r_rational
1.0.0
이것은 평범한 텍스트 조직 모드의 R/Rational Subreddit의 모든 게시물의 아카이브입니다.
나는 개인적으로 그것을 사용하여 전체 하위 구역에서 빠른 오프라인 전체 텍스트 검색을 수행합니다.
Reddit은 Org-Mode에 깨끗하게 매핑되지 않으므로 Org-Mode 파일을 만드는 데 사용되는 템플릿 변경에 대한 아이디어에 열려 있습니다.
Github는 조직 제목을 HTML 헤더로 렌더링합니다. Org-Mode Viewer를 사용하여 파일을 보거나 일반 텍스트로 열 수 있습니다.
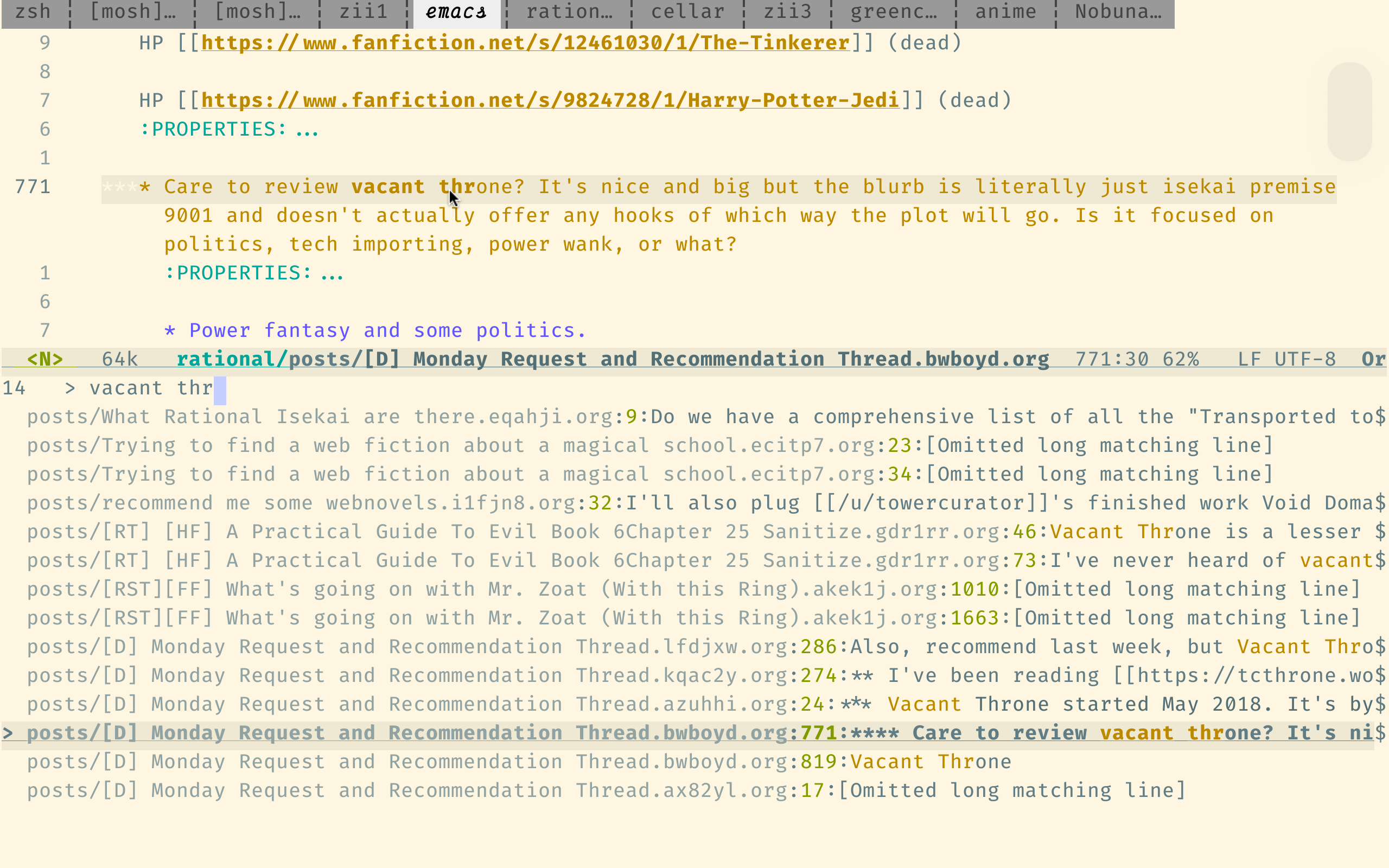
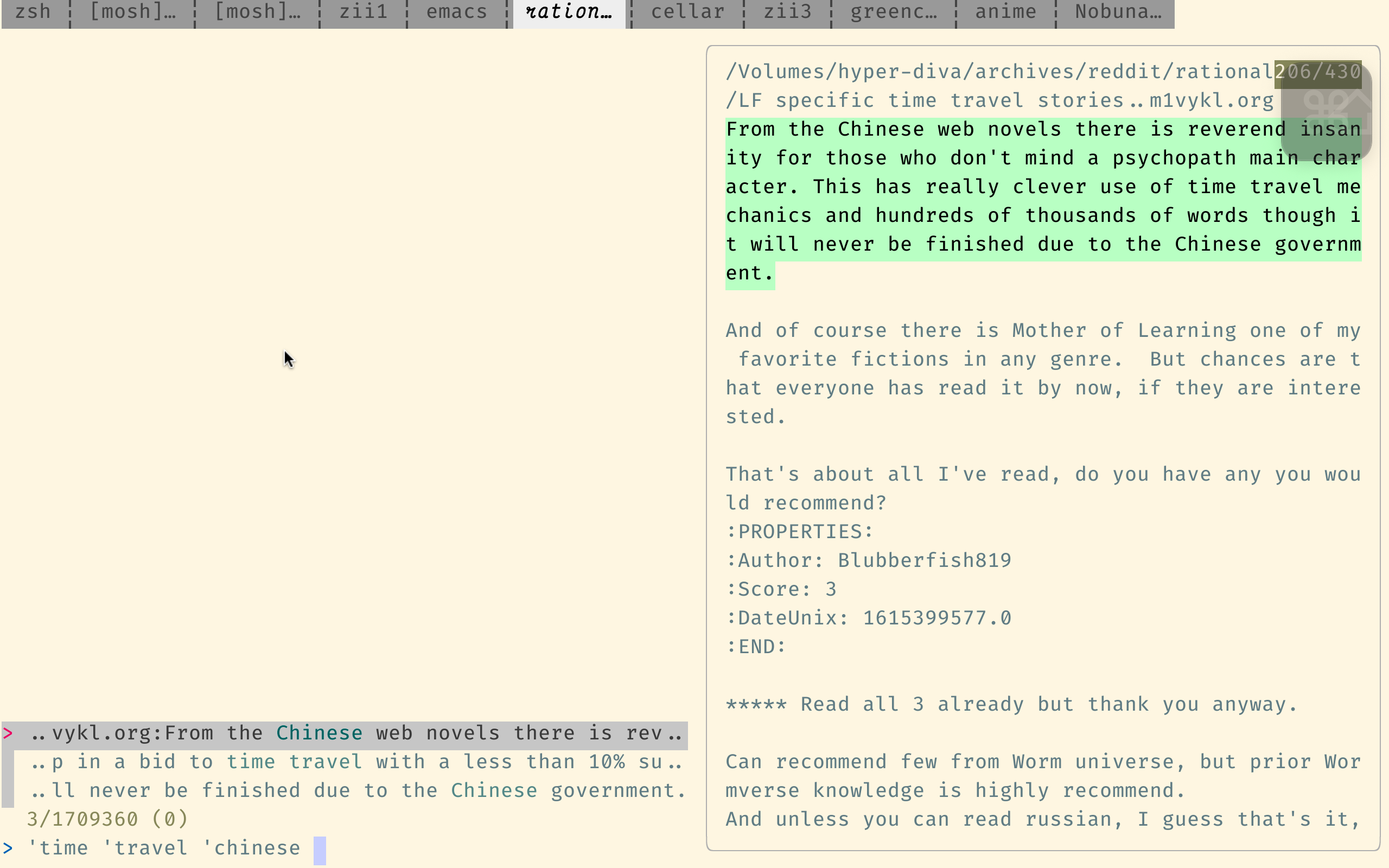
이 검색 엔진은 검색 코드에 최적화되었으므로 목적에 너무 적합하지는 않지만 여전히 Reddit의 자체 검색보다 훨씬 낫습니다.
다음은 SourceGraph의 쿼리 구문입니다. 중요한 점은 정규 표현을 지원하고 japanese AND horror 와 같은 부울 연산자를 사용하지 않는 한 단어가 올바른 순서라고 가정한다는 것입니다.
위의 링크는 indices 디렉토리에서 검색합니다. 각 파일에는 단일 주석 만 포함되어 있습니다. 이것은 보통 당신이 원하는 것입니다. (발견 된 결과에 대한 주석을 찾는 것이 지루하다는 것은 단지입니다.) 제출자 당 검색 (주석 대신)를 사용 하여이 링크를 사용하여 posts 디렉토리를 검색합니다.
