r_rational
1.0.0
這是純文本org模式中r/有理subreddit中所有帖子的存檔。
我個人使用它在整個Subreddit上進行快速的,離線的全文搜索。
Reddit不會乾淨地映射到組織模式,因此我對更改用於創建ORG模式文件的模板的想法開放。
GitHub將ORG標題呈現為HTML標題,這對這些根本不起作用。使用ORG模式查看器查看文件,或者只是將其作為普通文本打開。
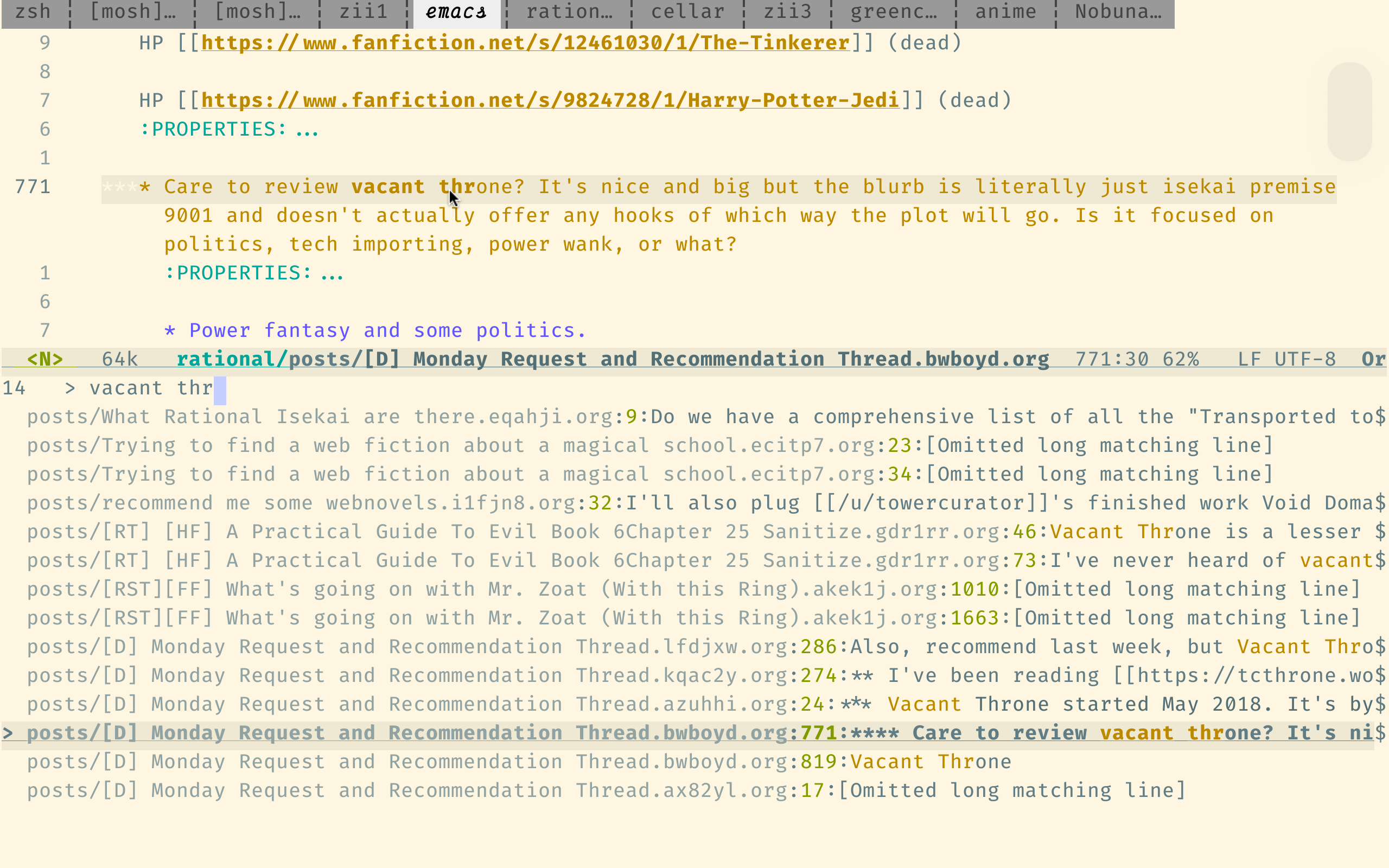
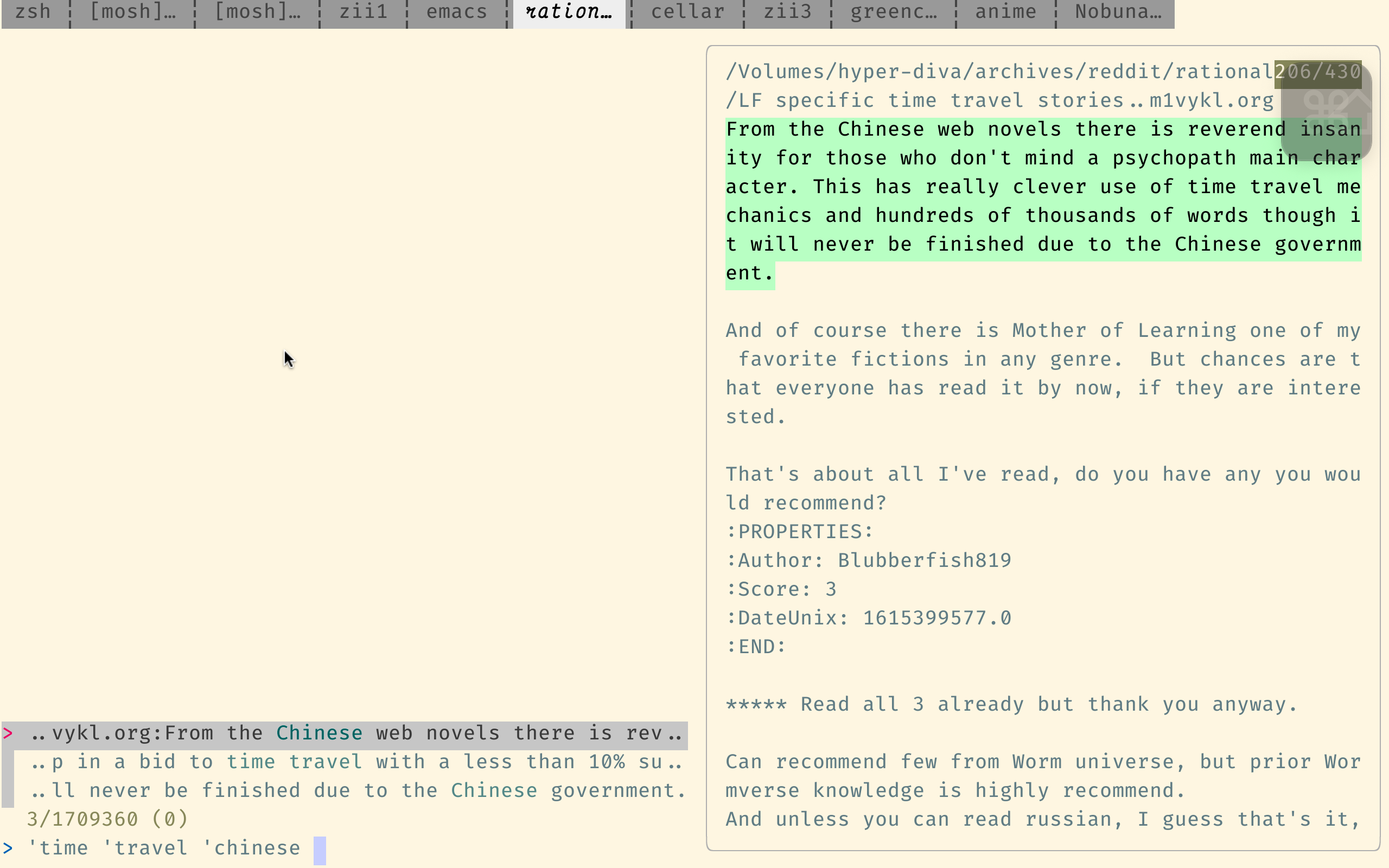
該搜索引擎已針對搜索代碼進行了優化,因此它不太適合我們的目的,但它仍然比Reddit自己的搜索要好得多。
這是SourceGraph的查詢語法。重要的一點是,它支持正則表達式,並假設單詞以正確的順序為順序,除非您使用japanese AND horror等布爾操作員。
