podcast synopsis generation openai
1.0.0
傳統上,播客概要的過程需要創作者,製作人和/或作家來理解內容,並手動編寫摘要,總結一集的顯著點和亮點。這種方法是耗時的,可能涉及討論主要主題的集思廣益會議,並完善文本,直到有效地傳達播客的信息和語氣(例如,喜劇播客可能在其摘要中具有幽默的語言或誇張)。
該存儲庫說明瞭如何使用Azure認知服務提供的服務組合來自動化本手冊和耗時的過程,特別是Azure Speech Service和Azure OpenAI用於轉錄和生成概要, Taglines ,SEO關鍵字, SEO關鍵字和多種語言。合併AI自動化這一過程並不能消除人類創造力的作用或人類參與的重要性。取而代之的是,它通過利用AI的力量來實現上市時間的顯著加速。在發布之前,最終的驗證和批准仍然是人類專家的責任。
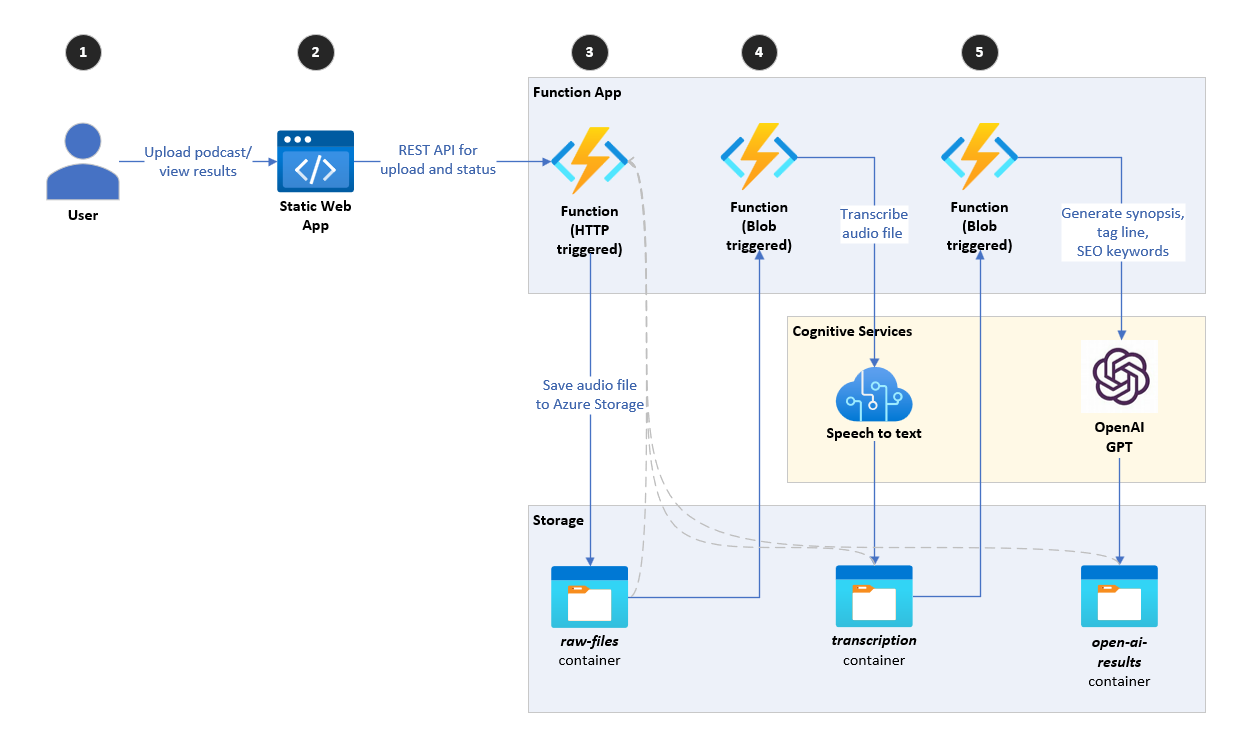
該存儲庫實現了一個高級體系結構,該體系結構將播放播客的音頻(步驟1-3),使用Azure Speech Services(步驟4)將音頻轉錄到文本中,並使用Azure OpenAI GPT-3.5(步驟5)基於轉錄生成簡介。請注意,使用的GPT模型版本可以很容易地升級到例如GPT-4或將來版本。
它由一個React Web應用程序組成,該應用程序允許用戶上傳音頻文件(播客)。該應用使用Azure函數(WebApihttptrigger)端點將音頻文件上傳到存儲帳戶,即raw-files容器。
當將新文件添加到raw-files容器中時,Azure函數(AudioFileUploadedBlobTrigger)會觸發。該功能下載音頻文件並將其發送到Azure Speech Services,並將音頻轉錄為文本。然後,它將轉錄保存到同一存儲帳戶,即transcription容器。
當將新文件添加到transcriptions容器中時,觸發了最後一個Azure函數(TranscriptionFileUploadedBlobTrigger)。該功能下載轉錄文件,並將其發送到執行以下功能的四種不同的Azure OpenAI方法:
它將結果作為單獨的文本文件保存在存儲帳戶open-ai-results容器中。
該項目歡迎貢獻和建議。大多數捐款要求您同意撰寫貢獻者許可協議(CLA),宣布您有權並實際上授予我們使用您的貢獻的權利。有關詳細信息,請訪問https://cla.opensource.microsoft.com。
為了做出貢獻,請首先創建一個自我分配的問題,從而對您想做的事情進行高級概述。一旦那裡的任何討論得出結論,請跟進PR。
該項目採用了Microsoft開源的行為代碼。有關更多信息,請參見《行為守則常見問題守則》或與其他問題或評論聯繫[email protected]。