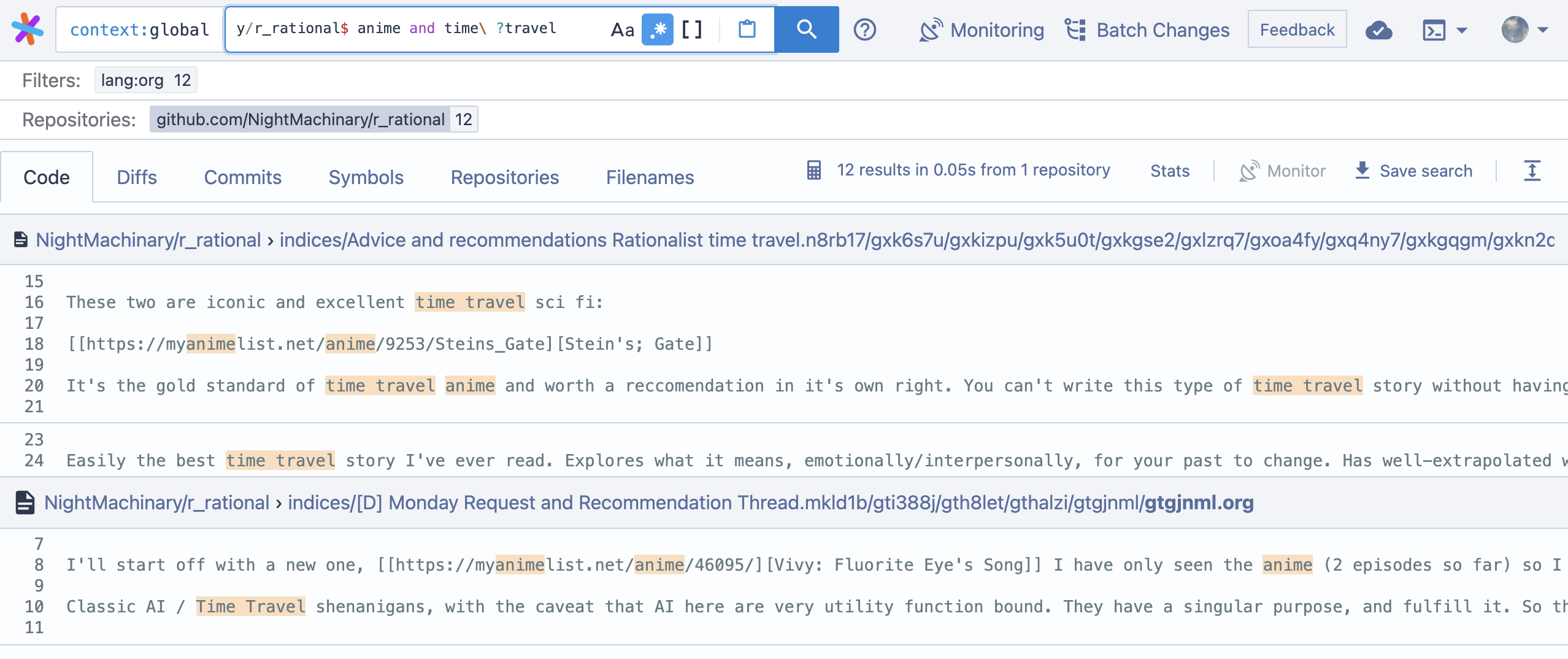
ugrep 통해 검색Github -Github -Genivia/Ugrep :? New Ugrep v3.3 : 대화식 que와 함께 Ultra Fast Grep…
Brew install ugrep
이제이 기능을 쉘에 붙여 넣습니다.
