llm github issues
1.0.0
이 프로젝트는 요약을 위해 LLMS (Large Language Model)를 사용하는 학습 운동입니다. GitHub 문제를 우리가 관련시킬 수있는 실용적인 사용 사례로 사용합니다.
목표는 개발자가 스레드에서 각 메시지를 읽지 않고도 문제에서보고되고 논의되는 내용을 이해할 수 있도록하는 것입니다. 우리는 원래 Github 문제를 댓글로 취하고 이와 같은 요약을 생성 할 것입니다.
업데이트 2024-07-21 : GPT-4O MINI 발표를 사용하면 GPT-3.5 모델을 사용해야 할 이유가 적고 적습니다. GPT-4O 및 GPT-4O MINI 모델을 사용하고 GPT-4 터보 모델을 제거하도록 코드를 업데이트했습니다 ( "이전 모델"에 나열되어 결국 제거 될 것이라고 암시합니다).
우리는 다음 주제를 검토 할 것입니다.
이 YouTube 비디오는 아래 섹션을 살펴 보지만 첫 번째 버전의 코드를 사용합니다. 그 이후로 코드가 업데이트되었습니다.
시작하기 전에 LLM을 사용하여 GitHub 문제를 요약 할 때 무대 뒤에서 발생하는 일을 검토해 봅시다.
다음 다이어그램은 주요 단계를 보여줍니다.
시퀀스 인디 아그램
Autonumber
사용자로서 배우
응용 프로그램으로서의 참가자 앱
Github API로 참가자 GH
참가자 LLM으로 LLM
u- >> 앱 : GitHub 문제에 URL을 입력하십시오
앱->> GH : 요청 데이터 요청
GH- >> 앱 : JSON 형식의 문제 데이터를 반환합니다
앱->> 앱 : JSON을 소형 텍스트 형식으로 구문 분석합니다
앱->> 앱 : LLM의 프롬프트 빌드
앱->> llm : LLM에 요청을 보내십시오
LLM- >> 앱 : 반환 응답 및 사용 데이터 (토큰)
앱->> u : 응답 및 사용 데이터를 표시합니다
이제 각 단계를 더 자세히 검토 할 것입니다.
