llm github issues
1.0.0
該項目是使用大型語言模型(LLM)進行摘要的學習練習。它使用GitHub問題作為我們可以與之相關的實際用例。
目的是允許開發人員了解問題中正在報告和討論的內容,而不必閱讀線程中的每個消息。我們將帶有其評論的原始GitHub問題,並產生這樣的摘要。
更新2024-07-21 :隨著GPT-4O Mini的宣布,使用GPT-3.5型號的理由越來越少。我更新了代碼,以使用GPT-4O和GPT-4O迷你型號並刪除GPT-4 Turbo模型(它們在“我們支持的較舊型號”下列出,暗示它們最終將被刪除)。
我們將回顧以下主題:
該YouTube視頻瀏覽了以下各節,但請注意,它使用了代碼的第一個版本。從那以後,該代碼已更新。
在開始之前,讓我們回顧一下當我們使用LLMS總結GitHub問題時,幕後會發生什麼。
下圖顯示了主要步驟:
測序圖
自動化器
演員u作為用戶
參與者應用程序作為應用程序
參與者GH作為GitHub API
參與者llm作為llm
u- >>應用:輸入url到github問題
應用 - >> GH:請求問題數據
GH- >>應用:以JSON格式返回問題數據
應用程序 - >>應用:將JSON放入緊湊的文本格式
應用程序 - >>應用:構建llm的提示
應用程序 - >> LLM:將請求發送到LLM
llm- >>應用:返迴響應和用法數據(令牌)
應用 - >> U:顯示響應和使用數據
現在,我們將更詳細地查看每個步驟。
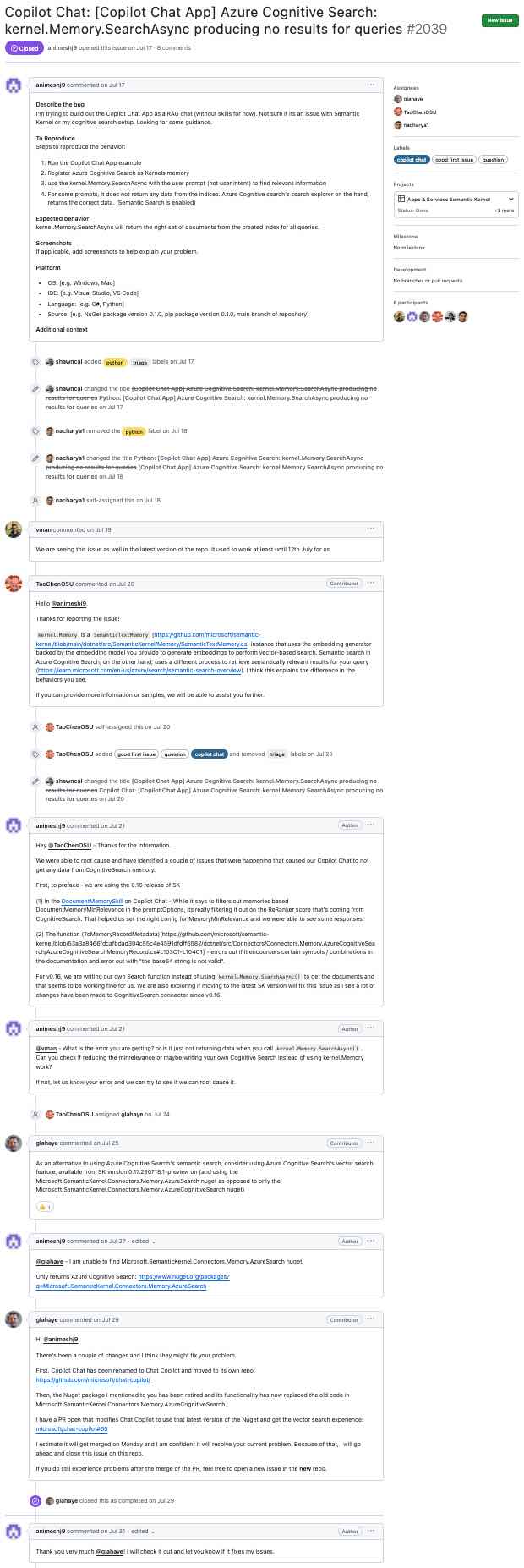
本節介紹了從類似GitHub問題進行的步驟(單擊放大)...
