r_rational
1.0.0
Este es un archivo de todas las publicaciones en el subreddit R/racional en el modo de organización de texto sencillo.
Personalmente lo uso para hacer búsquedas rápidas de texto completo fuera de línea en todo el subreddit.
Reddit no se mapea limpiamente en el modo ORG, por lo que estoy abierto a ideas para cambiar la plantilla utilizada para crear los archivos de modo Org.
GitHub presenta encabezados de organización como encabezados HTML, lo que no funciona en absoluto para estos. Use un visor de modo Org para ver los archivos o simplemente abrirlos como texto sencillo.
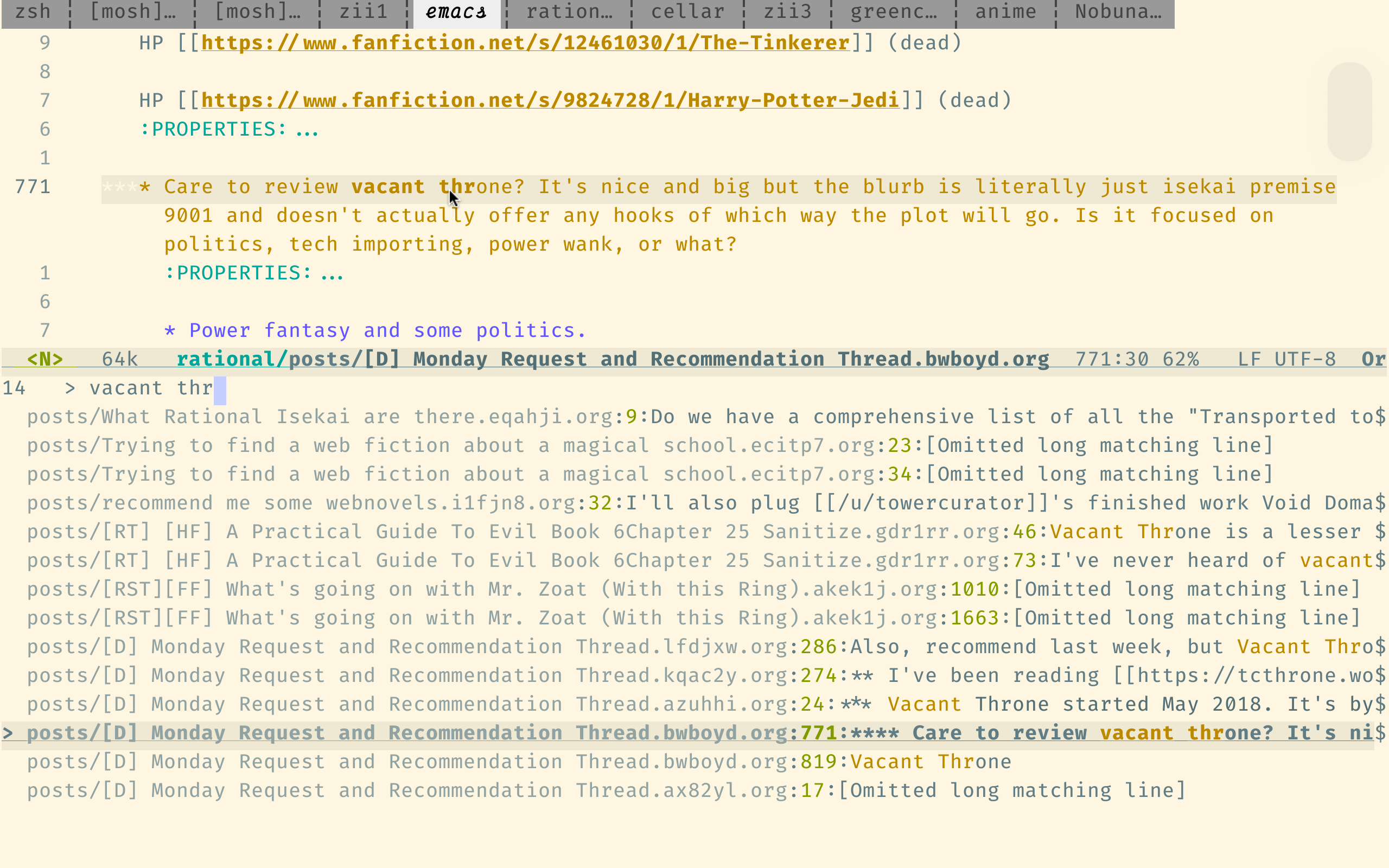
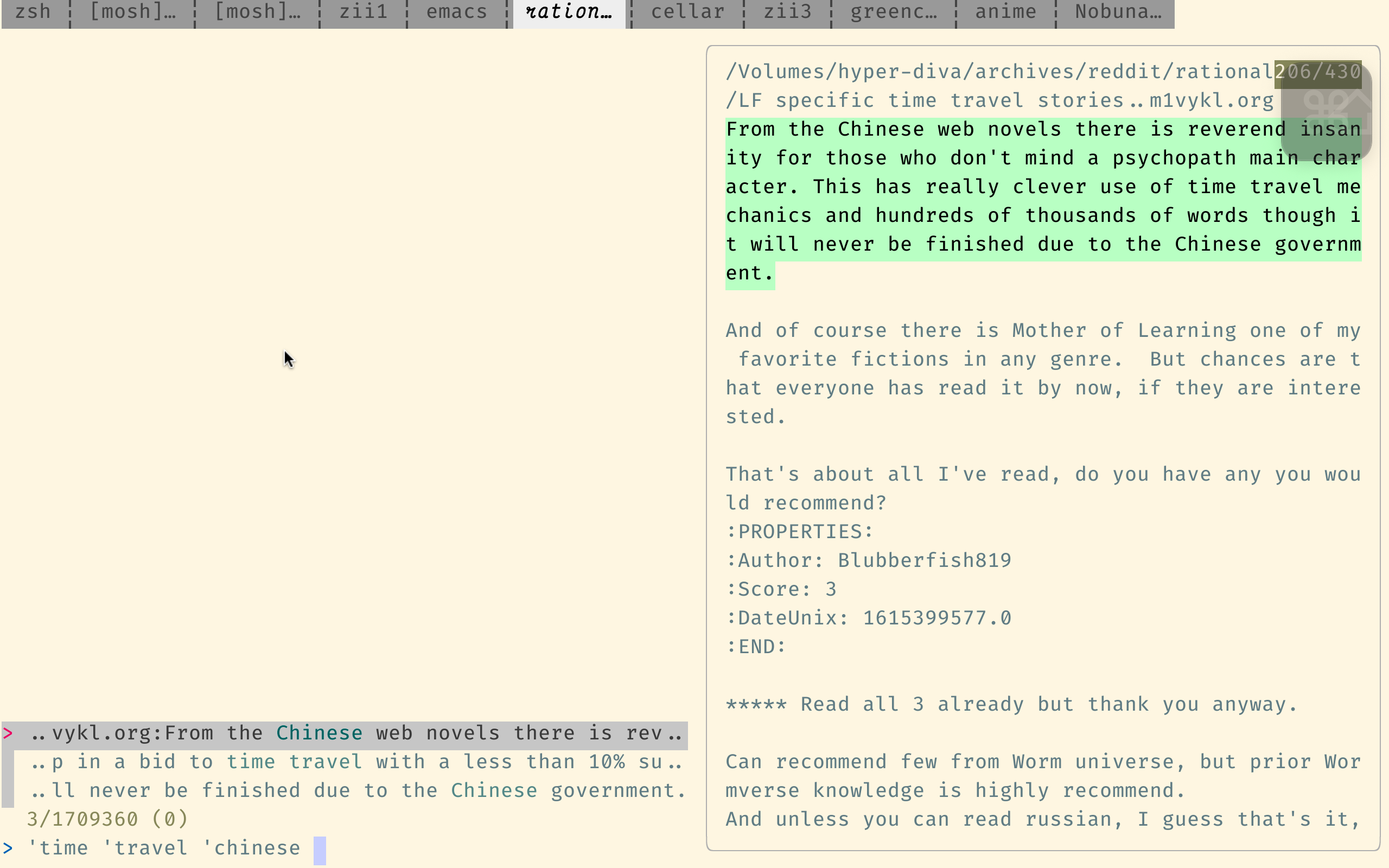
Este motor de búsqueda estaba optimizado para el código de búsqueda, por lo que no es demasiado adecuado para nuestros propósitos, pero aún es mucho mejor que la propia búsqueda de Reddit.
