GPT 4 Domain Specific Language
1.0.0
[NB: Dieses Repo ist eine Folge derselben Inferenzaufgabe, die Chatgpt bewertet.]
Großsprachenmodelle (LLMs) wie GPT-4, Chatgpt und Claude haben beeindruckende Programmierfähigkeiten gezeigt und können Probleme in einer Vielzahl von Sprachen und ihren Taxonomien lösen. Trotz dieser Erfolge bestehen einige Skepsis bestehen darüber, inwieweit diese Modelle eine zugrunde liegende Wertschätzung der syntaktischen und operativen Regeln aufweisen, die diesen Sprachen zugrunde liegen ( im Vergleich zu Auswendiglernen von Mustern aus Trainingsdaten).
In diesem Repository für Eingabeentwicklung werden die Programmierfähigkeiten von GPT-4 unter Verwendung einer willkürlichen domänenspezifischen Sprache (DSL) untersucht. DSLs stellen ein attraktives Substrat für die Untersuchung der Inferenzfähigkeiten von LLMs dar, da sie neuartig sind und während des Trainings 1 weniger wahrscheinlich auftreten und auswendig gelernt wurden. Als solches ermöglichen sie einen direkteren Test, inwieweit LLMs die Regeln neuartiger Programmiersprachen auf eine Weise schließen können.
Hier wurde die domänenspezifische Sprache SIL (Symmetrie-Integrationssprache) aus zwei Gründen ausgewählt. Erstens ist es äußerst unwahrscheinlich, dass GPT-4 während des Trainings einem erheblichen Volumen an SIL-Code ausgesetzt war, da es sich um eine interne DSL-DSL handelt, die von einem technisch-hedienlichen Hedgefonds namens Symmetry Investments entwickelt wurde. Zweitens hat es als Programmiersprache einige interessante Merkmale für das Modell zu reproduzieren (z. B. ist es eine funktionale Sprache, die die Ausdrucksfähigkeit hervorhebt, aber es fehlt, Ausdrücke wie in Haskell oder Ocaml let ).
Nach einigen Beispiel-Code-Eingabeaufforderungen versucht GPT-4, Code in einem neuartigen, funktionalen DSL zu schreiben, der als "SIL" bekannt ist.
Nachfolgend finden Sie eine Sammlung einiger Eingabeaufforderungen, die aus kurzen Beispielen für SIL -Code bestehen, die ihre Funktionalität hervorheben. Nachdem GPT-4 mit der Aufgabe und Bereitstellung von SIL-Code-Stichproben aufgenommen wurde (siehe unten; die vollständige Bibliothek von Eingabeaufforderungen und generierten Code-Samples finden Sie auch in diesem Repo), habe ich sie gebeten, eine Reihe von Mainstream-Programmierungsaufgaben in SIL zu implementieren.
In den folgenden Abschnitten zeige ich einige der Beispiel -SIL -Code -Skripte, mit denen das Modell aufgefordert wurde (die vollständigen Beispiele finden Sie hier) und seine Versuche, verschiedene Probleme in SIL zu implementieren.
Die erste Eingabeaufforderung ist ein Skript, um einige E -Mail -Server -Funktionen zu verarbeiten. Daher unterscheidet es sich stark von der Art von Problem, die ich anschließend ChatGPT zum Lösen fordern werde, aber es veranschaulicht einige der Syntax-, Datenstrukturen und funktionalen Aspekte von SIL (z. |> ).