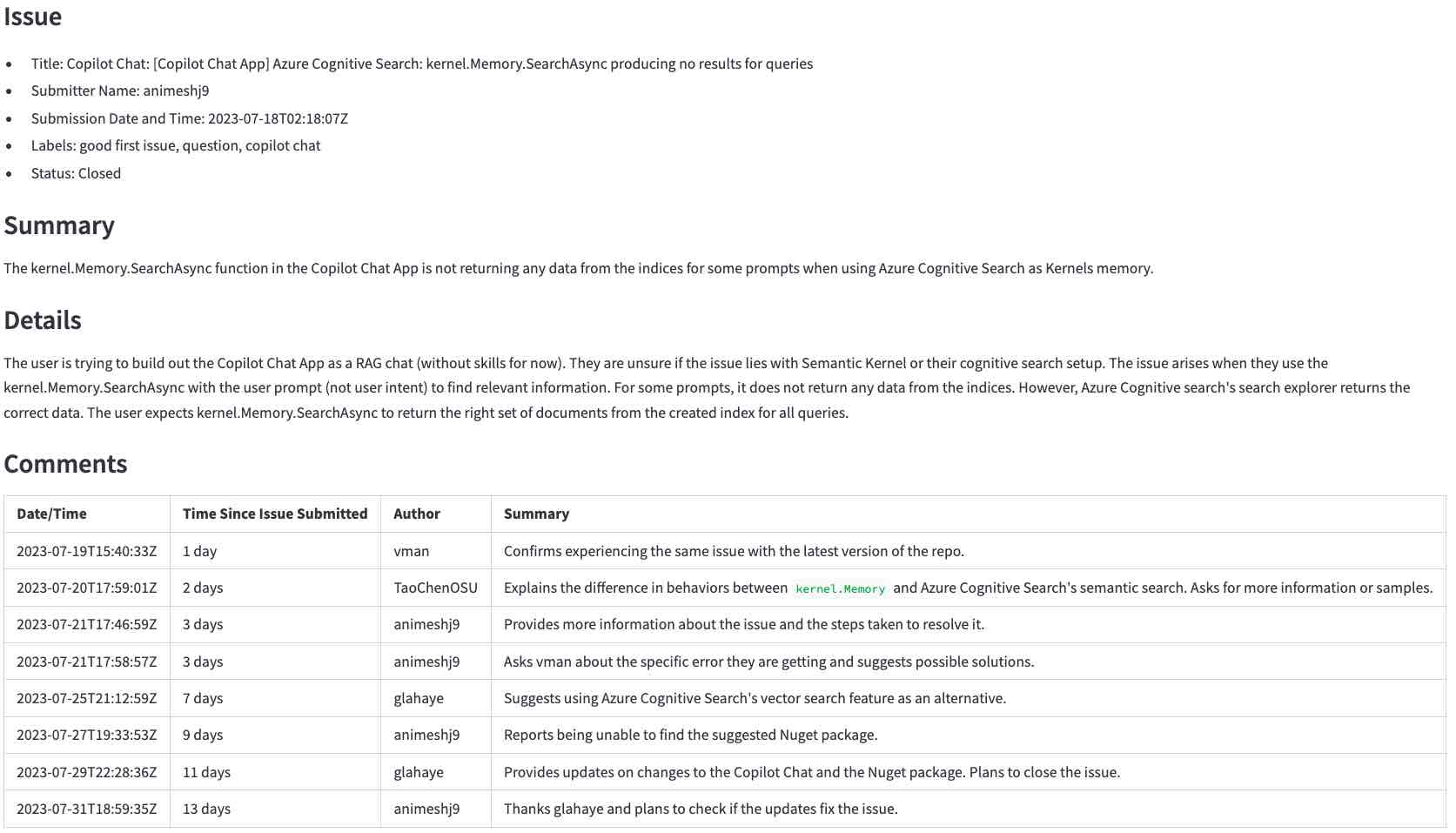
...要llm生成的摘要(單擊以放大):
首先,如果您還沒有這樣做,請準備環境。
運行以下命令以激活環境並在瀏覽器中啟動應用程序。
source venv/bin/activate
streamlit run app.py應用程序運行後,輸入上述問題的URL, https://github.com/microsoft/semantic-kernel/issues/2039 ,然後單擊Generate summary with <model>以生成摘要。要完成需要幾秒鐘。
注意:
在以下各節中,我們將在幕後查看應用程序的工作原理。
本節介紹了使用LLMS總結GitHub問題的步驟。我們將首先獲取問題數據,預處理數據,建立適當的提示,將其發送到LLM,最後處理響應。
第一步是使用GitHub API獲取原始數據。在此步驟中,我們將用戶輸入的URL轉換為GitHub API URL,並請求該問題及其註釋。例如,將URL https://github.com/microsoft/semantic-kernel/issues/2039轉化為https://api.github.com/repos/microsoft/semantic-kernel/issues/2039 。 GitHub API返回帶有問題的JSON對象。單擊此處查看問題的JSON對象。
該問題具有指定的鏈接:
"comments_url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039/comments",
我們使用該URL請求評論並獲取另一個JSON對象。單擊此處查看評論的JSON對象。
JSON對象的信息超出了我們的需求。在將請求發送到LLM之前,我們需要出於以下原因提取所需的部分:
在此步驟中,我們將JSON對象轉換為緊湊的文本格式。文本格式比JSON對象更容易處理,並且佔用空間少。
這是GitHub API返回的JSON對象的開始。
{
"url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039",
"repository_url": "https://api.github.com/repos/microsoft/semantic-kernel",
"labels_url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039/labels{/name}",
"comments_url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039/comments",
"events_url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039/events",
"html_url": "https://github.com/microsoft/semantic-kernel/issues/2039",
"id": 1808939848,
"node_id": "I_kwDOJDJ_Yc5r0jtI",
"number": 2039,
"title": "Copilot Chat: [Copilot Chat App] Azure Cognitive Search: kernel.Memory.SearchAsync producing no ...
"body": "**Describe the bug**rnI'm trying to build out the Copilot Chat App as a RAG chat (without
skills for now). Not sure if its an issue with Semantic Kernel or my cognitive search...
...many lines removed for brevity...
