movies_qna
1.0.0
ความตั้งใจของ repo นี้คือการใช้ OpenAI สำหรับการตอบคำถามตามฐานข้อมูล SQL และงานตอบคำถามตามการดึงข้อมูลอื่น ๆ โดยใช้ Langchain
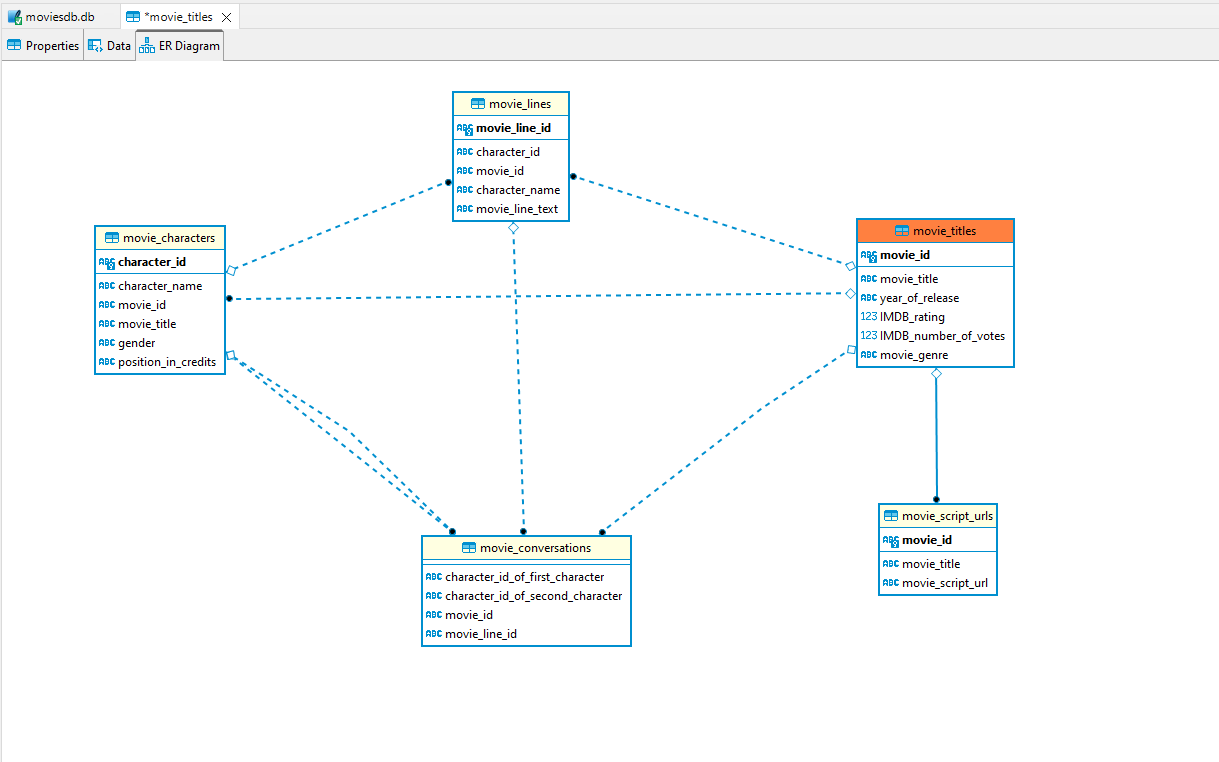
Movie-Dialog-Corpus จาก Cornell ใช้ใน repo นี้และการประมวลผลล่วงหน้าจะทำพร้อมกับการแปลงเป็นฐานข้อมูล SQL เชิงสัมพันธ์ด้วยการเพิ่มข้อ จำกัด DB เชิงสัมพันธ์เช่นคีย์หลักคีย์ต่างประเทศ ฯลฯ
การประมวลผลล่วงหน้าดำเนินการบนคลังข้อมูลเริ่มต้น (ไดเรกทอรีภาพยนตร์-ไดอารี่-คอร์ปัส) และฐานข้อมูลจะถูกส่งออกเป็นฐานข้อมูล SQLite ในไดเรกทอรีฐานข้อมูล โน้ตบุ๊กมีอยู่ในไดเรกทอรีโน้ตบุ๊กสำหรับการประมวลผลล่วงหน้าและการแปลง (preprocess_and_convert_to_sqlite_db.ipynb) (สมุดบันทึกนี้สามารถข้ามได้เนื่องจากไฟล์ SQLite DB พร้อมใช้งานใน repo และสามารถใช้โดยตรงในสมุดบันทึกถัดไป)
การตอบคำถามทำได้โดยใช้โมเดล Davinci ของ Openai พร้อมกับ Langchain วิธีการอธิบายไว้ในสมุดบันทึก question_answering_on_sql_database.ipynb โน้ตบุ๊กนี้ใช้ฐานข้อมูล SQLite ที่สร้างขึ้นในสมุดบันทึกก่อนหน้า
สำหรับการดึงข้อมูล/ขูดข้อมูลจาก URL สคริปต์ภาพยนตร์และเพื่อสร้างดัชนีฐานข้อมูลเวกเตอร์ที่ใช้ FAISS โดยใช้ OpenAI EMBEDDINGS อ้างอิง Notebook FETCH_MOVIE_SCRIPTS_AND_CREATE_INDEXES.IPYNB สมุดบันทึกนี้สามารถข้ามและสามารถดาวน์โหลดไฟล์ที่สร้างขึ้นได้จากโฟลเดอร์ Google Drive
สำหรับการสืบค้นจาก OpenAI สำหรับการสืบค้นใด ๆ หลังจากได้รับดัชนีที่เกี่ยวข้องจากดัชนีเวกเตอร์ที่สร้างขึ้นในสมุดบันทึกก่อนหน้านี้ให้ใช้สมุดบันทึก querying_from_openai_after_retrieriveal_from_indexes
สำหรับการใช้ตัวแทนและเข้าร่วมเครื่องมือหลายอย่างเข้าด้วยกันและสร้างระบบตอบคำถามพื้นฐานที่เข้าร่วมทั้งโมดูลฐานข้อมูล SQL และการสืบค้นแบบเวกเตอร์บนสคริปต์ภาพยนตร์และเครื่องมือเพิ่มเติม
ไฟล์ฐานข้อมูล SQLite Moviesdb.db สามารถดูได้โดยใช้ผู้ชมสำหรับฐานข้อมูล SQLite เช่น https://sqlitebrowser.org/
หากต้องการดูฐานข้อมูลใน Python ให้เรียกใช้รหัสด้านล่างในไดเรกทอรีเดียวกับฐานข้อมูล
import sqlite3
import pandas as pd
con = sqlite3.connect("moviesdb.db")
df = pd.read_sql_query("SELECT * from movie_titles", con)
แผนภาพเอ้อของฐานข้อมูลอยู่ด้านล่าง: -