// example of using IMAP IDLE to run rules on new mail
import imap
moveMessages(session,ids,target) => if (ids.length > 0 ) then imap.moveUIDs(session,ids,target) else false
login = imap.ImapLogin(environment( " IMAP_USER " ),environment( " IMAP_PASS " ))
server = imap.ImapServer( " imap.fastmail.com " , " 993 " )
session = imap.Session(server,login, true ,imap.Options(debugMode: true )) | > imap.openConnection | > imap.login
rules=[ [
[ " INBOX/0receipts " ,
[
" FROM [email protected] " ,
" FROM interactivebrokers.com " ,
]],
[ " Junk " ,
[
" FROM Tapatalk " ,
]],
[ " INBOX/newsletters " ,
[
" FROM [email protected] " ,
" HEADER X-mailer mailgun " ,
" HEADER X-mailer WPMailSMTP/Mailer/mailgun 2.4.0 " ,
" HEADER X-mailer nlserver " ,
" FROM hbr.org " ,
" FROM elliottwave.com " ,
" OR FROM cio.com FROM cio.co.uk " ,
" FROM substack.com " ,
" FROM eaglealpha.com " ,
" FROM haaretz.com " ,
" FROM gavekal.com " ,
" FROM go.weka.io " ,
" FROM marketing.weka.io " ,
` HEADER list-unsubscribe "" ` ,
` HEADER list-Id "" ` ,
` HEADER list-Post "" ` ,
` HEADER list-owner"" ` ,
` HEADER Precedence bulk ` ,
` HEADER Precedence list ` ,
` HEADER list-bounces "" ` ,
` HEADER list-help "" ` ,
` HEADER List-Unsubscribe "" ` ,
" FROM no-reply " ,
]],
[ " INBOX/notifications " ,
[
` KEYWORD "$IsNotification" ` ,
" FROM [email protected] " ,
" FROM [email protected] " ,
" FROM skillcast.com " ,
" FROM reedmac.co.uk " ,
" FROM [email protected] " ,
" FROM [email protected] " ,
" FROM [email protected] " ,
]],
]
runRules(Session,Rules) => Rules
| > map(target => [target[ 0 ],(target[ 1 ] | > map(term => imap.search(Session,term).ids))])
| > mapa(set => moveMessages(Session,set[ 1 ] | > join,set[ 0 ]))
runRulesBox(Session,Rules,Mailbox) => {
imap.select(Session,Mailbox)
in runRules (Session,Rules)
}
inboxes=[ " INBOX " ]
result = inboxes | > mapa(inbox => runRulesBox(session,rules,imap.Mailbox(session,inbox)))
print(result)
import parallel;
threadFunction(x) => {
imap.idle(session)
in inboxes | > mapa(inbox => runRulesBox(session,rules,imap.Mailbox(session,inbox)))
}
parallel.runEvents((x) => false ,[threadFunction]) Die zweite Beispiel -Code -Eingabeaufforderung zielt in ähnlicher Weise darauf ab, einige Funktionen dieses DSL für das Modell hervorzuheben und einige neue Standardbibliotheksfunktionen wie iota und fold einzuführen.
import imap
import imap_config
import string
// Get the configuration from the environment and command line.
config = imap_config.getConfig(commandLineArguments)
// -------------------------------------------------------------------------------------------------
// Some helper functions.
//
// Firstly, a function to join an array of strings.
joinFields(flds, sep) => {
len(flds) > 0 | > enforce( " Cannot join an empty array. " )
in fold (flds[ 1 :$], (str, fld) => str ~ sep ~ fld, flds[ 0 ])
}
// Secondly, a field formatter which strips the field prefix and pads to a fixed width.
// E.g., ("From: [email protected]" |> fmtField(20)) == "[email protected] "
fmtField(field, width) => {
pad(str) => iota(width - len(str)) | > fold((a, i) => a ~ " " , str)
in field
| > string .split( " : " )[ 1 :$]
| > joinFields( " : " )
| > pad
}
// And thirdly, a function which concatenates the headers into a formatted string.
fmtHeaders(outStr, headers) => {
outStr ~ " " ~ joinFields(headers, " | " ) ~ " n "
}
// -------------------------------------------------------------------------------------------------
// Connect to the inbox.
creds = imap.ImapLogin(config.user, config.pass)
server = imap.ImapServer(config.host, config.port)
session =
imap.Session(server, creds)
| > imap.openConnection()
| > imap.login()
inbox = imap.Mailbox(session, " INBOX " )
// Get the number of messages in the inbox.
msgCount = imap.status(session, inbox).messages
// Select the default inbox.
inbox | > imap.examine(session, _)
// Get the headers (date, from and subject) for each message, from oldest to newest, format and
// print them.
headers =
iota(msgCount)
| > map(id => " # " ~ toString(id + 1 ))
| > map(id =>
imap.fetchFields(session, id, " date from subject " ).lines
| > map(hdr => fmtField(hdr, 40 )))
| > fold(fmtHeaders, " INBOX: n " )
print(headers)Das dritte Code -Beispiel veranschaulicht einige der ungewöhnlichen Funktionen dieser DSL, mit dem Ziel, dass ChatGPT diese als nächstes in seinen eigenen Implementierungen verwenden wird.
