QDrant NLP
1.0.0
將人保持在循環中。我不是Qdrant的開發人員,也不是與他們直接相關的開發人員,但是我認為他們已經建立了一些出色的東西,並且迄今為止被低估了。這個倉庫在這裡比其他任何事情都更能充當演示。
https://github.com/qdrant/qdrant
一旦整理並在Dockerhub上可用,我將其稱為完成。就足夠,您可以使用它來運行自己的POC而無需任何其他代碼。
您只需通過Swagger UI即可達到該工具的幾乎一半,但是顯然,這是為了擊中簡單的API而不是以數據為中心的AI工作流,因此缺少一些有用的組件。這項工作在此處更深入地寫下https://medium.com/@george.pearse(矢量數據庫第2部分)。
玩具徽標位於放大鏡之間,用於該工具如何使您真正專注於特定的數據子集,而經典的貝葉斯圖則是我被帶走足以嘗試添加積極學習的情況。
通過Google搜索來查找有關擁抱face句子轉換器的文檔,使我瘋狂地生活在這裡https://www.sbert.net/docs/hugging_face.html
用擁抱面,精簡和QDRANT快速標記。首先,我將支持NLP,然後我會考慮添加圖像支持(這是這個想法的來源)。
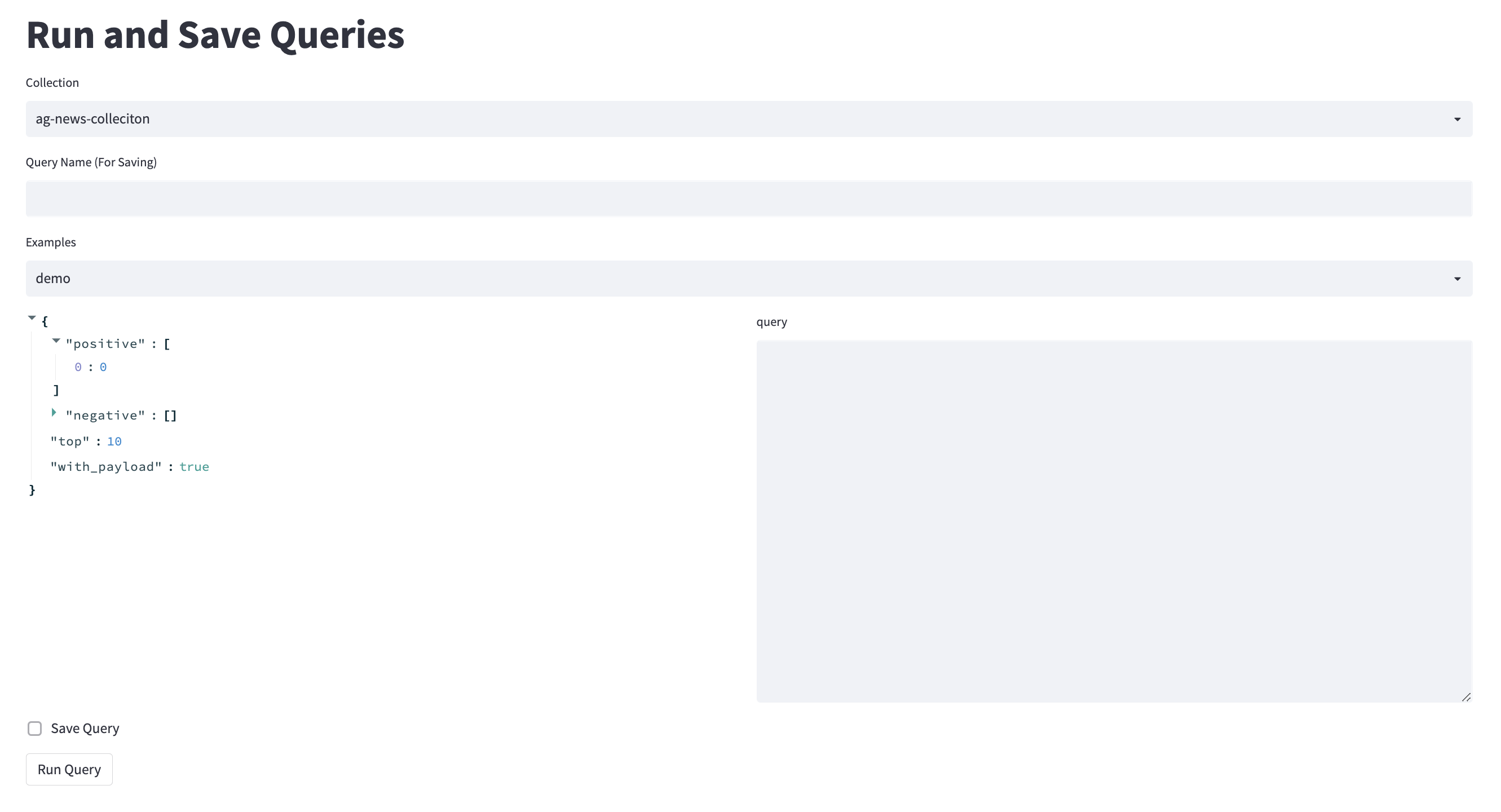
有關完整的解決方案,請參見Kern.ai,該解決方案在幕後使用QDRANT。該工具本來應該足夠簡單,可以作為矢量數據庫的簡介。您可以像通過Python API一樣編寫和查看請求。
同樣,koaning/散裝非常好,但是如果UMAP(在此處插入替代維度降低技術)會失去所有細微差別,而高級可視化無法為您的數據集提供價值?
我還想給FastAPI進行一次微小的測試運行,因此,對於您保存的每個查詢(發布請求),您可以通過使用查詢名稱擊中FastApi端點來收到其結果。
要將這些工具應用於多模式數據集,您只需要將每個組件的嵌入式嵌入,然後使用所有相同的技術。
NB:其他名稱
使用切斷的相似性而不是最近的K。
首先,只需運行
docker-compose up