package version 0.1.0, pip package version 0.1.0, main branch of repository]rnrn**Additional
context**rn",
...
這是我們從中創建的緊湊文本格式。
Title: Copilot Chat: [Copilot Chat App] Azure Cognitive Search: kernel.Memory.SearchAsync producing no
results for queries
Body (between '''):
'''
**Describe the bug**
I'm trying to build out the Copilot Chat App as a RAG chat (without skills for now). Not sure if its an
issue with Semantic Kernel or my cognitive search setup. Looking for some guidance.
...many lines removed for brevity...
要從JSON對象獲得緊湊的文本格式,我們執行以下操作:
repository_url , node_id等。{"title": "Copilot Chat: [Copilot Chat App] Azure ...變為Title: Copilot Chat: [Copilot Chat App] Azure ...Body (between ''')告訴LLM問題的主體是在'''字符之間。單擊此處查看此步驟的結果。與此問題的JSON對象進行比較,並評論以查看文本格式的較小程度。
提示告訴LLM如何做什麼以及所需的數據。
我們的提示存儲在此文件中。提示指示LLM總結我們想要的格式的問題和評論( “不要浪費...”部分來自此示例)。
You are an experienced developer familiar with GitHub issues.
The following text was parsed from a GitHub issue and its comments.
Extract the following information from the issue and comments:
- Issue: A list with the following items: title, the submitter name, the submission date and
time, labels, and status (whether the issue is still open or closed).
- Summary: A summary of the issue in precisely one short sentence of no more than 50 words.
- Details: A longer summary of the issue. If code has been provided, list the pieces of code
that cause the issue in the summary.
- Comments: A table with a summary of each comment in chronological order with the columns:
date/time, time since the issue was submitted, author, and a summary of the comment.
Don't waste words. Use short, clear, complete sentences. Use active voice. Maximize detail, meaning focus on the content. Quote code snippets if they are relevant.