// This script will create a report based on a specific example set of automated 'support' emails.
// E.g.,
//
// "support.mbox": 17 messages 17 new
// N 1 [email protected] Mon May 11 22:26 28/1369 "Alert: new issue 123"
// N 2 [email protected] Tue May 12 12:20 22/933 "Notification: service change"
// N 3 [email protected] Tue May 12 12:36 26/1341 "Alert: new issue 124"
// N 4 [email protected] Wed May 13 02:13 21/921 "Resolution: issue 124"
// N 5 [email protected] Wed May 13 18:53 26/1332 "Email not from robot."
// N 6 [email protected] Thu May 14 03:13 27/1339 "Alert: new issue 125"
// N 7 [email protected] Thu May 14 08:46 26/1270 "Resolution: issue 123"
// N 8 [email protected] Thu May 14 17:06 25/1249 "Alert: new issue 126"
// N 9 [email protected] Fri May 15 09:46 24/1185 "Resolution: issue 126"
// N 10 [email protected] Fri May 15 12:33 23/1052 "Alert: new issue 127"
// N 11 [email protected] Fri May 15 15:20 27/1331 "Notification: service change"
// N 12 [email protected] Fri May 15 18:06 23/953 "Resolution: issue 127"
// N 13 [email protected] Mon May 18 12:46 27/1218 "Alert: new issue 128"
// N 14 [email protected] Mon May 18 15:33 32/1628 "Alert: new issue 129"
// N 15 [email protected] Tue May 19 05:26 25/1176 "Resolution: issue 128"
// N 16 [email protected] Tue May 19 08:13 26/1312 "Notification: service change"
// N 17 [email protected] Tue May 19 11:00 28/1275 "Alert: new issue 130"
//
//
// Each of these automated emails are from `robot` _except_ for message 5. Messages 2, 8 and 16 are
// from `robot` but are unrelated to issues.
//
// This script will search for emails and match new issue numbers with resolutions to report the
// number of outstanding alerts.
import imap
import * from imap.query
import imap_config
import dates
import string
// Get the configuration from the environment and command line.
config = imap_config.getConfig(commandLineArguments)
// Connect to the inbox.
creds = imap.ImapLogin(config.user, config.pass)
server = imap.ImapServer(config.host, config.port)
session =
imap.Session(server, creds)
| > imap.openConnection()
| > imap.login()
inbox = imap.Mailbox(session, " support " )
// Select the default inbox.
inbox | > imap.examine(session, _)
// These criteria are common for both our searches.
commonCrit = imap.Query()
| > and(from( ` [email protected] ` ))
| > and(sentSince(dates. Date ( 2020 , 5 , 13 )))
// Get each of the alerts and resolutions from the past week (13-19 May 2020).
alertMsgIds =
imap.search(session, imap.Query(subject( " Alert: new issue " )) | > and(commonCrit)).ids
resolutionMsgIds =
imap.search(session, imap.Query(subject( " Resolution: issue " )) | > and(commonCrit)).ids
// A function to get the alert ID from a message subject.
getAlertId(msgId) => {
imap.fetchFields(session, toString (msgId), " subject " ).lines[ 0 ]
| > string .split()[$ - 1 ]
}
// A function to remove an entry from a table whether it's there or not.
removeIfExists(tbl, key) => {
if find( keys (tbl), key) == [] then
tbl
else
removeEntry(tbl, key)
}
// Now find those alerts which have no resolution. Firstly the subject for each alert, get the
// issue number end and store it in a table.
allAlertTable = alertMsgIds | > fold((tbl, msgId) => addEntry(tbl, getAlertId(msgId), msgId), {})
// Go through the resolutions and remove their corresponding alerts from the table.
unresolvedAlertTable =
resolutionMsgIds | > fold((tbl, msgId) => removeIfExists(tbl, getAlertId(msgId)), allAlertTable)
// Create a report with the date of the unresolved alerts.
