GPT 4 Domain Specific Language
1.0.0
[NB:此存儲庫是評估CHATGPT的相同推理任務的後續。]
大型語言模型(LLM),例如GPT-4,Chatgpt和Claude表現出了令人印象深刻的編程能力,並且能夠解決各種語言及其分類法的問題。儘管取得了這些成功,但在這些模型表現出對這些語言基礎的句法和操作規則的任何基本欣賞程度上,某些懷疑態度仍然存在。
在此及時工程存儲庫中,使用任意域特異性語言(DSL)探索GPT-4的編程能力。 DSL代表了研究LLMS的推理能力的有吸引力的底物,因為它們是新穎的,並且在訓練中遇到廣泛遇到和記憶的可能性較小。因此,它們可以更直接地測試LLM可以以幾種方式推斷出新型編程語言規則的程度。
在這裡,選擇了特定於域的語言SIL(對稱集成語言),原因有兩個。首先,GPT-4在培訓過程中暴露於任何大量的SIL代碼,因為這是由技術繁重的對沖基金(稱為Symmetry Investments)開發的內部DSL。其次,作為一種編程語言,該模型具有一些有趣的功能(例如,這是一種強調表達性的功能性語言,但缺乏像Haskell或Ocaml中的let ”。
在一些示例代碼提示之後,GPT-4嘗試在一種稱為“ SIL”的小說,功能性DSL中編寫代碼。
以下是一些提示的集合,其中包括SIL代碼的簡短示例,這些示例突出了其功能。在提示GPT-4執行任務並提供SIL代碼樣本之後(請參見下文;在此回購中也可以找到提示和生成的代碼樣本的完整庫),我要求它在SIL中實現許多主流編程任務。
在下面的一節中,我顯示了一些示例SIL代碼腳本,並在此提示了該模型(可以在此處找到完整的示例)及其在SIL中實現各種問題的嘗試。
第一個提示是處理一些郵件服務器功能的腳本。因此,它與我隨後會提示chatgpt的問題類型有很大不同,但它確實說明了SIL(例如|> )的某些語法,數據結構和功能方面。
// example of using IMAP IDLE to run rules on new mail
import imap
moveMessages(session,ids,target) => if (ids.length > 0 ) then imap.moveUIDs(session,ids,target) else false
login = imap.ImapLogin(environment( " IMAP_USER " ),environment( " IMAP_PASS " ))
server = imap.ImapServer( " imap.fastmail.com " , " 993 " )
session = imap.Session(server,login, true ,imap.Options(debugMode: true )) | > imap.openConnection | > imap.login
rules=[ [
[ " INBOX/0receipts " ,
[
" FROM [email protected] " ,
" FROM interactivebrokers.com " ,
]],
[ " Junk " ,
[
" FROM Tapatalk " ,
]],
[ " INBOX/newsletters " ,
[
" FROM [email protected] " ,
" HEADER X-mailer mailgun " ,
" HEADER X-mailer WPMailSMTP/Mailer/mailgun 2.4.0 " ,
" HEADER X-mailer nlserver " ,
" FROM hbr.org " ,
" FROM elliottwave.com " ,
" OR FROM cio.com FROM cio.co.uk " ,
" FROM substack.com " ,
" FROM eaglealpha.com " ,
" FROM haaretz.com " ,
" FROM gavekal.com " ,
" FROM go.weka.io " ,
" FROM marketing.weka.io " ,
` HEADER list-unsubscribe "" ` ,
` HEADER list-Id "" ` ,
` HEADER list-Post "" ` ,
` HEADER list-owner"" ` ,
` HEADER Precedence bulk ` ,
` HEADER Precedence list ` ,
` HEADER list-bounces "" ` ,
` HEADER list-help "" ` ,
` HEADER List-Unsubscribe "" ` ,
" FROM no-reply " ,
]],
[ " INBOX/notifications " ,
[
` KEYWORD "$IsNotification" ` ,
" FROM [email protected] " ,
" FROM [email protected] " ,
" FROM skillcast.com " ,
" FROM reedmac.co.uk " ,
" FROM [email protected] " ,
" FROM [email protected] " ,
" FROM [email protected] " ,
]],
]
runRules(Session,Rules) => Rules
| > map(target => [target[ 0 ],(target[ 1 ] | > map(term => imap.search(Session,term).ids))])
| > mapa(set => moveMessages(Session,set[ 1 ] | > join,set[ 0 ]))
runRulesBox(Session,Rules,Mailbox) => {
imap.select(Session,Mailbox)
in runRules (Session,Rules)
}
inboxes=[ " INBOX " ]
result = inboxes | > mapa(inbox => runRulesBox(session,rules,imap.Mailbox(session,inbox)))
print(result)
import parallel;
threadFunction(x) => {
imap.idle(session)
in inboxes | > mapa(inbox => runRulesBox(session,rules,imap.Mailbox(session,inbox)))
}
parallel.runEvents((x) => false ,[threadFunction])第二個示例代碼提示類似地旨在突出該DSL的某些功能,並引入了一些新的標準庫功能,例如iota和fold 。
import imap
import imap_config
import string
// Get the configuration from the environment and command line.
