redis nvidia recsys
1.0.0
Ce référentiel contient les actifs qui complètent l'article " Offline to Online: Feature Storage pour les systèmes de recommandation en temps réel avec Nvidia Merlin " Écrit à l'origine pour le blog de développeur NVIDIA.
Nous fournissons des exemples d'architectures de système de recommandation et fournissons des instructions de déploiement de cloud pour l'utilisation de la production. Chacun des exemples s'appuie sur Redis et le cadre Nvidia Merlin qui fournit un certain nombre de blocs de construction pour créer des systèmes de recommandation.
Il y a 3 exemples dans ce référentiel
La grande échelle développe la deuxième architecture pour les cas d'utilisation qui exigent une formation ou une inférence à grande échelle (> 1 GPU).
Chacun des exemples est conçu pour s'exécuter localement sur un système compatible NVIDIA GPU avec Docker et Docker-Compose. Nous vous recommandons d'exécuter tous les éléments suivants sur une instance cloud avec un GPU Nvidia (idéalement le AWS Pytorch Ami)
Cependant, nous fournissons également un ensemble de scripts Terraform et de cahiers anibles qui peuvent déployer l'infrastructure nécessaire pour exécuter les exemples sur les instances AWS.
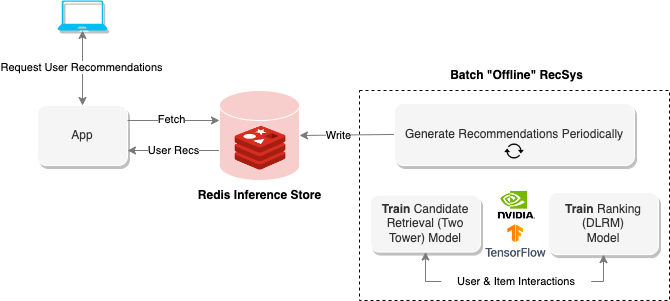
Les systèmes de recommandation "hors ligne" utilisent l'informatique par lots pour traiter de grandes quantités de données, puis les stocker pour une récupération ultérieure. Le diagramme ci-dessus montre un exemple d'un tel système qui utilise une approche à deux points pour générer des recommandations, puis les stocke dans une base de données Redis pour une récupération ultérieure.
Le cahier hors ligne fournit des méthodes pour construire ce type de système de recommandation ainsi que des trains et exportations des modèles nécessaires à l'exécution du système de recommandation en ligne dans la section suivante.
Pour exécuter le cahier, exécutez ce qui suit
$ cd offline-batch-recsys/
$ docker compose up # -d to daemonizeOuvrez ensuite le lien généré par Jupyter dans un navigateur.
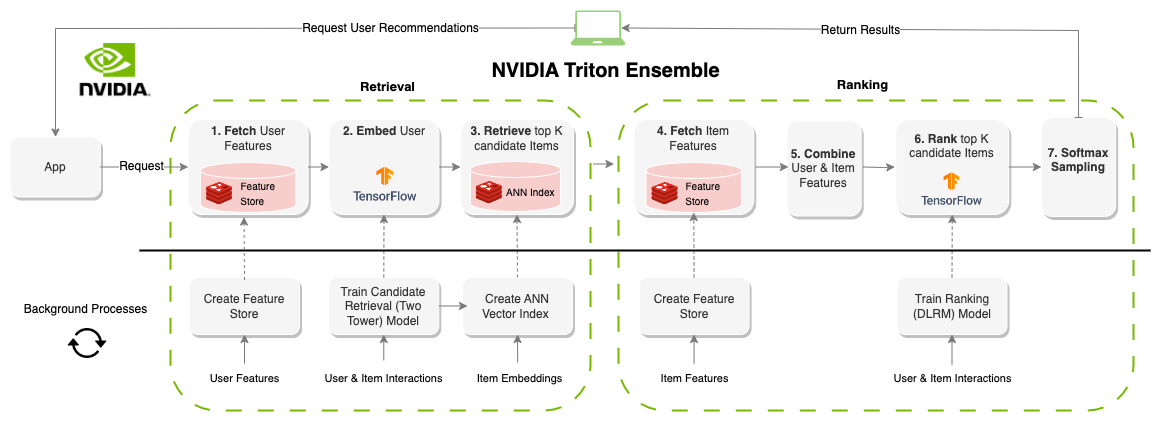
Un système de recommandation "en ligne" génère des recommandations à la demande. Contrairement aux systèmes axés sur les lots, les systèmes en ligne sont liés à la latence. Lors de la conception de ces systèmes, la durée pour produire des recommandations est probablement le facteur le plus important. Courpué autour de 100 à 300 ms, chaque partie du système a besoin de composants qui sont non seulement efficaces mais évolutifs à des millions d'utilisateurs et d'éléments. La création d'un système de recommandation en ligne a beaucoup plus de contraintes que les systèmes de lots, cependant, le résultat est souvent de meilleures recommandations car les informations (fonctionnalités) peuvent être mises à jour en temps réel. Le diagramme ci-dessus montre un exemple de cette architecture.
