llm github issues
1.0.0
Dieses Projekt ist eine Lernübung zur Verwendung von LLMs (Language Language Models) zur Zusammenfassung. Es verwendet GitHub -Probleme als praktischen Anwendungsfall, mit dem wir uns beziehen können.
Ziel ist es, den Entwicklern zu ermöglichen, zu verstehen, was in den Themen gemeldet und diskutiert wird, ohne jede Nachricht im Thread lesen zu müssen. Wir werden das ursprüngliche Github -Problem mit seinen Kommentaren nehmen und eine Zusammenfassung wie diese erstellen.
Update 2024-07-21 : Mit der Ankündigung von GPT-4O Mini gibt es immer weniger Gründe, GPT-3,5-Modelle zu verwenden. Ich habe den Code aktualisiert, um die GPT-4O- und GPT-4O-Mini-Modelle zu verwenden und die GPT-4-Turbo-Modelle zu entfernen (sie werden unter "älteren Modellen, die wir unterstützen" aufgeführt, und deutet darauf hin, dass sie schließlich entfernt werden).
Wir werden die folgenden Themen überprüfen:
Dieses YouTube -Video durchläuft die folgenden Abschnitte. Beachten Sie jedoch, dass die erste Version des Code verwendet wird. Der Code wurde seitdem aktualisiert.
Bevor wir beginnen, lesen wir, was hinter den Kulissen passiert, wenn wir LLMs verwenden, um GitHub -Probleme zusammenzufassen.
Das folgende Diagramm zeigt die Hauptschritte:
sequenzieren
Autonumber
Schauspieler u als Benutzer
Teilnehmer -App als Anwendung
Teilnehmer GH als Github -API
Teilnehmer LLM als LLM
U->> App: Geben Sie die URL in das GitHub-Problem ein
APP->> GH: Problem mit Problemen anfordern
GH->> App: Problemdaten im JSON-Format zurückgeben
App->> App: JSON in kompaktes Textformat analysieren
App->> App: Erstellen Sie die Eingabeaufforderung für LLM
App->> LLM: Anfrage an LLM senden
LLM->> App: Rückgabedaten und Nutzungsdaten (Token)
App->> u: Antwort- und Nutzungsdaten anzeigen
Wir werden jetzt jeden Schritt detaillierter überprüfen.
In diesem Abschnitt werden die Schritte beschrieben, die von einem Github -Problem wie diesem ausgehen (klicken, um zu vergrößern) ...