config = imap_config.getConfig(commandLineArguments)
// -------------------------------------------------------------------------------------------------
// Some helper functions.
//
// Firstly, a function to join an array of strings.
joinFields(flds, sep) => {
len(flds) > 0 | > enforce( " Cannot join an empty array. " )
in fold (flds[ 1 :$], (str, fld) => str ~ sep ~ fld, flds[ 0 ])
}
// Secondly, a field formatter which strips the field prefix and pads to a fixed width.
// E.g., ("From: [email protected]" |> fmtField(20)) == "[email protected] "
fmtField(field, width) => {
pad(str) => iota(width - len(str)) | > fold((a, i) => a ~ " " , str)
in field
| > string .split( " : " )[ 1 :$]
| > joinFields( " : " )
| > pad
}
// And thirdly, a function which concatenates the headers into a formatted string.
fmtHeaders(outStr, headers) => {
outStr ~ " " ~ joinFields(headers, " | " ) ~ " n "
}
// -------------------------------------------------------------------------------------------------
// Connect to the inbox.
creds = imap.ImapLogin(config.user, config.pass)
server = imap.ImapServer(config.host, config.port)
session =
imap.Session(server, creds)
| > imap.openConnection()
| > imap.login()
inbox = imap.Mailbox(session, " INBOX " )
// Get the number of messages in the inbox.
msgCount = imap.status(session, inbox).messages
// Select the default inbox.
inbox | > imap.examine(session, _)
// Get the headers (date, from and subject) for each message, from oldest to newest, format and
// print them.
headers =
iota(msgCount)
| > map(id => " # " ~ toString(id + 1 ))
| > map(id =>
imap.fetchFields(session, id, " date from subject " ).lines
| > map(hdr => fmtField(hdr, 40 )))
| > fold(fmtHeaders, " INBOX: n " )
print(headers)第三個代碼示例進一步說明了該DSL的一些異常功能,其目的是接下來將在其自己的實現中使用這些功能。
// This script will create a report based on a specific example set of automated 'support' emails.
// E.g.,
//
// "support.mbox": 17 messages 17 new
// N 1 [email protected] Mon May 11 22:26 28/1369 "Alert: new issue 123"
// N 2 [email protected] Tue May 12 12:20 22/933 "Notification: service change"
// N 3 [email protected] Tue May 12 12:36 26/1341 "Alert: new issue 124"
// N 4 [email protected] Wed May 13 02:13 21/921 "Resolution: issue 124"
// N 5 [email protected] Wed May 13 18:53 26/1332 "Email not from robot."
// N 6 [email protected] Thu May 14 03:13 27/1339 "Alert: new issue 125"
// N 7 [email protected] Thu May 14 08:46 26/1270 "Resolution: issue 123"
// N 8 [email protected] Thu May 14 17:06 25/1249 "Alert: new issue 126"
// N 9 [email protected] Fri May 15 09:46 24/1185 "Resolution: issue 126"
// N 10 [email protected] Fri May 15 12:33 23/1052 "Alert: new issue 127"
// N 11 [email protected] Fri May 15 15:20 27/1331 "Notification: service change"
// N 12 [email protected] Fri May 15 18:06 23/953 "Resolution: issue 127"
// N 13 [email protected] Mon May 18 12:46 27/1218 "Alert: new issue 128"
// N 14 [email protected] Mon May 18 15:33 32/1628 "Alert: new issue 129"
// N 15 [email protected] Tue May 19 05:26 25/1176 "Resolution: issue 128"
// N 16 [email protected] Tue May 19 08:13 26/1312 "Notification: service change"
// N 17 [email protected] Tue May 19 11:00 28/1275 "Alert: new issue 130"
//
//
// Each of these automated emails are from `robot` _except_ for message 5. Messages 2, 8 and 16 are
// from `robot` but are unrelated to issues.
