llm github issues
1.0.0
このプロジェクトは、要約のために大規模な言語モデル(LLMS)を使用する学習演習です。 GitHubの問題を、私たちが関連することができる実用的なユースケースとして使用します。
目標は、開発者がスレッド内の各メッセージを読むことなく、問題で報告および議論されていることを理解できるようにすることです。オリジナルのGithubの問題をそのコメントで取り上げ、このような要約を生成します。
更新2024-07-21 :GPT-4O Miniの発表により、GPT-3.5モデルを使用する理由はますます少なくなります。 GPT-4OおよびGPT-4O MINIモデルを使用し、GPT-4ターボモデルを削除するためにコードを更新しました(「サポートする古いモデル」にリストされており、最終的に削除されることを示唆しています)。
次のトピックを確認します。
このYouTubeビデオは、以下のセクションを説明しますが、コードの最初のバージョンを使用していることに注意してください。それ以来、コードは更新されています。
開始する前に、LLMSを使用してGitHubの問題を要約したときに舞台裏で何が起こるかを確認しましょう。
次の図は、主な手順を示しています。
Sequendediagram
Autonumber
ユーザーとしての俳優u
アプリケーションとしての参加者アプリ
Github APIとしての参加者GH
LLMとしての参加者LLM
u- >>アプリ:githubの問題にurlを入力します
APP- >> GH:問題データを要求します
GH- >> APP:JSON形式の問題データを返します
APP- >> APP:JSONをコンパクトテキスト形式に解析します
アプリ - >>アプリ:LLMのプロンプトをビルドします
APP- >> LLM:LLMにリクエストを送信します
LLM- >>アプリ:応答と使用データを返す(トークン)
APP- >> U:応答と使用データを表示します
次に、各ステップを詳細に確認します。
このセクションでは、このようなgithub問題から行く手順について説明します(クリックして拡大)...
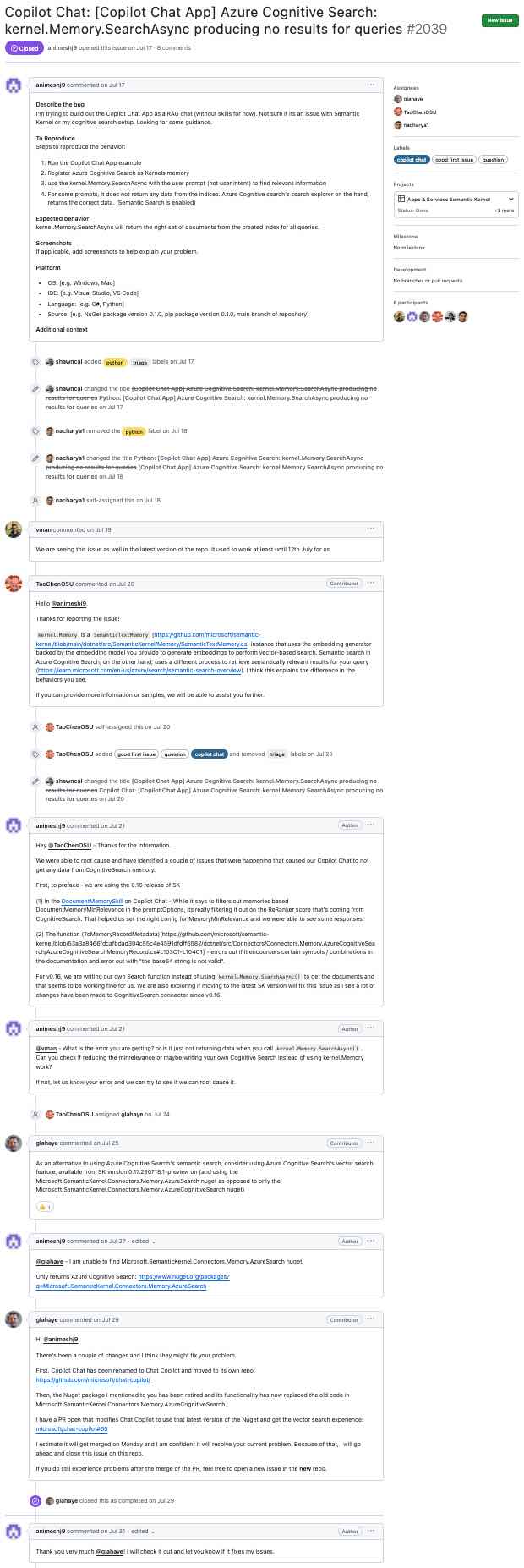
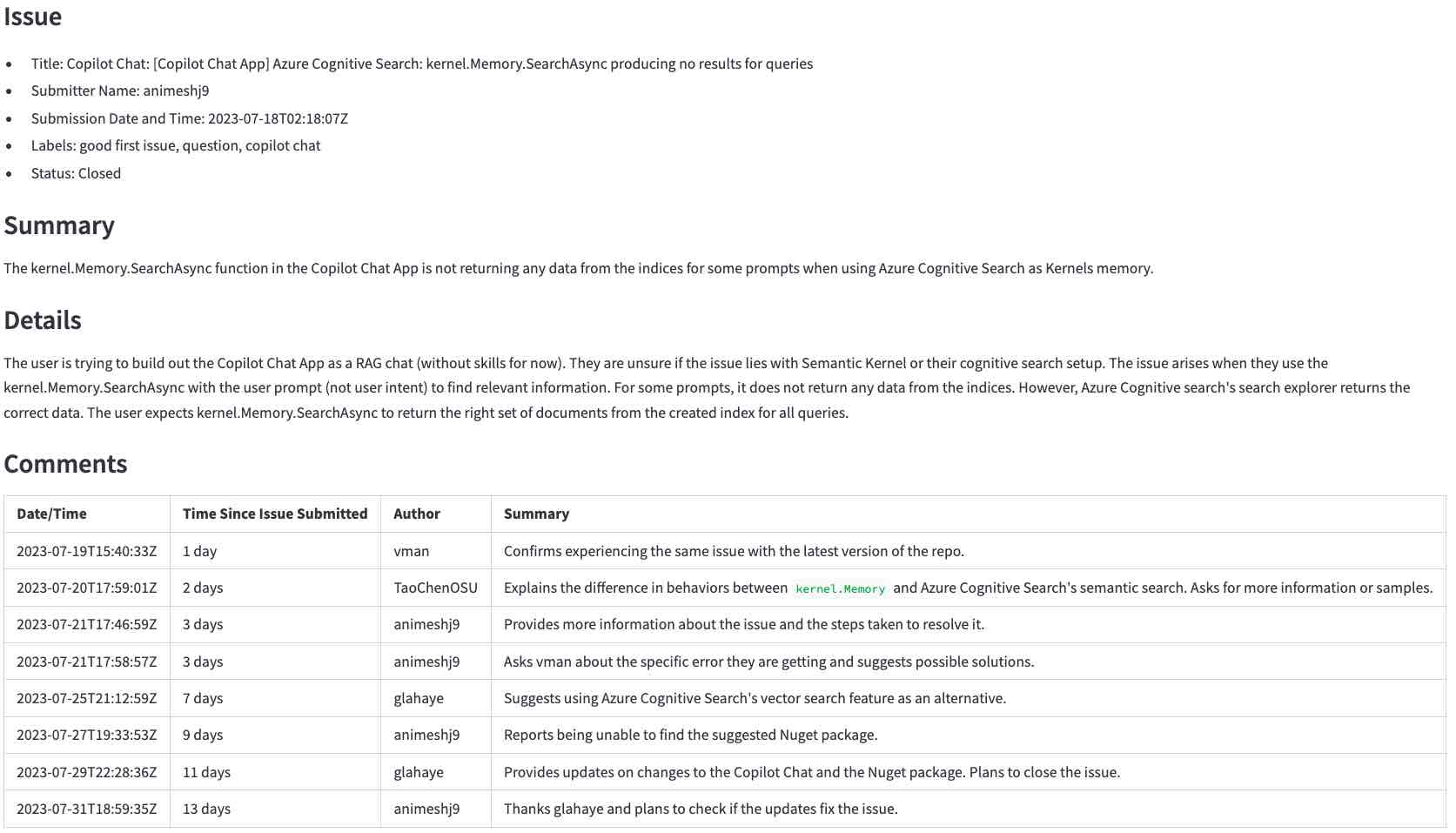
... LLMに生成された要約に(クリックして拡大):
まず、まだ行っていない場合は、環境を準備してください。
次のコマンドを実行して、環境をアクティブにし、ブラウザでアプリケーションを開始します。
source venv/bin/activate
streamlit run app.pyアプリケーションが実行されたら、上記の問題のURLを入力してくださいhttps://github.com/microsoft/semantic-kernel/issues/2039 、そしてGenerate summary with <model>をクリックして要約を生成します。完了するまでに数秒かかります。
注:
次のセクションでは、舞台裏でアプリケーションの仕組みを確認します。
