movies_qna
1.0.0
このレポの目的は、SQLデータベースおよびLangchainを使用した他の検索ベースの質問回答タスクに基づいて質問に答えるためにOpenaiを使用することです。
Cornellのムービーダイアログコルパスはこのレポで使用されており、その前処理は、リレーショナルSQLデータベースへの変換とともに行われます。
前処理は初期コーパス(Movie-Dialog-Corpusディレクトリ)で実行され、データベースはデータベースディレクトリのSQLiteデータベースとしてエクスポートされます。ノートブックは、プリプロセシングと変換用のノートブックディレクトリ(PREPROCESS_AND_CONVERT_TO_SQLITE_DB.IPYNB)で入手できます。 (このノートブックは、sqlite dbファイルがレポで利用可能であり、次のノートブックで直接使用できるため、スキップできます)
質問の回答は、LangchainとともにOpenaiのDavinciモデルを使用して行われます。このアプローチはノートブックで説明されています。 question_answering_on_sql_database.ipynb。このノートブックは、以前のノートブックで作成されたSQLiteデータベースを使用しています。
映画スクリプトURLからデータを取得/スクレイピングし、OpenAI埋め込みを使用したFAISSベースのベクトルデータベースインデックスを作成するには、ノートブックfetch_movie_scripts_and_create_indexes.ipynbを参照してください。このノートブックはスキップでき、Googleドライブフォルダーから生成されたファイルをダウンロードできます。
以前のノートブックで作成されたベクトルインデックスから関連するインデックスを取得した後、任意のクエリをopenaiからクエリするには、ノートブックquerying_from_openai_after_retrieval_from_indexesを使用します
エージェントを使用して複数のツールを結合し、SQLデータベースモジュールと映画スクリプトと追加ツールのベクトルベースのクエリの両方を結合する基本的な質問回答システムを構築するには、Note_agents_for_qa_on_sql_and_vectordb.ipynbを使用して、
sqliteデータベースファイルムービーDB.DBは、https://sqlitebrowser.org/などのSQLiteデータベースのViewerを使用して表示できます。
Pythonでデータベースを表示するには、データベースと同じディレクトリで以下のコードを実行します
import sqlite3
import pandas as pd
con = sqlite3.connect("moviesdb.db")
df = pd.read_sql_query("SELECT * from movie_titles", con)
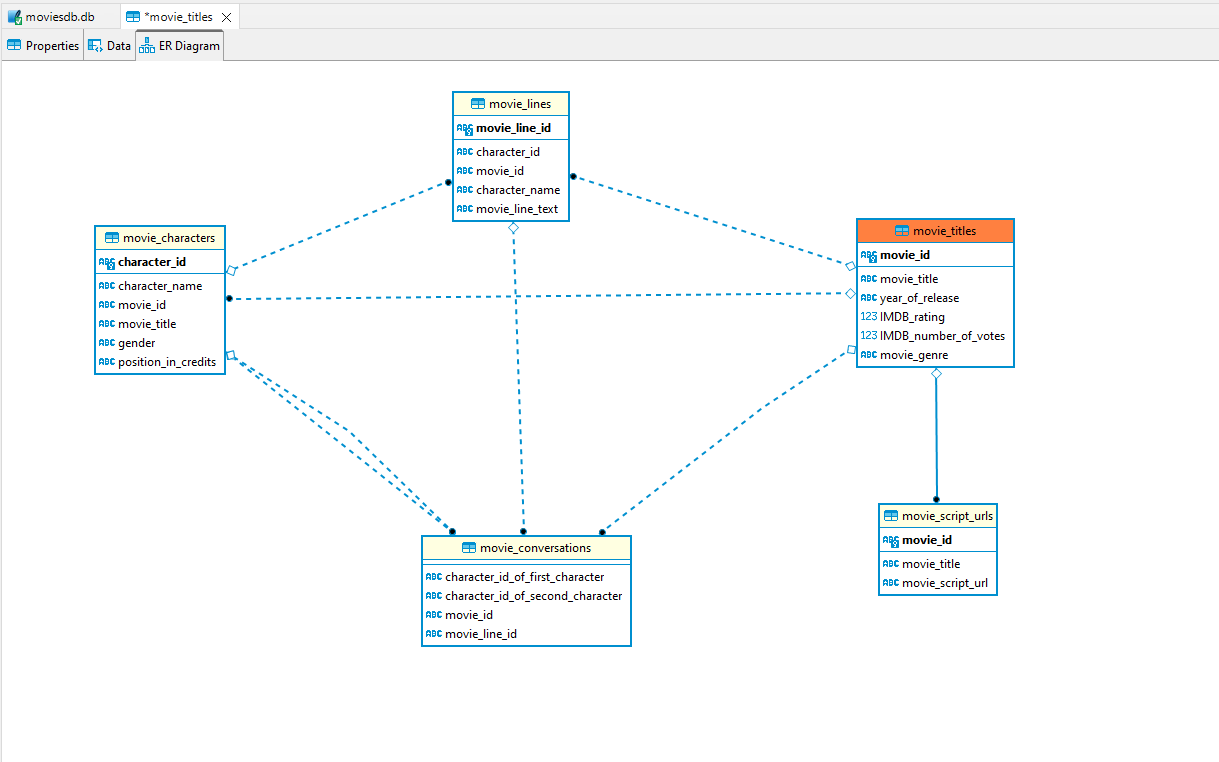
データベースのER図は以下にあります: -