ugc () {
ugrep-heading-color = always always-pretty --context = 3-수용--bool --- bool--smart-case '---sort = best'-no-confirm --perl-regexp-hidden '--- binary-files = match' ""$@"| 덜 -n
}
이제 할 수 있습니다 :
Git Clone -recursive https://github.com/nightmachinary/r_rational CD r_rational/게시물
UGC '일본 공포'
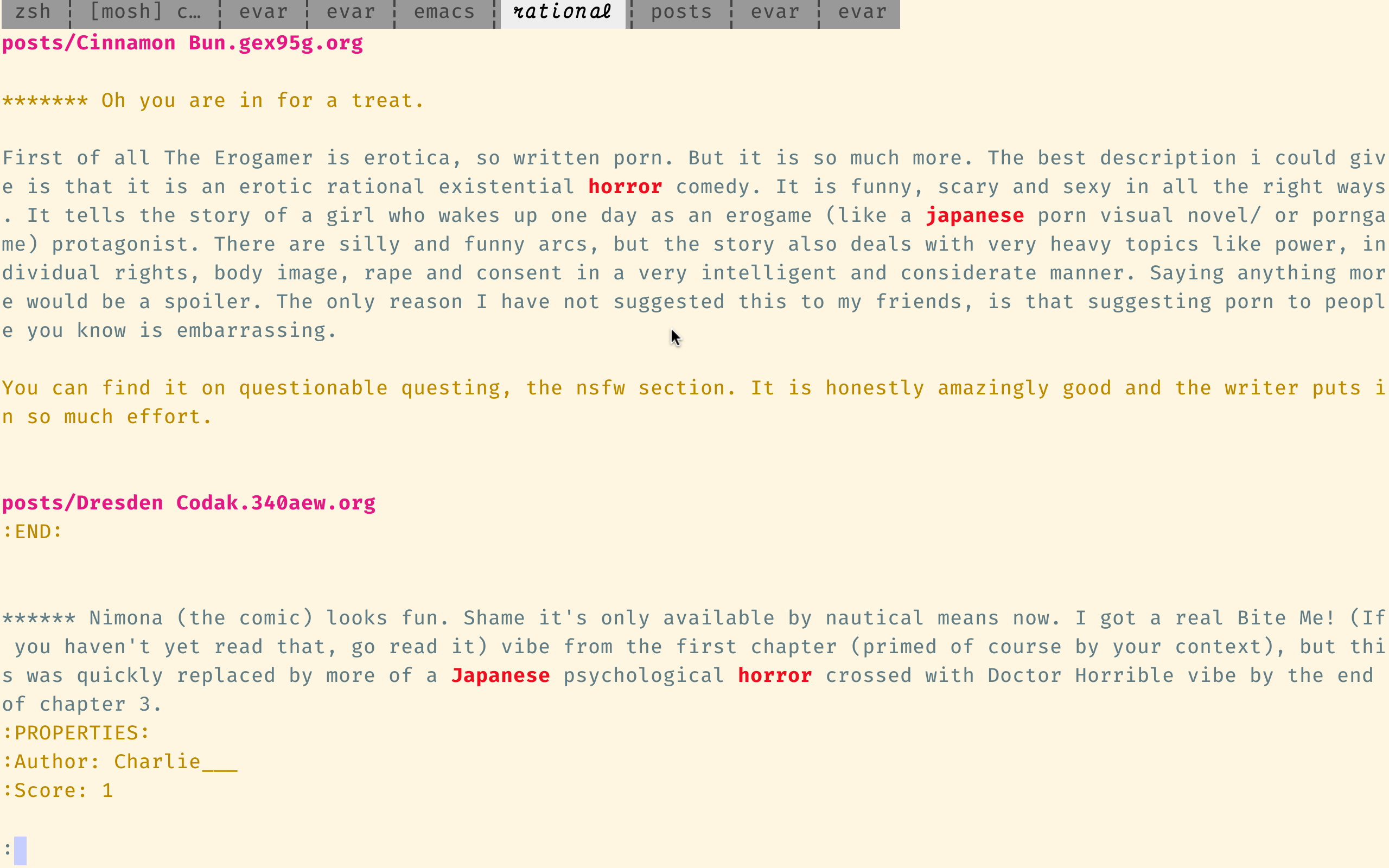
ugrep 또한 대화식, 증분 검색 모드를 지원합니다.
함수 ugci {
로컬 r = "$ {@[-1]}"opts = ( "$ {@[1, -2]}")
ugrep-heading-color = always always-pretty --context = 3-recursive-bool--smart-case '--sort = best'-no-confirm --perl-regexp-hidden '--- binary-files = match' ""$ opts [@] "-query = 1 --regexp ="$ r "
}
UGCI '일본 공포'
indices 삭제하여 저장 비용을 줄입니다 이 디렉토리는 각 주석을 단일 파일로 저장하는데, 이는 블록 크기가 4KB 인 최신 OS에서 매우 비효율적입니다. 이 파일을 사용하지 않으면이 파일을 삭제하면이 레포지기의 크기가 많이 줄어 듭니다 (이 글을 쓰는 시점에서 posts 디렉토리는 163MB에 불과합니다). .git 디렉토리를 삭제할 수도 있지만 새 업데이트를 가져 오는 것과 같은 git 기능에 대한 액세스를 잃게됩니다.
이를 달성하는 가장 쉬운 방법은 MS-JPQ/SAD와 같은 검색 및 재구성 도구를 사용하여 데이터에서 저자 이름을 삭제하는 것입니다.
FD. | 슬픈 ' s*: 저자 :.*' '' FD. | 슬픈 'u/ s+' 'u/redacted'
이 저장소는이 스크립트를 사용하여 만들어졌으며,이 스크립트는 내 환경에서 분리되기 위해 약간의 리팩토링이 필요합니다.
새 게시물이 하위 레드에 추가되면서 리포지토리를 최신 상태로 유지할 계획입니다.