このセクションでは、LLMSを使用してGitHubの問題を要約する手順について説明します。問題データを取得し、それを前処理し、適切なプロンプトを構築し、LLMに送信し、最後に応答を処理することから始めます。
最初のステップは、GitHub APIを使用して生データを取得することです。このステップでは、ユーザーがGitHub API URLに入力したURLを翻訳し、問題とそのコメントを要求します。たとえば、URL https://github.com/microsoft/semantic-kernel/issues/2039はhttps://api.github.com/repos/microsoft/semantic-kernel/issues/2039に翻訳されています。 GitHub APIは、JSONオブジェクトを問題で返します。ここをクリックして、この問題についてはJSONオブジェクトをご覧ください。
この問題には、コメントへのリンクがあります。
"comments_url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039/comments",
そのURLを使用してコメントを要求し、別のJSONオブジェクトを取得します。コメントについてはJSONオブジェクトを表示するには、ここをクリックしてください。
JSONオブジェクトには、必要以上の情報があります。リクエストをLLMに送信する前に、次の理由で必要なピースを抽出する必要があります。
このステップでは、JSONオブジェクトをコンパクトなテキスト形式に変換します。テキスト形式は処理が簡単で、JSONオブジェクトよりもスペースが少なくなります。
これは、問題のためにGitHub APIによって返されたJSONオブジェクトの開始です。
{
"url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039",
"repository_url": "https://api.github.com/repos/microsoft/semantic-kernel",
"labels_url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039/labels{/name}",
"comments_url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039/comments",
"events_url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039/events",
"html_url": "https://github.com/microsoft/semantic-kernel/issues/2039",
"id": 1808939848,
"node_id": "I_kwDOJDJ_Yc5r0jtI",
"number": 2039,
"title": "Copilot Chat: [Copilot Chat App] Azure Cognitive Search: kernel.Memory.SearchAsync producing no ...
