r_rational
1.0.0
Il s'agit d'une archive de tous les articles dans le sous-trairdit r / rationnel en mode org en texte brut.
Je l'utilise personnellement pour effectuer des recherches rapides et hors ligne sur l'ensemble de la sous-éditeur.
Reddit ne mappe pas proprement en mode org, donc je suis ouvert aux idées sur la modification du modèle utilisé pour créer les fichiers en mode org.
GitHub rend les titres org en tant qu'en-têtes HTML, ce qui ne fonctionne pas du tout pour ceux-ci. Utilisez une visionneuse en mode org pour afficher les fichiers ou ouvrez-les simplement en texte clair.
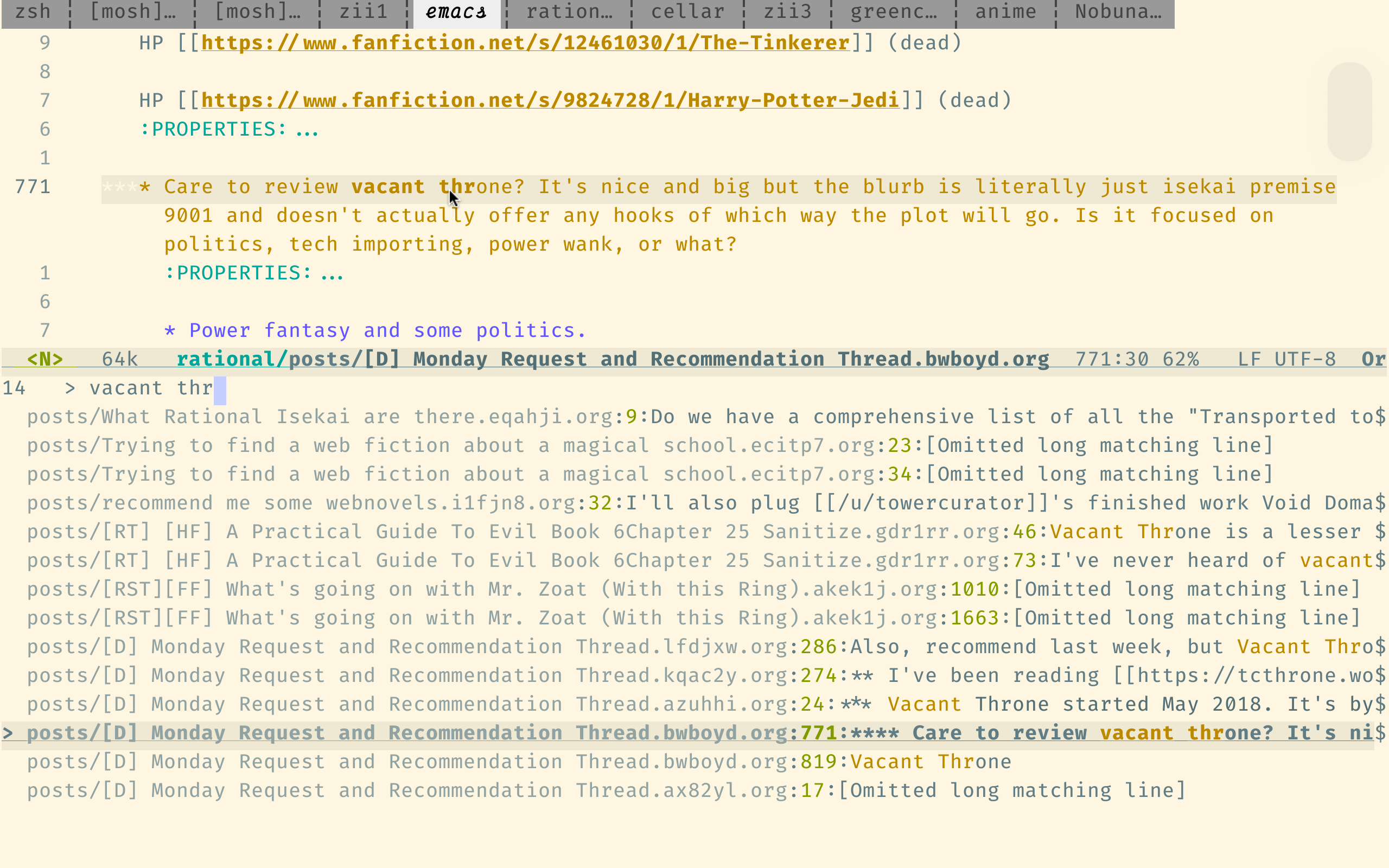
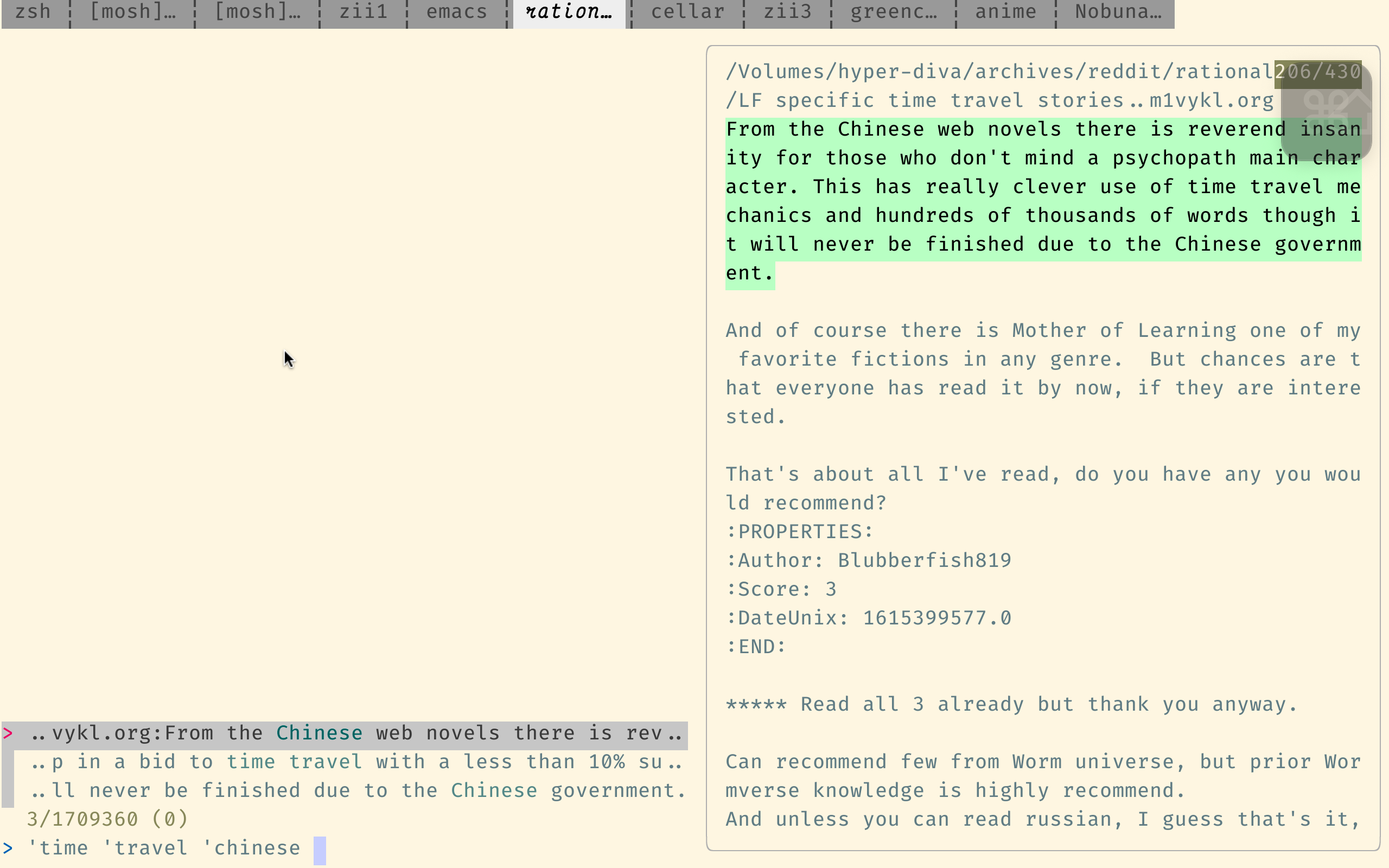
Ce moteur de recherche a été optimisé pour la recherche de code, il n'est donc pas trop adapté à nos fins, mais il est toujours bien meilleur que la propre recherche de Reddit.
Voici la syntaxe de requête de SourceGraph. Le point important est qu'il prend en charge les expressions régulières et suppose que les mots sont dans le bon ordre, sauf si vous utilisez des opérateurs booléens tels que japanese AND horror .
Notez que le lien ci-dessus recherche dans le répertoire indices , où chaque fichier ne contient qu'un seul commentaire. C'est généralement ce que vous voulez. (Ce n'est que des inconvénients qu'il est fastidieux de trouver les commentaires autour des résultats trouvés.) Pour rechercher par soumission (plutôt que par commentaire), utilisez ce lien, qui recherche plutôt le répertoire posts .
