r_rational
1.0.0
这是纯文本org模式中r/有理subreddit中所有帖子的存档。
我个人使用它在整个Subreddit上进行快速的,离线的全文搜索。
Reddit不会干净地映射到组织模式,因此我对更改用于创建ORG模式文件的模板的想法开放。
GitHub将ORG标题呈现为HTML标题,这对这些根本不起作用。使用ORG模式查看器查看文件,或者只是将其作为普通文本打开。
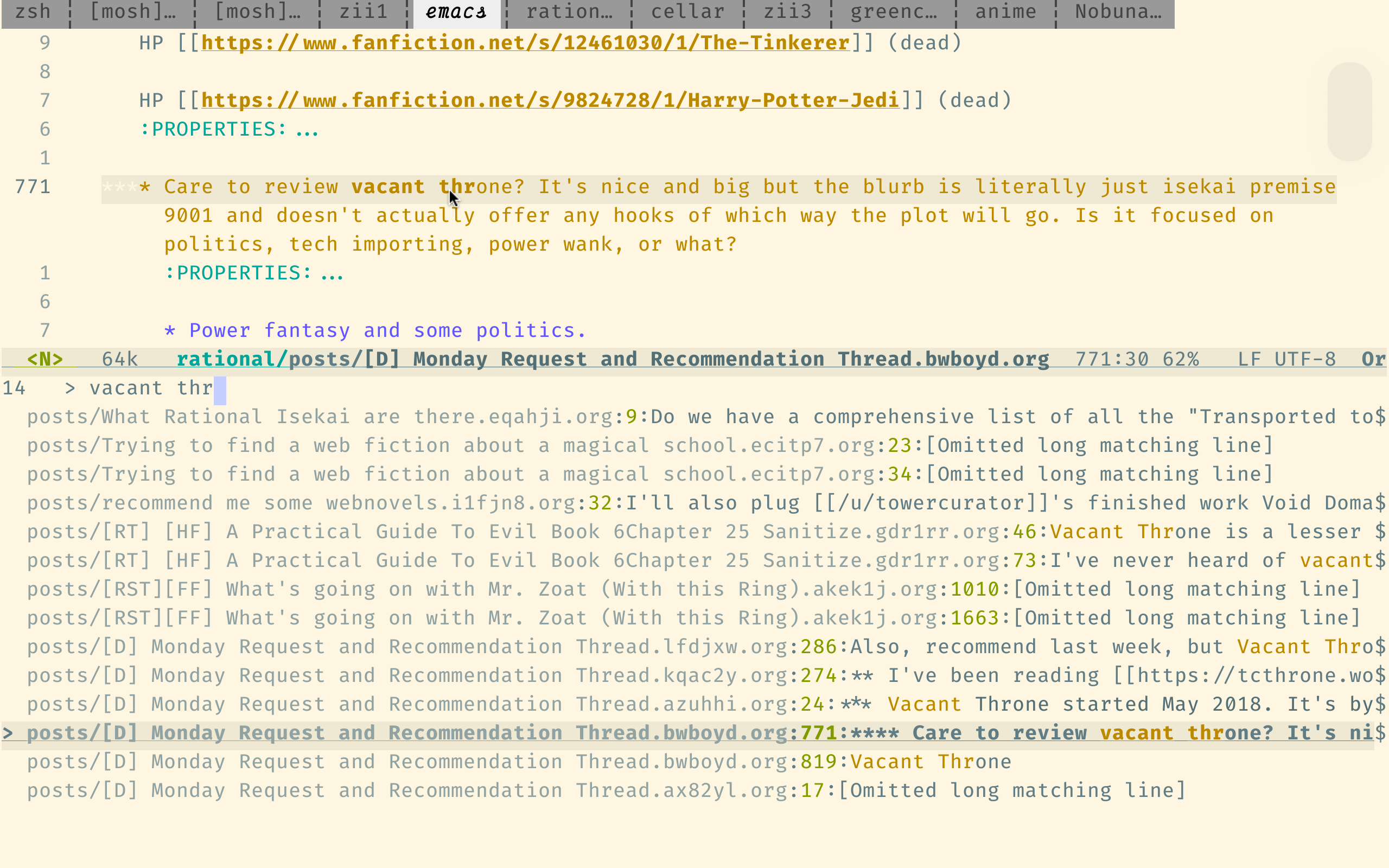
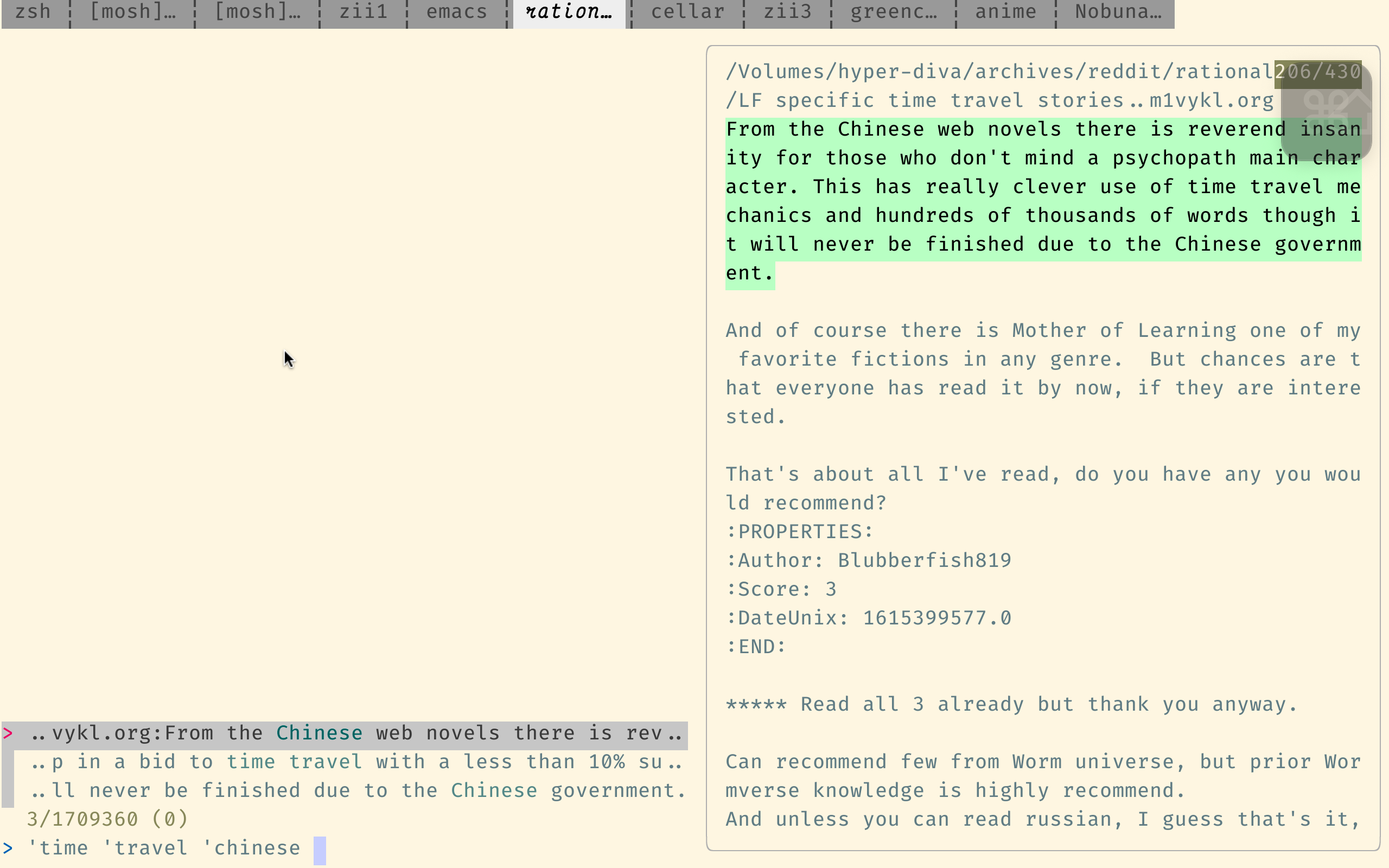
该搜索引擎已针对搜索代码进行了优化,因此它不太适合我们的目的,但它仍然比Reddit自己的搜索要好得多。
这是SourceGraph的查询语法。重要的一点是,它支持正则表达式,并假设单词以正确的顺序为顺序,除非您使用japanese AND horror等布尔操作员。