"body": "**Describe the bug**rnI'm trying to build out the Copilot Chat App as a RAG chat (without
skills for now). Not sure if its an issue with Semantic Kernel or my cognitive search...
...many lines removed for brevity...
package version 0.1.0, pip package version 0.1.0, main branch of repository]rnrn**Additional
context**rn",
...
そして、これは私たちが作成するコンパクトなテキスト形式です。
Title: Copilot Chat: [Copilot Chat App] Azure Cognitive Search: kernel.Memory.SearchAsync producing no
results for queries
Body (between '''):
'''
**Describe the bug**
I'm trying to build out the Copilot Chat App as a RAG chat (without skills for now). Not sure if its an
issue with Semantic Kernel or my cognitive search setup. Looking for some guidance.
...many lines removed for brevity...
JSONオブジェクトからコンパクトなテキスト形式に入手するには、以下を実行します。
repository_url 、 node_id 、その他多く。{"title": "Copilot Chat: [Copilot Chat App] Azure ... Beeve Be Be Be Title: Copilot Chat: [Copilot Chat App] Azure ...Body (between ''')問題のボディが'''キャラクターの間にあることをLLMに伝えます。このステップの結果を確認するには、ここをクリックしてください。問題とコメントについては、JSONオブジェクトと比較して、テキスト形式がどれだけ小さいかを確認します。
プロンプトは、必要なデータとともに、LLMに何をすべきかを伝えます。
プロンプトはこのファイルに保存されています。このプロンプトは、LLMに、必要な形式の問題とコメントを要約するように指示します( 「廃棄しないで...」部分はこの例から来ています)。
You are an experienced developer familiar with GitHub issues.
The following text was parsed from a GitHub issue and its comments.
Extract the following information from the issue and comments:
- Issue: A list with the following items: title, the submitter name, the submission date and
time, labels, and status (whether the issue is still open or closed).
- Summary: A summary of the issue in precisely one short sentence of no more than 50 words.
- Details: A longer summary of the issue. If code has been provided, list the pieces of code
that cause the issue in the summary.
- Comments: A table with a summary of each comment in chronological order with the columns:
date/time, time since the issue was submitted, author, and a summary of the comment.
Don't waste words. Use short, clear, complete sentences. Use active voice. Maximize detail, meaning focus on the content. Quote code snippets if they are relevant.
Answer in markdown with section headers separating each of the parts above.
