QDrant NLP
1.0.0
将人保持在循环中。我不是Qdrant的开发人员,也不是与他们直接相关的开发人员,但是我认为他们已经建立了一些出色的东西,并且迄今为止被低估了。这个仓库在这里比其他任何事情都更能充当演示。
https://github.com/qdrant/qdrant
一旦整理并在Dockerhub上可用,我将其称为完成。就足够,您可以使用它来运行自己的POC而无需任何其他代码。
您只需通过Swagger UI即可达到该工具的几乎一半,但是显然,这是为了击中简单的API而不是以数据为中心的AI工作流,因此缺少一些有用的组件。这项工作在此处更深入地写下https://medium.com/@george.pearse(矢量数据库第2部分)。
玩具徽标位于放大镜之间,用于该工具如何使您真正专注于特定的数据子集,而经典的贝叶斯图则是我被带走足以尝试添加积极学习的情况。
通过Google搜索来查找有关拥抱face句子转换器的文档,使我疯狂地生活在这里https://www.sbert.net/docs/hugging_face.html
用拥抱面,精简和QDRANT快速标记。首先,我将支持NLP,然后我会考虑添加图像支持(这是这个想法的来源)。
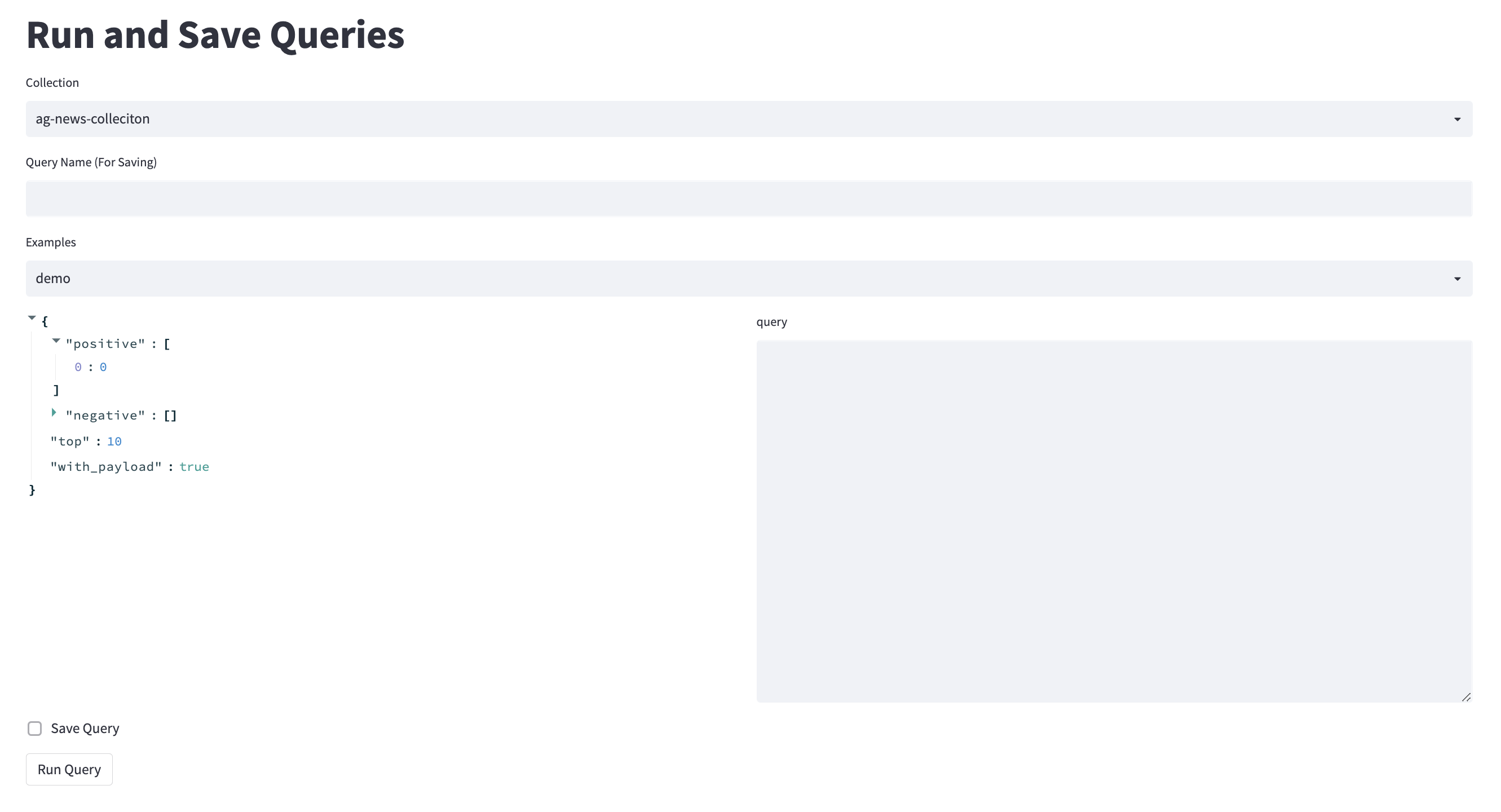
有关完整的解决方案,请参见Kern.ai,该解决方案在幕后使用QDRANT。该工具本来应该足够简单,可以作为矢量数据库的简介。您可以像通过Python API一样编写和查看请求。
同样,koaning/散装非常好,但是如果UMAP(在此处插入替代维度降低技术)会失去所有细微差别,而高级可视化无法为您的数据集提供价值?
我还想给FastAPI进行一次微小的测试运行,因此,对于您保存的每个查询(发布请求),您可以通过使用查询名称击中FastApi端点来收到其结果。
要将这些工具应用于多模式数据集,您只需要将每个组件的嵌入式嵌入,然后使用所有相同的技术。
NB:其他名称
使用切断的相似性而不是最近的K。
首先,只需运行
docker-compose up


