podcast synopsis generation openai
1.0.0
传统上,播客概要的过程需要创作者,制作人和/或作家来理解内容,并手动编写摘要,总结一集的显着点和亮点。这种方法是耗时的,可能涉及讨论主要主题的集思广益会议,并完善文本,直到有效地传达播客的信息和语气(例如,喜剧播客可能在其摘要中具有幽默的语言或夸张)。
该存储库说明了如何使用Azure认知服务提供的服务组合来自动化本手册和耗时的过程,特别是Azure Speech Service和Azure OpenAI用于转录和生成概要, Taglines ,SEO关键字, SEO关键字和多种语言。合并AI自动化这一过程并不能消除人类创造力的作用或人类参与的重要性。取而代之的是,它通过利用AI的力量来实现上市时间的显着加速。在发布之前,最终的验证和批准仍然是人类专家的责任。
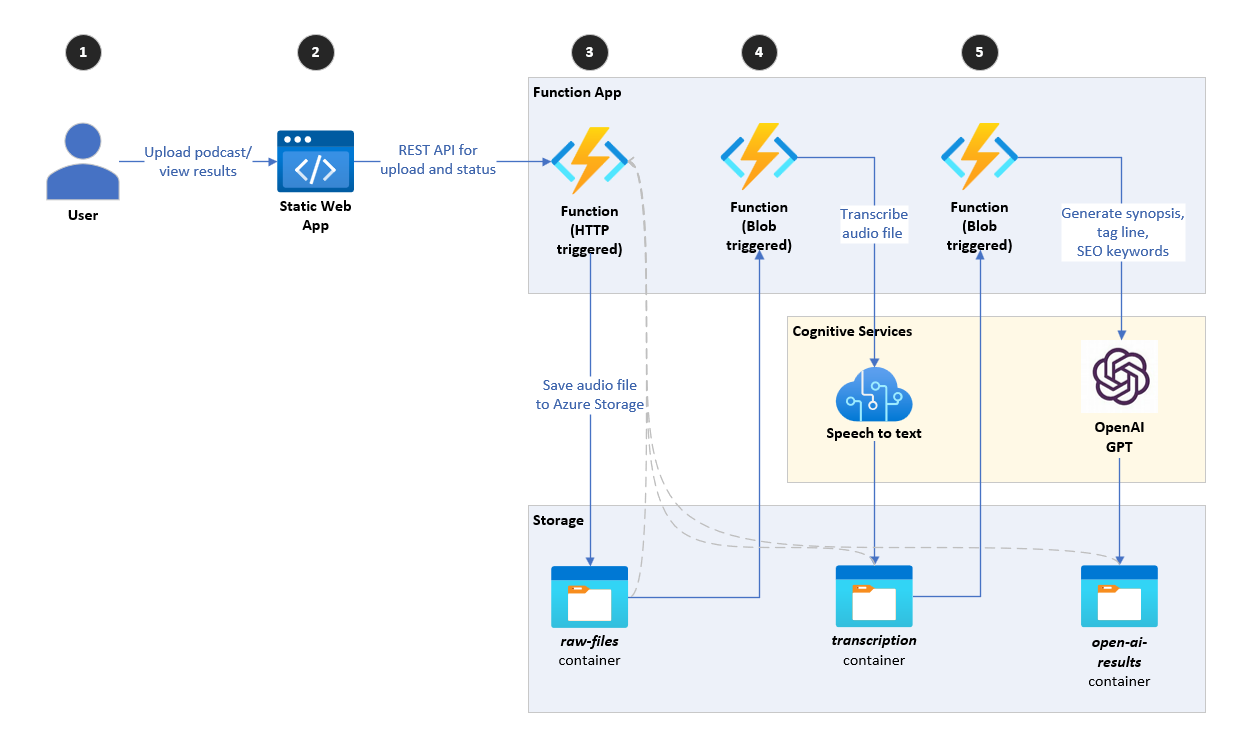
该存储库实现了一个高级体系结构,该体系结构将播放播客的音频(步骤1-3),使用Azure Speech Services(步骤4)将音频转录到文本中,并使用Azure OpenAI GPT-3.5(步骤5)基于转录生成简介。请注意,使用的GPT模型版本可以很容易地升级到例如GPT-4或将来版本。
它由一个React Web应用程序组成,该应用程序允许用户上传音频文件(播客)。该应用使用Azure函数(WebApihttptrigger)端点将音频文件上传到存储帐户,即raw-files容器。
当将新文件添加到raw-files容器中时,Azure函数(AudioFileUploadedBlobTrigger)会触发。该功能下载音频文件并将其发送到Azure Speech Services,并将音频转录为文本。然后,它将转录保存到同一存储帐户,即transcription容器。
当将新文件添加到transcriptions容器中时,触发了最后一个Azure函数(TranscriptionFileUploadedBlobTrigger)。该功能下载转录文件,并将其发送到执行以下功能的四种不同的Azure OpenAI方法:
它将结果作为单独的文本文件保存在存储帐户open-ai-results容器中。
该项目欢迎贡献和建议。大多数捐款要求您同意撰写贡献者许可协议(CLA),宣布您有权并实际上授予我们使用您的贡献的权利。有关详细信息,请访问https://cla.opensource.microsoft.com。
为了做出贡献,请首先创建一个自我分配的问题,从而对您想做的事情进行高级概述。一旦那里的任何讨论得出结论,请跟进PR。
该项目采用了Microsoft开源的行为代码。有关更多信息,请参见《行为守则常见问题守则》或与其他问题或评论联系[email protected]。