Answer in markdown with section headers separating each of the parts above.
現在,我們需要將請求發送到LLM所需的所有部分。不同的LLM具有不同的API,但其中大多數具有以下參數的變化:
這些是我們在這個項目中使用的主要項目。我們可以針對其他用例調整其他參數。
這是llm.py中的相關代碼:
completion = client . chat . completions . create (
model = model ,
messages = [
{ "role" : "system" , "content" : prompt },
{ "role" : "user" , "content" : user_input },
],
temperature = 0.0 # We want precise and repeatable results
)LLM返回帶有響應和使用數據的JSON對象。我們顯示對用戶的響應,並使用使用數據來計算請求的成本。
這是LLM(使用OpenAI API)的示例響應:
ChatCompletion (..., choices = [ Choice ( finish_reason = 'stop' , index = 0 , message = ChatCompletionMessage ( content =
'<response removed to save space>' , role = 'assistant' , function_call = None ))], created = 1698528558 ,
model = 'gpt-3.5-turbo-0613' , object = 'chat.completion' , usage = CompletionUsage ( completion_tokens = 304 ,
prompt_tokens = 1301 , total_tokens = 1605 ))除了響應外,我們還獲得了令牌用法。成本不是回應的一部分。我們必鬚根據已發表的定價規則來計算自己。
在這一點上,我們擁有向用戶顯示響應所需的一切。