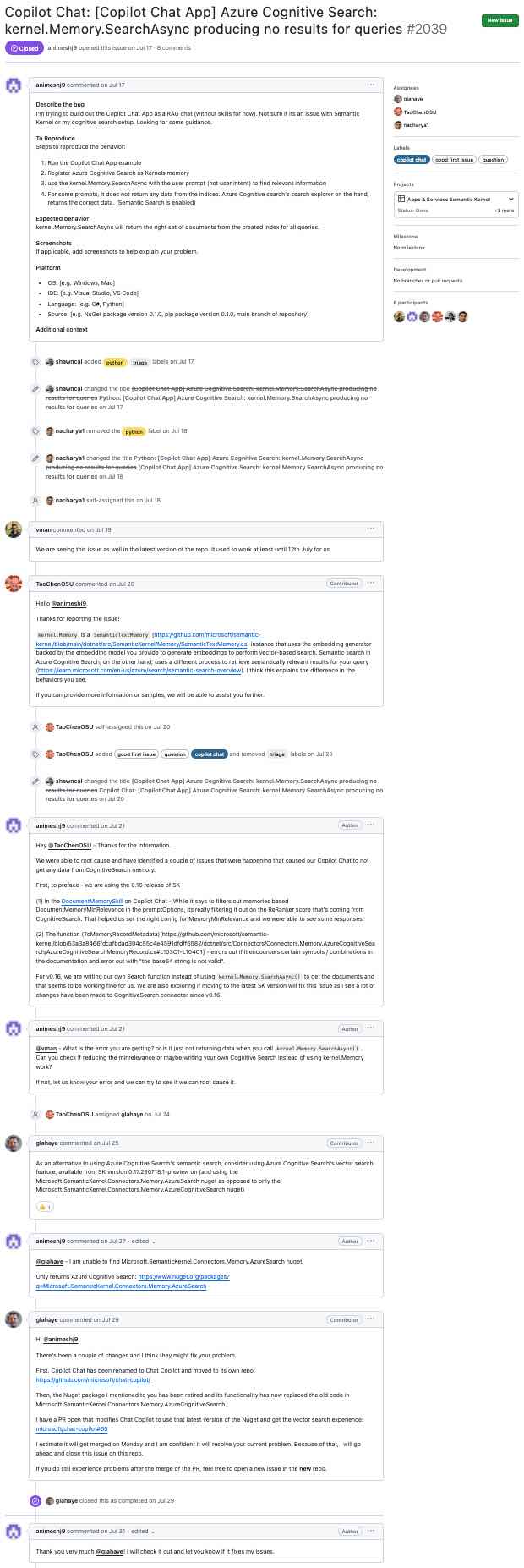
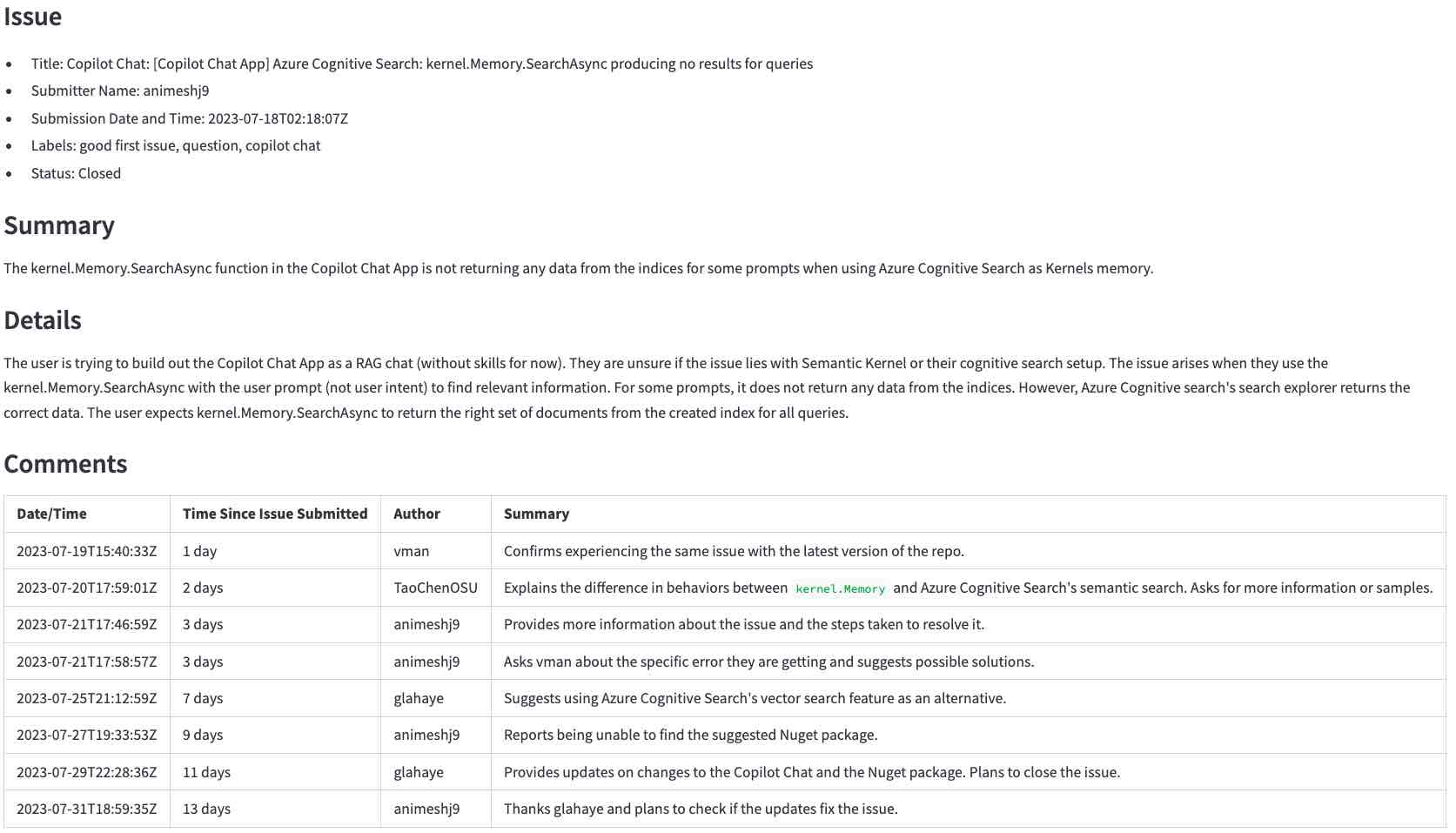
... zu LLM-generierter Zusammenfassung (klicken, um zu vergrößern):
Bereiten Sie zunächst die Umgebung vor, wenn Sie dies noch nicht getan haben.
Führen Sie die folgenden Befehle aus, um die Umgebung zu aktivieren und die Anwendung in einem Browser zu starten.
source venv/bin/activate
streamlit run app.py Sobald die Anwendung ausgeführt wird, geben Sie die URL für das obige Problem ein, https://github.com/microsoft/semantic-kernel/issues/2039 , und klicken Sie auf die Schaltfläche Generate summary with <model> um die Zusammenfassung zu erstellen. Es wird ein paar Sekunden dauern, bis es fertig ist.
Anmerkungen :
In den folgenden Abschnitten werden wir hinter die Kulissen gehen, um zu sehen, wie die Anwendung funktioniert.
In diesem Abschnitt werden die Schritte beschrieben, um ein GitHub -Problem mit LLMs zusammenzufassen. Wir werden zunächst die Ausgabedaten abrufen, die Vorverarbeitung vorbereiten, eine angemessene Eingabeaufforderung erstellen, sie an die LLM senden und schließlich die Antwort verarbeiten.
Der erste Schritt besteht darin, die Rohdaten mit der Github -API zu erhalten. In diesem Schritt übersetzen wir die URL, die der Benutzer in eine GitHub -API -URL eingegeben hat und das Problem und seine Kommentare anfordern. Zum Beispiel wird die URL https://github.com/microsoft/semantic-kernel/issues/2039 in https://api.github.com/repos/microsoft/semantic-kernel/issues/2039 übersetzt. Die Github -API gibt ein JSON -Objekt mit dem Problem zurück. Klicken Sie hier, um das JSON -Objekt für das Problem anzuzeigen.
Das Problem hat einen Link zu seinen Kommentaren:
"comments_url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039/comments",
Wir verwenden diese URL, um die Kommentare anzufordern und ein anderes JSON -Objekt zu erhalten. Klicken Sie hier, um das JSON -Objekt für die Kommentare anzuzeigen.