이 섹션은 이와 같은 Github 문제에서 진행되는 단계에 대해 설명합니다 (확대하려면 클릭하십시오) ...
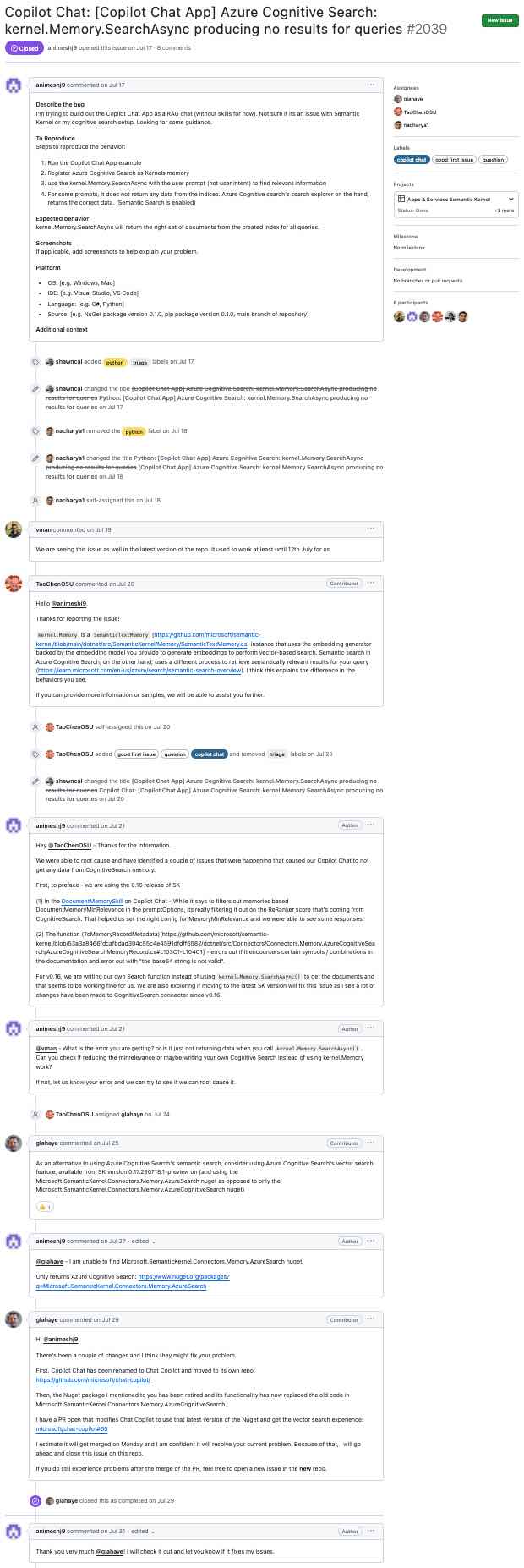
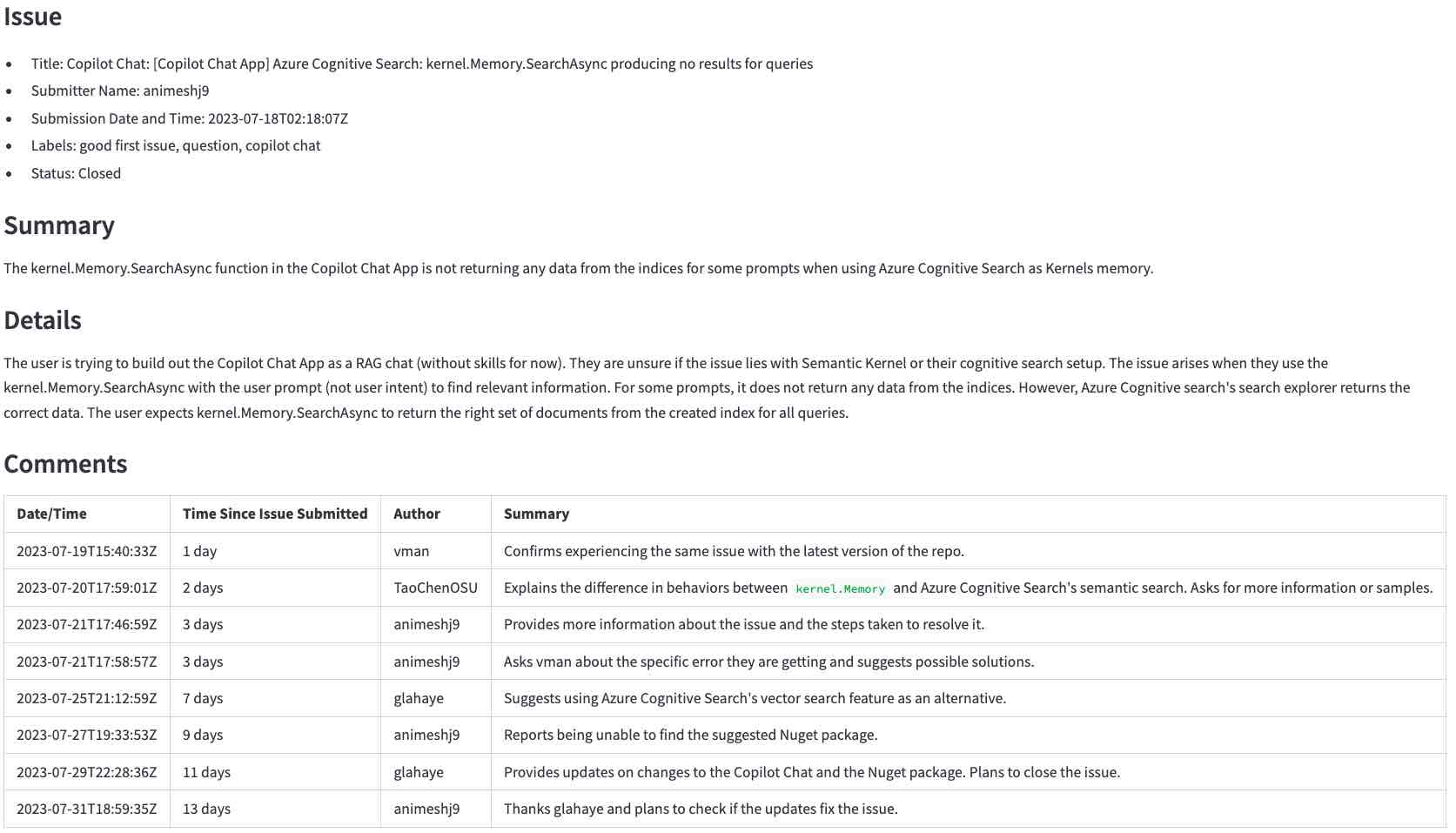
... LLM 생성 요약 (확대하려면 클릭) :
먼저, 아직 그렇게하지 않았다면 환경을 준비하십시오.
다음 명령을 실행하여 환경을 활성화하고 브라우저에서 응용 프로그램을 시작하십시오.
source venv/bin/activate
streamlit run app.py 응용 프로그램이 실행되면 위의 문제에 대한 URL을 입력하면 https://github.com/microsoft/semantic-kernel/issues/2039 입력하고 Generate summary with <model> 클릭하여 요약을 생성하십시오. 완료하는 데 몇 초가 걸립니다.
참고 :
다음 섹션에서는 응용 프로그램의 작동 방식을보기 위해 무대 뒤에서갑니다.
이 섹션에서는 LLM을 사용하여 GitHub 문제를 요약하는 단계에 대해 설명합니다. 우리는 문제 데이터를 가져오고, 전처리하고, 적절한 프롬프트를 구축하고, LLM으로 보내고, 마지막으로 응답을 처리하는 것으로 시작합니다.
첫 번째 단계는 Github API를 사용하여 원시 데이터를 얻는 것입니다. 이 단계에서는 사용자가 GitHub API URL에 입력 한 URL을 번역하고 문제와 주석을 요청합니다. 예를 들어, URL https://github.com/microsoft/semantic-kernel/issues/2039 는 https://api.github.com/repos/microsoft/semantic-kernel/issues/2039 로 변환됩니다. GitHub API는 문제가있는 JSON 객체를 반환합니다. 문제에 대한 JSON 개체를 보려면 여기를 클릭하십시오.
이 문제는 그 의견에 대한 링크가 있습니다.