请注意,上面的链接在indices目录中搜索,其中每个文件仅包含一个注释。这通常就是您想要的。 (这只是缺点是找到围绕找到结果的评论很乏味。)要搜索每个提交(而不是每个注释),请使用此链接,该链接改为搜索posts目录。
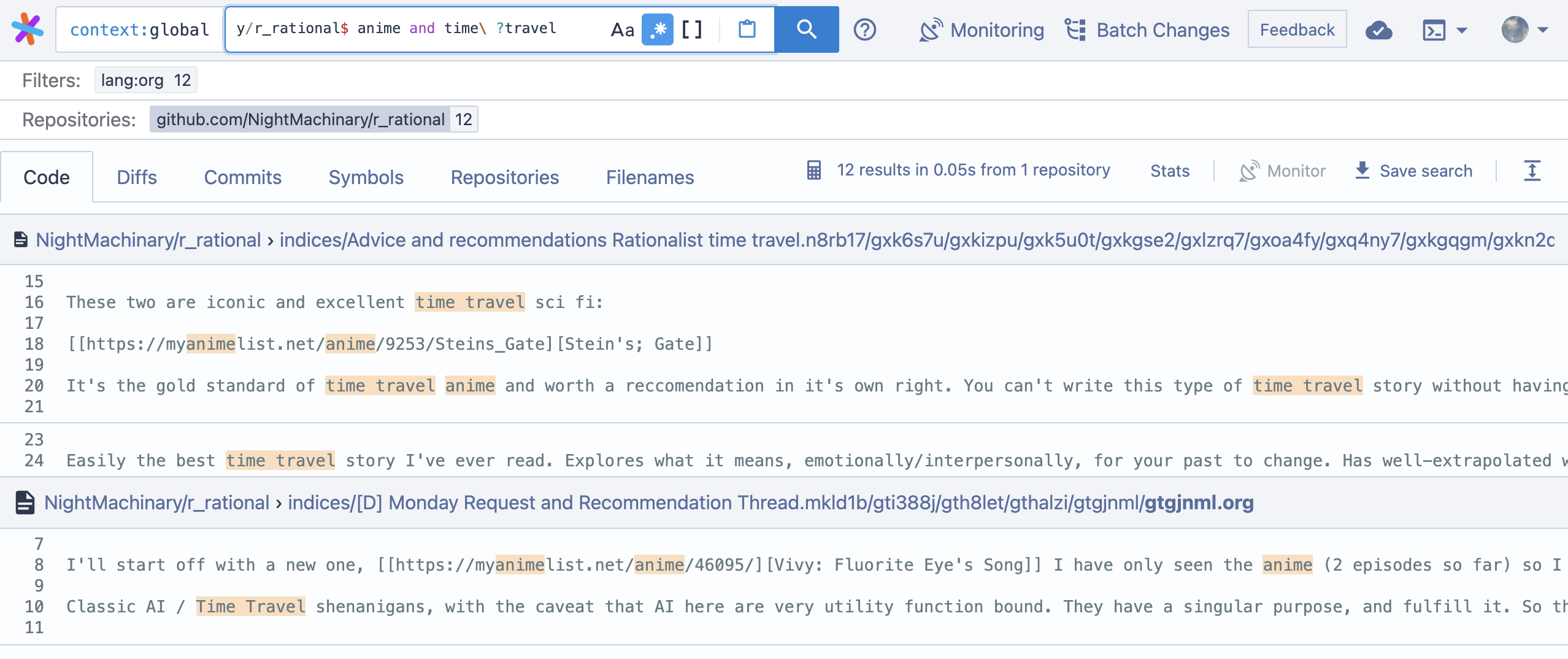
ugrep搜索安装github -genivia/ugrep:?新的ugrep v3.3:超快速的互动que…by,例如,例如,
酿造ugrep安装
现在将此功能粘贴到您的外壳中:
UGC(){
UGREP - 头 - 彩色=始终-pretty -pontext = 3-回复 - bool-smart-case' - sort = best' - no-confirm ---no-confirm - perl-regexp -hidden' - hidden' - binary' - binary-files = noter-match'noth-match'少-n