report =
keys (unresolvedAlertTable)
| > map(alertId => {
msgId = unresolvedAlertTable[alertId] | > toString
in [ alertId
, imap.fetchFields(session, msgId, " date " ).lines[ 0 ]
, imap.fetchText(session, msgId).lines[ 0 ]
]
})
| > fold((outStr, tuple) => {
outStr ~ " Issue: " ~ tuple[ 0 ] ~ " n " ~ tuple[ 1 ] ~ " n Summary: " ~ tuple[ 2 ] ~ " n "
}, " n UNRESOLVED ISSUES FROM THE PAST 10 DAYS: nn " )
// Close the session.
imap.closeConnection(session)
// Print the report last.
print(report) Als erste Übung habe ich das Modell gebeten, eine sehr einfache relationale Datenbank in SIL mit grundlegenden Funktionen zu implementieren (beachten Sie, dass // ein Kommentar in SIL bezeichnet).
import imap
import imap_config
import string
// Get the configuration from the environment and command line.
config = imap_config.getConfig(commandLineArguments)
// Connect to the server.
creds = imap.ImapLogin(config.user, config.pass)
server = imap.ImapServer(config.host, config.port)
session =
imap.Session(server, creds)
| > imap.openConnection()
| > imap.login()
// -------------------------------------------------------------------------------------------------
// Here's an attempt to create something resembling a simple relational database.
// Define two tables, 'Employees' and 'Departments'.
Employees = { " 1 " : [ " Alice " , " Engineering " ], " 2 " : [ " Bob " , " Marketing " ], " 3 " : [ " Charlie " , " Engineering " ] }
Departments = { " Engineering " : [ " Alice " , " Charlie " ], " Marketing " : [ " Bob " ] }
// Function to emulate SQL SELECT operation.
select = (table, id) => {
table[id] | > enforce( " Id does not exist in table. " )
}
// Function to emulate SQL INSERT operation.
insert = (table, id, values ) => {
addEntry(table, id, values )
}
// Function to emulate SQL DELETE operation.
delete = (table, id) => {
removeEntry(table, id)
}
// Function to emulate SQL JOIN operation.
join = (table1, table2, commonField) => {
// This is a very basic JOIN operation and does not account for multiple matches, etc.
joinedTable = {}
for key in keys (table1) {
value = table1[key][commonField]
if find( keys (table2), value) != [] {
joinedTable = addEntry(joinedTable, key, [table1[key], table2[value]])
}
}
joinedTable
}
// Close the session.
imap.closeConnection(session)
// Perform operations.
newEmployee = [ " David " , " Marketing " ]
Employees = insert(Employees, " 4 " , newEmployee)
Departments = insert(Departments, newEmployee[ 1 ], [ " David " ])
print(select(Employees, " 1 " ))
print(join(Employees, Departments, 1 ))Das Implementieren von Sortieralgorithmen ist eine archetypische Frage der Software -Engineering -Interview. Hier bat ich GPT-4, Bubblesort (konzeptionell den grundlegendsten Sortieralgorithmus) in SIL implementieren. Unten ist die Antwort:
// Helper function to bubble up the largest value in one pass
bubble(list) => {
if length(list) <= 1 then
list
else
if list[ 0 ] > list[ 1 ] then
[list[ 1 ]] ~ bubble([list[ 0 ]] ~ list[ 2 to $])
else
[list[ 0 ]] ~ bubble(list[ 1 to $])
}
// Main BubbleSort function
bubbleSort(list) => {
bubbled = bubble(list)
if bubbled == list then
list
else
bubbleSort(bubbled)
} Als nächstes forderte ich das Modell auf, ein Skript zum Berechnen des Medianes einer Liste zu schreiben (generierte Antwort unten). Die Helfer-Funktions sortList stimmt tatsächlich mit funktionalen Programmierparadigmen überein, aber hier setzt GPT-4 die Existenz des Zuweisungsoperators an := .
// Helper function to sort an array of integers.
sortList(list) => list | > len | > iota | > map(i => list | > min | > snd) | > each((i, minVal) => list := removeIndex(list, minVal))
// Function to compute the median of a set of integers.
computeMedian(list) => {
// Sort the list in ascending order.
sortedList = sortList(list)
// Get the length of the list.
length = len(sortedList)
// Check if the length is even.
isEven = length % 2 == 0
// If the length is even, the median is the average of the two middle numbers.