"comments_url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039/comments",
우리는 해당 URL을 사용하여 주석을 요청하고 다른 JSON 객체를 얻습니다. 주석에 대한 JSON 개체를 보려면 여기를 클릭하십시오.
JSON 객체에는 필요한 것보다 더 많은 정보가 있습니다. LLM에 요청을 보내기 전에 다음과 같은 이유로 필요한 부분을 추출해야합니다.
이 단계에서는 JSON 객체를 컴팩트 한 텍스트 형식으로 변환합니다. 텍스트 형식은 처리하기 쉽고 JSON 객체보다 공간이 적습니다.
이것은 문제에 대해 Github API가 반환 한 JSON 객체의 시작입니다.
{
"url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039",
"repository_url": "https://api.github.com/repos/microsoft/semantic-kernel",
"labels_url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039/labels{/name}",
"comments_url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039/comments",
"events_url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039/events",
"html_url": "https://github.com/microsoft/semantic-kernel/issues/2039",
"id": 1808939848,
"node_id": "I_kwDOJDJ_Yc5r0jtI",
"number": 2039,
"title": "Copilot Chat: [Copilot Chat App] Azure Cognitive Search: kernel.Memory.SearchAsync producing no ...
"body": "**Describe the bug**rnI'm trying to build out the Copilot Chat App as a RAG chat (without
skills for now). Not sure if its an issue with Semantic Kernel or my cognitive search...
...many lines removed for brevity...
package version 0.1.0, pip package version 0.1.0, main branch of repository]rnrn**Additional
context**rn",
...
그리고 이것은 우리가 만든 소형 텍스트 형식입니다.
Title: Copilot Chat: [Copilot Chat App] Azure Cognitive Search: kernel.Memory.SearchAsync producing no
results for queries
Body (between '''):
'''
**Describe the bug**
I'm trying to build out the Copilot Chat App as a RAG chat (without skills for now). Not sure if its an
issue with Semantic Kernel or my cognitive search setup. Looking for some guidance.
...many lines removed for brevity...
JSON 객체에서 컴팩트 한 텍스트 형식으로 이동하려면 다음을 수행합니다.
repository_url , node_id 및 기타 많은 것들.{"title": "Copilot Chat: [Copilot Chat App] Azure ... Title: Copilot Chat: [Copilot Chat App] Azure ...Body (between ''') LLM에 문제의 본문이 ''' 문자 사이에 있다고 말합니다.이 단계의 결과를 보려면 여기를 클릭하십시오. 텍스트 형식이 얼마나 작은 지 확인하려면 문제와 주석에 대한 JSON 객체와 비교하십시오.
프롬프트는 LLM에 필요한 데이터와 함께해야 할 일을 알려줍니다.
우리의 프롬프트는이 파일에 저장됩니다. 프롬프트는 LLM에 문제와 주석을 우리가 원하는 형식으로 요약하도록 지시합니다 ( "낭비하지 마십시오 ..." 부분은이 예에서 나옵니다).
You are an experienced developer familiar with GitHub issues.
The following text was parsed from a GitHub issue and its comments.
Extract the following information from the issue and comments:
- Issue: A list with the following items: title, the submitter name, the submission date and
time, labels, and status (whether the issue is still open or closed).
- Summary: A summary of the issue in precisely one short sentence of no more than 50 words.
- Details: A longer summary of the issue. If code has been provided, list the pieces of code
that cause the issue in the summary.
- Comments: A table with a summary of each comment in chronological order with the columns:
date/time, time since the issue was submitted, author, and a summary of the comment.
Don't waste words. Use short, clear, complete sentences. Use active voice. Maximize detail, meaning focus on the content. Quote code snippets if they are relevant.
Answer in markdown with section headers separating each of the parts above.
이제 요청을 LLM으로 보내는 데 필요한 모든 부분이 있습니다. 다른 LLM에는 API가 다르지만 대부분은 다음 매개 변수의 변형이 있습니다.
이것들은이 프로젝트에서 우리가 사용하는 주요 것입니다. 다른 사용 사례에 대해 조정할 수있는 다른 매개 변수가 있습니다.
이것은 llm.py의 관련 코드입니다.
completion = client . chat . completions . create (
model = model ,
messages = [
{ "role" : "system" , "content" : prompt },
{ "role" : "user" , "content" : user_input },
],
temperature = 0.0 # We want precise and repeatable results
)LLM은 응답 및 사용 데이터로 JSON 객체를 반환합니다. 사용자에 대한 응답을 표시하고 사용 데이터를 사용하여 요청 비용을 계산합니다.
이것은 LLM (OpenAI API 사용)의 샘플 응답입니다.
ChatCompletion (..., choices = [ Choice ( finish_reason = 'stop' , index = 0 , message = ChatCompletionMessage ( content =
'<response removed to save space>' , role = 'assistant' , function_call = None ))], created = 1698528558 ,
model = 'gpt-3.5-turbo-0613' , object = 'chat.completion' , usage = CompletionUsage ( completion_tokens = 304 ,
prompt_tokens = 1301 , total_tokens = 1605 ))응답 외에도 토큰 사용량을 얻습니다. 비용은 응답의 일부가 아닙니다. 우리는 게시 된 가격 규칙에 따라 스스로를 계산해야합니다.