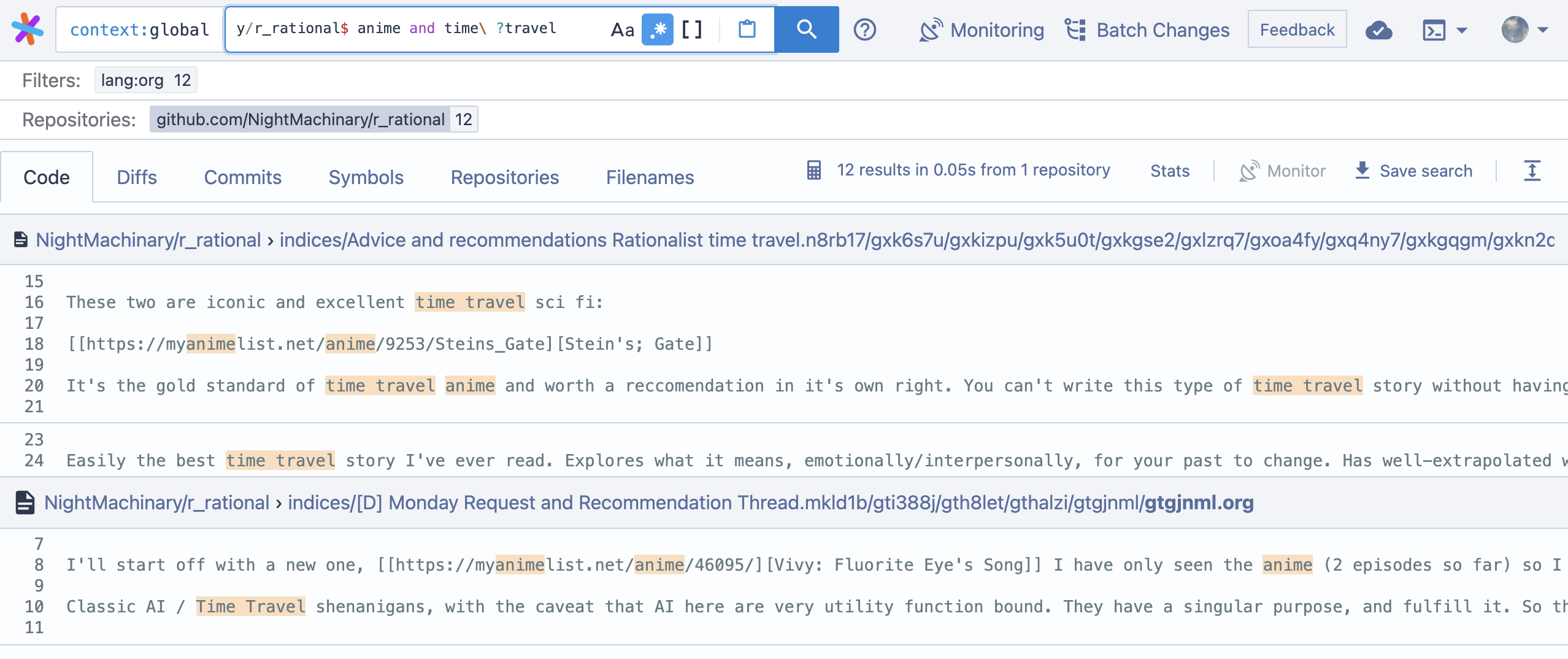
ugrepInstallez GitHub - Genivia / Ugrep :? New UGREP V3.3: Ultra Fast Grep avec interactive Que… par, par exemple,
Brew Installer UGREP
Collez maintenant cette fonction dans votre shell:
ugc () {
ugrep --tête-color = always --pretty --context = 3 --réursive --bool --mart-case '--sort = best' --no-confirm --perl-regexp --hidden '- binary-files = without-match' "$ @" | moins -n
}
Maintenant, vous pouvez faire:
GIT CLONE - RECURSIVE https://github.com/nightmachinary/r_ational CD R_ational / Posts
UGC 'Horreur japonaise'
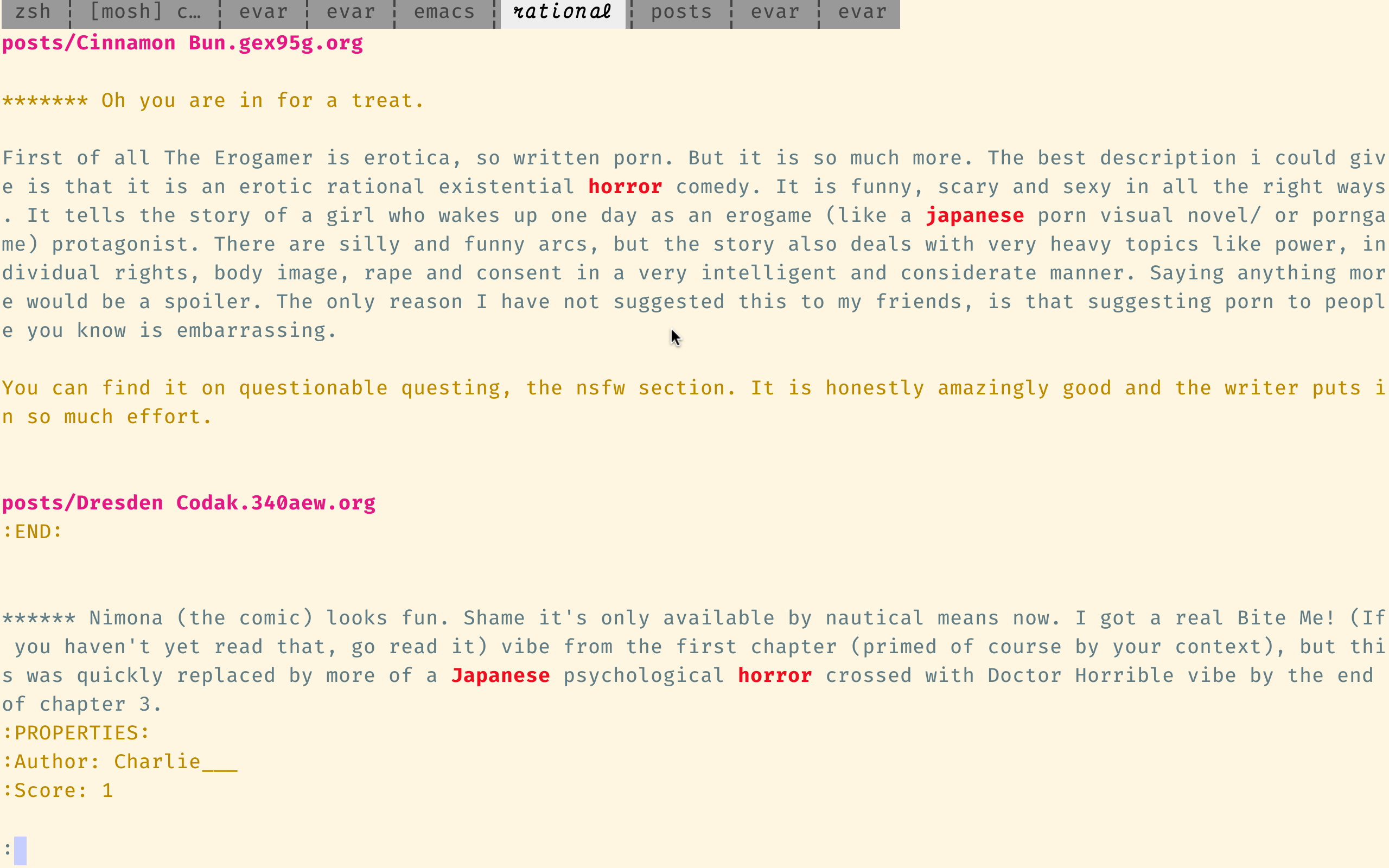
ugrep prend également en charge un mode de recherche incrémentiel interactif:
fonction ugci {
R local r = "$ {@ [- 1]}" opts = ("$ {@ [1, -2]}")
ugrep --tête --color = always --pretty --context = 3 --recursive --bool --mart-case '--sort = best' --no-confirm —perl-regexp - hidden '--binary-files = without-match' "$ opts [@]" --query = 1 --regexp = "$ r"
}
UGCI 'Horreur japonaise'
indices Ce répertoire enregistre chaque commentaire sur un seul fichier, ce qui est très inefficace sur les OSO modernes avec une taille de bloc de 4KB. Si vous n'utilisez pas ces fichiers, les supprimer réduira beaucoup la taille de ce dépôt (à ce jour, le répertoire posts n'est que de 163 Mo). Vous pouvez également supprimer le répertoire .git , mais vous perdriez ensuite l'accès aux fonctionnalités git telles que la réalisation de nouvelles mises à jour.
Le moyen le plus simple d'y parvenir est de supprimer les noms des auteurs des données à l'aide d'un outil de recherche et de repensage tel que MS-JPQ / SAD:
Fd. | triste ' s *: auteur :. *' '' Fd. | triste 'u / s +' 'u / expurgé'
Ce dépôt a été créé en utilisant ce script, qui a besoin de refactorisation pour être découplé de mon environnement.
J'ai l'intention de garder le repo à jour lorsque de nouveaux messages sont ajoutés à la sous-éditeur.


