redis nvidia recsys
1.0.0
Dieses Repository enthält die Vermögenswerte, die den Artikel " Offline to Online: Feature-Speicher für Echtzeit-Empfehlungssysteme mit NVIDIA Merlin " ergänzen, die ursprünglich für den NVIDIA Developer-Blog geschrieben wurden.
Wir geben Beispiele für Empfehlungssystemarchitekturen und bieten Cloud -Bereitstellungsanweisungen für die Produktionsnutzung an. Jedes der Beispiele stützt sich auf Redis und den Nvidia Merlin -Framework, das eine Reihe von Bausteinen zum Erstellen von Empfehlungssystemen bietet.
Es gibt 3 Beispiele in diesem Repository
Der große Maßstab erweitert die zweite Architektur für Anwendungsfälle, in denen ein großes (> 1 GPU) Training oder Inferenz benötigt wird.
Jedes der Beispiele ist so konzipiert, dass sie lokal auf einem NVIDIA-GPU-fähigen System mit Docker und Docker-Compose ausgeführt werden. Wir empfehlen, alle Folgenden in einer Cloud -Instanz mit einer NVIDIA -GPU (idealerweise The AWS Pytorch AMI) auszuführen.
Wir bieten jedoch auch eine Reihe von Terraformskripten und Ansible -Notebooks, mit denen die Infrastruktur bereitgestellt werden kann, die zur Ausführung der Beispiele zu AWS -Instanzen erforderlich ist.
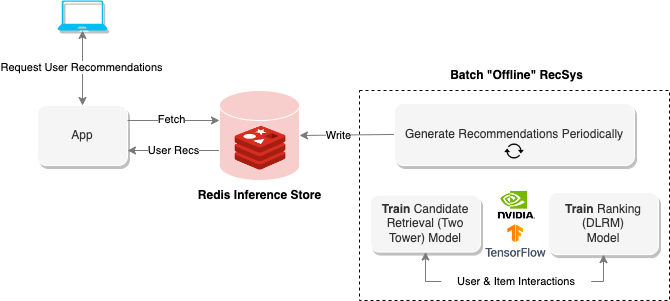
Empfehlungssysteme "Offline" verwenden Batch Computing, um große Datenmengen zu verarbeiten und sie dann für das spätere Abrufen zu speichern. Das obige Diagramm zeigt ein Beispiel für ein solches System, das einen Zwei-Turm-Ansatz verwendet, um Empfehlungen zu erzeugen und sie dann in einer Redis-Datenbank für ein späteres Abrufen zu speichern.
Das Offline -Notizbuch bietet Methoden zum Aufbau dieser Art von Empfehlungssystem sowie Züge und exportiert die Modelle, die für die Ausführung des Online -Empfehlungssystems im folgenden Abschnitt erforderlich sind.
Führen Sie Folgendes aus, um das Notizbuch auszuführen, um Folgendes auszuführen
$ cd offline-batch-recsys/
$ docker compose up # -d to daemonizeÖffnen Sie dann den von Jupyter in einem Browser generierten Link.
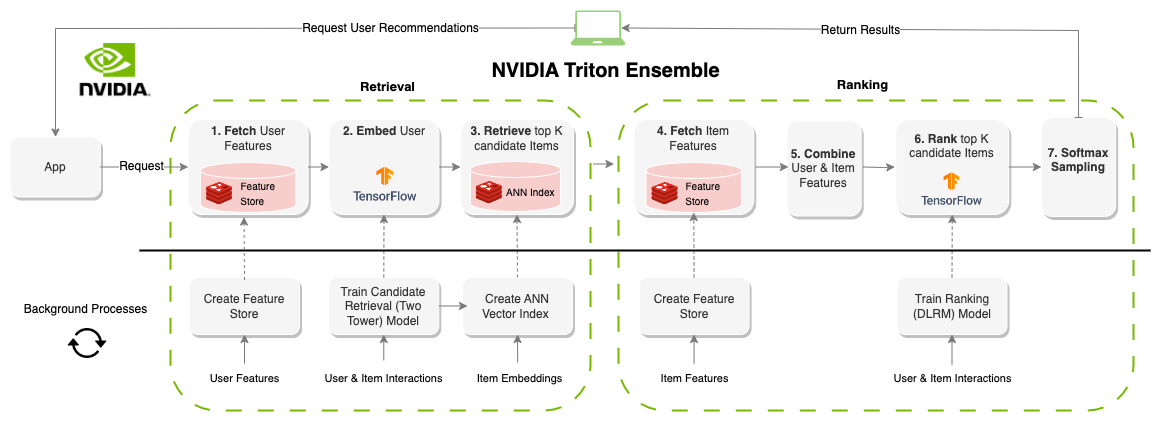
Ein "Online" -Erempfehlungssystem generiert Empfehlungen on-Demand. Im Gegensatz zu batchorientierten Systemen sind Online-Systeme mit Latenz und begrenzt. Bei der Gestaltung dieser Systeme ist die Zeitspanne für die Erstellung von Empfehlungen wahrscheinlich der wichtigste Faktor. Jeder Teil des Systems wird üblicherweise um 100-300 ms eingedeckt und benötigt Komponenten, die nicht nur effizient, sondern auch für Millionen von Benutzern und Elementen skalierbar sind. Das Erstellen eines Online-Empfehlungssystems hat wesentlich mehr Einschränkungen als Batch-Systeme. Das Ergebnis ist jedoch häufig bessere Empfehlungen, da in Echtzeit aktualisiert werden kann. Das obige Diagramm zeigt ein Beispiel für diese Architektur.