이 시점에서 우리는 사용자에 대한 응답을 보여주기 위해 필요한 모든 것이 있습니다.
이 섹션에서는 응용 프로그램에서 LLM을 사용하는 방법에 대한 몇 가지 예를 검토합니다. 우리는 잘 작동하는 간단한 사례로 시작한 다음 예상대로 행동하지 않는 경우와 주변에서 일하는 방법으로 넘어갑니다.
이것은 다음 섹션에서 다루는 내용에 대한 요약입니다.
LLM이 얼마나 잘 요약 할 수 있는지 확인하기 위해 간단한 사례로 시작합니다.
다음 명령으로 사용자 인터페이스를 시작하십시오.
source venv/bin/activate
streamlit run app.py 그런 다음 샘플 목록에서 <https://github.com/openai/openai-python/issues/488> (simple example) 에서 첫 번째 문제를 선택하고 "요약 생성 ..." 버튼을 클릭하십시오.
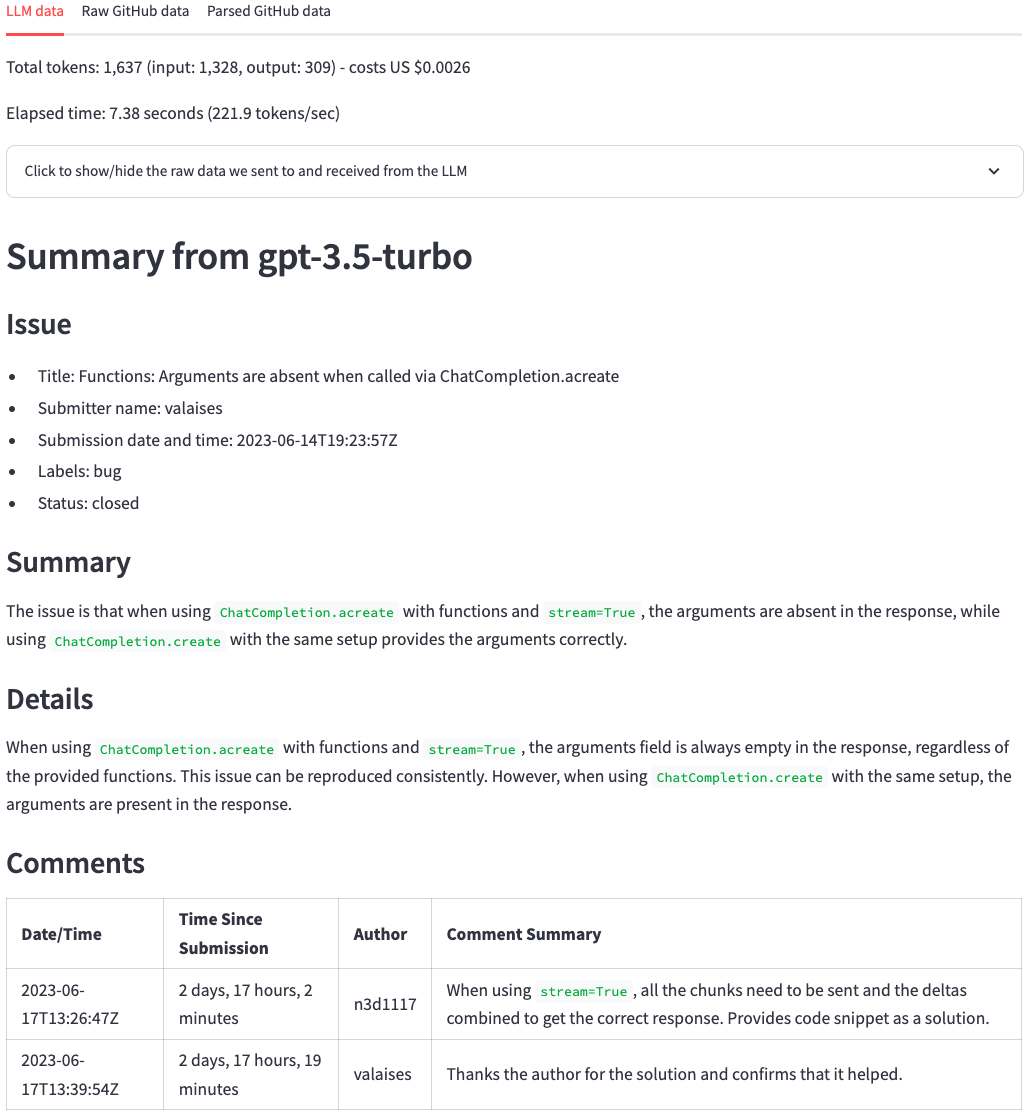
몇 초 후에 아래 그림과 같은 요약을 받아야합니다. 상단에서 우리는 토큰 수, 비용 (토큰 수에서 파생) 및 LLM이 요약을 생성하는 데 걸리는 시간을 볼 수 있습니다. 그 후 우리는 LLM의 응답을 봅니다. 원래 GitHub 문제와 비교할 때 LLM은 문제의 주요 요점과 의견을 요약하는 좋은 작업을 수행합니다. 한눈에, 우리는 문제의 주요 요점과 그 의견을 볼 수 있습니다.
이제 문제를 선택하고 https://github.com/scikit-learn/scikit-learn/issues/9354 ... "요약 생성 ..." 버튼을 클릭하십시오. 아직 LLM 모델을 변경하지 마십시오.