請注意,上面的鏈接在indices目錄中搜索,其中每個文件僅包含一個註釋。這通常就是您想要的。 (這只是缺點是找到圍繞找到結果的評論很乏味。)要搜索每個提交(而不是每個註釋),請使用此鏈接,該鏈接改為搜索posts目錄。
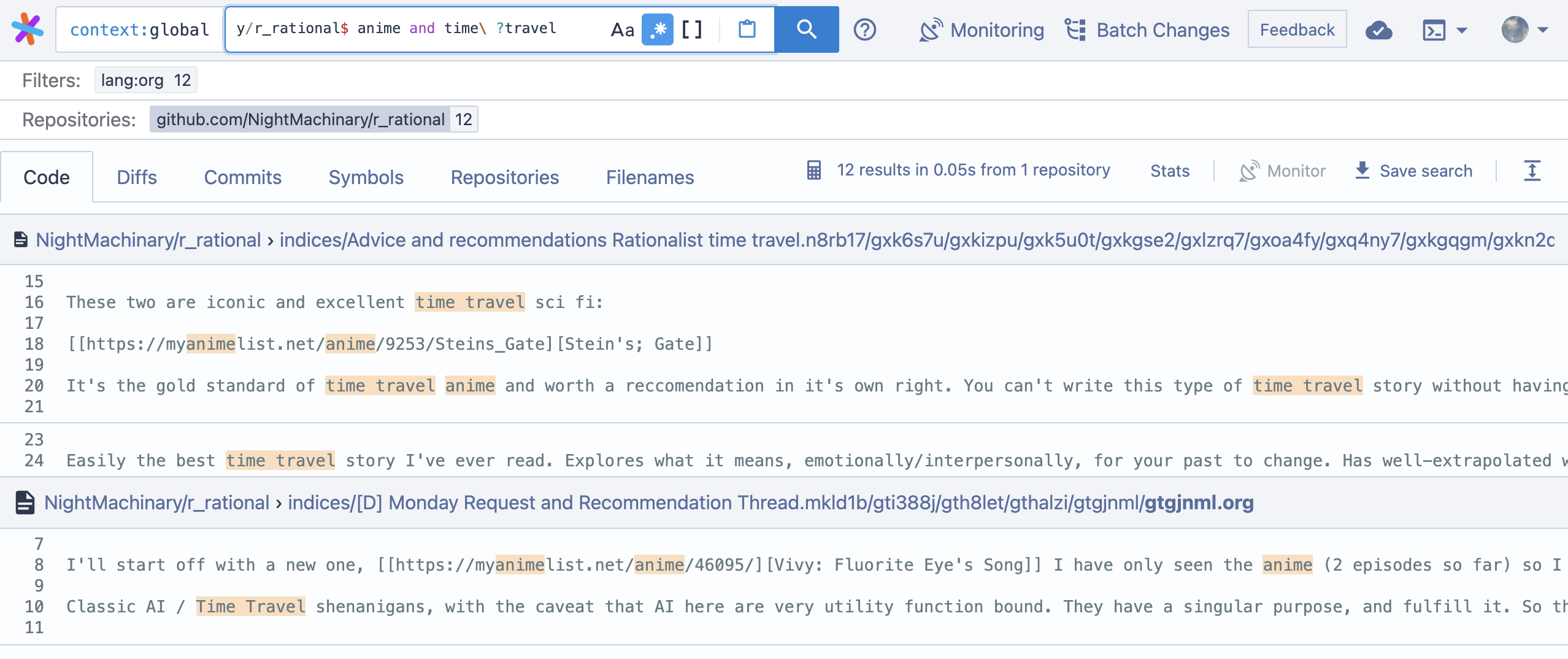
ugrep搜索安裝github -genivia/ugrep:?新的ugrep v3.3:超快速的互動que…by,例如,例如,
釀造ugrep安裝
現在將此功能粘貼到您的外殼中:
UGC(){
UGREP - 頭 - 彩色=始終-pretty -pontext = 3-回复 - bool-smart-case' - sort = best' - no-confirm ---no-confirm - perl-regexp -hidden' - hidden' - binary' - binary-files = noter-match'noth-match'少-n
