redis nvidia recsys
1.0.0
Este repositório detém os ativos que complementam o artigo " Offline ao online: armazenamento de recursos para sistemas de recomendação em tempo real com a NVIDIA Merlin " escrita originalmente para o blog de desenvolvedores da NVIDIA.
Fornecemos exemplos de arquiteturas do sistema de recomendação e fornecemos instruções de implantação em nuvem para uso da produção. Cada um dos exemplos depende da Redis e da NVIDIA Merlin Framework, que fornece vários blocos de construção para criar sistemas de recomendação.
Existem 3 exemplos neste repositório
A grande escala expande a segunda arquitetura para casos de uso que exigem treinamento ou inferência em larga escala (> 1 GPU).
Cada um dos exemplos é projetado para ser executado localmente em um sistema habilitado para GPU da NVIDIA com o Docker e o Docker-Compose. Recomendamos a execução de todos os seguintes em uma instância em nuvem com uma GPU da NVIDIA (idealmente o AWS Pytorch AMI)
No entanto, também fornecemos um conjunto de scripts da Terraform e notebooks Ansible que podem implantar a infraestrutura necessária para executar os exemplos nas instâncias da AWS.
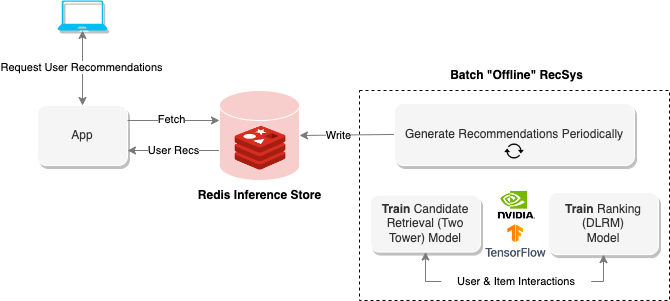
Os sistemas de recomendação "offline" usam a computação em lote para processar grandes quantidades de dados e, em seguida, armazená -los para recuperação posterior. O diagrama acima mostra um exemplo desse sistema que usa uma abordagem de duas torres para gerar recomendações e depois as armazena dentro de um banco de dados Redis para recuperação posterior.
O notebook offline fornece métodos para criar esse tipo de sistema de recomendação, bem como trens e exporta os modelos necessários para a execução do sistema de recomendação on -line na seção a seguir.
Para executar o notebook, execute o seguinte
$ cd offline-batch-recsys/
$ docker compose up # -d to daemonizeEm seguida, abra o link gerado por Jupyter em um navegador.
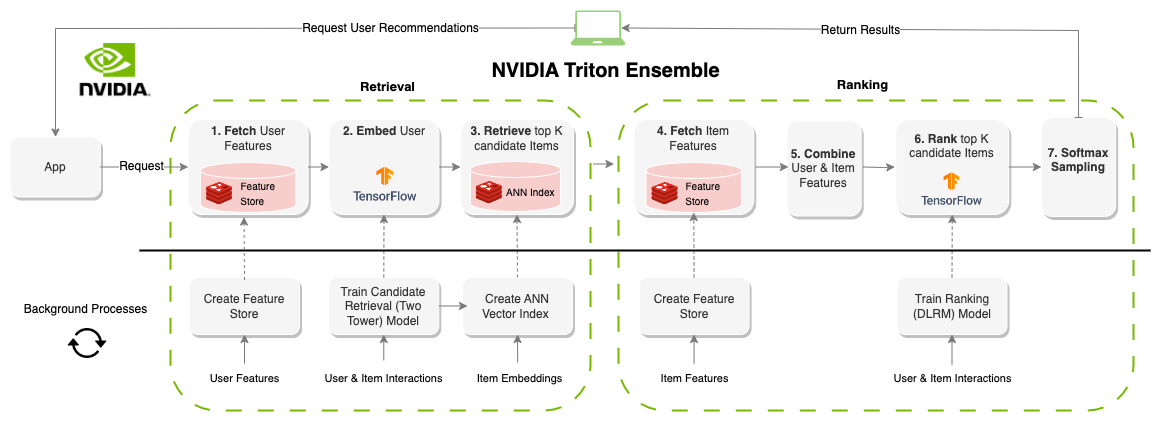
Um sistema de recomendação "online" gera recomendações sob demanda. Ao contrário dos sistemas orientados a lotes, os sistemas on-line são restritos à latência. Ao projetar esses sistemas, a quantidade de tempo para produzir recomendações é provavelmente o fator mais importante. Geralmente limitado em torno de 100-300ms, cada parte do sistema precisa de componentes que não são apenas eficientes, mas escaláveis para milhões de usuários e itens. Criar um sistema de recomendação on-line tem significativamente mais restrições do que os sistemas em lote; no entanto, o resultado geralmente é melhor recomendações, pois as informações (recursos) podem ser atualizadas em tempo real. O diagrama acima mostra um exemplo dessa arquitetura.
