podcast synopsis generation openai
1.0.0
ポッドキャストの概要生成のプロセスは、伝統的に作成者、プロデューサー、および/または作家にコンテンツを理解し、エピソードの顕著なポイントとハイライトを要約して、概要を手動で書くことを要求していました。このアプローチは時間がかかり、主なテーマについて議論し、ポッドキャストのメッセージとトーンを効果的に伝えるまでテキストを改良するブレーンストーミングセッションを含む場合があります(たとえば、コメディーポッドキャストには、ユーモラスな言語や誇張が概要を説明する場合があります)。
このリポジトリは、Azure Cognitive Services、特にAzure Speech ServiceとAzure Openaiが提供するサービスのポートフォリオを使用して、このマニュアルおよび時間のかかるプロセスの大部分を自動化する方法を示しています。このプロセスを自動化するためにAIを組み込むことは、人間の創造性の役割や人間の関与の重要性を排除しません。代わりに、AIの力を活用することにより、市場までの時間に大きな加速を可能にします。コンテンツの最終的な検証と承認は、公開前の人間の専門家の責任のままです。
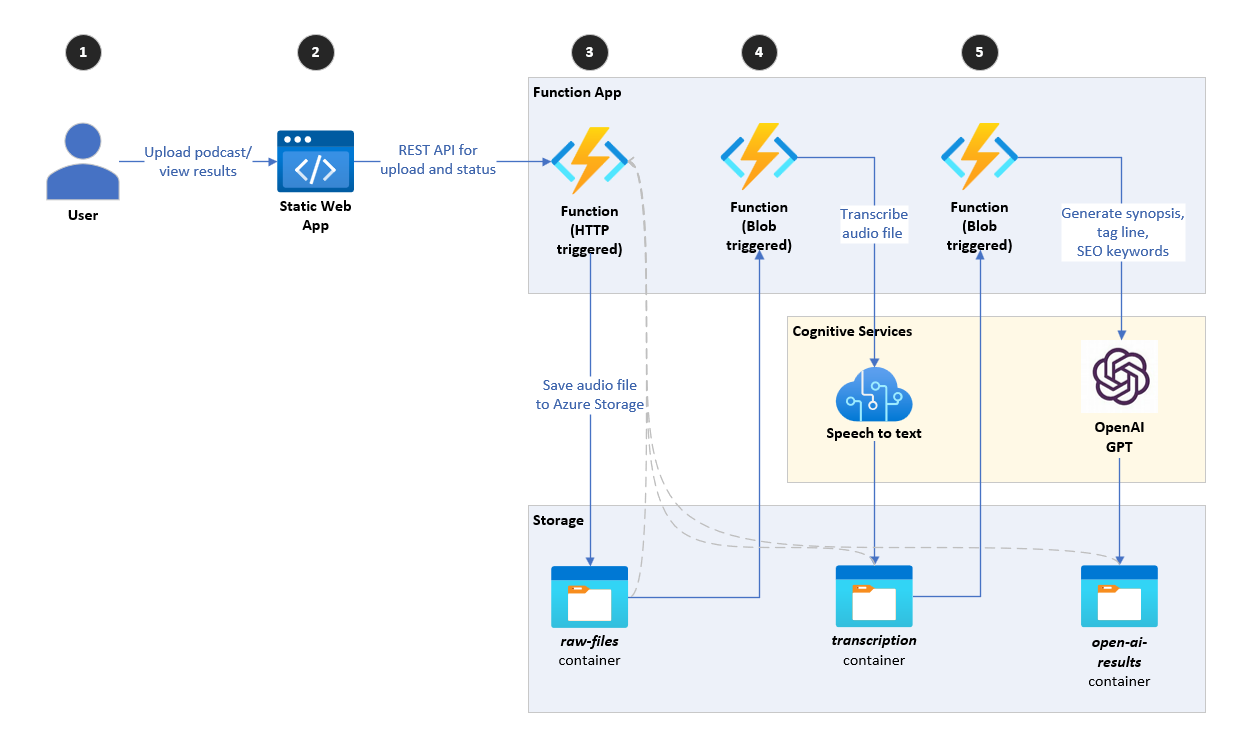
このリポジトリは、ポッドキャスト(ステップ1-3)の音声を取得し、Azure Speech Services(ステップ4)を使用してオーディオをテキストに転写し、Azure OpenAI GPT-3.5(ステップ5)を使用して転写に基づいて概要を生成する高レベルアーキテクチャを実装します。使用されるGPTモデルのバージョンは、たとえばGPT-4または将来のバージョンに簡単にアップグレードできることに注意してください。
ユーザーがオーディオファイル(ポッドキャスト)をアップロードできるReact Webアプリで構成されています。アプリは、Azure関数(WebAPIHTTPTRIGGER)エンドポイントを使用して、オーディオファイルをストレージアカウント、つまりraw-filesコンテナにアップロードします。
azure関数(audiofileuploadedblobtrigger)は、新しいファイルがraw-filesコンテナに追加されるとトリガーされます。この関数はオーディオファイルをダウンロードし、Azure Speech Servicesに送信し、オーディオをテキストに転写します。次に、転写を同じストレージアカウント、つまりtranscription容器に保存します。
最後のAzure関数(TranscriptionFileuploadedBlobtrigger)は、新しいファイルがtranscriptionsコンテナに追加されるとトリガーされます。この関数は、転写ファイルをダウンロードし、次の機能を実行する4つの異なるAzure Openaiメソッドに送信します。
ストレージアカウントのopen-ai-resultsコンテナ内の個別のテキストファイルとして結果を保存します。
このプロジェクトは、貢献と提案を歓迎します。ほとんどの貢献では、貢献者ライセンス契約(CLA)に同意する必要があります。詳細については、https://cla.opensource.microsoft.comをご覧ください。
貢献するには、自己割り当ての問題を作成して、やりたいことの高レベルの概要を示してください。そこで議論が終了したら、PRでフォローアップしてください。
このプロジェクトは、Microsoftのオープンソース行動規範を採用しています。詳細については、FAQのコードを参照するか、追加の質問やコメントについては[email protected]にお問い合わせください。


