redis nvidia recsys
1.0.0
该存储库的资产是补充“离线到Online:使用Nvidia Merlin的实时推荐系统的功能存储”的资产,最初是为Nvidia Developer Blog编写的。
我们提供推荐系统体系结构的示例,并为生产使用提供云部署说明。每个示例都取决于Redis和Nvidia Merlin框架,该框架提供了许多用于创建推荐系统的构建块。
此存储库中有3个示例
大规模扩展了第二个需要大规模(> 1 GPU)培训或推理的用例的体系结构。
每个示例均设计为在启用docker和docker-compose的NVIDIA GPU系统上本地运行。我们建议使用NVIDIA GPU在云实例上执行所有以下内容(理想情况下是AWS Pytorch AMI)
但是,我们还提供了一组Terraform脚本和可安装的笔记本,这些脚本可以部署在AWS实例上执行示例所需的基础架构。
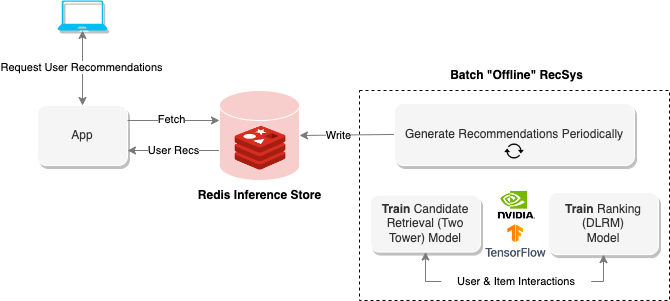
“离线”推荐系统使用批处理计算来处理大量数据,然后存储它们以备以后检索。上图显示了这样一个系统的示例,该系统使用两塔方法生成建议,然后将其存储在Redis数据库中以进行以后的检索。
离线笔记本电脑提供了建立此类推荐系统的方法,并在以下部分中导出了运行在线推荐系统所需的模型。
要执行笔记本,请运行以下内容
$ cd offline-batch-recsys/
$ docker compose up # -d to daemonize然后打开Jupyter在浏览器中生成的链接。
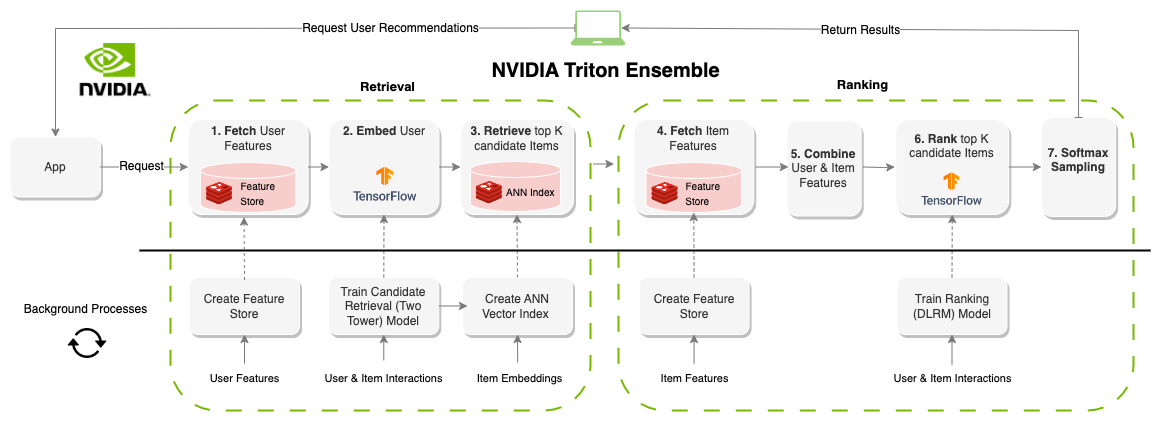
“在线”推荐系统会生成按需建议。与面向批处理的系统相反,在线系统是延迟约束的。在设计这些系统时,提出建议的时间可能是最重要的因素。系统通常限制在100-300ms左右,系统的每个部分都需要有效的组件,而且对数百万用户和项目可扩展。与批处理系统相比,创建在线推荐系统的约束要大得多,但是,由于可以实时更新信息(功能),因此结果通常是更好的建议。上图显示了此体系结构的示例。
批处理建议的上一个示例生成了此笔记本的模型和数据集,但是您也可以使用AWS CLI下载预培训的资产如下。