これで、リクエストをLLMに送信するために必要なすべてのピースがあります。異なるLLMには異なるAPIがありますが、それらのほとんどには次のパラメーターのバリエーションがあります。
これらは、このプロジェクトで使用する主なものです。他のユースケースを調整できる他のパラメーターがあります。
これはllm.pyの関連コードです:
completion = client . chat . completions . create (
model = model ,
messages = [
{ "role" : "system" , "content" : prompt },
{ "role" : "user" , "content" : user_input },
],
temperature = 0.0 # We want precise and repeatable results
)LLMは、応答データと使用データを使用してJSONオブジェクトを返します。ユーザーへの応答を表示し、使用データを使用してリクエストのコストを計算します。
これは、LLMからのサンプル応答です(Openai APIを使用):
ChatCompletion (..., choices = [ Choice ( finish_reason = 'stop' , index = 0 , message = ChatCompletionMessage ( content =
'<response removed to save space>' , role = 'assistant' , function_call = None ))], created = 1698528558 ,
model = 'gpt-3.5-turbo-0613' , object = 'chat.completion' , usage = CompletionUsage ( completion_tokens = 304 ,
prompt_tokens = 1301 , total_tokens = 1605 ))応答に加えて、トークンの使用が取得されます。コストは応答の一部ではありません。公開された価格ルールに従って自分自身を計算する必要があります。
この時点で、ユーザーへの応答を表示するために必要なすべてがあります。
このセクションでは、アプリケーションでLLMを使用する方法のいくつかの例を確認します。うまく機能する簡単なケースから始めてから、物事が予想どおりに振る舞わない場合や、回避方法に移ります。
これは、次のセクションで説明されているものの要約です。
LLMSがどれだけうまく要約できるかを確認するために、簡単なケースから始めます。
次のコマンドでユーザーインターフェイスを開始します。
source venv/bin/activate
