redis nvidia recsys
1.0.0
該存儲庫的資產是補充“離線到Online:使用Nvidia Merlin的實時推薦系統的功能存儲”的資產,最初是為Nvidia Developer Blog編寫的。
我們提供推薦系統體系結構的示例,並為生產使用提供雲部署說明。每個示例都取決於Redis和Nvidia Merlin框架,該框架提供了許多用於創建推薦系統的構建塊。
此存儲庫中有3個示例
大規模擴展了第二個需要大規模(> 1 GPU)培訓或推理的用例的體系結構。
每個示例均設計為在啟用docker和docker-compose的NVIDIA GPU系統上本地運行。我們建議使用NVIDIA GPU在雲實例上執行所有以下內容(理想情況下是AWS Pytorch AMI)
但是,我們還提供了一組Terraform腳本和可安裝的筆記本,這些腳本可以部署在AWS實例上執行示例所需的基礎架構。
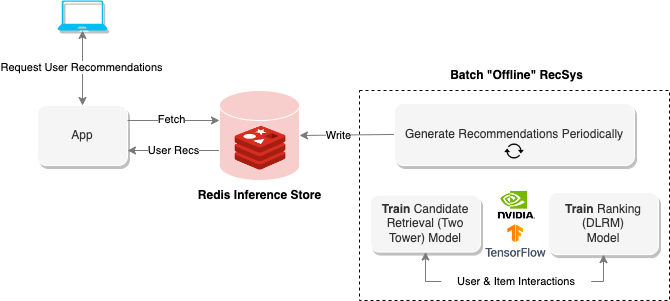
“離線”推薦系統使用批處理計算來處理大量數據,然後存儲它們以備以後檢索。上圖顯示了這樣一個系統的示例,該系統使用兩塔方法生成建議,然後將其存儲在Redis數據庫中以進行以後的檢索。
離線筆記本電腦提供了建立此類推薦系統的方法,並在以下部分中導出了運行在線推薦系統所需的模型。
要執行筆記本,請運行以下內容
$ cd offline-batch-recsys/
$ docker compose up # -d to daemonize然後打開Jupyter在瀏覽器中生成的鏈接。
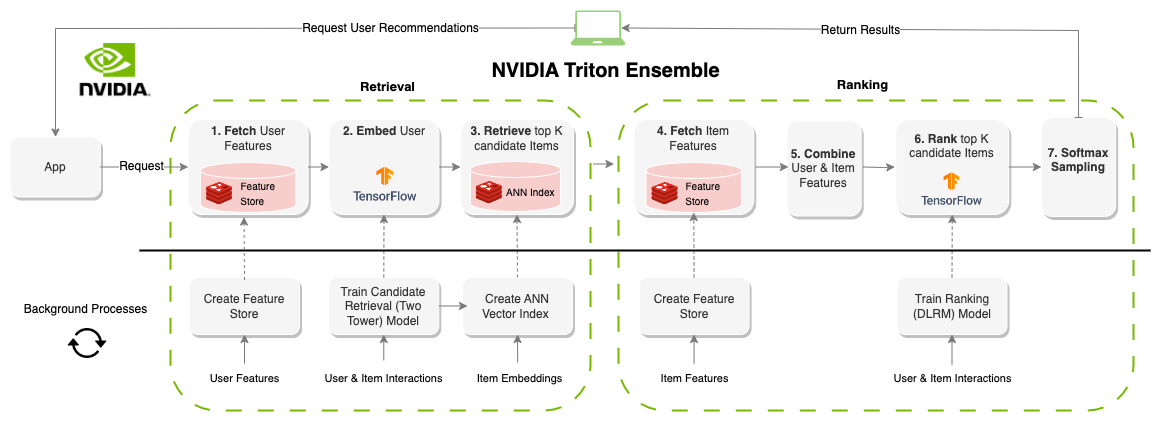
“在線”推薦系統會生成按需建議。與面向批處理的系統相反,在線系統是延遲約束的。在設計這些系統時,提出建議的時間可能是最重要的因素。系統通常限制在100-300ms左右,系統的每個部分都需要有效的組件,而且對數百萬用戶和項目可擴展。與批處理系統相比,創建在線推薦系統的約束要大得多,但是,由於可以實時更新信息(功能),因此結果通常是更好的建議。上圖顯示了此體系結構的示例。
批處理建議的上一個示例生成了此筆記本的模型和數據集,但是您也可以使用AWS CLI下載預培訓的資產如下。