}
現在您可以做:
git克隆 - 恢復https://github.com/nightmachinary/r_rational CD r_rational/帖子
UGC“日本恐怖”
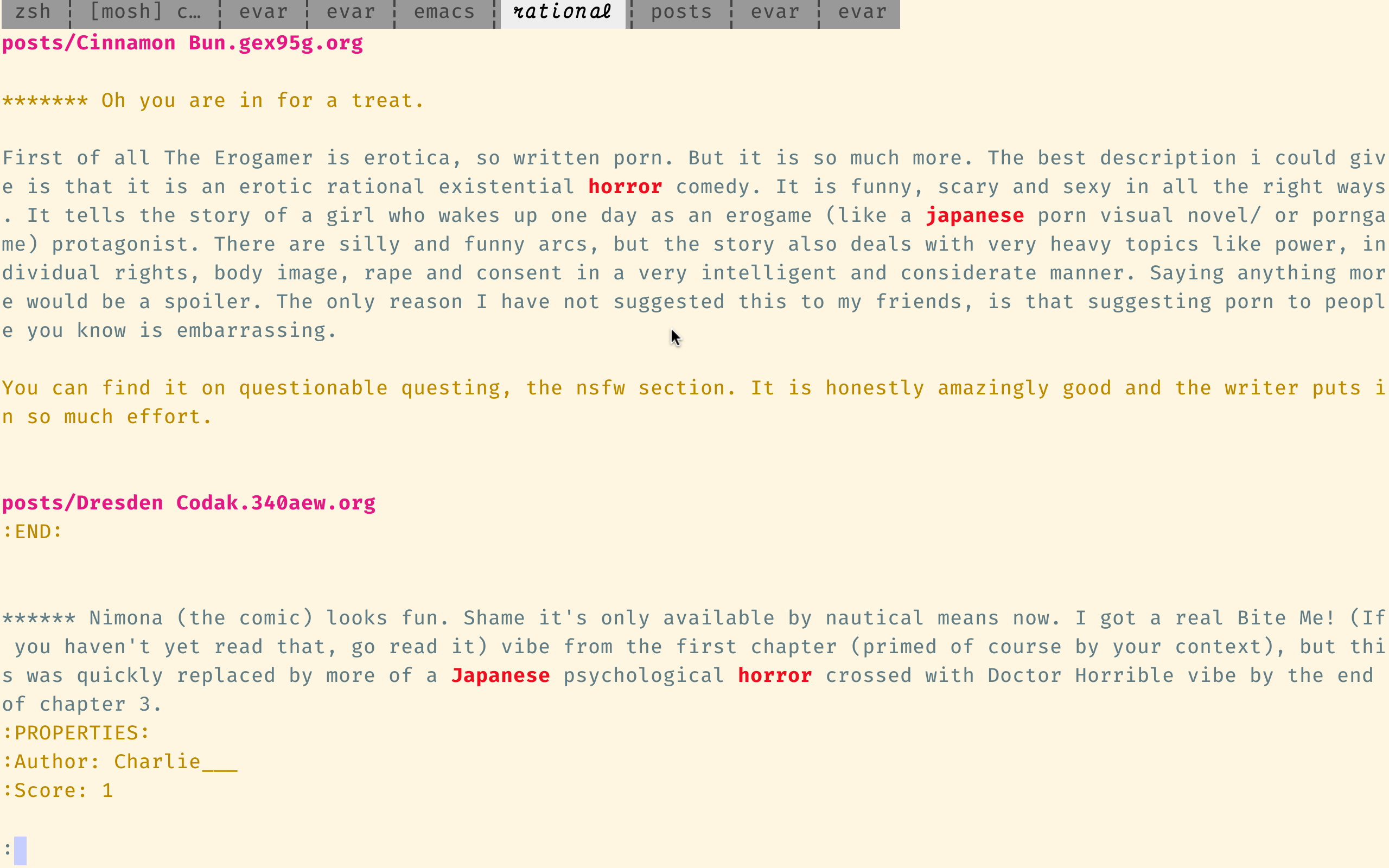
ugrep還支持交互式的增量搜索模式:
功能UGCI {
local r =“ $ {@[ - 1]}” opts =(“ $ {@[1,-2]}”)
UGREP - 頭 - 彩色=始終 - pretty--context = 3-恢復-bool -bool -smart-case' - sort = best' - no-confirm - no-confirm - perl-regexp -hidden' - hidden' - hidden' - binard' - binard' - binard' - binary' - binary' - binary'' - bonefiles = noth-match'noth-match'
}
UGCI“日本恐怖”
indices降低存儲成本該目錄將每個註釋保存到一個文件中,該文件對4KB的塊大小的現代OS效率非常低。如果您不使用這些文件,則將其刪除將大量減少此存儲庫的大小(在撰寫本文時, posts目錄僅為163MB)。您還可以刪除.git目錄,但是然後您將無法訪問git功能,例如提取新更新。
實現此目的的最簡單方法是使用搜索和重新定位工具(例如MS-JPQ/SAD:)從數據中刪除作者名稱:
fd。 |悲傷的' s*:作者:。 *''' fd。 |悲傷的'u/ s+''u/redacted'
此存儲庫是使用此腳本創建的,該腳本需要一些重構才能與我的環境分離。
我計劃將新帖子添加到SubredDit中,以保持回購的最新狀態。