Die JSON -Objekte haben mehr Informationen als wir brauchen. Bevor wir die Anfrage an die LLM senden, müssen wir aus den folgenden Gründen die Teile extrahieren, die wir benötigen:
In diesem Schritt konvertieren wir die JSON -Objekte in ein kompaktes Textformat. Das Textformat ist einfacher zu verarbeiten und nimmt weniger Platz als die JSON -Objekte.
Dies ist der Beginn des JSON -Objekts, das von der Github -API für das Problem zurückgegeben wurde.
{
"url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039",
"repository_url": "https://api.github.com/repos/microsoft/semantic-kernel",
"labels_url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039/labels{/name}",
"comments_url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039/comments",
"events_url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039/events",
"html_url": "https://github.com/microsoft/semantic-kernel/issues/2039",
"id": 1808939848,
"node_id": "I_kwDOJDJ_Yc5r0jtI",
"number": 2039,
"title": "Copilot Chat: [Copilot Chat App] Azure Cognitive Search: kernel.Memory.SearchAsync producing no ...
"body": "**Describe the bug**rnI'm trying to build out the Copilot Chat App as a RAG chat (without
skills for now). Not sure if its an issue with Semantic Kernel or my cognitive search...
...many lines removed for brevity...
package version 0.1.0, pip package version 0.1.0, main branch of repository]rnrn**Additional
context**rn",
...
Und dies ist das kompakte Textformat, das wir daraus erstellen.
Title: Copilot Chat: [Copilot Chat App] Azure Cognitive Search: kernel.Memory.SearchAsync producing no
results for queries
Body (between '''):
'''
**Describe the bug**
I'm trying to build out the Copilot Chat App as a RAG chat (without skills for now). Not sure if its an
issue with Semantic Kernel or my cognitive search setup. Looking for some guidance.
...many lines removed for brevity...
Um vom JSON -Objekt zum kompakten Textformat zu gelangen, machen wir Folgendes:
repository_url , node_id und viele andere.{"title": "Copilot Chat: [Copilot Chat App] Azure ... wird Title: Copilot Chat: [Copilot Chat App] Azure ...Body (between ''') dem LLM, dass der Körper des Problems zwischen den ''' Charakteren liegt.Klicken Sie hier, um das Ergebnis dieses Schritts anzuzeigen. Vergleichen Sie mit dem JSON -Objekt für das Problem und Kommentare, um zu sehen, wie viel kleiner das Textformat ist.
Eine Eingabeaufforderung teilt dem LLM mit, was zu tun ist, zusammen mit den von ihnen benötigten Daten.
Unsere Eingabeaufforderung wird in dieser Datei gespeichert. Die Eingabeaufforderung weist die LLM an, das Problem und die Kommentare in dem gewünschten Format zusammenzufassen (der Teil "Nicht verschwenden ..." stammt aus diesem Beispiel).
You are an experienced developer familiar with GitHub issues.
The following text was parsed from a GitHub issue and its comments.
Extract the following information from the issue and comments:
- Issue: A list with the following items: title, the submitter name, the submission date and
time, labels, and status (whether the issue is still open or closed).
- Summary: A summary of the issue in precisely one short sentence of no more than 50 words.
- Details: A longer summary of the issue. If code has been provided, list the pieces of code
that cause the issue in the summary.
- Comments: A table with a summary of each comment in chronological order with the columns:
date/time, time since the issue was submitted, author, and a summary of the comment.
Don't waste words. Use short, clear, complete sentences. Use active voice. Maximize detail, meaning focus on the content. Quote code snippets if they are relevant.
Answer in markdown with section headers separating each of the parts above.
Wir haben jetzt alle Teile, die wir benötigen, um die Anfrage an die LLM zu senden. Unterschiedliche LLMs haben unterschiedliche APIs, aber die meisten von ihnen haben eine Variation der folgenden Parameter:
Dies sind die wichtigsten, die wir in diesem Projekt verwenden. Es gibt andere Parameter, die wir für andere Anwendungsfälle anpassen können.
Dies ist der relevante Code in LLM.Py:
completion = client . chat . completions . create (
model = model ,
messages = [
{ "role" : "system" , "content" : prompt },
{ "role" : "user" , "content" : user_input },
],
temperature = 0.0 # We want precise and repeatable results
)Das LLM gibt ein JSON -Objekt mit den Antwort- und Nutzungsdaten zurück. Wir zeigen die Antwort auf den Benutzer und verwenden die Nutzungsdaten, um die Kosten der Anfrage zu berechnen.
Dies ist eine Beispielantwort aus der LLM (unter Verwendung der OpenAI -API):
ChatCompletion (..., choices = [ Choice ( finish_reason = 'stop' , index = 0 , message = ChatCompletionMessage ( content =
'<response removed to save space>' , role = 'assistant' , function_call = None ))], created = 1698528558 ,
model = 'gpt-3.5-turbo-0613' , object = 'chat.completion' , usage = CompletionUsage ( completion_tokens = 304 ,
prompt_tokens = 1301 , total_tokens = 1605 ))Neben der Antwort erhalten wir den Token -Gebrauch. Die Kosten sind nicht Teil der Antwort. Wir müssen berechnen, dass wir nach den veröffentlichten Preisregeln nachkommen.
Zu diesem Zeitpunkt haben wir alles, was wir brauchen, um die Antwort dem Benutzer zu zeigen.