이 오류로 실패합니다.
Error code: 400 - {'error': {'message': "This model's maximum context length is 16385 tokens. However, your messages resulted in 20437 tokens. Please reduce the length of the messages.", 'type': 'invalid_request_error', 'param': 'messages', 'code': 'context_length_exceeded'}}
각 LLM은 한 번에 처리 할 수있는 토큰 수에 제한이 있습니다. 이 한계는 컨텍스트 창 크기입니다. 컨텍스트 창은 요약하려는 정보와 요약 자체에 맞아야합니다. 요약하려는 정보가 컨텍스트 창보다 크면이 경우 LLM이 요청을 거부합니다.
이 문제를 해결하는 몇 가지 방법이 있습니다.
두 번째 옵션을 사용합니다. 화면 상단에서 "프롬프트 및 모델을 구성하려면 클릭" 을 클릭하고 GPT-4O 모델을 선택하고 "GPT-4O를 사용하여 요약 생성" 버튼을 클릭하십시오.
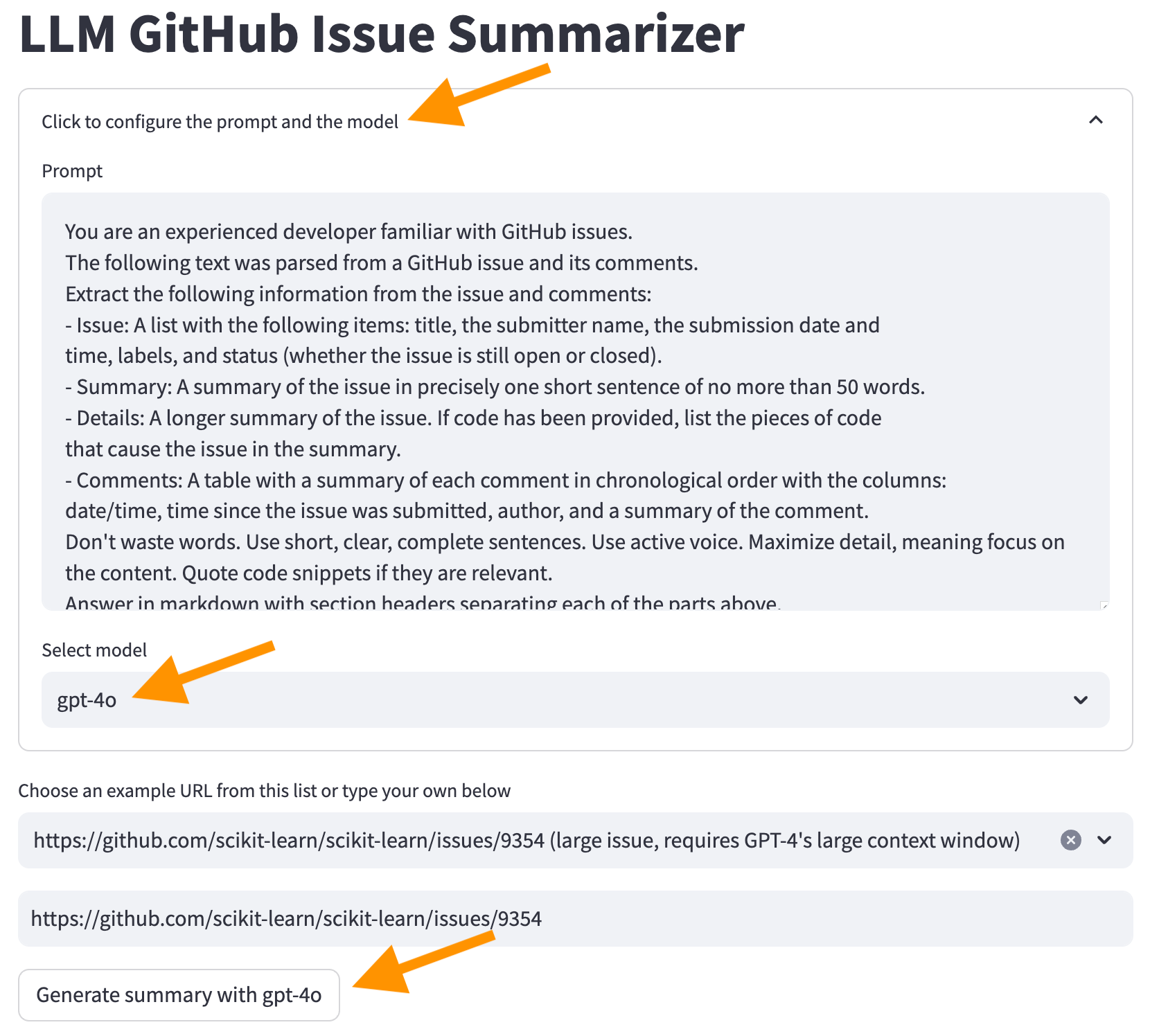
이제 LLM에서 요약을받습니다. 그러나 요약을 생성하는 데 시간이 더 걸리고 더 많은 비용이 소요됩니다.