aws s3 cp s3://redisventures/merlin/merlin-recsys-data.zip ./data
要執行筆記本,請運行以下內容
$ cd online-multi-stage-recsys/
$ docker compose up # -d to daemonize本節包含兩個筆記本:一個用於部署功能存儲(REDIS)和創建向量索引(REDIS),另一個用於定義和運行集合模型以運行整個管道(Triton)。
注意:請確保在第二個筆記本電腦之前運行第一個筆記本電腦,否則模型將無法執行。
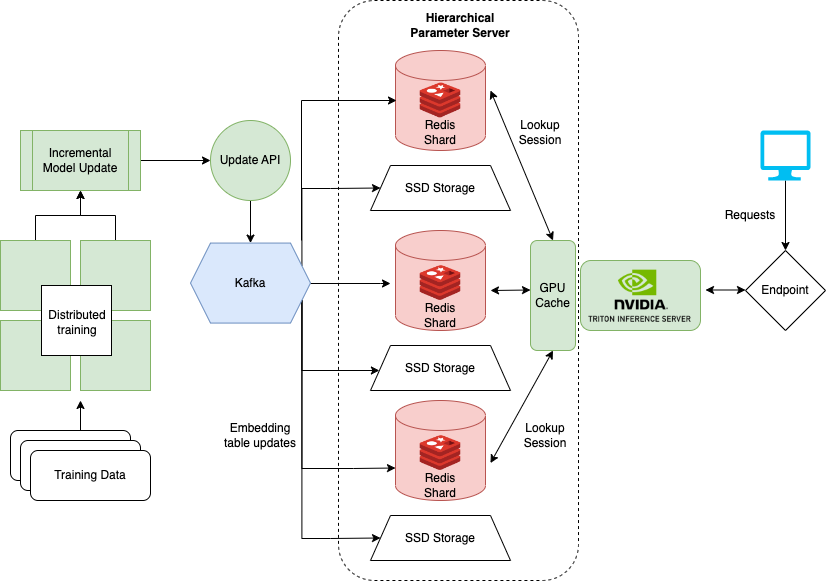
最後一個筆記本電腦顯示瞭如何在訓練DLRM(例如DLRM)進行推薦系統時處理非常大的數據集。大型企業通常有數百萬用戶和項目。模型的整個嵌入式表可能不適合單個GPU。為此,NVIDIA創建了Hugectr框架。
Hugectr是NVIDIA MERLIN框架的一部分,並增加了用於分佈式培訓和推薦模型服務的設施。此處詳細介紹的筆記本重點介紹了Hugectr的部署和服務,並提供了可用於示例的DLRM的預訓練版本。有關與Hugectr分佈式培訓的更多信息,請參見此處。
要執行本地筆記本,請運行以下內容
$ cd large-scale-recsys/
$ docker compose up # -d to daemonize該文件夾包含部署的Terraform腳本和Ansible劇本
全部在Amazon Web服務上。
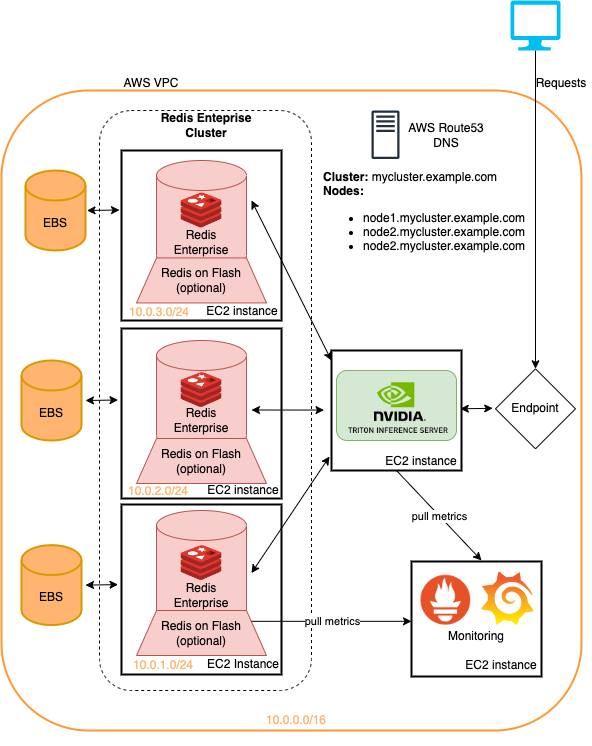
該存儲庫中介紹的示例都可以在地表基礎架構上運行,並且最小的變化。這是一種快速部署此基礎架構的方法,以嘗試此處詳細介紹的建議系統管道。有關更多信息,請參見雲部署中的讀數。
可以通過運行AWS CLI檢索本教程中的模型
aws s3 cp s3://redisventures/merlin/merlin-recsys-data.zip ./data
以下repostories鏈接到文章和筆記本中使用的代碼/資產
此處的筆記本基於許多現有筆記本的工作,例如
我們強烈建議閱讀