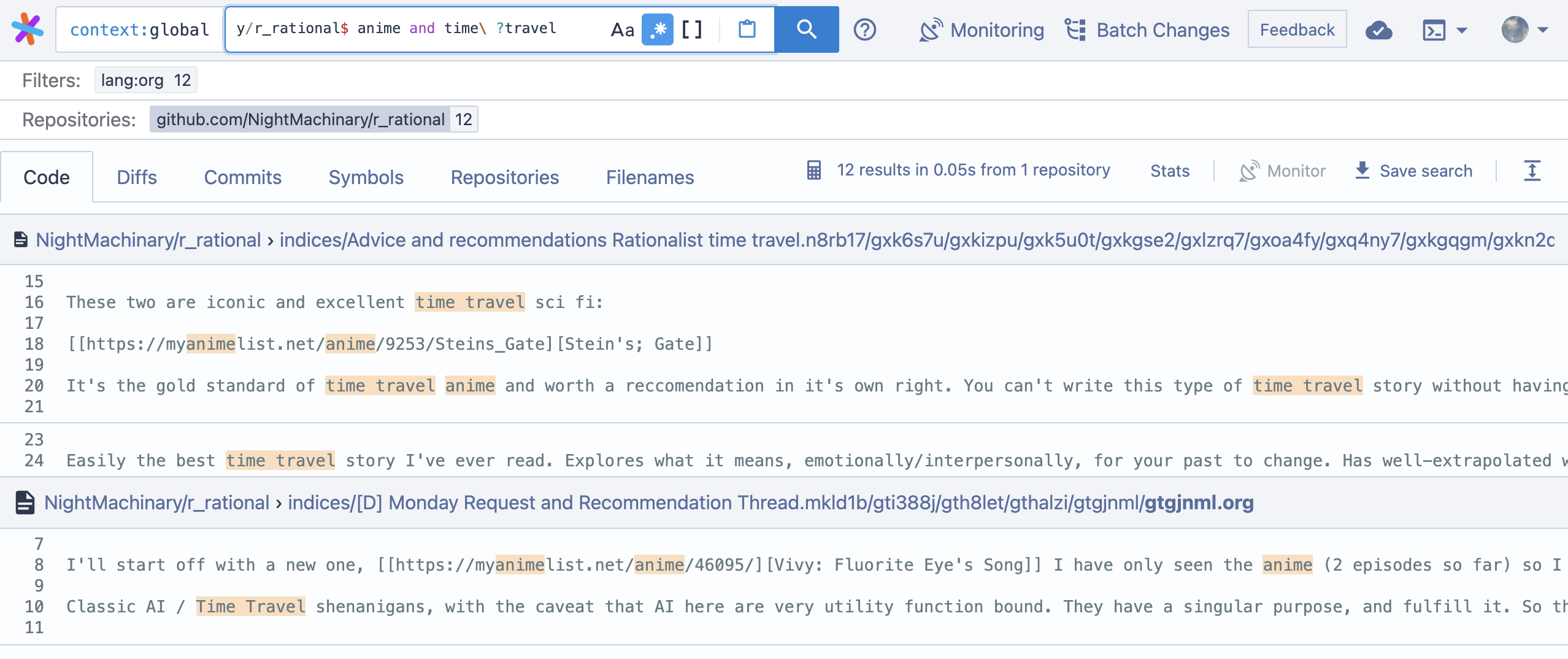
Aquí está la sintaxis de consulta de SourceGraph. El punto importante es que admite expresiones regulares y supone que las palabras están en el orden correcto, a menos que use operadores booleanos como japanese AND horror .
Tenga en cuenta que el enlace anterior busca en el directorio indices , donde cada archivo contiene solo un comentario. Esto suele ser lo que quieres. (Es solo un inconveniente que es tedioso encontrar los comentarios sobre los resultados encontrados). Para buscar por envío (en lugar de por comentario), use este enlace, que busca el directorio posts .