그러한 문제를 피하기 위해 GPT-4O로 시작하지 않는 이유는 무엇입니까? 돈. 일반적으로 컨텍스트가 큰 LLM은 더 많은 비용이 듭니다. OpenAI와 같은 AI 제공 업체를 사용하는 경우 토큰 당 더 많은 비용을 지불해야합니다. 모델을 직접 실행하면 더 강력한 하드웨어를 구입해야합니다. 어느 쪽이든, 더 큰 컨텍스트 창을 사용하는 데 더 많은 비용이 듭니다.
GPT-4O를 사용한 결과 더 나은 요약도 얻습니다.
처음부터 GPT-4O를 사용하지 않는 이유는 무엇입니까? 위의 이유 (돈) 외에도 대기 시간이 더 높습니다. 일반적으로 더 나은 모델도 더 큽니다. 더 많은 하드웨어가 필요하며, 토큰 당 더 높은 비용으로 변환하고 응답을 생성하는 데 더 오랜 시간이 걸립니다.
GPT-3.5-Turbo와 GPT-4O 모델 사이의 요약을 생성하기위한 토큰 수, 비용 및 시간을 비교하는 차이를 볼 수 있습니다.
모델을 어떻게 선택합니까? 사용 사례에 따라 다릅니다. 좋은 결과를 얻는 가장 작고 더 저렴하고 빠른 모델로 시작하십시오. 더 강력한 모델을 사용하는시기를 결정하기 위해 휴리스틱을 만듭니다. 예를 들어, 주석이 특정 크기보다 큰 경우 더 큰 모델로 전환하고 사용자가 더 나은 결과를 더 오래 기다리려면 (때로는 평균 결과가 나중에 완벽한 결과보다 낫습니다).