Das vorherige Beispiel für Batch-Empfehlungen generiert die Modelle und Datensätze für dieses Notebook
aws s3 cp s3://redisventures/merlin/merlin-recsys-data.zip ./data
Führen Sie Folgendes aus, um das Notizbuch auszuführen, um Folgendes auszuführen
$ cd online-multi-stage-recsys/
$ docker compose up # -d to daemonizeDieser Abschnitt enthält zwei Notizbücher: eine für die Bereitstellung des Feature Store (REDIS) und zum Erstellen des Vector Index (REDIS) und eines zum Definieren und Ausführen des Ensemble -Modells, um die gesamte Pipeline (Triton) auszuführen.
Hinweis: Stellen Sie sicher, dass Sie das erste Notizbuch vor dem zweiten ausführen oder das Modell wird nicht ausgeführt.
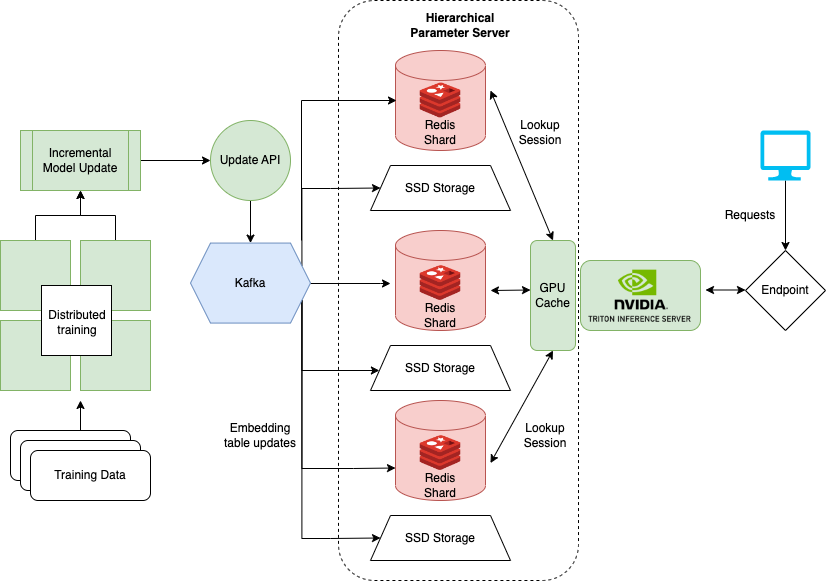
Das letzte Notizbuch, das zeigt, wie Sie mit sehr großen Datensätzen umgehen, wenn Trainingsmodelle wie DLRM für Empfehlungssysteme. Große Unternehmen haben oft Millionen von Benutzern und Elementen. Die gesamte Einbettungstabelle eines Modells passt möglicherweise nicht auf eine einzelne GPU. Dafür erstellte Nvidia das Übersichts -Framework.
Hugecr ist Teil eines Nvidia Merlin -Frameworks und fügt Einrichtungen für verteilte Schulungen und Servierungen von Empfehlungsmodellen hinzu. Das hier beschriebene Notizbuch konzentriert sich auf die Bereitstellung und das Servieren von Übersicht und bietet eine vorgebildete Version von DLRM, die für das Beispiel verwendet werden kann. Weitere Informationen zum verteilten Training mit Übersicht finden Sie hier.
Führen Sie Folgendes aus, um das lokale Notizbuch auszuführen
$ cd large-scale-recsys/
$ docker compose up # -d to daemonizeDieser Ordner enthält Terraformskripte und ansible Playbooks, die bereitgestellt werden
Alles auf Amazon Web Services.
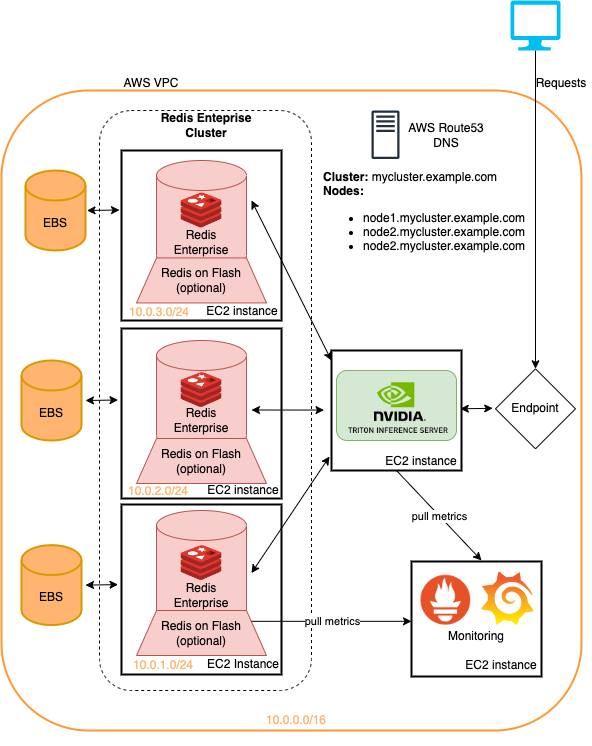
Die in diesem Repository vorgestellten Beispiele können alle auf der terraformierten Infrastruktur mit minimalen Änderungen durchgeführt werden. Dies ist eine schnelle Methode, um diese Infrastruktur bereitzustellen, um die hier detaillierten Empfehlungssystemepipelines auszuprobieren. Weitere weitere Informationen finden Sie in der Readme im Cloud-Deployment.
Die Modelle in diesem Tutorial können mit der AWS CLI durch Laufen abgerufen werden
aws s3 cp s3://redisventures/merlin/merlin-recsys-data.zip ./data
Der folgende Repostories -Link zu Code/Assets, die in Artikeln und Notizbüchern verwendet werden
Die Notizbücher hier bauen auf der Arbeit vieler bereits bestehender Notizbücher wie auf
Wir empfehlen sehr