在本節中,我們將回顧一些如何在應用程序中使用LLM的示例。我們將從效果很好的簡單案例開始,然後繼續進行事物的行為不像預期以及如何圍繞它們工作的情況。
這是以下各節所涵蓋的摘要。
我們將從一個簡單的案例開始,以了解LLM的總結。
使用以下命令啟動用戶界面。
source venv/bin/activate
streamlit run app.py然後在樣本列表中選擇第一個問題, <https://github.com/openai/openai-python/issues/488> (simple example) ,然後單擊“使用...生成摘要”按鈕。
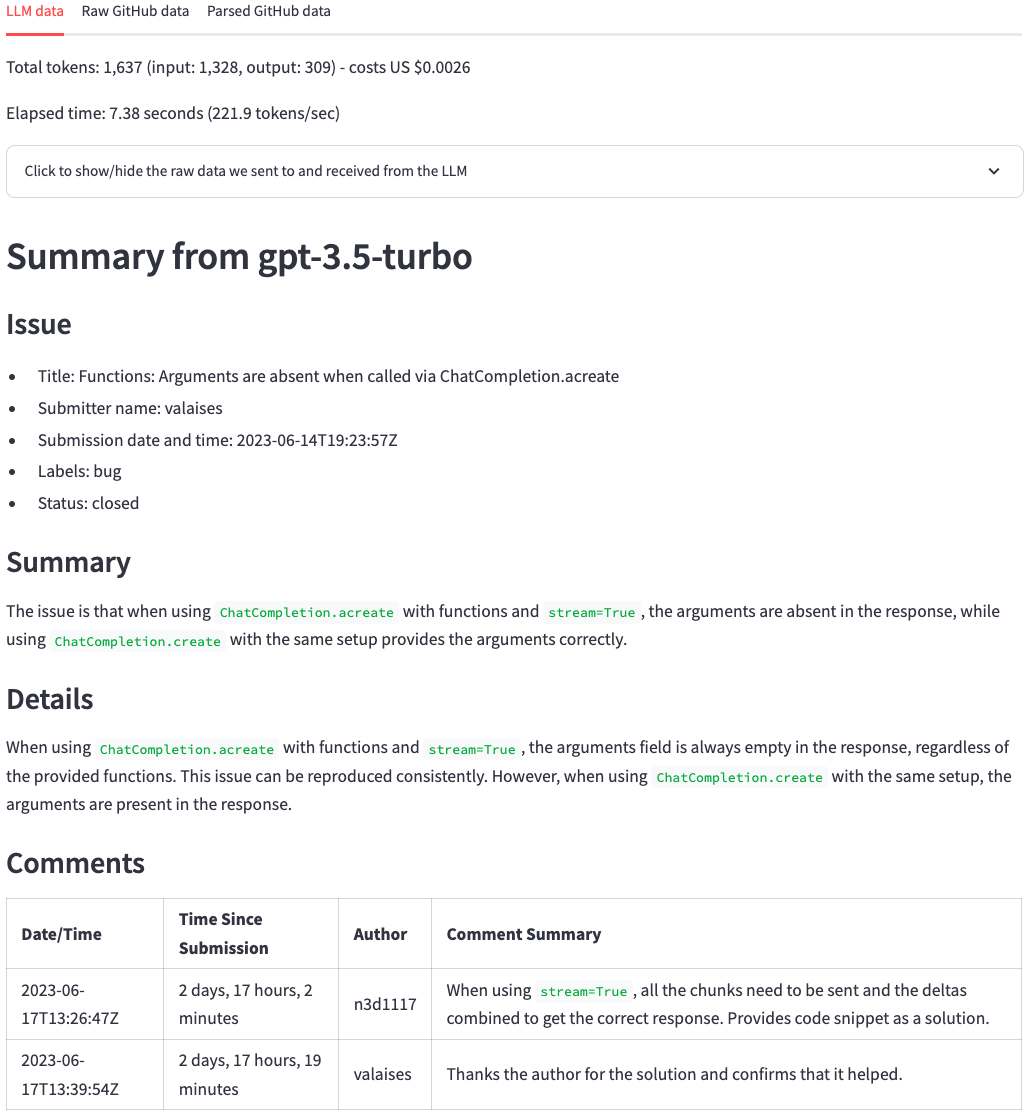
幾秒鐘後,我們應該得到以下圖片的摘要。在頂部,我們可以看到令牌計數,成本(源自令牌計數)以及LLM生成摘要所需的時間。之後,我們看到LLM的回應。與原始的GitHub問題相比,LLM總結了問題要點和評論的出色工作。乍一看,我們可以看到問題的要點及其評論。
現在選擇問題https://github.com/scikit-learn/scikit-learn/issues/9354 ... ,然後單擊“使用...生成摘要”按鈕。請勿更改LLM模型。
由於此錯誤,它將失敗:
Error code: 400 - {'error': {'message': "This model's maximum context length is 16385 tokens. However, your messages resulted in 20437 tokens. Please reduce the length of the messages.", 'type': 'invalid_request_error', 'param': 'messages', 'code': 'context_length_exceeded'}}
每個LLM一次可以處理的令牌數量限制。此限制是上下文窗口大小。上下文窗口必須符合我們要匯總的信息和摘要本身。如果我們要匯總的信息大於上下文窗口,如我們在這種情況下所見,LLM將拒絕請求。
有幾種解決此問題的方法:
我們將使用第二個選項。單擊屏幕頂部的“單擊以配置提示和模型” ,選擇GPT-4O模型,然後單擊“使用GPT-4O生成摘要”按鈕。