이전 섹션은 GPT-3.5 터보를 GPT-4O와 비교하여 더 작은 모델과 훨씬 더 큰 모델의 차이를 강조했습니다. 그러나 2024 년 7 월 OpenAi는 GPT-4O 미니 모델을 소개했습니다. GPT-4O 모델과 동일한 128K 토큰 컨텍스트 창이 제공되지만 비용이 훨씬 낮습니다. GPT-3.5 모델보다 훨씬 저렴합니다. 자세한 내용은 OpenAI API 가격을 참조하십시오.
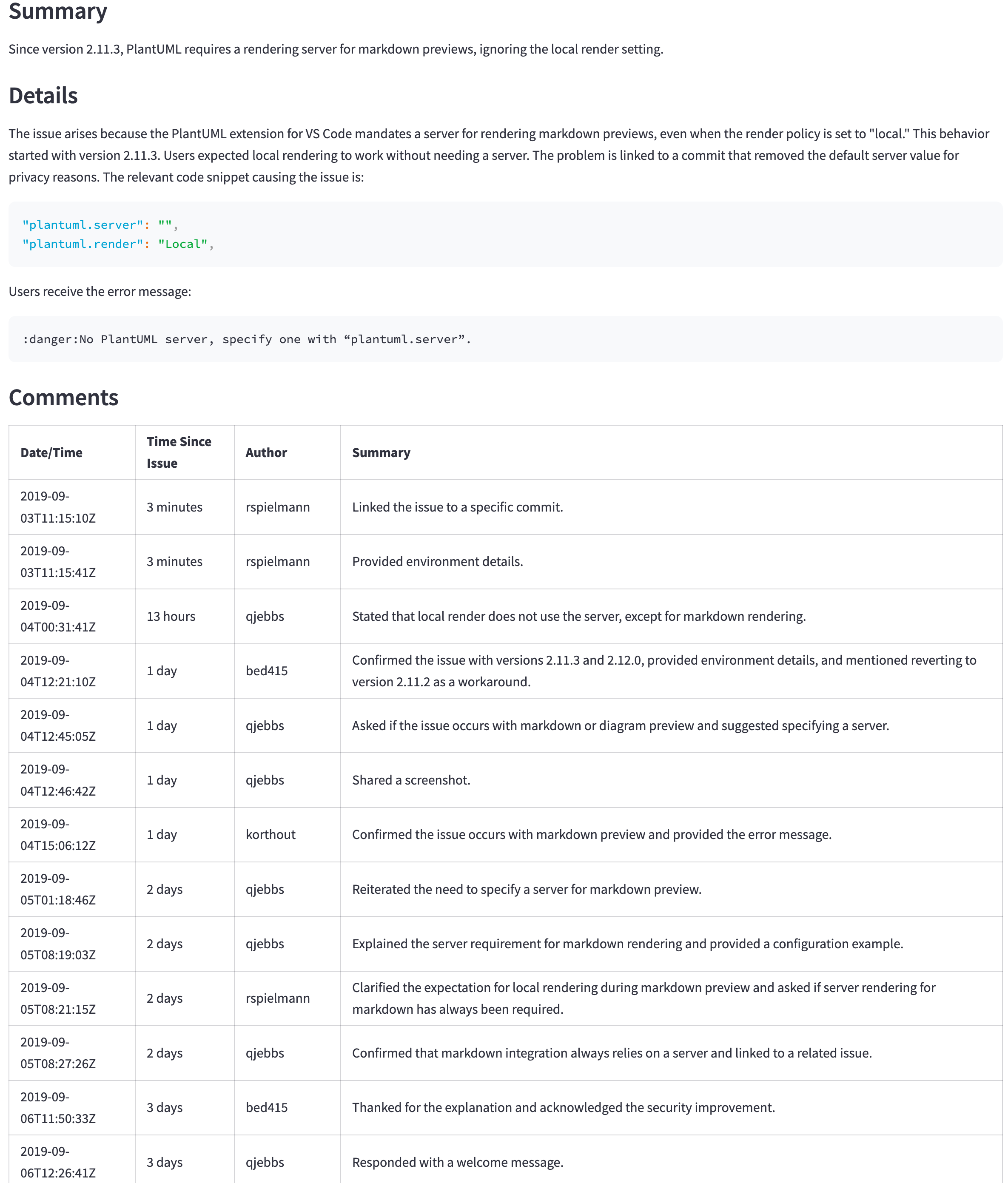
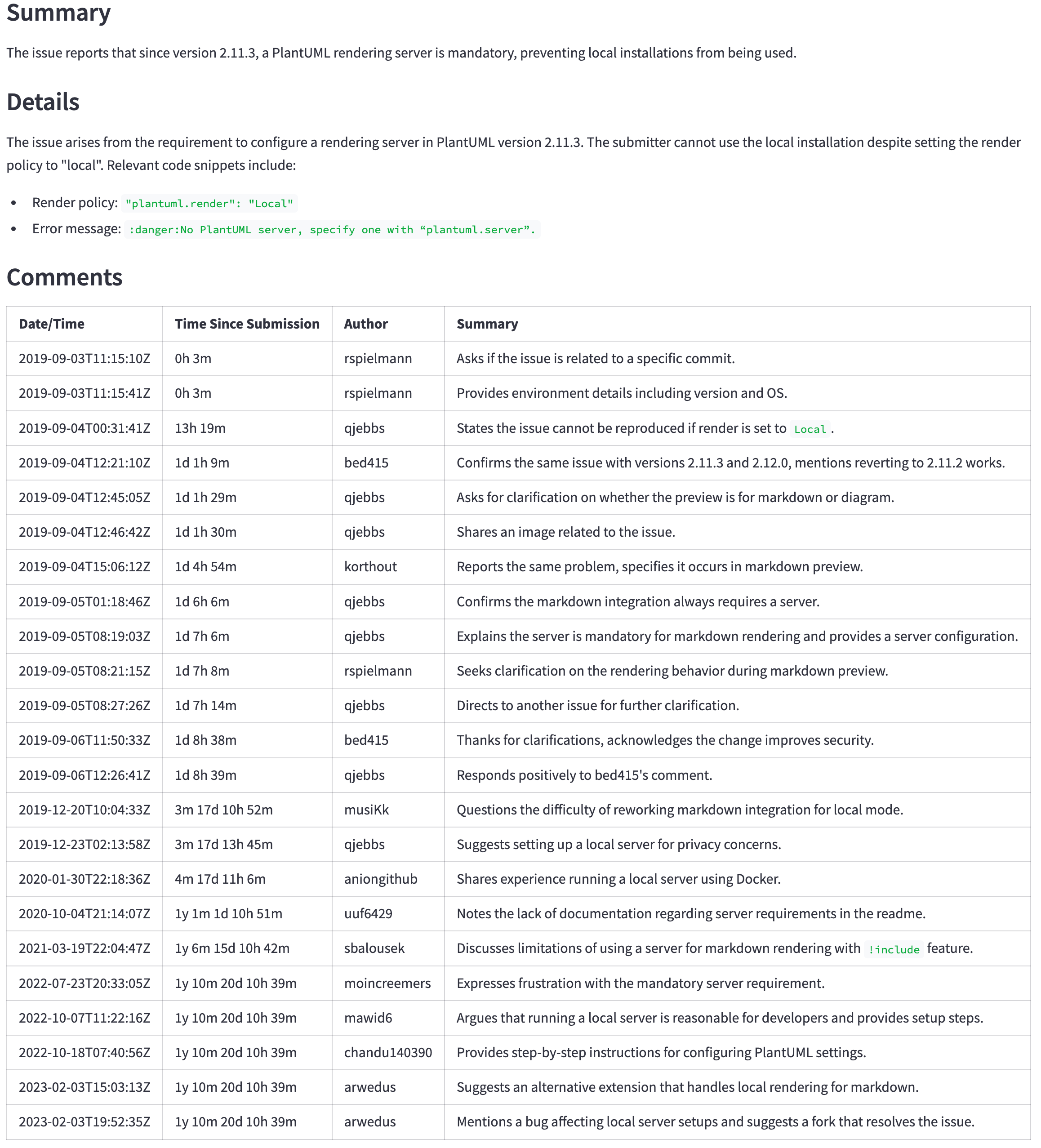
GPT-4O (미니 아님)는 여전히 더 나은 모델이지만 가격과 대기 시간은 더 나은 결과를 정당화하지 않을 수 있습니다. 예를 들어, 다음 표는 큰 문제에 대한 요약을 보여줍니다 ( https://github.com/qjebbs/vscode-plantuml/issues/255 ). GPT-4O는 왼쪽에 있고 GPT-4O 미니는 미니에 있습니다. 비용의 차이는 엄청나지 만 결과는 그다지 다르지 않습니다.