streamlit run app.py次に、サンプルのリストで最初の問題を選択します<https://github.com/openai/openai-python/issues/488> (simple example) 。 [...]で[概要を生成]ボタンをクリックします。
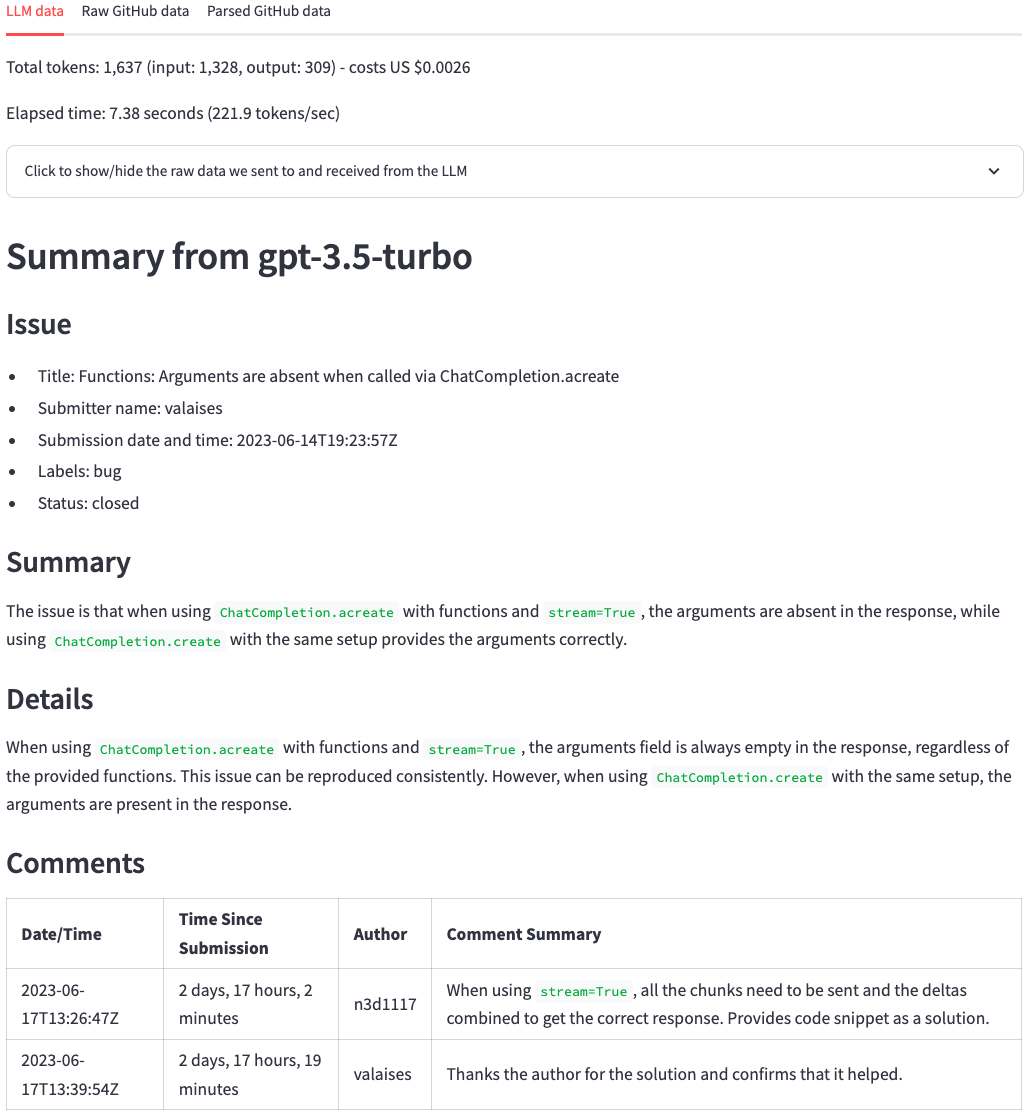
数秒後、下の写真のような要約を取得する必要があります。上部では、トークンカウント、コスト(トークンカウントから派生)、およびLLMが要約を生成するのにどれくらいの時間がかかったかがわかります。その後、LLMの応答が表示されます。元のGithubの問題と比較して、LLMは問題の主なポイントとコメントを要約する良い仕事をしています。一目で、問題の主なポイントとそのコメントを見ることができます。
次に、問題を選択してくださいhttps://github.com/scikit-learn/scikit-learn/issues/9354 ...そして「...」ボタンをクリックします。まだLLMモデルを変更しないでください。
このエラーで失敗します:
Error code: 400 - {'error': {'message': "This model's maximum context length is 16385 tokens. However, your messages resulted in 20437 tokens. Please reduce the length of the messages.", 'type': 'invalid_request_error', 'param': 'messages', 'code': 'context_length_exceeded'}}
各LLMには、一度に処理できるトークンの数に制限があります。この制限は、コンテキストウィンドウサイズです。コンテキストウィンドウは、要約する情報と要約自体に適合する必要があります。要約したい情報がコンテキストウィンドウよりも大きい場合、この場合に見たように、LLMはリクエストを拒否します。
この問題を回避する方法はいくつかあります:
2番目のオプションを使用します。 [[プロンプト]をクリックして[プロンプトとモデルを構成]画面の上部にクリックし、GPT-4Oモデルを選択し、 [GPT-4Oで概要を生成]ボタンをクリックします。
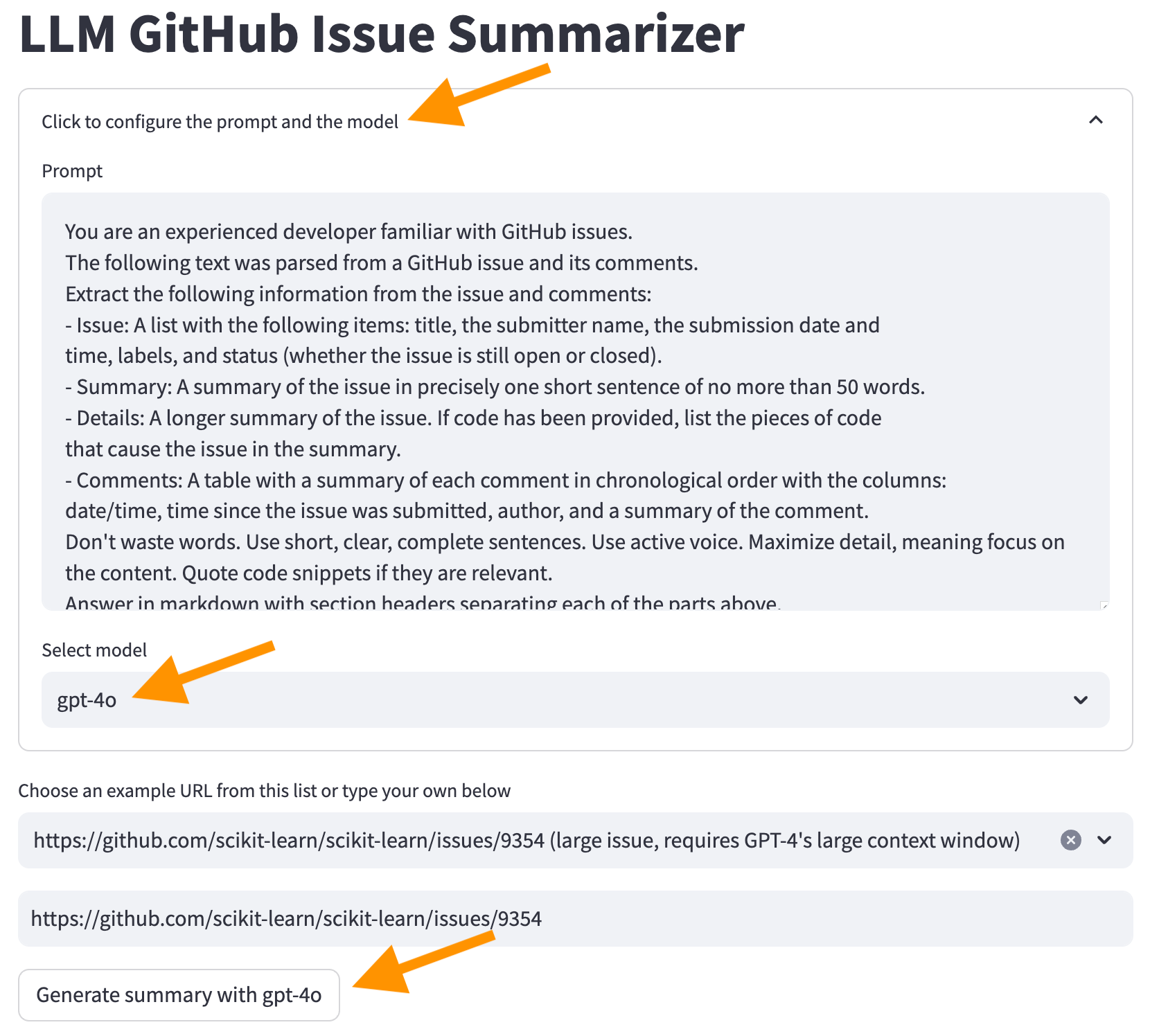
次に、LLMから概要を取得します。ただし、概要を生成するのに時間がかかり、コストがかかることに注意してください。