In diesem Abschnitt werden wir einige Beispiele für die Verwendung von LLMs in Anwendungen überprüfen. Wir werden mit einfachen Fällen beginnen, die gut funktionieren, und dann zu Fällen übergehen, in denen sich die Dinge nicht wie erwartet verhalten und wie sie um sie herum arbeiten.
Dies ist eine Zusammenfassung dessen, was in den folgenden Abschnitten behandelt wird.
Wir werden mit einem einfachen Fall beginnen, um zu sehen, wie gut LLMs zusammenfassen können.
Starten Sie die Benutzeroberfläche mit dem folgenden Befehl.
source venv/bin/activate
streamlit run app.py Wählen Sie dann das erste Problem in der Liste der Beispiele, <https://github.com/openai/openai-python/issues/488> (simple example) und klicken Sie auf die Schaltfläche "Mit ..." auf die Schaltfläche "Zusammenfassung generieren .
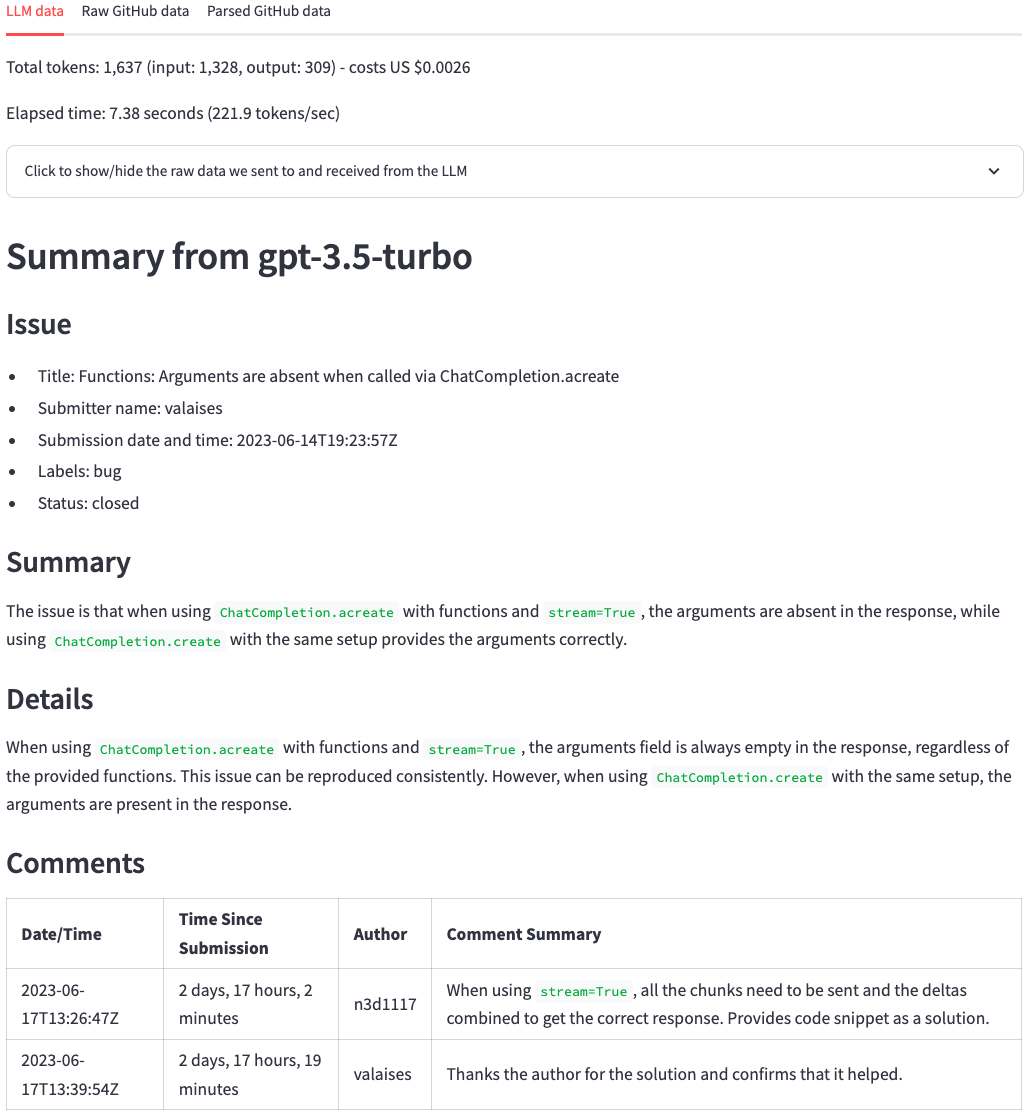
Nach ein paar Sekunden sollten wir eine Zusammenfassung wie das Bild unten erhalten. Oben können wir die Anzahl der Token sehen, die Kosten (abgeleitet von der Token -Anzahl) und wie lange es dauerte, bis die LLM die Zusammenfassung erzeugt. Danach sehen wir die Antwort des LLM. Im Vergleich zum ursprünglichen GitHub -Problem fasst die LLM die Hauptpunkte und die Kommentare des Problems gut zusammen und fasst einen guten Job zusammen. Auf einen Blick können wir die wichtigsten Punkte des Problems und seine Kommentare sehen.
Wählen Sie nun das Problem aus https://github.com/scikit-learn/scikit-learn/issues/9354 ... und klicken Sie auf die Schaltfläche "Zusammenfassung generieren Sie mit ..." . Ändern Sie das LLM -Modell noch nicht.
