QDrant NLP
1.0.0
Manteniendo al humano en el bucle. No soy un desarrollador de Qdrant, ni directamente asociado con ellos, pero creo que han construido algo excelente y, por lo tanto, poco apreciado. Este repositorio está aquí para actuar como una demostración más que cualquier otra cosa.
https://github.com/qdrant/qdrant
Lo llamaré una vez que esté ordenado y esté disponible en Dockerhub. Solo lo suficiente para que pueda usarlo para ejecutar su propio POC sin ningún código adicional.
Puede lograr casi la mitad de esta herramienta solo a través de su interfaz de usuario de Swagger, pero obviamente, está diseñado para golpear API simples, no flujos de trabajo de IA centrados en datos, por lo que le falta algunos componentes útiles. Este trabajo se escribe con más profundidad aquí https://medium.com/@george.pearse (Bases de datos de vectores Parte 2).
El logotipo de Toy está en algún lugar entre una lupa de cómo las herramientas le permiten centrarse realmente en un subconjunto de datos específico, y un gráfico bayesiano clásico para si me llevo lo suficiente como para tratar de agregar el aprendizaje activo.
Encontrar la documentación para los transformadores de oraciones de abrazaderas de abrazo a través de Google Search me enloqueció, vive aquí https://www.sbert.net/docs/hugging_face.html
Etiquetado rápido con cara de abrazo, racionalización y qdrant. Primero admitiré NLP, luego pensaré en agregar soporte de imagen (que es de donde proviene esta idea).
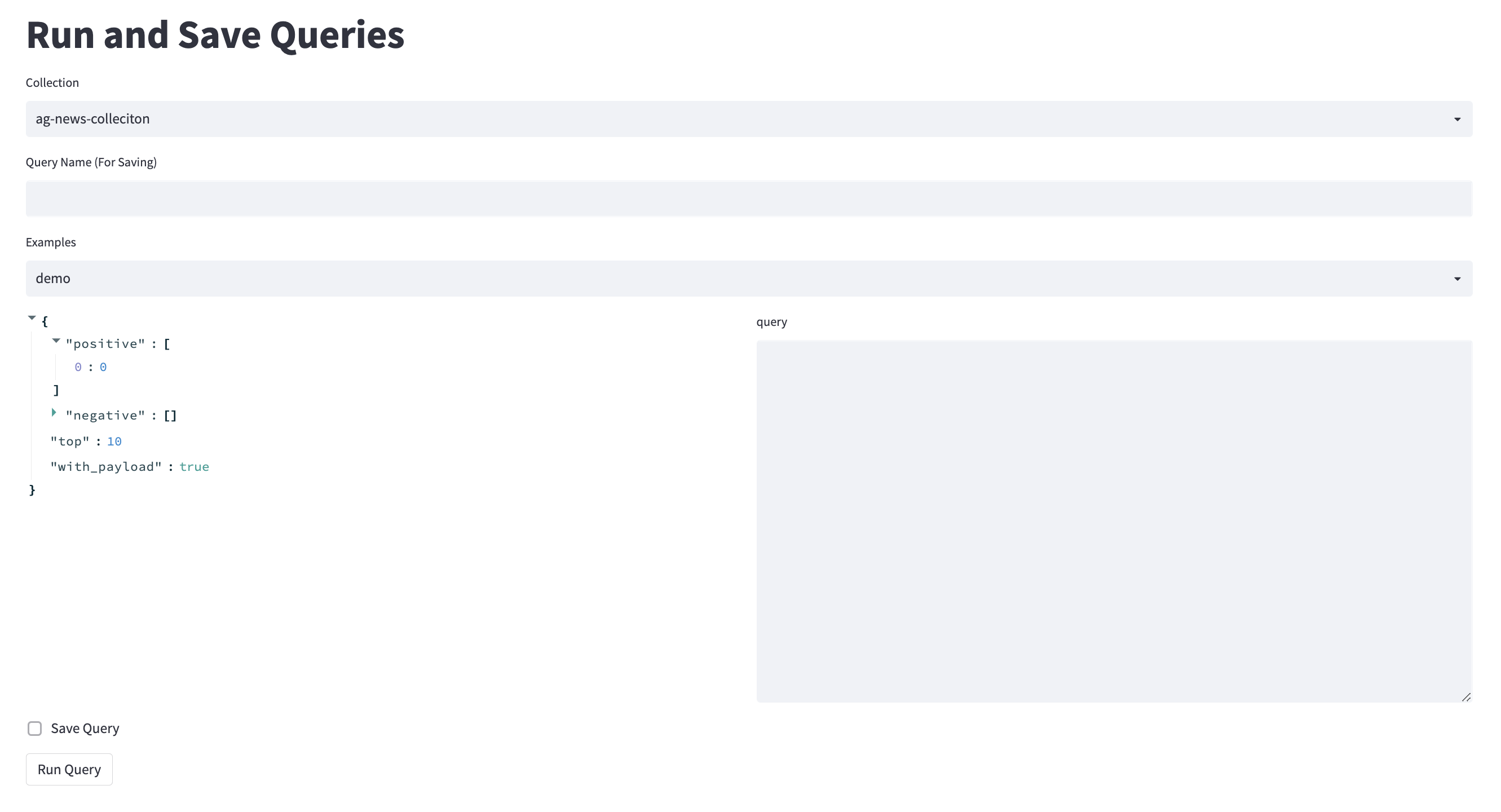
Vea Kern.ai para una solución completa que usa Qdrant detrás de escena. Esta herramienta está destinada a ser lo suficientemente simple como para actuar como una introducción a las bases de datos vectoriales. Puede escribir y ver las solicitudes, tal como lo haría a través de la API de Python.
Del mismo modo, Koaning/Bulk es excelente, pero ¿qué pasa si UMAP (Insertar la técnica de reducción de dimensionalidad alternativa aquí) pierde todos los matices y las visualizaciones de alto nivel no pueden proporcionar valor para su conjunto de datos?
También quería darle a Fastapi una pequeña ejecución de prueba, por lo que para cada consulta (solicitud posterior) que guarde, puede recibir sus resultados al alcanzar el punto final de Fastapi con el nombre de la consulta.
Para aplicar estas herramientas a un conjunto de datos multimodal, solo necesitaría concatenar los incrustaciones para cada componente y ir con las mismas técnicas.
NB: otros nombres
Podría tener sentido aplicar un corte de similitud en lugar de la K. más cercana.
Para comenzar, solo corre
docker-compose up