// Otherwise, the median is just the middle number.
median =
if isEven then
(sortedList[length / 2 - 1 ] + sortedList[length / 2 ]) / 2
else
sortedList[length / 2 ]
// Return the median.
median
} GPT -4 wurde als nächstes veranlasst, den k -nachträglichen Nachbarnalgorithmus in SIL implementieren. Abgesehen von der Halluzinierung/Annahme der Existenz eines Moduls namens math (das wohl eine vernünftige Annahme für den Umfang dieser Übung ist), scheint dies eine akzeptable Lösung zu sein, die funktionelle Operatoren wie |> , map und fold angemessen nutzt.
import math
distance(p1, p2) => {
math.sqrt(
math.pow(p1[ 0 ] - p2[ 0 ], 2 )
+ math.pow(p1[ 1 ] - p2[ 1 ], 2 )
)
}
majorityVote(labels) => {
labelCounts = labels | > fold((counts, label) => addEntry(counts, label, get (counts, label, 0 ) + 1 ), {})
labelCounts | > maxBy((_, count) => count)
}
knn(data, newPoint, k) => {
distances = data | > map((point, label) => (distance(point, newPoint), label))
sorted = distances | > sort((a, b) => a[ 0 ] < b[ 0 ])
nearest = sorted | > take(k)
labels = nearest | > map((_, label) => label)
majorityVote(labels)
}
Eines der interessanten Merkmale funktionaler Sprachen ist, dass sie sehr ausdrucksstark sein können. Hier forderte ich GPT-4 dazu auf, die grundlegenden Funktionsbetreiber- map zu implementieren, filter und reduce (oder im Kontext von Funktionssprachen fold ).
// map
// The map-like function would take a function and a list, and apply the function to each element in the list.
mapList(func, list) => {
len(list) > 0 | > enforce( " Cannot map over an empty list. " )
in iota (len(list)) | > fold((result, i) => addEntry(result, func(list[i])), [])
}
// filter
// The filter-like function would take a predicate and a list, and return a list of elements for which the predicate returns true.
filterList(pred, list) => {
len(list) > 0 | > enforce( " Cannot filter an empty list. " )
in iota (len(list)) | > fold((result, i) => if pred(list[i]) then addEntry(result, list[i]) else result, [])
}
// reduce
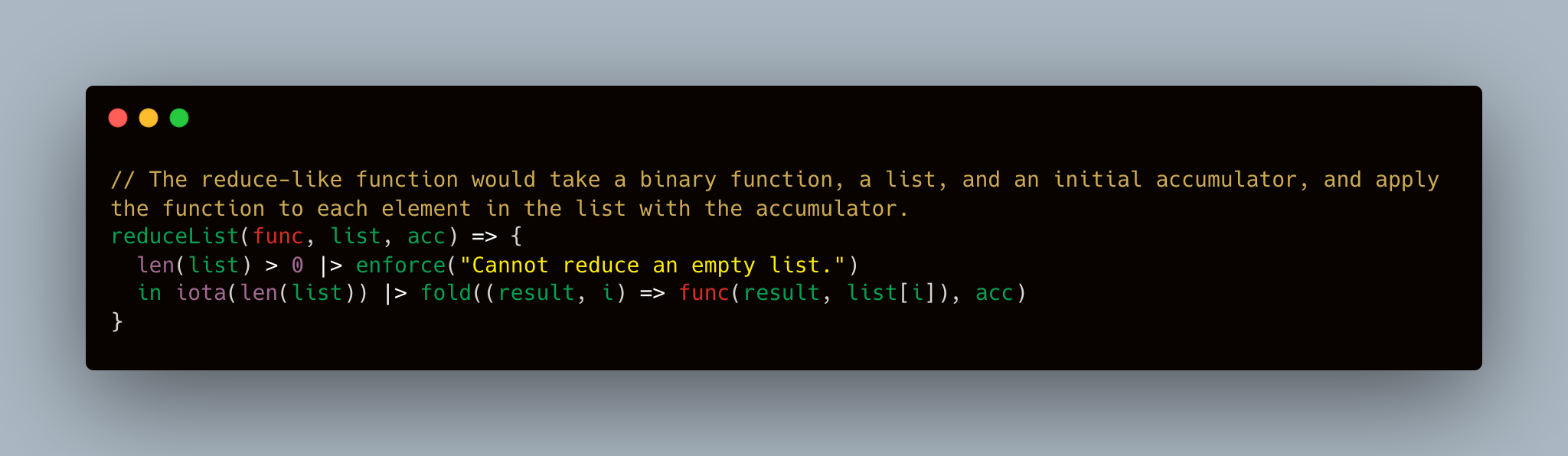
// The reduce-like function would take a binary function, a list, and an initial accumulator, and apply the function to each element in the list with the accumulator.