Es wird bei diesem Fehler fehlschlagen:
Error code: 400 - {'error': {'message': "This model's maximum context length is 16385 tokens. However, your messages resulted in 20437 tokens. Please reduce the length of the messages.", 'type': 'invalid_request_error', 'param': 'messages', 'code': 'context_length_exceeded'}}
Jedes LLM hat eine Grenze für die Anzahl der Token, die es jeweils verarbeiten kann. Diese Grenze ist die Kontextfenstergröße . Das Kontextfenster muss in die Informationen passen, die wir zusammenfassen möchten und die Zusammenfassung selbst. Wenn die Informationen, die wir zusammenfassen möchten, größer sind als das Kontextfenster, wie wir in diesem Fall gesehen haben, lehnt der LLM die Anfrage ab.
Es gibt einige Möglichkeiten, dieses Problem zu umgehen:
Wir werden die zweite Option verwenden. Klicken Sie auf "Klicken Sie auf die Eingabeaufforderung und das Modell" oben auf dem Bildschirm, wählen Sie das GPT-4O-Modell und klicken Sie auf die Schaltfläche "Zusammenfassung mit GPT-4O" .
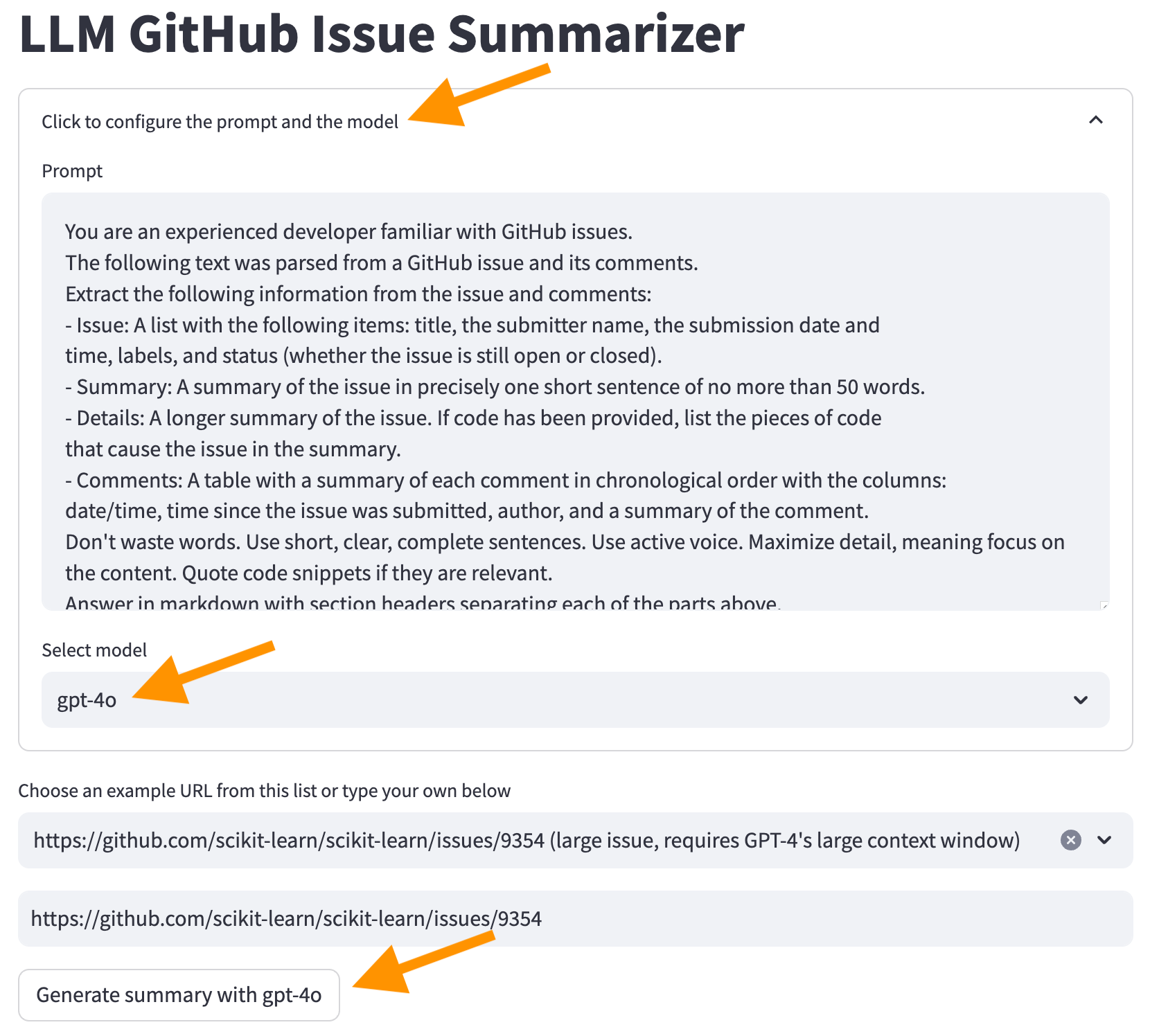
Jetzt erhalten wir eine Zusammenfassung aus der LLM. Beachten Sie jedoch, dass es länger dauern wird, die Zusammenfassung zu erzeugen und mehr zu kosten.
Warum beginnen wir nicht mit GPT-4O, um solche Probleme zu vermeiden? Geld. In der Regel kosten LLMs mit größeren Kontextfenstern mehr. Wenn wir einen KI -Anbieter wie OpenAI verwenden, müssen wir mehr pro Token bezahlen. Wenn wir das Modell selbst ausführen, müssen wir leistungsfähigere Hardware kaufen. In jedem Fall kostet die Verwendung eines größeren Kontextfensters mehr.