そのような問題を回避するためにGPT-4oから始めてみませんか?お金。一般的なルールとして、コンテキストウィンドウが大きいLLMSはさらにコストがかかります。 OpenaiなどのAIプロバイダーを使用する場合、トークンごとにさらに支払う必要があります。モデルを自分で実行する場合、より強力なハードウェアを購入する必要があります。いずれにせよ、より大きなコンテキストウィンドウを使用すると、さらにコストがかかります。
GPT-4Oを使用した結果、より良い要約も得られます。
最初からGPT-4Oを使用してみませんか?上記の理由(お金)に加えて、レイテンシも高くなっています。一般的なルールとして、より良いモデルも大きくなっています。実行するには、より多くのハードウェアが必要であり、トークンあたりのコストが高くなり、応答を生成するために長い時間に変換されます。
GPT-3.5-ターボモデルとGPT-4Oモデルの間の概要を生成するために、トークンカウント、コスト、および時間を比較する違いを確認できます。
どのようにモデルを選択しますか?ユースケースに依存します。良い結果をもたらす最小の(したがって、より安価で高速な)モデルから始めます。いくつかのヒューリスティックを作成して、より強力なモデルを使用するタイミングを決定します。たとえば、コメントが特定のサイズよりも大きい場合、ユーザーがより良い結果をより長く待つことをいとわない場合は、より大きなモデルに切り替えます(平均的な結果は、後の完全な結果よりも優れている場合があります)。
以前のセクションでは、GPT-3.5ターボをGPT-4Oと比較して、より小さなモデルとはるかに大きなモデルの違いを強調しました。しかし、2024年7月に、OpenaiはGPT-4O Miniモデルを導入しました。 GPT-4Oモデルと同じ128Kトークンコンテキストウィンドウが付属していますが、コストがはるかに低くなっています。 GPT-3.5モデルよりもさらに安いです。詳細については、Openai API価格を参照してください。
GPT-4O(Miniではない)は依然としてより良いモデルですが、その価格と遅延はより良い結果を正当化しないかもしれません。たとえば、次の表は、大きな問題の要約を示しています( https://github.com/qjebbs/vscode-plantuml/issues/255 )。 GPT-4Oは左側にあり、GPT-4O MINIはミニ上にあります。コストの違いは驚異的ですが、結果はそれほど違いはありません。
メッセージは、GPT-3.5ターボを使用する特定の理由がない限り、GPT-4O Miniモデルで新しいプロジェクトを開始する必要があるということです。 GPT-3.5ターボコストよりも少ない場合、GPT-4oに匹敵する結果を生成します。
| GPT-4o要約 | GPT-4Oミニの概要 |
|---|---|
| 3,859トークン、0.0303米ドル | 4,060、トークン、0.0012米ドル |