}
现在您可以做:
git克隆 - 恢复https://github.com/nightmachinary/r_rational CD r_rational/帖子
UGC“日本恐怖”
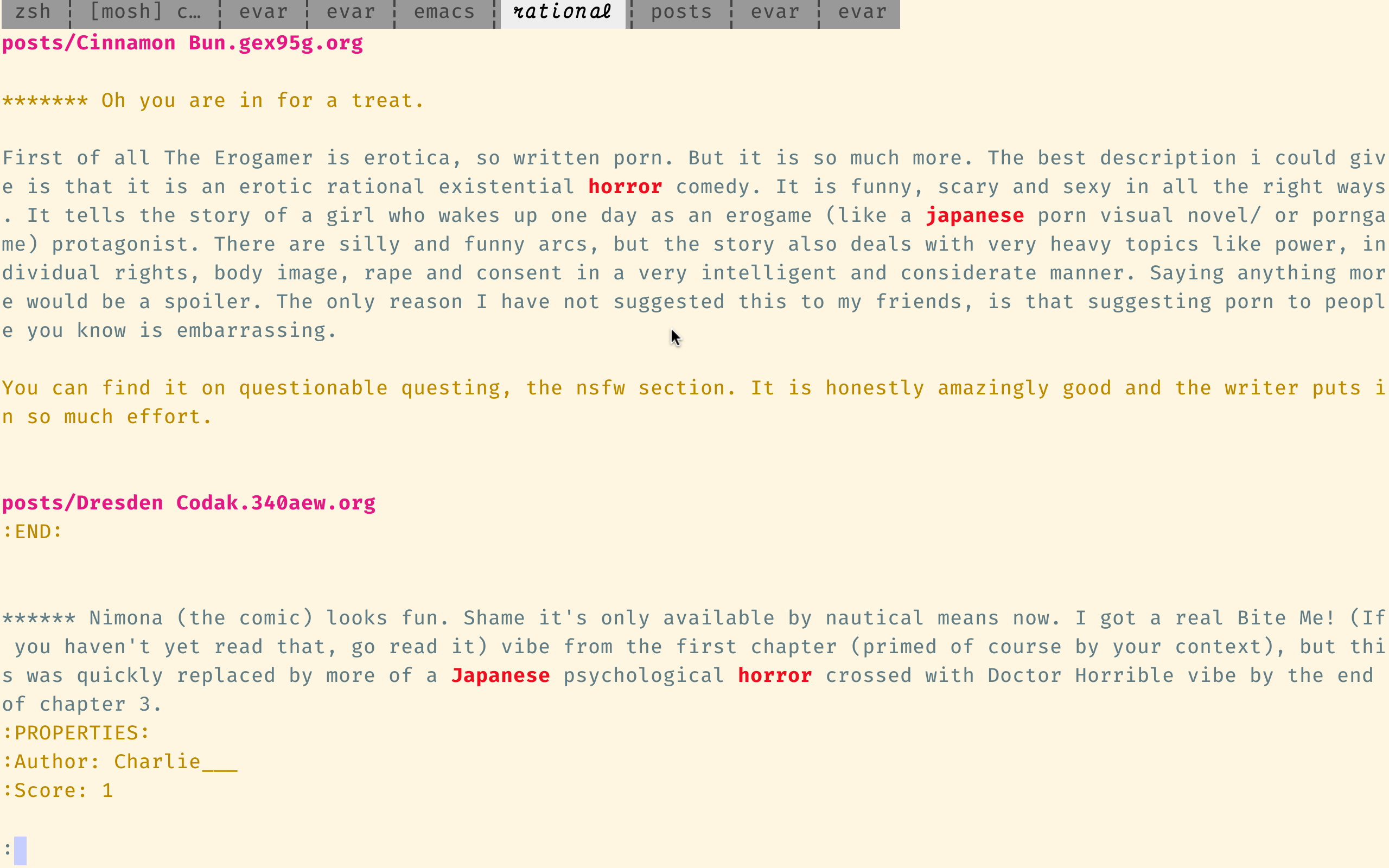
ugrep还支持交互式的增量搜索模式:
功能UGCI {
local r =“ $ {@[ - 1]}” opts =(“ $ {@[1,-2]}”)
UGREP - 头 - 彩色=始终 - pretty--context = 3-恢复-bool -bool -smart-case' - sort = best' - no-confirm - no-confirm - perl-regexp -hidden' - hidden' - hidden' - binardy' - binard' - binary' - binary' - binary' - binary-files = noth-match'noth-match'
}
UGCI“日本恐怖”
indices降低存储成本该目录将每个注释保存到一个文件中,该文件对4KB的块大小的现代OS效率非常低。如果您不使用这些文件,则将其删除将大量减少此存储库的大小(在撰写本文时, posts目录仅为163MB)。您还可以删除.git目录,但是然后您将无法访问git功能,例如提取新更新。
实现此目的的最简单方法是使用MS-JPQ/SAD等搜索和重新定位工具从数据中删除作者名称:
fd。 |悲伤的' s*:作者:。*''' fd。 |悲伤的'u/ s+''u/redacted'
此存储库是使用此脚本创建的,该脚本需要一些重构才能与我的环境分离。
我计划将新帖子添加到SubredDit中,以保持回购的最新状态。