Infolge der Verwendung von GPT-4O erhalten wir auch bessere Zusammenfassungen.
Warum verwenden wir GPT-4O von Anfang an nicht? Zusätzlich zu den oben genannten Grund (Geld) gibt es auch eine höhere Latenz. In der Regel sind auch bessere Modelle größer. Sie benötigen mehr Hardware, um zu höheren Kosten pro Token und längere Zeit um eine Antwort zu erzielen.
Wir können den Unterschied sehen, wie die Token-Anzahl, die Kosten und die Zeit für die Zusammenfassung der GPT-3,5-Turbo und den GPT-4O-Modellen verglichen werden.
Wie wählen wir ein Modell aus? Es hängt vom Anwendungsfall ab. Beginnen Sie mit dem kleinsten (und damit billigeren und schnelleren) Modell, das gute Ergebnisse erzielt. Erstellen Sie einige Heuristiken, um zu entscheiden, wann ein leistungsstärkeres Modell verwendet werden soll. Wechseln Sie beispielsweise zu einem größeren Modell, wenn die Kommentare größer als eine bestimmte Größe sind und die Benutzer bereit sind, länger auf bessere Ergebnisse zu warten (manchmal ist ein durchschnittliches Ergebnis schneller besser als das perfekte Ergebnis später).
Die vorherigen Abschnitte verglichen GPT-3,5 Turbo mit GPT-4O, um die Unterschiede zwischen einem kleineren und einem viel größeren Modell hervorzuheben. Im Juli 2024 führte OpenAI jedoch das GPT-4O-Mini-Modell ein. Es wird mit dem gleichen 128K-Token-Kontextfenster wie das GPT-4O-Modell geliefert, jedoch mit viel geringeren Kosten. Es ist sogar billiger als die GPT-3,5-Modelle. Weitere Informationen finden Sie in der OpenAI -API -Preisgestaltung.
