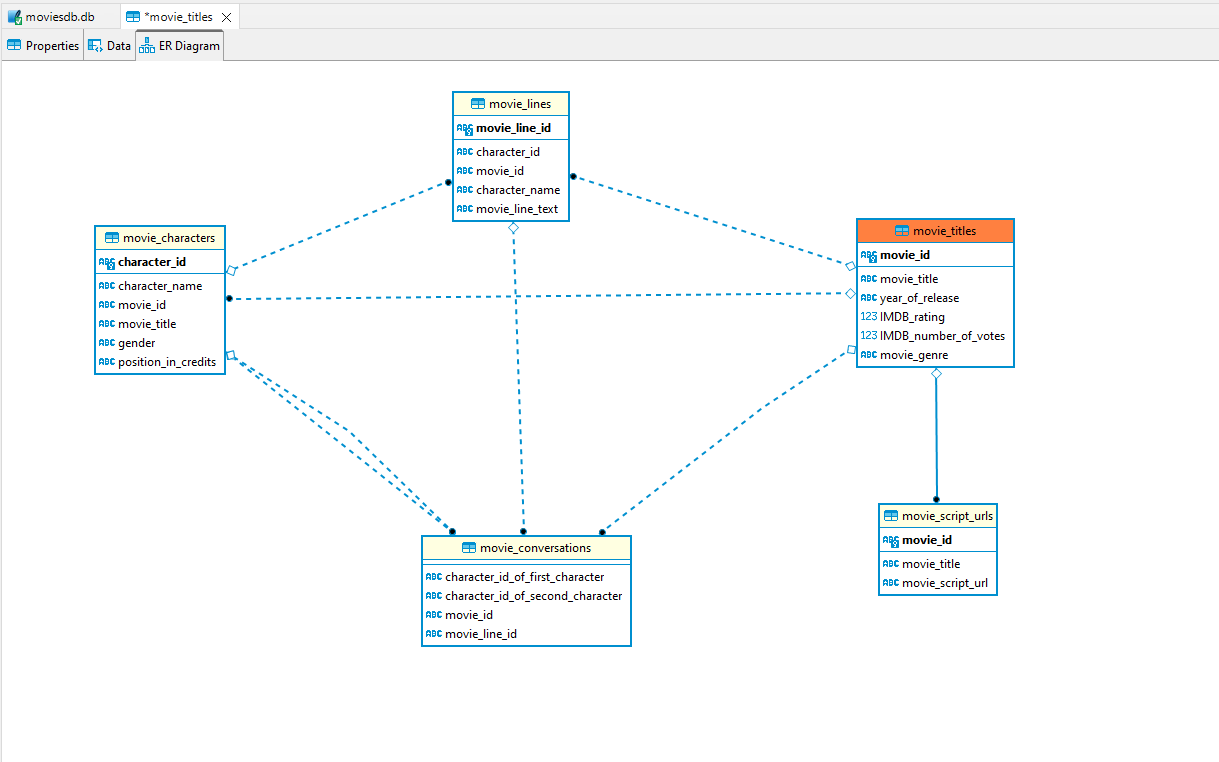
康奈尔(Cornell)的电影dialog-corpus用于此存储库,其预处理以及其转换为关系SQL数据库,并添加了相关DB约束(例如主键,外键,外国密钥等)。
在初始语料库(Movie-Dialog-Corpus目录)上进行预处理,并将数据库导出为数据库目录中的SQLITE数据库。笔记本电脑可在笔记本电脑目录中获得,用于预处理和转换(preprocess_and_convert_to_to_sqlite_db.ipynb)。 (可以跳过此笔记本,因为SQLite DB文件可在Repo中找到,可以在下一个笔记本中直接使用)
问答是使用Openai的Davinci模型以及Langchain进行的,笔记本中描述了该方法。 Question_answering_on_sql_database.ipynb。本笔记本使用上一个笔记本中创建的SQLite数据库。
要从电影脚本URL获取/刮擦数据,并使用OpenAI嵌入式创建基于FAISS的矢量数据库索引,请参阅Notebook fetch_movie_scripts_and_create_indexes.ipynb。可以跳过此笔记本,并可以从Google Drive文件夹下载生成的文件。
要从OpenAI查询任何查询以后从上一个笔记本中创建的向量索引获得相关索引后,请使用笔记本QUERYING_FROM_OPENAI_OPENAI_AFTER_RETRIEVAL_FROM_FROM_INDEXES
对于使用代理并将多个工具连接在一起并构建一个基本的问题回答系统,同时连接了SQL数据库模块和基于Vector的查询在电影脚本和其他工具上,请仔细阅读笔记本,使用_AGENTS_FOR_QA_SQL_SQL_SQL_AND_VECTORDB.IPYNB
可以通过使用sqlite数据库(例如https://sqlitebrowser.org/)查看SQLITE数据库文件MovieDB.db。
要在Python中查看数据库,请以与数据库相同的目录运行以下代码
import sqlite3
import pandas as pd
con = sqlite3.connect("moviesdb.db")
df = pd.read_sql_query("SELECT * from movie_titles", con)
数据库的ER图如下: -