reduceList(func, list, acc) => {
len(list) > 0 | > enforce( " Cannot reduce an empty list. " )
in iota (len(list)) | > fold((result, i) => func(result, list[i]), acc)
}
Project Euler ist eine Sammlung mathematischer und Programmierprobleme (von denen ich denke, dass sie interessante Eingabeaufforderungen für LLMs erstellen). Hier fordere ich GPT-4 auf, die ersten beiden Projekte Euler mit SIL zu lösen.
// Project Euler problem #1:
// Here, my prompt was to solve the (easy) first problem of the Project Euler series (https://projecteuler.net/problem=1)
// Define a range from 1 to 999.
range = iota( 999 ) | > map(x => x + 1 )
// Define a function to check if a number is a multiple of 3 or 5.
isMultipleOf3Or5 = (num) => num % 3 == 0 || num % 5 == 0
// Filter the range to get only multiples of 3 or 5.
multiples = range | > filter(isMultipleOf3Or5)
// Sum the multiples.
sum = multiples | > fold((a, b) => a + b, 0 )
// Print the sum.
print(sum)
// Project Euler problem #2:
// This prompt is to solve the second Project Euler problem (https://projecteuler.net/problem=2)
// Define a function to generate the next term in the Fibonacci sequence.
nextFibonacciTerm = (tuple) => [tuple[ 1 ], tuple[ 0 ] + tuple[ 1 ]]
// Start with the first two terms.
initialTerms = [ 1 , 2 ]
// Define a function to generate Fibonacci sequence up to a limit.
generateFibonacci = (limit) => {
fibonacciSequence = unfold(nextFibonacciTerm, initialTerms, (tuple) => tuple[ 1 ] <= limit)
fibonacciSequence
}
// Define a function to check if a number is even.
isEven = (num) => num % 2 == 0
// Generate the Fibonacci sequence up to four million.
fibonacciSequence = generateFibonacci( 4000000 )
// Extract the second term from each tuple in the sequence, which is the actual Fibonacci number.
fibonacciNumbers = fibonacciSequence | > map(tuple => tuple[ 1 ])
// Filter the sequence to get only even numbers.
evenFibonacciNumbers = fibonacciNumbers | > filter(isEven)
// Sum the even numbers.
sum = evenFibonacciNumbers | > fold((a, b) => a + b, 0 )
// Print the sum.
print(sum)
Die Erforschung der Fähigkeit von LLMs, die Merkmale einer neuartigen Programmiersprache auf eine offene Weise zu schließen und zu verstehen, bleibt eine offene und interessante Frage. Hier wurden diese Kapazitäten im Kontext von GPT-4 untersucht, um zu Problemen in einer neuartigen domänenspezifischen Sprache (DSL) namens SIL zu lösen. DSLs sind ein potenziell nützlicher Testfall für die Erforschung von Inferenz- und Auswendiglernen in LLMs, da sie häufig charakteristische Merkmale aufweisen und während des Trainings weniger wahrscheinlich auftreten (wenn überhaupt).
Die vielleicht interessanteste Erkenntnis dieser Übung ist, dass die wenigen Schuss-Inferenzfähigkeiten von GPT-4 deutlich besser sind als die von ChatGPT, wenn sie an denselben Eingabeaufforderungen und Aufgaben bewertet werden (siehe Analoge Übung mit ChatGPT hier).
Es gibt Hinweise darauf, dass die LLM -Memorisierung durch die Häufigkeit der Trainingsbeispiele und die Anzahl der relevanten Token gefördert wird, die zur Aufforderung des Modells verwendet werden. ↩