現在,我們從LLM獲得了一個摘要。但是,請注意,生成摘要並成本更高將需要更長的時間。
我們為什麼不從GPT-4O開始以避免此類問題?錢。通常,具有較大上下文Windows的LLMS成本更高。如果我們使用諸如OpenAI之類的AI提供商,則必須為每個令牌支付更多。如果我們自己運行模型,我們需要購買更強大的硬件。無論哪種方式,使用較大的上下文窗口的成本更高。
由於使用GPT-4O,我們也獲得了更好的摘要。
為什麼我們從一開始就不使用GPT-4O?除上述原因(金錢)外,還有更高的延遲。通常,更好的模型也更大。他們需要更多的硬件來運行,轉化為每個令牌的成本更高,並更長的時間來產生響應。
我們可以看到比較令牌計數,成本和時間的差異,以生成GPT-3.5-Turbo和GPT-4O模型之間的摘要。
我們如何選擇模型?這取決於用例。從產生良好結果的最小(因此更便宜,更快)的模型開始。創建一些啟發式方法來決定何時使用更強大的模型。例如,如果註釋大於某個尺寸,並且用戶願意等待更長的結果(有時平均結果更快比以後的完美結果更好),請切換到更大的模型。
先前的部分將GPT-3.5 Turbo與GPT-4O進行了比較,以強調較小模型和較大模型之間的差異。但是,在2024年7月,OpenAI推出了GPT-4O Mini型號。它具有與GPT-4O型號相同的128K令牌上下文窗口,但成本要低得多。它甚至比GPT-3.5型號便宜。有關詳細信息,請參見OpenAI API定價。
GPT-4O(非迷你)仍然是一個更好的模型,但其價格和延遲可能無法證明更好的結果是合理的。例如,下表顯示了一個大問題的摘要( https://github.com/qjebbs/vscode-plantuml/issues/255 )。 GPT-4O在左側,GPT-4O Mini在Mini上。成本的差異是驚人的,但是結果並沒有太大不同。
消息是,除非您有使用GPT-3.5 Turbo的特定原因,否則應使用GPT-4O Mini模型開始一個新項目。它將產生與GPT-4O相當的結果,而少於GPT-3.5渦輪增壓成本。
| GPT-4O摘要 | GPT-4O迷你摘要 |
|---|---|
| 3,859代幣,US $ 0.0303 | 4,060,令牌,US $ 0.0012 |