메시지는 GPT-3.5 터보를 사용하는 특정한 이유가 없다면 GPT-4O 미니 모델로 새로운 프로젝트를 시작해야한다는 것입니다. GPT-3.5 터보 비용보다 적은 비용으로 GPT-4O와 비슷한 결과를 생성 할 것입니다.
| GPT-4O 요약 | GPT-4O 미니 요약 |
|---|---|
| 3,859 토큰, US $ 0.0303 | 4,060, 토큰, US $ 0.0012 |
 |  |
좋은 결과를 얻으려면 프롬프트의 정확한 지침이 중요합니다. 좋은 프롬프트의 차이를 설명하기 위해 :
https://github.com/openai/openai-python/issues/488 을 선택하십시오.우리는 이와 같은 의견을 요약합니다.

프롬프트에서 "단어를 낭비하지 마십시오. 짧고 명확하며 완전한 문장을 사용하십시오. 활성 음성을 사용하십시오. 세부 사항을 극대화하고 내용에 초점을 맞추십시오. 관련된 경우 견적 코드 스 니펫을 의미합니다." , 우리는이 요약을 얻습니다. 텍스트가 어떻게 장황하고 실제로 "단어를 낭비하는지"에 주목하십시오.

라인을 제거하려면 화면 상단에서 "프롬프트와 모델을 구성하려면 클릭하여 클릭 하고 프롬프트에서 라인을 제거한 다음 "요약 생성 ... 라인을 복원하려면 페이지를 다시로드하십시오.
프롬프트 권리를 얻는 것은 여전히 실험적인 과정입니다. 프롬프트 엔지니어링 이라는 이름으로갑니다. 이들은 신속한 엔지니어링에 대한 자세한 내용을 알리는 몇 가지 참조입니다.
일단 우리가 LLM으로 텍스트를 요약 할 수있게되면, 우리는 모든 것을 위해 그것을 사용하고 싶은 유혹을받습니다. 이 문제에 대한 의견 수를 알고 싶다고 가정 해 봅시다. LLM을 프롬프트에 추가하여 LLM을 요청할 수 있습니다.
화면 상단에서 "프롬프트와 모델을 구성하려면 클릭" 을 클릭하고 아래 그림과 같이 - Number of comments in the issue 추가하십시오. 다른 모든 줄을 변경하지 않도록하십시오.
You are an experienced developer familiar with GitHub issues.
The following text was parsed from a GitHub issue and its comments.
Extract the following information from the issue and comments:
- Issue: A list with the following items: title, the submitter name, the submission date and
time, labels, and status (whether the issue is still open or closed).
- Number of comments in the issue <-- ** ADD THIS LINE **
...remainder of the lines...
LLM은 여러 의견을 반환하지만 일반적으로 잘못됩니다. 예를 들어 샘플 목록에서 https://github.com/qjebbs/vscode-plantuml/issues/255 문제를 선택하십시오. 모델 중 어느 것도 댓글 수를 올바르게 얻지 못합니다.
왜? LLM은 "실행"지침이 아니기 때문에 한 번에 하나의 토큰을 생성합니다.
이것은 명심해야 할 중요한 개념입니다. LLM은 텍스트의 의미를 이해하지 못합니다 . 그들은 이전 토큰을 기반으로 다음 토큰을 선택합니다. 그들은 코드를 대체하지 않습니다.
대신 무엇을해야합니까? 원하는 정보에 쉽게 액세스 할 수 있다면 사용해야합니다. 이 경우 GitHub API 응답에서 댓글 수를 얻을 수 있습니다.
issue , comments = get_github_data ( st . session_state . issue_url )
num_comments = len ( comments ) # <--- This is all we need cli.py 의 CLI 코드를 사용하여 코드에 대한 수정을 테스트하십시오. CLI에서 코드를 디버깅하는 것이 간소화 앱보다 쉽습니다. CLI에서 코드가 작동하면 Streamlit 앱을 조정하십시오.
이것은 일회성 단계입니다. 이미이 작업을 수행 한 경우 source venv/bin/activate 사용하여 가상 환경을 활성화하십시오.
환경을 준비하기위한 두 단계가 있습니다.
가상 환경을 만들려면 다음 명령을 실행하고 필요한 패키지를 설치하십시오.
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install -r requirements.txt이 코드는 OpenAI GPT 모델을 사용하여 요약을 생성합니다. 현재 LLM을 시작하는 가장 쉬운 방법 중 하나입니다. API 액세스에 대한 OpenAI는 US $ 5 크레딧을 제공하여 GPT-4O 미니 모델을 사용하는 소규모 프로젝트에서 먼 길을 갈 수 있습니다. 놀라운 청구서를 피하기 위해 지출 한도를 설정할 수 있습니다.
이미 OpenAI 계정이있는 경우 여기에서 API 키를 만듭니다. 계정이없는 경우 여기에서 계정을 만드십시오.
OpenAI API 키가 있으면 다음 내용으로 Project Root 디렉토리에서 .env 파일을 만듭니다.
OPENAI_API_KEY= < your key >여기에 키를 추가하는 것이 안전합니다. 그것은 결코 저장소에 전념하지 않을 것입니다.
이 프로젝트를 사용하면 문서에 대한 질문을하고 LLM으로부터 답변을 얻을 수 있습니다. 이 프로젝트와 유사한 기술을 사용하지만 상당한 차이가 있습니다. LLM은 컴퓨터에서 로컬로 실행됩니다.