GPT-4O (nicht Mini) ist immer noch ein besseres Modell, aber sein Preis und seine Latenz rechtfertigen möglicherweise nicht die besseren Ergebnisse. Beispielsweise zeigt die folgende Tabelle die Zusammenfassung für ein großes Problem ( https://github.com/qjebbs/vscode-plantuml/issues/255 ). GPT-4O ist links und GPT-4O Mini auf dem Mini. Der Kostenunterschied ist erstaunlich, aber die Ergebnisse sind nicht viel unterschiedlich.
Die Nachricht ist, dass Sie ein neues Projekt mit dem GPT-4O-Mini-Modell starten sollten, wenn Sie keinen bestimmten Grund für die Verwendung von GPT-3.5-Turbo haben. Es werden Ergebnisse erzielt, die mit GPT-4O für weniger als die GPT-3,5-Turbokosten vergleichbar sind.
| GPT-4O-Zusammenfassung | GPT-4O Mini-Zusammenfassung |
|---|---|
| 3.859 Token, 0,0303 US -Dollar | 4.060, Tokens, 0,0012 US -Dollar |
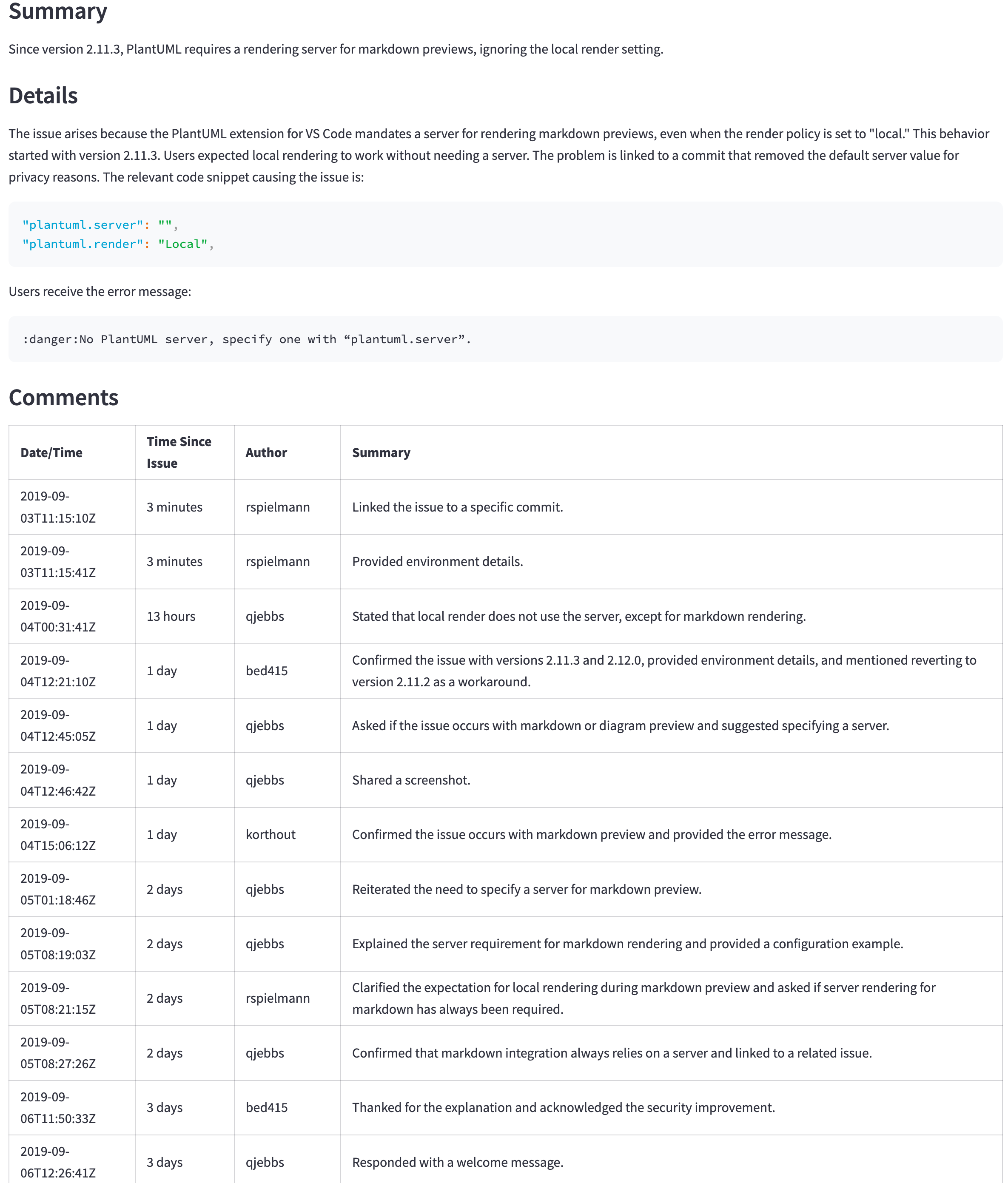 | 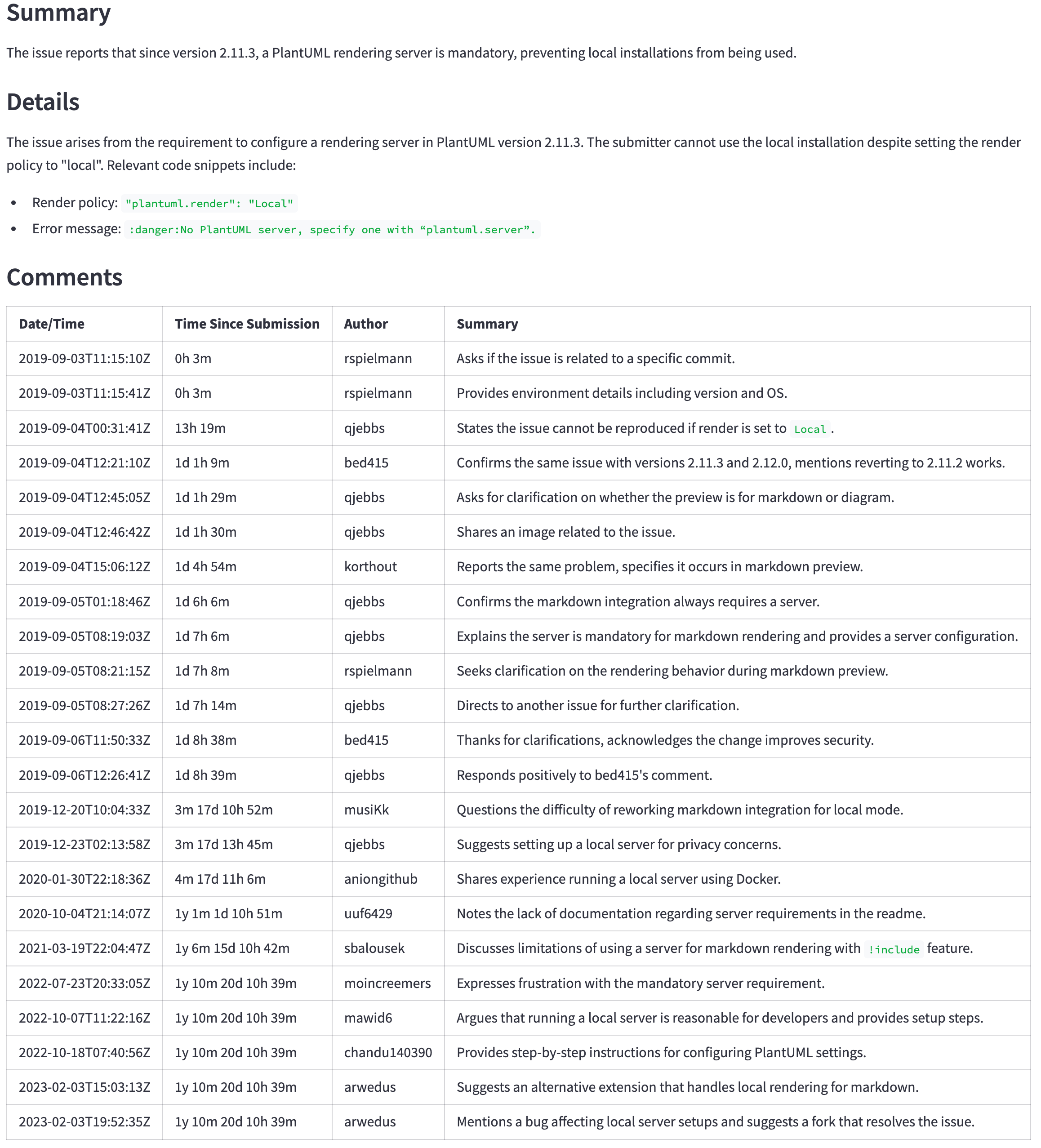 |
Genaue Anweisungen in der Eingabeaufforderung sind wichtig, um gute Ergebnisse zu erzielen. Um zu veranschaulichen, was für einen Unterschied eine gute Eingabeaufforderung macht:
https://github.com/openai/openai-python/issues/488 aus der Beispielliste.Wir erhalten eine Zusammenfassung der Kommentare wie diese.