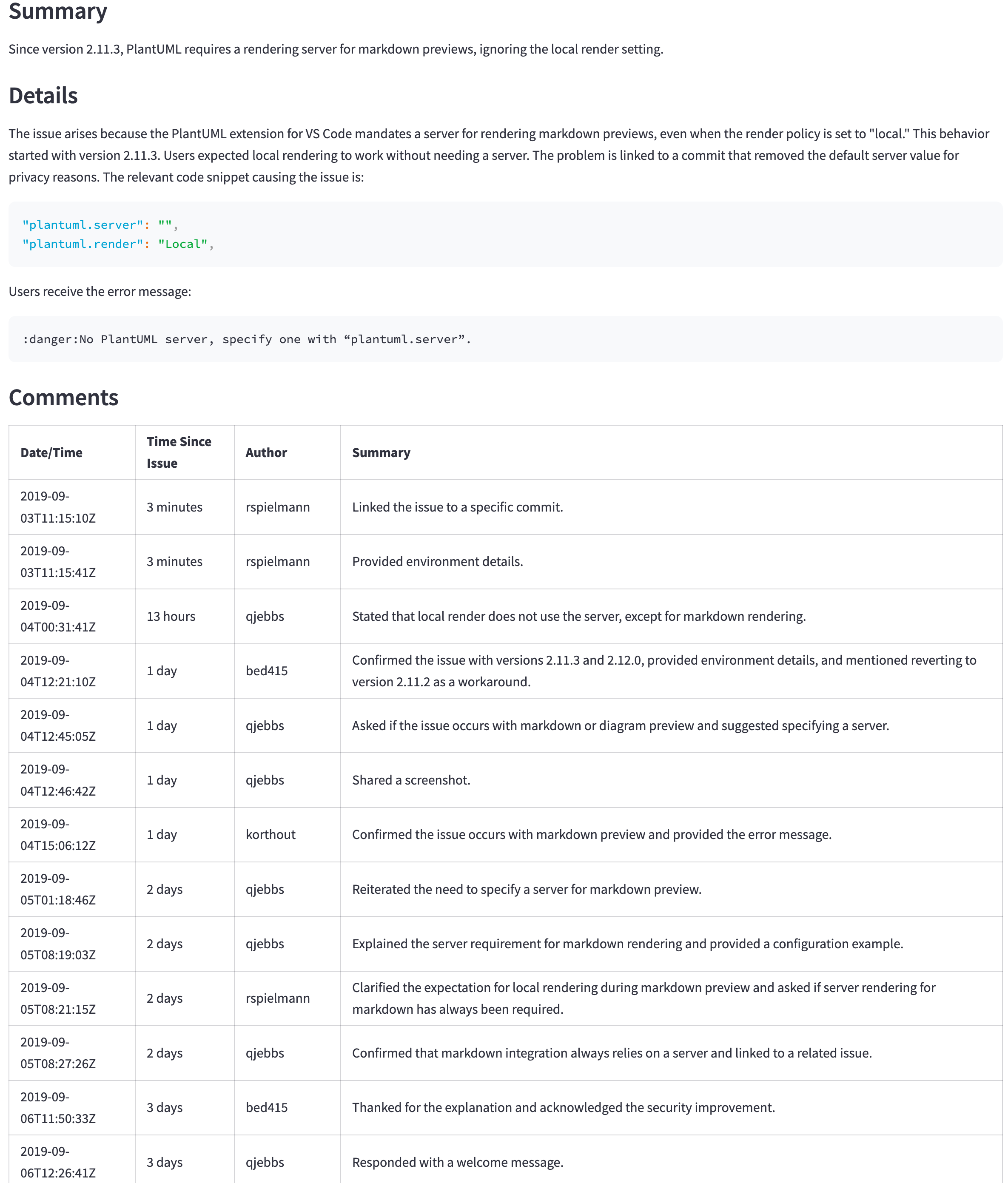 | 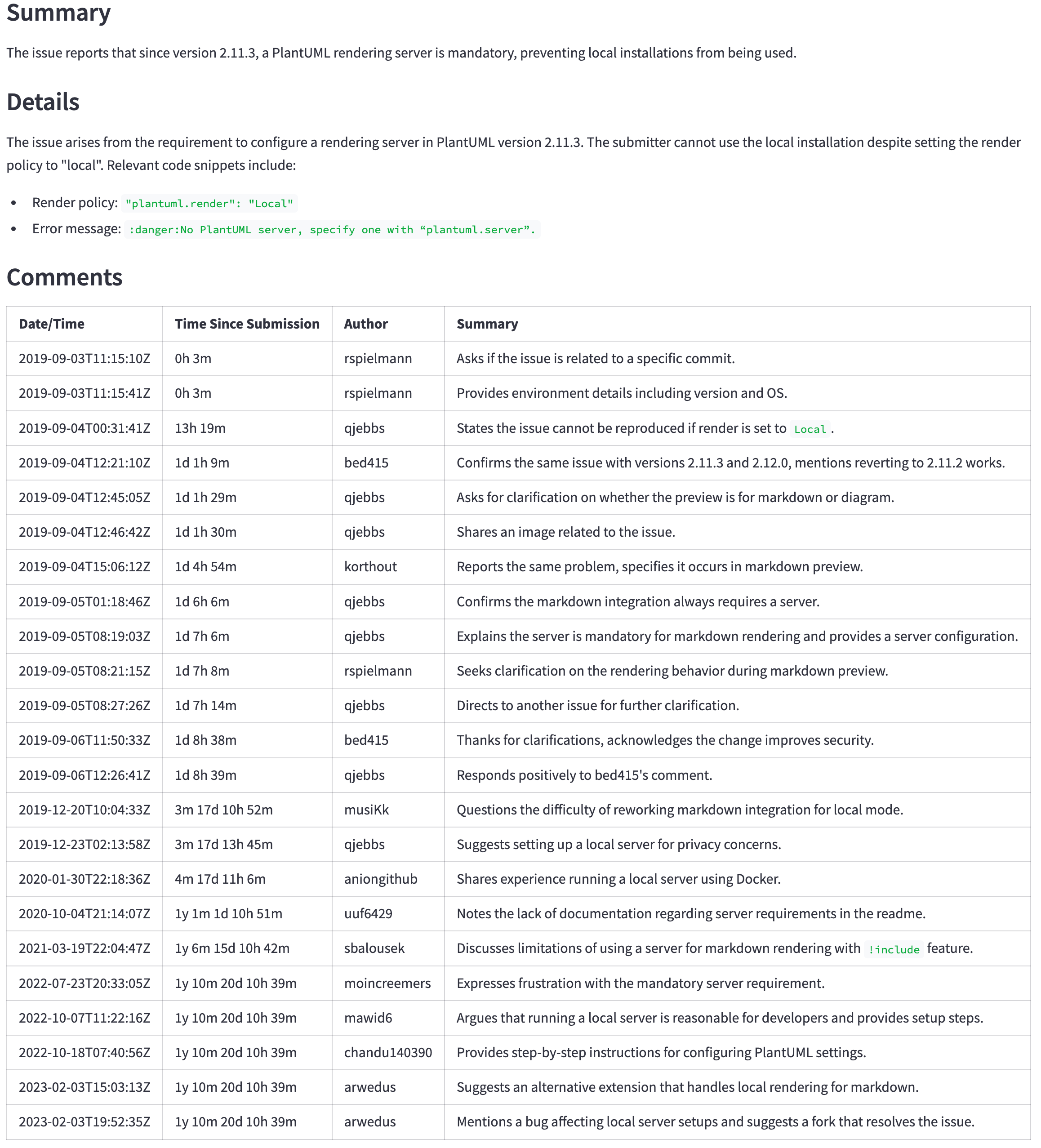 |
提示中的精確說明對於獲得良好的結果很重要。為了說明好提示帶來的區別:
https://github.com/openai/openai-python/issues/488 。我們得到這樣的評論的摘要。

如果我們從提示中刪除“不要浪費單詞。請使用簡短,清晰,完整的句子。使用主動語音。最大化細節,意思是關注內容。引用代碼片段(如果相關)。” ,我們得到這個摘要。注意文本如何更詳細,並且確實是“浪費單詞”。

要刪除該行,請單擊屏幕頂部的“單擊以配置提示和模型” ,然後從提示符中刪除行,然後再次單擊“使用...生成摘要”按鈕。重新加載頁面以還原行。
正確的提示仍然是一個實驗過程。它以及時工程的名稱為名。這些是一些參考,以了解有關及時工程的更多信息。
一旦我們得知我們可以用LLM總結文本,我們就可以將其用於所有內容。假設我們還想知道有關該問題的評論數量。我們可以通過將其添加到提示中來詢問LLM。
單擊屏幕頂部的“單擊以配置提示和模型” ,然後添加行- Number of comments in the issue到下面的提示。將所有其他線保持不變。
You are an experienced developer familiar with GitHub issues.
The following text was parsed from a GitHub issue and its comments.
Extract the following information from the issue and comments:
- Issue: A list with the following items: title, the submitter name, the submission date and
time, labels, and status (whether the issue is still open or closed).
- Number of comments in the issue <-- ** ADD THIS LINE **