L'exemple précédent pour les recommandations par lots génère les modèles et les ensembles de données pour ce cahier, mais vous pouvez également télécharger des actifs pré-formés avec l'AWS CLI comme suit
aws s3 cp s3://redisventures/merlin/merlin-recsys-data.zip ./data
Pour exécuter le cahier, exécutez ce qui suit
$ cd online-multi-stage-recsys/
$ docker compose up # -d to daemonizeCette section contient deux ordinateurs portables: un pour le déploiement du magasin de fonctionnalités (redis) et la création de l'index vectoriel (redis) et un autre pour définir et exécuter le modèle d'ensemble pour exécuter l'intégralité du pipeline (Triton).
Remarque: assurez-vous d'exécuter le premier ordinateur portable avant le second ou le modèle ne s'exécutera pas.
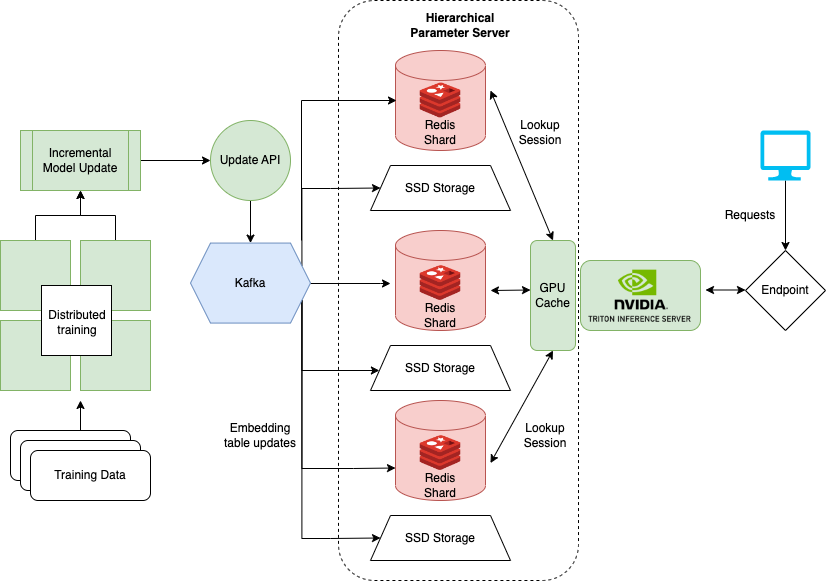
Le dernier cahier qui montre comment gérer de très grands ensembles de données lors de la formation de modèles comme DLRM pour les systèmes de recommandation. Les grandes entreprises comptent souvent des millions d'utilisateurs et d'articles. L'ensemble du tableau d'intégration d'un modèle peut ne pas tenir sur un seul GPU. Pour cela, NVIDIA a créé le Framework Hugecct.
Hugectr fait partie d'un cadre Nvidia Merlin et ajoute des installations pour la formation distribuée et le service de modèles de recommandation. Le cahier détaillé ici se concentre sur le déploiement et la portion de Hugectr et fournit une version pré-formée de DLRM qui peut être utilisée pour l'exemple. Plus d'informations sur la formation distribuée avec Hugectrage peuvent être trouvées ici.
Pour exécuter le cahier local, exécutez ce qui suit
$ cd large-scale-recsys/
$ docker compose up # -d to daemonizeCe dossier comprend des scripts Terraform et des livres de jeu anibles qui déploient
Tous sur Amazon Web Services.
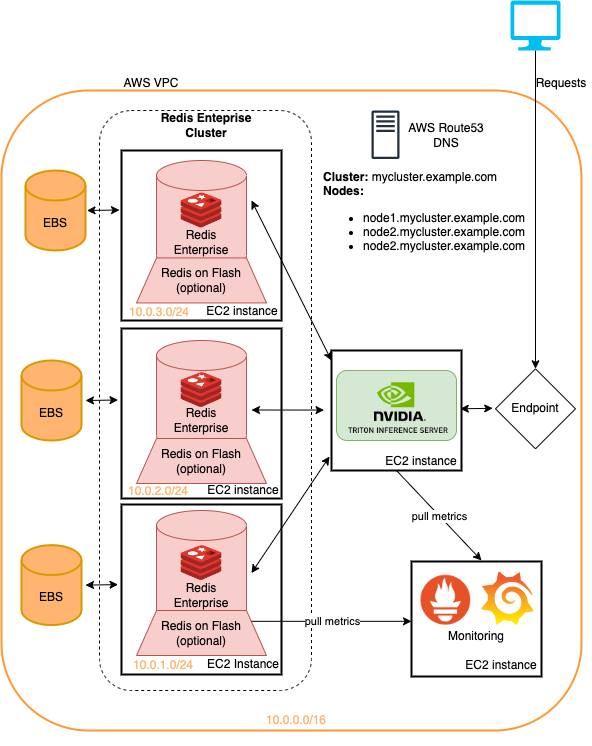
Les exemples présentés dans ce référentiel peuvent tous être exécutés sur l'infrastructure terraformée avec un minimum de changements. Il s'agit d'une méthode rapide pour déployer cette infrastructure pour essayer les pipelines du système de recommandation détaillées ici. Voir le ReadMe dans le déploiement du cloud pour en savoir plus.
Les modèles de ce tutoriel peuvent être récupérés avec la CLI AWS en fonctionnant
aws s3 cp s3://redisventures/merlin/merlin-recsys-data.zip ./data
Le lien des repostoires suivants vers le code / les actifs utilisés dans les articles et les cahiers
Les cahiers ici s'appuient sur le travail de nombreux cahiers préexistants tels que
Nous recommandons fortement la lecture