ugrepInstale GitHub - Genivia/UGREP :? New UGREP V3.3: Ultra Fast Grep con que interactiva ... por, por ejemplo,
Brew instalar UGREP
Ahora pegue esta función en su carcasa:
ugc () {
Ugrep--Heading--Color = Always --Pretty--Context = 3--Recursive --Bool--Smart-Case '--sort = Best'--No-Confirm --Perl-Regexp--Hidden '--Binary-Files = sin combinación' "$@" | menos -n
}
Ahora puedes hacer:
Git Clone ---RECURSIVE https://github.com/nightmachinary/r_rational CD r_rational/publicaciones
UGC 'Horror japonés'
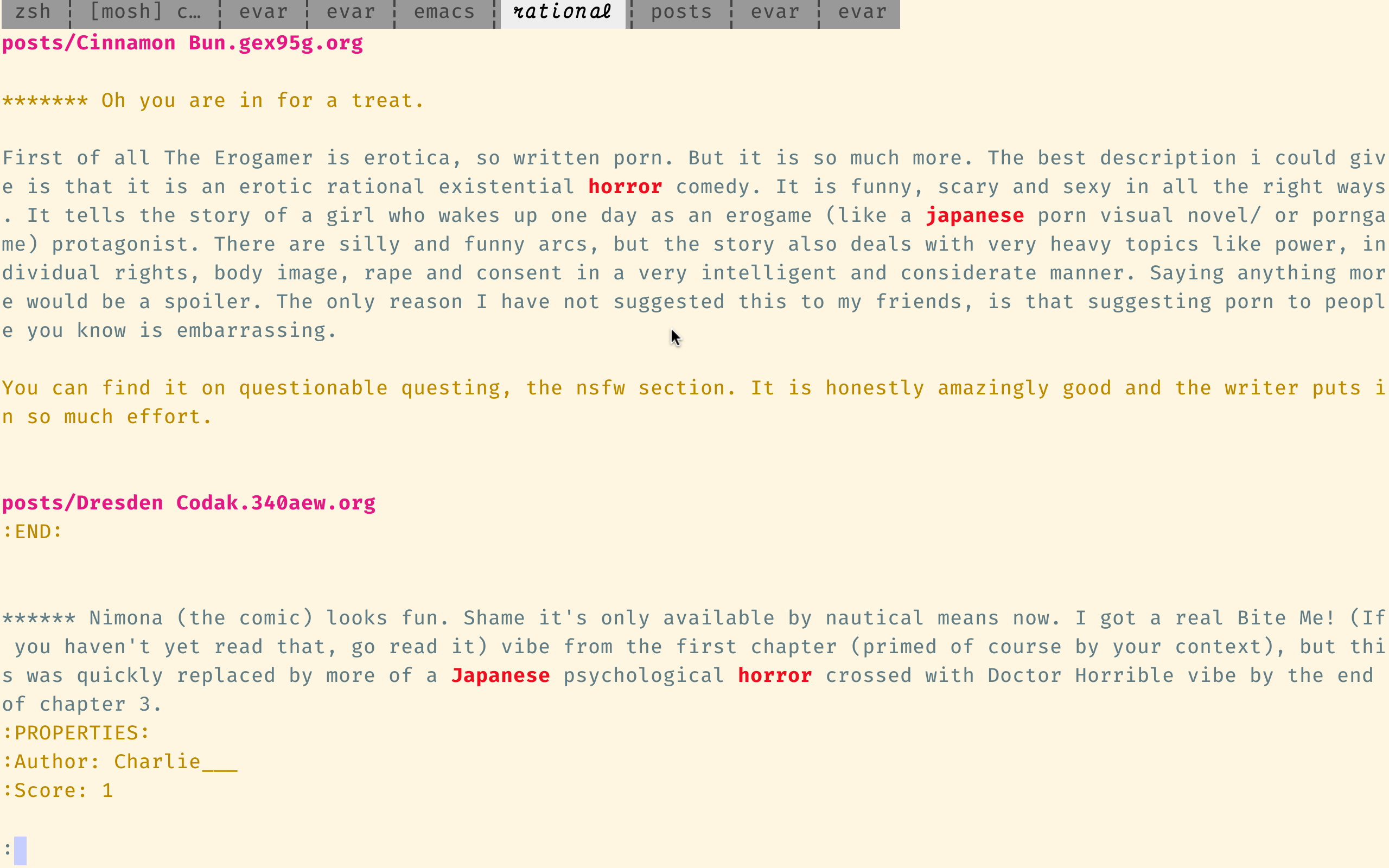
ugrep también admite un modo de búsqueda interactivo e incremental:
función ugci {
local r = "$ {@[-1]}" opts = ("$ {@[1, -2]}")
UGREP-Heading--Color = Always --Pretty--Context = 3--Recursive --Bool--Smart-Case '--sort = Best'--No-Confirm --PERL-ReGEXP--Hidden '--Binary-Files = sin coincidencia' "$ Opts [@]" --Query = 1 --regexp = "$ R"
}
ugci 'horror japonés'
indices Este directorio guarda cada comentario en un solo archivo, que es muy ineficiente en OSS modernos con un tamaño de bloque de 4KB. Si no usa estos archivos, eliminarlos reducirá el tamaño de este repositorio por mucho (a partir de este escrito, el directorio posts es de solo 163 MB). También puede eliminar el directorio .git , pero luego perdería acceso a funciones git , como extraer nuevas actualizaciones.
La forma más fácil de lograr esto es eliminar los nombres de los autores de los datos utilizando una herramienta de búsqueda y reemplazo como MS-JPQ/SAD:
fd. | triste ' s*: autor :.*' '' fd. | triste 'u/ s+' 'u/redactado'
Este repositorio se creó utilizando este script, que necesita algo de refactorización para ser desacoplados de mi entorno.
Planeo mantener el repositorio actualizado a medida que se agregan nuevas publicaciones al subreddit.