O exemplo anterior para recomendações em lote gera os modelos e conjuntos de dados para este notebook, mas você também pode baixar ativos pré-treinados com a AWS CLI da seguinte forma
aws s3 cp s3://redisventures/merlin/merlin-recsys-data.zip ./data
Para executar o notebook, execute o seguinte
$ cd online-multi-stage-recsys/
$ docker compose up # -d to daemonizeEsta seção contém dois notebooks: um para implantar o Store de Recursos (Redis) e criar o Índice de Vector (Redis) e outro para definir e executar o modelo de conjunto para executar todo o pipeline (Triton).
Nota: Certifique -se de executar o primeiro notebook antes do segundo ou o modelo não será executado.
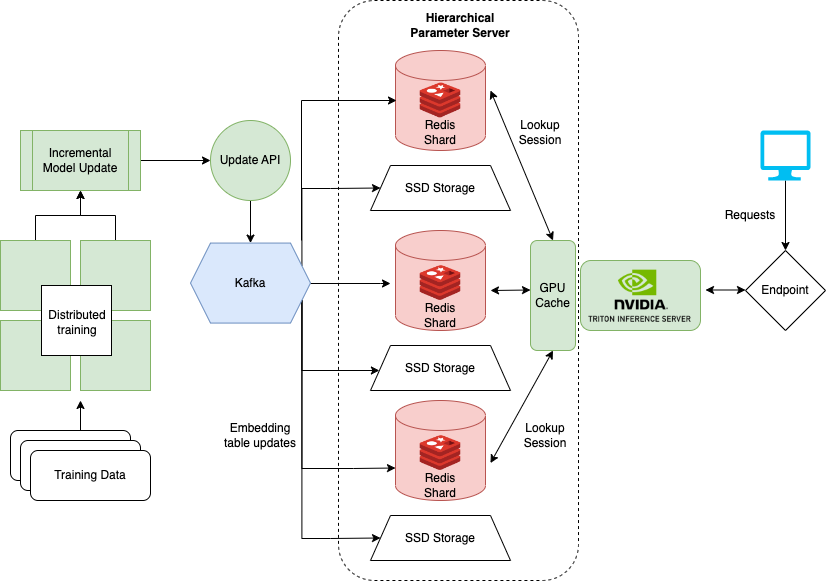
O último caderno que mostra como lidar com conjuntos de dados muito grandes ao treinar modelos como o DLRM para sistemas de recomendação. As grandes empresas geralmente têm milhões de usuários e itens. Toda a tabela de incorporação de um modelo pode não se encaixar em uma única GPU. Para isso, a NVIDIA criou a estrutura do Hugect.
A Hugect faz parte de uma estrutura Nvidia Merlin e adiciona instalações para treinamento distribuído e porção de modelos de recomendação. O caderno detalhado aqui se concentra na implantação e em servir do Hugectr e fornece uma versão pré-treinada do DLRM que pode ser usada para o exemplo. Mais informações sobre o treinamento distribuído com o Hugectr podem ser encontradas aqui.
Para executar o caderno local, execute o seguinte
$ cd large-scale-recsys/
$ docker compose up # -d to daemonizeEsta pasta inclui scripts do Terraform e manuais de Ansible que implantam
Tudo no Amazon Web Services.
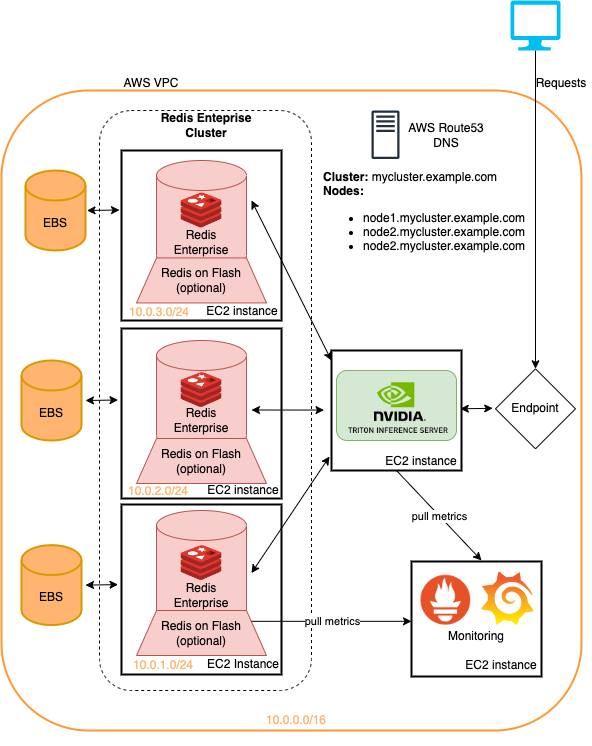
Os exemplos apresentados neste repositório podem ser executados na infraestrutura terrestre com alterações mínimas. Este é um método rápido para implantar essa infraestrutura para experimentar os pipelines do sistema de recomendação detalhados aqui. Veja o ReadMe dentro do implantação da nuvem para obter mais.
Os modelos deste tutorial podem ser recuperados com a CLI da AWS executando
aws s3 cp s3://redisventures/merlin/merlin-recsys-data.zip ./data
Os seguintes repostóricos vinculam para código/ativo usado em artigos e notebooks
Os notebooks aqui se baseiam no trabalho de muitos notebooks pré-existentes, como
Recomendamos a leitura