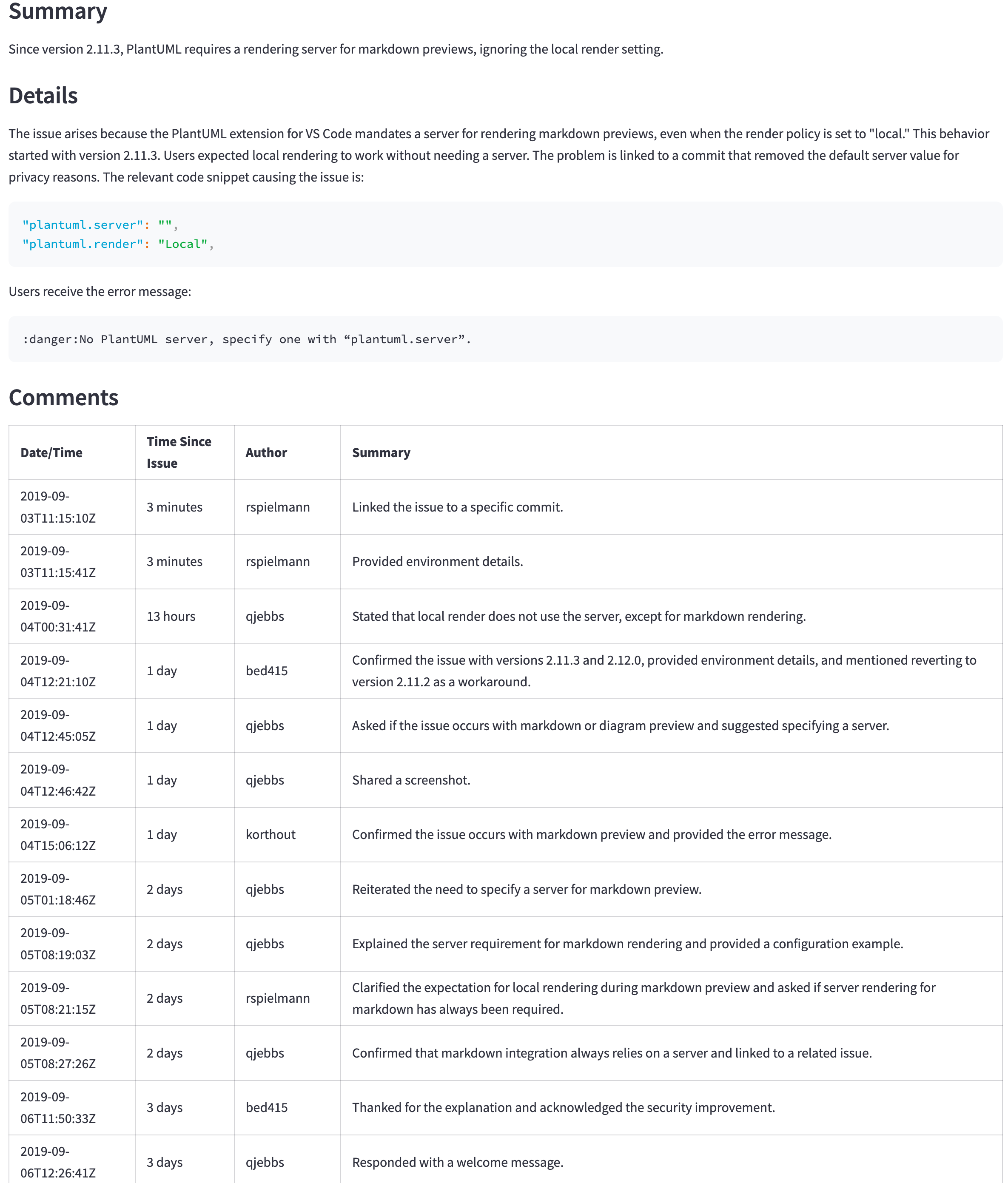 | 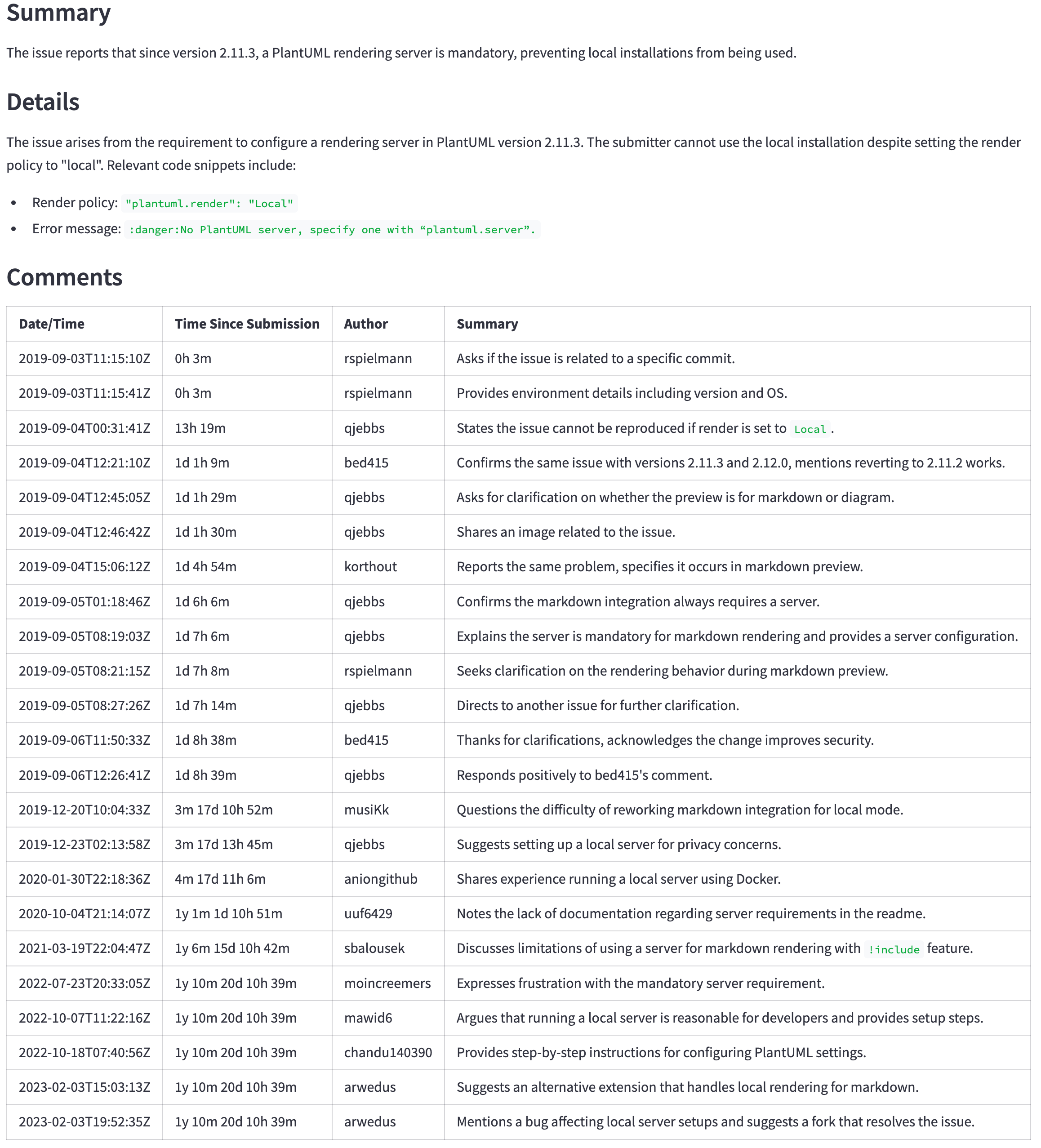 |
プロンプトの正確な指示は、良い結果を得るために重要です。良いプロンプトがどのような違いをもたらすかを説明するために:
https://github.com/openai/openai-python/issues/488をサンプルリストから選択します。このようなコメントの要約を取得します。

プロンプトから「単語を無駄にしないでください。短く、明確で完全な文を使用します。アクティブな音声を使用します。詳細を最大化します。コンテンツに焦点を合わせます。 、この要約を取得します。テキストがより冗長であり、実際に「単語を浪費する」方法に注意してください。

ラインを削除するには、 [[プロンプト]をクリックして[プロンプトとモデルを構成]画面の上部にクリックし、プロンプトから行を削除し、 [...]の[概要を生成]ボタンをもう一度クリックします。ページをリロードして、ラインを復元します。
プロンプトを正しく取得することは、依然として実験プロセスです。それは迅速なエンジニアリングの名前の下にあります。これらは、迅速なエンジニアリングについて詳しく知るためのいくつかの言及です。
学習したら、LLMでテキストを要約できるようになり、すべてに使用するように誘惑されます。問題に関するコメントの数も知りたいとしましょう。 LLMをプロンプトに追加することで尋ねることができます。
[クリック]をクリックして、 「[プロンプトとモデルを構成してモデルを構成します」画面の上部に、次のように- Number of comments in the issueプロンプトに追加します。他のすべての行を変更せずに残します。
You are an experienced developer familiar with GitHub issues.
The following text was parsed from a GitHub issue and its comments.
Extract the following information from the issue and comments:
- Issue: A list with the following items: title, the submitter name, the submission date and
time, labels, and status (whether the issue is still open or closed).
- Number of comments in the issue <-- ** ADD THIS LINE **
...remainder of the lines...