//
// This script will search for emails and match new issue numbers with resolutions to report the
// number of outstanding alerts.
import imap
import * from imap.query
import imap_config
import dates
import string
// Get the configuration from the environment and command line.
config = imap_config.getConfig(commandLineArguments)
// Connect to the inbox.
creds = imap.ImapLogin(config.user, config.pass)
server = imap.ImapServer(config.host, config.port)
session =
imap.Session(server, creds)
| > imap.openConnection()
| > imap.login()
inbox = imap.Mailbox(session, " support " )
// Select the default inbox.
inbox | > imap.examine(session, _)
// These criteria are common for both our searches.
commonCrit = imap.Query()
| > and(from( ` [email protected] ` ))
| > and(sentSince(dates. Date ( 2020 , 5 , 13 )))
// Get each of the alerts and resolutions from the past week (13-19 May 2020).
alertMsgIds =
imap.search(session, imap.Query(subject( " Alert: new issue " )) | > and(commonCrit)).ids
resolutionMsgIds =
imap.search(session, imap.Query(subject( " Resolution: issue " )) | > and(commonCrit)).ids
// A function to get the alert ID from a message subject.
getAlertId(msgId) => {
imap.fetchFields(session, toString (msgId), " subject " ).lines[ 0 ]
| > string .split()[$ - 1 ]
}
// A function to remove an entry from a table whether it's there or not.
removeIfExists(tbl, key) => {
if find( keys (tbl), key) == [] then
tbl
else
removeEntry(tbl, key)
}
// Now find those alerts which have no resolution. Firstly the subject for each alert, get the
// issue number end and store it in a table.
allAlertTable = alertMsgIds | > fold((tbl, msgId) => addEntry(tbl, getAlertId(msgId), msgId), {})
// Go through the resolutions and remove their corresponding alerts from the table.
unresolvedAlertTable =
resolutionMsgIds | > fold((tbl, msgId) => removeIfExists(tbl, getAlertId(msgId)), allAlertTable)
// Create a report with the date of the unresolved alerts.
report =
keys (unresolvedAlertTable)
| > map(alertId => {
msgId = unresolvedAlertTable[alertId] | > toString
in [ alertId
, imap.fetchFields(session, msgId, " date " ).lines[ 0 ]
, imap.fetchText(session, msgId).lines[ 0 ]
]
})
| > fold((outStr, tuple) => {
outStr ~ " Issue: " ~ tuple[ 0 ] ~ " n " ~ tuple[ 1 ] ~ " n Summary: " ~ tuple[ 2 ] ~ " n "
}, " n UNRESOLVED ISSUES FROM THE PAST 10 DAYS: nn " )
// Close the session.
imap.closeConnection(session)
// Print the report last.
print(report)作為第一次練習,我要求模型在SIL中實現一個非常簡單的關係數據庫,具有基本功能(請注意, //表示SIL中的評論)。
import imap
import imap_config
import string
// Get the configuration from the environment and command line.
config = imap_config.getConfig(commandLineArguments)
// Connect to the server.
creds = imap.ImapLogin(config.user, config.pass)
server = imap.ImapServer(config.host, config.port)
session =
imap.Session(server, creds)
| > imap.openConnection()
| > imap.login()
// -------------------------------------------------------------------------------------------------
// Here's an attempt to create something resembling a simple relational database.
// Define two tables, 'Employees' and 'Departments'.
Employees = { " 1 " : [ " Alice " , " Engineering " ], " 2 " : [ " Bob " , " Marketing " ], " 3 " : [ " Charlie " , " Engineering " ] }
Departments = { " Engineering " : [ " Alice " , " Charlie " ], " Marketing " : [ " Bob " ] }
// Function to emulate SQL SELECT operation.
select = (table, id) => {
table[id] | > enforce( " Id does not exist in table. " )
}
// Function to emulate SQL INSERT operation.
insert = (table, id, values ) => {
addEntry(table, id, values )
}
// Function to emulate SQL DELETE operation.
delete = (table, id) => {
removeEntry(table, id)
}
// Function to emulate SQL JOIN operation.
join = (table1, table2, commonField) => {
// This is a very basic JOIN operation and does not account for multiple matches, etc.
joinedTable = {}
for key in keys (table1) {
value = table1[key][commonField]
if find( keys (table2), value) != [] {
joinedTable = addEntry(joinedTable, key, [table1[key], table2[value]])
}
}
joinedTable
}
// Close the session.
imap.closeConnection(session)
// Perform operations.