aws s3 cp s3://redisventures/merlin/merlin-recsys-data.zip ./data
要执行笔记本,请运行以下内容
$ cd online-multi-stage-recsys/
$ docker compose up # -d to daemonize本节包含两个笔记本:一个用于部署功能存储(REDIS)和创建向量索引(REDIS),另一个用于定义和运行集合模型以运行整个管道(Triton)。
注意:请确保在第二个笔记本电脑之前运行第一个笔记本电脑,否则模型将无法执行。
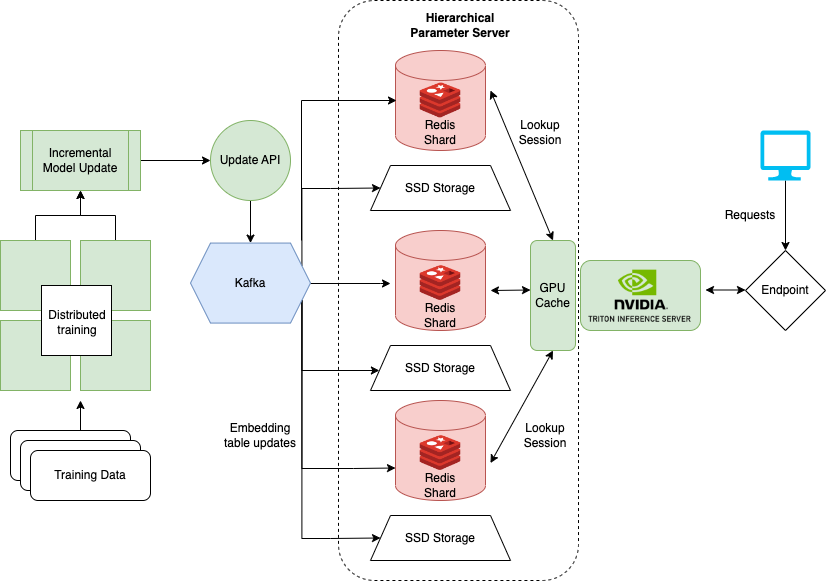
最后一个笔记本电脑显示了如何在训练DLRM(例如DLRM)进行推荐系统时处理非常大的数据集。大型企业通常有数百万用户和项目。模型的整个嵌入式表可能不适合单个GPU。为此,NVIDIA创建了Hugectr框架。
Hugectr是NVIDIA MERLIN框架的一部分,并增加了用于分布式培训和推荐模型服务的设施。此处详细介绍的笔记本重点介绍了Hugectr的部署和服务,并提供了可用于示例的DLRM的预训练版本。有关与Hugectr分布式培训的更多信息,请参见此处。
要执行本地笔记本,请运行以下内容
$ cd large-scale-recsys/
$ docker compose up # -d to daemonize该文件夹包含部署的Terraform脚本和Ansible剧本
全部在Amazon Web服务上。
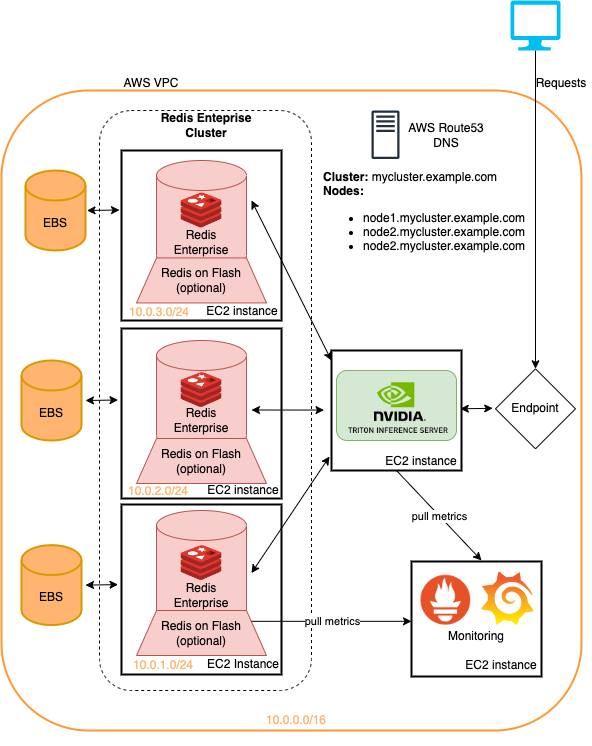
该存储库中介绍的示例都可以在地表基础架构上运行,并且最小的变化。这是一种快速部署此基础架构的方法,以尝试此处详细介绍的建议系统管道。有关更多信息,请参见云部署中的读数。
可以通过运行AWS CLI检索本教程中的模型
aws s3 cp s3://redisventures/merlin/merlin-recsys-data.zip ./data
以下repostories链接到文章和笔记本中使用的代码/资产
此处的笔记本基于许多现有笔记本的工作,例如
我们强烈建议阅读


