QDrant NLP
1.0.0
Garder l'humain dans la boucle. Je ne suis pas un développeur chez Qdrant, ni directement associé, mais je pense qu'ils ont construit quelque chose d'excellent et jusqu'à présent sous-estimé. Ce dépôt est là pour agir comme une démo plus que toute autre chose.
https://github.com/qdrant/qdrant
Je l'appellerai fait une fois bien rangé et disponible sur DockerHub. Juste assez pour que vous puissiez peut-être l'utiliser pour exécuter votre propre POC sans aucun code supplémentaire.
Vous pouvez réaliser près de la moitié de cet outil juste via leur interface utilisateur Swagger, mais évidemment, c'est conçu pour frapper des API simples, pas des flux de travail IA centrés sur les données, il manque donc quelques composants utiles. Ce travail est écrit plus en profondeur ici https://medium.com/@george.pearse (Bases de données vectorielles partie 2).
Le logo jouet se situe quelque part entre une loupe pour la façon dont l'outillage vous permet de vraiment vous concentrer sur un sous-ensemble de données spécifique, et un graphique bayésien classique pour si je suis suffisamment emporté pour essayer d'ajouter un apprentissage actif.
Trouver la documentation pour les transformateurs de phrases en face de câlins via Google Search m'a rendu fou, il vit ici https://www.sbert.net/docs/hugging_face.html
Étiquetage rapide avec des étreintes, rationalisant et qdrant. Je vais d'abord prendre en charge la PNL, puis je penserai à ajouter un support d'image (d'où cette idée vient).
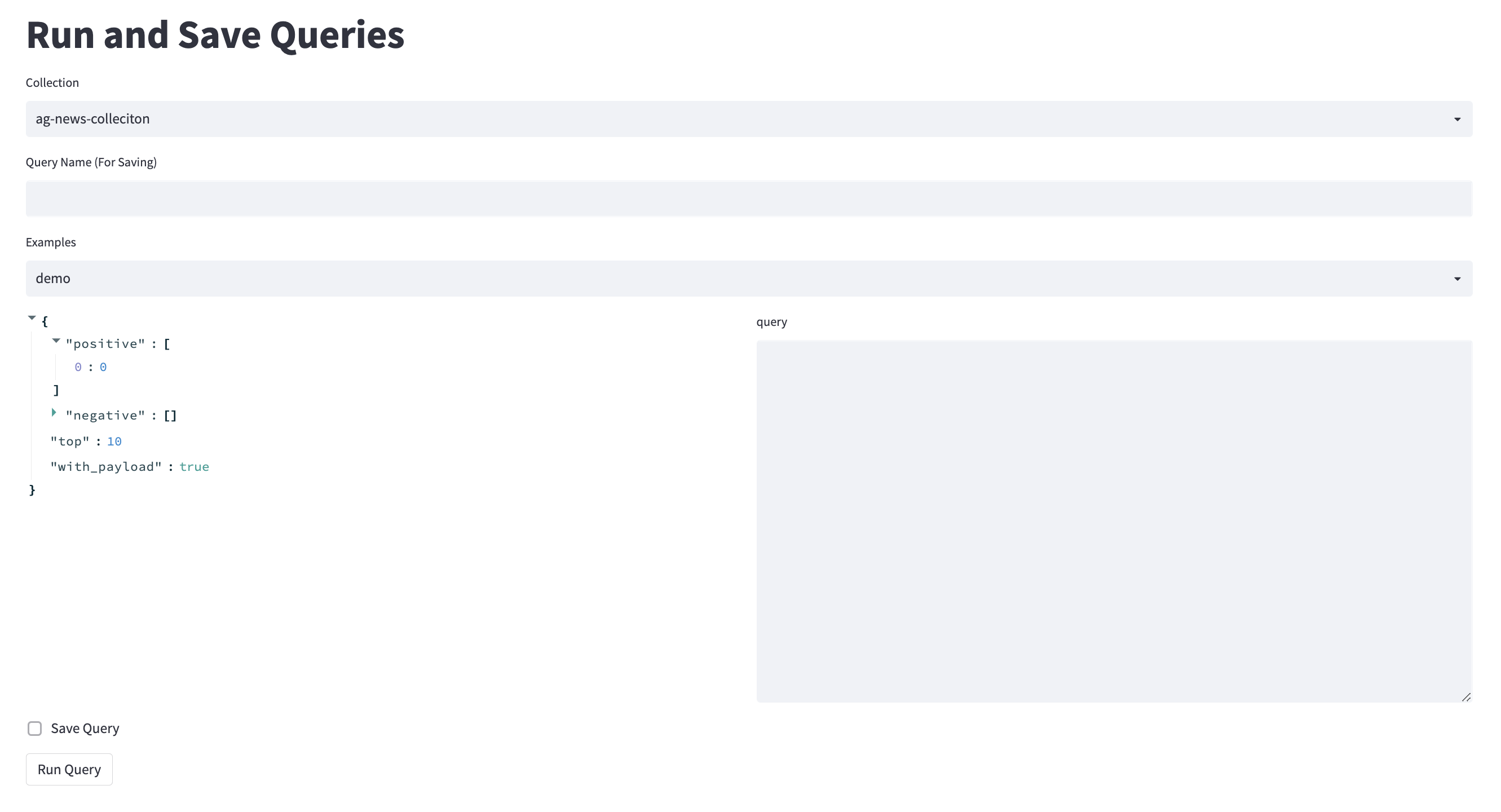
Voir Kern.ai pour une solution complète qui utilise Qdrant dans les coulisses. Cet outil est censé être assez simple pour agir comme introduction aux bases de données vectorielles. Vous pouvez écrire et voir les demandes, tout comme vous le feriez via l'API Python.
De même, le koaning / le vrac est excellent, mais que se passe-t-il si UMAP (insérer une technique de réduction de la dimensionnalité alternative ici) perd toute la nuance et que les visualisations de haut niveau ne fournissent pas de valeur à votre ensemble de données?
Je voulais également donner à Fastapi un petit test, donc pour chaque requête (demande de poste) que vous enregistrez, vous pouvez recevoir ses résultats en frappant le point de terminaison Fastapi avec le nom de la requête.
Pour appliquer ces outils à un ensemble de données multimodal, vous n'auriez besoin que de concaténer les incorporations pour chaque composant et vous allez avec tous les mêmes technqiues.
NB: Autres noms
Pourrait être logique d'appliquer une similitude coupée au lieu du K. le plus proche.
Pour commencer, courez juste
docker-compose up