newEmployee = [ " David " , " Marketing " ]
Employees = insert(Employees, " 4 " , newEmployee)
Departments = insert(Departments, newEmployee[ 1 ], [ " David " ])
print(select(Employees, " 1 " ))
print(join(Employees, Departments, 1 ))實施排序算法是一個原型軟件工程面試問題。在這裡,我要求GPT-4在SIL中實現Bubblesort(從概念上講是最基本的排序算法)。以下是回應:
// Helper function to bubble up the largest value in one pass
bubble(list) => {
if length(list) <= 1 then
list
else
if list[ 0 ] > list[ 1 ] then
[list[ 1 ]] ~ bubble([list[ 0 ]] ~ list[ 2 to $])
else
[list[ 0 ]] ~ bubble(list[ 1 to $])
}
// Main BubbleSort function
bubbleSort(list) => {
bubbled = bubble(list)
if bubbled == list then
list
else
bubbleSort(bubbled)
}接下來,我提示該模型編寫一個用於計算列表中值的腳本(下面生成的響應)。實際上,輔助函數sortList確實與功能編程範式一致,但是在這裡GPT-4假定分配運算符的存在:= 。
// Helper function to sort an array of integers.
sortList(list) => list | > len | > iota | > map(i => list | > min | > snd) | > each((i, minVal) => list := removeIndex(list, minVal))
// Function to compute the median of a set of integers.
computeMedian(list) => {
// Sort the list in ascending order.
sortedList = sortList(list)
// Get the length of the list.
length = len(sortedList)
// Check if the length is even.
isEven = length % 2 == 0
// If the length is even, the median is the average of the two middle numbers.
// Otherwise, the median is just the middle number.
median =
if isEven then
(sortedList[length / 2 - 1 ] + sortedList[length / 2 ]) / 2
else
sortedList[length / 2 ]
// Return the median.
median
}接下來提示GPT -4在SIL中實現K -Neart最鄰居算法。除了幻覺/假設存在一個稱為math的模塊(可以說是本練習範圍的合理假設)之外,這似乎是一種可接受的解決方案,該解決方案適當地利用了功能運算符,例如|> , map和fold 。
import math
distance(p1, p2) => {
math.sqrt(
math.pow(p1[ 0 ] - p2[ 0 ], 2 )
+ math.pow(p1[ 1 ] - p2[ 1 ], 2 )
)
}
majorityVote(labels) => {
labelCounts = labels | > fold((counts, label) => addEntry(counts, label, get (counts, label, 0 ) + 1 ), {})
labelCounts | > maxBy((_, count) => count)
}
knn(data, newPoint, k) => {
distances = data | > map((point, label) => (distance(point, newPoint), label))
sorted = distances | > sort((a, b) => a[ 0 ] < b[ 0 ])
nearest = sorted | > take(k)
labels = nearest | > map((_, label) => label)
majorityVote(labels)
}
功能語言的有趣特徵之一是它們可以具有很高的表現力。在這裡,我提示GPT-4實現基本功能運算map , filter和reduce (或在功能語言的背景下fold )。
// map
// The map-like function would take a function and a list, and apply the function to each element in the list.
mapList(func, list) => {
len(list) > 0 | > enforce( " Cannot map over an empty list. " )
in iota (len(list)) | > fold((result, i) => addEntry(result, func(list[i])), [])
}
// filter
// The filter-like function would take a predicate and a list, and return a list of elements for which the predicate returns true.
