movies_qna
1.0.0
이 repo의 의도는 SQL 데이터베이스를 기반으로 한 질문에 OpenAI를 사용하고 Langchain을 사용하는 작업에 응답하는 기타 검색 기반 질문에 대한 답변을 사용하는 것입니다.
Cornell의 Movie-Dialog-Corpus는이 Repo에서 사용되며 사전 프로세싱은 기본 키, 외국 키 등과 같은 관계형 DB 제약 조건을 추가하여 관계형 SQL 데이터베이스로의 전환과 함께 수행됩니다.
전처리는 초기 코퍼스 (Movie-Dialog-Corpus 디렉토리)에서 수행되었으며 데이터베이스는 데이터베이스 디렉토리의 SQLITE 데이터베이스로 내보내집니다. 노트북은 전처리 및 변환 (preprocess_and_convert_to_sqlite_db.ipynb)을위한 노트북 디렉토리에서 구입할 수 있습니다. (이 노트북은 SQLITE DB 파일이 Repo에서 사용할 수 있으므로 다음 공책에서 직접 사용할 수 있으므로 건너 뛸 수 있습니다)
질문 응답은 Langchain과 함께 Openai의 Davinci 모델을 사용하여 수행되며, 접근 방식은 노트북에 설명되어 있습니다. question_answering_on_sql_database.ipynb. 이 노트북은 이전 노트북에서 만든 SQLITE 데이터베이스를 사용합니다.
영화 스크립트 URL에서 데이터를 가져 오기/스크래핑하고 OpenAi 임베딩을 사용하여 FAISS 기반 벡터 데이터베이스 인덱스를 작성하려면 노트북 Fetch_movie_Script_and_Create_Indexes.ipynb를 참조하십시오. 이 노트북은 건너 뛸 수 있고 생성 된 파일은 Google 드라이브 폴더에서 다운로드 할 수 있습니다.
이전 노트북에서 생성 된 벡터 인덱스에서 관련 인덱스를 얻은 후 모든 쿼리에 대한 OpenAi에서 쿼리를하려면 노트북 querying_from_openai_after_retrieval_from_indexes를 사용하십시오.
에이전트를 사용하고 여러 도구를 결합하고 기본적인 질문 응답 시스템을 구축하려면 영화 스크립트 및 추가 도구에서 SQL 데이터베이스 모듈과 벡터 기반 쿼리를 결합하는 기본 질문 응답 시스템을 구축하려면 _agents_for_QA_ON_SQL_AND_VECTORDB.IPYNB를 사용하여 노트북을 방문하십시오.
sqlite 데이터베이스 파일 영화 divisedb.db는 https://sqlitebrowser.org/와 같은 sqlite 데이터베이스의 뷰어를 사용하여 볼 수 있습니다.
Python에서 데이터베이스를 보려면 데이터베이스와 동일한 디렉토리에서 아래 코드를 실행하십시오.
import sqlite3
import pandas as pd
con = sqlite3.connect("moviesdb.db")
df = pd.read_sql_query("SELECT * from movie_titles", con)
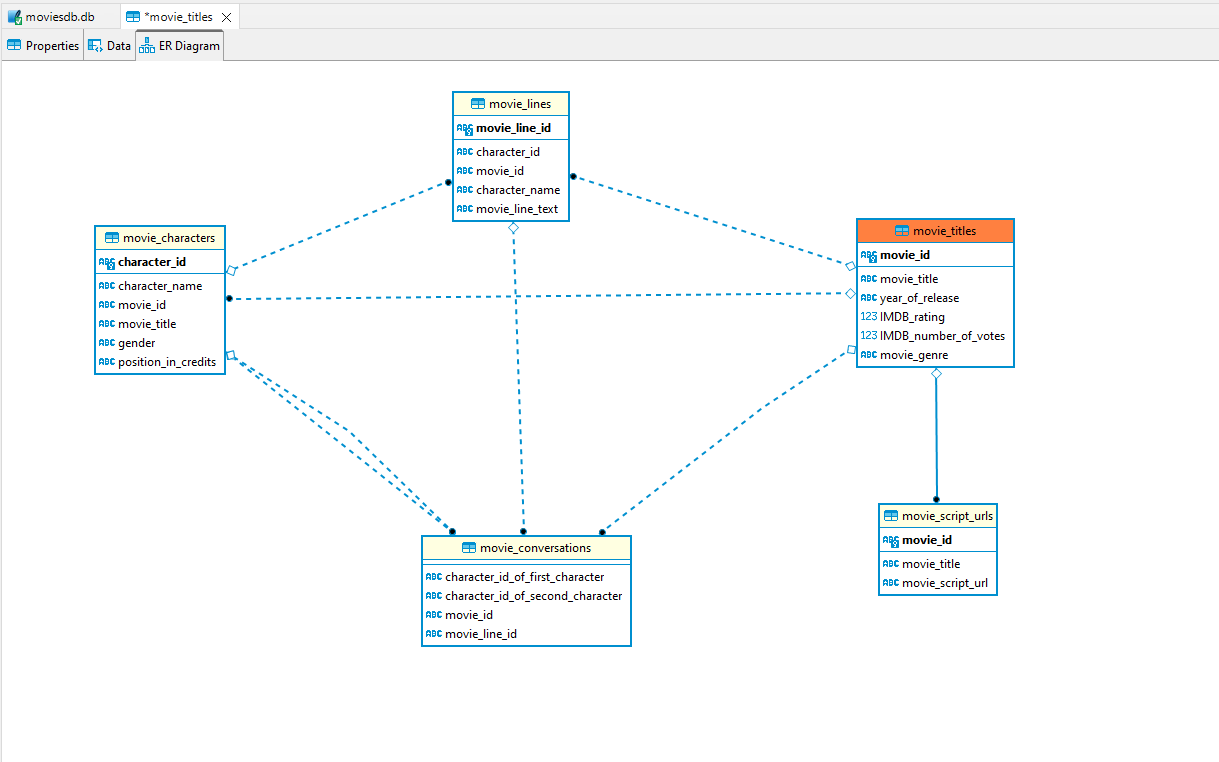
데이터베이스의 ER 다이어그램은 다음과 같습니다. -