Wenn wir aus der Eingabeaufforderung die Zeile entfernen "Verschwenden Sie keine Wörter. Verwenden Sie kurze, klare, vollständige Sätze. Verwenden Sie die aktive Stimme. Maximieren Sie das Detail, bedeutet, dass Sie sich auf den Inhalt konzentrieren. Zitat Code -Snippets, wenn sie relevant sind." Wir bekommen diese Zusammenfassung. Beachten Sie, wie der Text ausführlicher ist und in der Tat "Wörter verschwendet".

Um die Zeile zu entfernen, klicken Sie oben auf dem Bildschirm auf "Klicken Sie, um die Eingabeaufforderung und das Modell zu konfigurieren" , und entfernen Sie die Zeile der Eingabeaufforderung. Klicken Sie dann auf die Schaltfläche "Zusammenfassung generieren" erneut. Laden Sie die Seite neu, um die Zeile wiederherzustellen.
Das Richtige der Eingabeaufforderung ist immer noch ein experimenteller Prozess. Es geht unter den Namen prompt Engineering . Dies sind einige Verweise, um mehr über schnelle Engineering zu erfahren.
Sobald wir erfahren haben, dass wir Texte mit einem LLM zusammenfassen können, sind wir versucht, es für alles zu verwenden. Nehmen wir an, wir möchten auch die Anzahl der Kommentare zu diesem Thema kennen. Wir konnten das LLM fragen, indem wir sie zur Eingabeaufforderung hinzufügen.
Klicken Sie oben auf dem Bildschirm auf "Klicken Sie, um die Eingabeaufforderung und das Modell zu konfigurieren" und fügen Sie die Zeile hinzu - Number of comments in the issue zur Eingabeaufforderung, wie unten gezeigt. Lassen Sie alle anderen Zeilen unverändert.
You are an experienced developer familiar with GitHub issues.
The following text was parsed from a GitHub issue and its comments.
Extract the following information from the issue and comments:
- Issue: A list with the following items: title, the submitter name, the submission date and
time, labels, and status (whether the issue is still open or closed).
- Number of comments in the issue <-- ** ADD THIS LINE **
...remainder of the lines...
Die LLM gibt eine Reihe von Kommentaren zurück, aber es ist normalerweise falsch. Wählen Sie beispielsweise das Problem https://github.com/qjebbs/vscode-plantuml/issues/255 aus der Beispielliste. Keiner der Modelle erhält die Anzahl der Kommentare korrekt.
Warum? Da LLMs keine Anweisungen "ausführen" , generieren sie einfach jeweils ein Token.
Dies ist ein wichtiges Konzept, das man beachten sollte. LLMs verstehen nicht, was der Text bedeutet . Sie wählen nur das nächste Token aus, basierend auf den vorherigen. Sie sind kein Ersatz für Code.
Was tun stattdessen? Wenn wir einen einfachen Zugriff auf die gewünschten Informationen haben, sollten wir sie einfach verwenden. In diesem Fall können wir die Anzahl der Kommentare aus der GitHub -API -Antwort erhalten.
issue , comments = get_github_data ( st . session_state . issue_url )
num_comments = len ( comments ) # <--- This is all we need Verwenden Sie den CLI -Code in cli.py , um Änderungen am Code zu testen. Das Debugging -Code in einer CLI ist einfacher als in einer streamlit -App. Sobald der Code in der CLI funktioniert, passen Sie die Streamlit -App an.
Dies ist ein einmaliger Schritt. Wenn Sie dies bereits getan haben, aktivieren Sie einfach die virtuelle Umgebung mit source venv/bin/activate .
Es gibt zwei Schritte, um die Umgebung vorzubereiten.
Führen Sie die folgenden Befehle aus, um eine virtuelle Umgebung zu erstellen und die erforderlichen Pakete zu installieren.
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install -r requirements.txtDer Code verwendet OpenAI -GPT -Modelle, um Zusammenfassungen zu generieren. Es ist derzeit eine der einfachsten Möglichkeiten, mit LLMs zu beginnen. Während OpenAI für den API-Zugang berechnet, enthält es ein Guthaben von 5 US-Dollar, der in kleinen Projekten, die das GPT-4O-Mini-Modell verwenden, einen langen Weg zurücklegen können. Um Überraschungsrechnungen zu vermeiden, können Sie Ausgabengrenzen festlegen.
Wenn Sie bereits ein OpenAI -Konto haben, erstellen Sie hier einen API -Schlüssel. Wenn Sie kein Konto haben, erstellen Sie hier eines.
Sobald Sie den OpenAI -API -Schlüssel haben, erstellen Sie eine .env -Datei im Projektroot -Verzeichnis mit dem folgenden Inhalt.
OPENAI_API_KEY= < your key >Es ist sicher, den Schlüssel hier hinzuzufügen. Es wird niemals dem Repository verpflichtet.
Mit diesem Projekt können Sie Fragen zu einem Dokument stellen und Antworten von einem LLM erhalten. Es verwendet Techniken ähnlich wie dieses Projekt, aber mit einem signifikanten Unterschied: Die LLM läuft lokal auf Ihrem Computer.