filterList(pred, list) => {
len(list) > 0 | > enforce( " Cannot filter an empty list. " )
in iota (len(list)) | > fold((result, i) => if pred(list[i]) then addEntry(result, list[i]) else result, [])
}
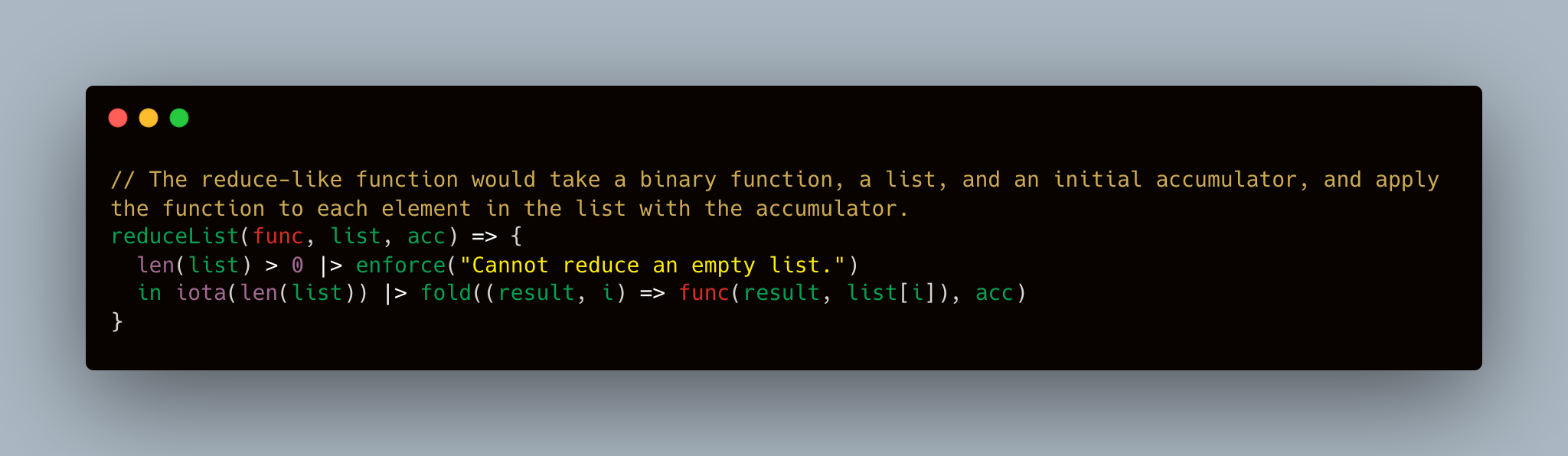
// reduce
// The reduce-like function would take a binary function, a list, and an initial accumulator, and apply the function to each element in the list with the accumulator.
reduceList(func, list, acc) => {
len(list) > 0 | > enforce( " Cannot reduce an empty list. " )
in iota (len(list)) | > fold((result, i) => func(result, list[i]), acc)
}
Euler項目是數學和編程問題的集合(我認為這是LLM的有趣提示)。在這裡,我提示GPT-4使用SIL解決前兩個項目Euler問題。
// Project Euler problem #1:
// Here, my prompt was to solve the (easy) first problem of the Project Euler series (https://projecteuler.net/problem=1)
// Define a range from 1 to 999.
range = iota( 999 ) | > map(x => x + 1 )
// Define a function to check if a number is a multiple of 3 or 5.
isMultipleOf3Or5 = (num) => num % 3 == 0 || num % 5 == 0
// Filter the range to get only multiples of 3 or 5.
multiples = range | > filter(isMultipleOf3Or5)
// Sum the multiples.
sum = multiples | > fold((a, b) => a + b, 0 )
// Print the sum.
print(sum)
// Project Euler problem #2:
// This prompt is to solve the second Project Euler problem (https://projecteuler.net/problem=2)
// Define a function to generate the next term in the Fibonacci sequence.
nextFibonacciTerm = (tuple) => [tuple[ 1 ], tuple[ 0 ] + tuple[ 1 ]]
// Start with the first two terms.
initialTerms = [ 1 , 2 ]
// Define a function to generate Fibonacci sequence up to a limit.
generateFibonacci = (limit) => {
fibonacciSequence = unfold(nextFibonacciTerm, initialTerms, (tuple) => tuple[ 1 ] <= limit)
fibonacciSequence
}
// Define a function to check if a number is even.
isEven = (num) => num % 2 == 0
// Generate the Fibonacci sequence up to four million.
fibonacciSequence = generateFibonacci( 4000000 )
// Extract the second term from each tuple in the sequence, which is the actual Fibonacci number.
fibonacciNumbers = fibonacciSequence | > map(tuple => tuple[ 1 ])
// Filter the sequence to get only even numbers.
evenFibonacciNumbers = fibonacciNumbers | > filter(isEven)
// Sum the even numbers.
sum = evenFibonacciNumbers | > fold((a, b) => a + b, 0 )
// Print the sum.
print(sum)
探索LLMs以幾種方式推斷和理解新型編程語言特徵的能力仍然是一個開放而有趣的問題。在這裡,這些能力是在促使GPT-4解決促使特定領域特定語言(DSL)的問題的背景下進行了探索的。 DSL是探索LLMS中推理與記憶的潛在有用的測試用例,因為它們通常具有獨特的特徵,並且在訓練期間(如果有的話)中遇到了廣泛的特徵。
這項練習的最有趣的發現也許是,在相同的提示和任務上評估時,GPT-4的少量推理功能明顯好於Chatgpt的推理功能(請參閱此處的Chatgpt類似練習)。
有證據表明,LLM記憶是通過訓練示例演示的頻率以及用於提示模型的相關令牌的數量來促進的。 ↩