LLMは多くのコメントを返しますが、通常は間違っています。たとえば、問題https://github.com/qjebbs/vscode-plantuml/issues/255サンプルリストから選択します。コメントの数を正しく取得するモデルはいずれもありません。
なぜ? LLMは指示を「実行」していないため、一度に1つのトークンを生成しているだけです。
これは留意すべき重要な概念です。 LLMSはテキストの意味を理解していません。彼らは以前のトークンに基づいて次のトークンを選ぶだけです。それらはコードの代替品ではありません。
代わりに何をしますか?必要な情報に簡単にアクセスできる場合は、使用するだけです。この場合、GitHub API応答からコメントの数を取得できます。
issue , comments = get_github_data ( st . session_state . issue_url )
num_comments = len ( comments ) # <--- This is all we need cli.pyのCLIコードを使用して、コードの変更をテストします。 CLIでコードをデバッグすることは、retrylidアプリよりも簡単です。コードがCLIで動作したら、RimeLitアプリを適応させます。
これは1回限りのステップです。すでにこれを行っている場合は、 source venv/bin/activateを使用して仮想環境を有効にしてください。
環境を準備するための2つのステップがあります。
次のコマンドを実行して仮想環境を作成し、必要なパッケージをインストールします。
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install -r requirements.txtこのコードは、OpenAI GPTモデルを使用して要約を生成します。現在、LLMSを開始する最も簡単な方法の1つです。 OpenaiはAPIアクセスに料金を請求しますが、GPT-4o Miniモデルを使用する小規模プロジェクトでは大いに役立つ5米ドルのクレジットが提供されます。驚きの請求書を避けるために、支出制限を設定できます。
既にOpenAIアカウントをお持ちの場合は、ここでAPIキーを作成します。アカウントをお持ちでない場合は、ここでアカウントを作成してください。
OpenAI APIキーを取得したら、次のコンテンツを使用してProject Root Directoryに.envファイルを作成します。
OPENAI_API_KEY= < your key >ここにキーを追加しても安全です。リポジトリにコミットすることはありません。
このプロジェクトを使用すると、ドキュメントで質問し、LLMから回答を得ることができます。このプロジェクトに似たテクニックを使用しますが、大きな違いがあります。LLMはコンピューターでローカルに実行されます。