...remainder of the lines...
LLM將返回許多評論,但通常會錯。例如,從樣本列表中選擇“問題” https://github.com/qjebbs/vscode-plantuml/issues/255 。這些模型均未正確獲得評論的數量。
為什麼?由於LLMS不是“執行”指令,因此它們只是一次生成一個令牌。
這是一個重要的概念。 LLM不了解文本的含義。他們只是根據以前的象徵選擇下一個令牌。它們不是代碼的替代品。
代替該怎麼辦?如果我們可以輕鬆訪問所需的信息,則應使用它。在這種情況下,我們可以從GitHub API響應中獲取評論數量。
issue , comments = get_github_data ( st . session_state . issue_url )
num_comments = len ( comments ) # <--- This is all we need 使用cli.py中的CLI代碼測試對代碼的修改。在CLI中調試代碼比精簡應用程序更容易。代碼在CLI中工作後,請調整簡化應用程序。
這是一個一次性步驟。如果您已經這樣做了,只需使用source venv/bin/activate激活虛擬環境。
準備環境有兩個步驟。
運行以下命令以創建虛擬環境並安裝所需的軟件包。
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install -r requirements.txt該代碼使用OpenAI GPT模型生成摘要。目前,這是開始使用LLM的最簡單方法之一。雖然OpenAI用於API訪問費用,但它給出了5美元的信貸,可以在使用GPT-4O Mini型號的小型項目中走很長一段路。為了避免賬單,您可以設置支出限額。
如果您已經擁有OpenAI帳戶,請在此處創建一個API密鑰。如果您沒有帳戶,請在此處創建一個帳戶。
擁有OpenAI API密鑰後,請在項目根目錄中創建一個.env文件,其中包含以下內容。
OPENAI_API_KEY= < your key >在這裡添加密鑰是安全的。它永遠不會致力於存儲庫。
該項目使您可以在文檔上詢問問題,並從LLM獲得答案。它使用與此項目類似的技術,但具有顯著差異:LLM在您的計算機上本地運行。


