llm github issues
1.0.0
该项目是使用大型语言模型(LLM)进行摘要的学习练习。它使用GitHub问题作为我们可以与之相关的实际用例。
目的是允许开发人员了解问题中正在报告和讨论的内容,而不必阅读线程中的每个消息。我们将带有其评论的原始GitHub问题,并产生这样的摘要。
更新2024-07-21 :随着GPT-4O Mini的宣布,使用GPT-3.5型号的理由越来越少。我更新了代码,以使用GPT-4O和GPT-4O迷你型号并删除GPT-4 Turbo模型(它们在“我们支持的较旧型号”下列出,暗示它们最终将被删除)。
我们将回顾以下主题:
该YouTube视频浏览了以下各节,但请注意,它使用了代码的第一个版本。从那以后,该代码已更新。
在开始之前,让我们回顾一下当我们使用LLMS总结GitHub问题时,幕后会发生什么。
下图显示了主要步骤:
测序图
自动化器
演员u作为用户
参与者应用程序作为应用程序
参与者GH作为GitHub API
参与者llm作为llm
u- >>应用:输入url到github问题
应用 - >> GH:请求问题数据
GH- >>应用:以JSON格式返回问题数据
应用程序 - >>应用:将JSON放入紧凑的文本格式
应用程序 - >>应用:构建llm的提示
应用程序 - >> LLM:将请求发送到LLM
llm- >>应用:返回响应和用法数据(令牌)
应用 - >> U:显示响应和使用数据
现在,我们将更详细地查看每个步骤。
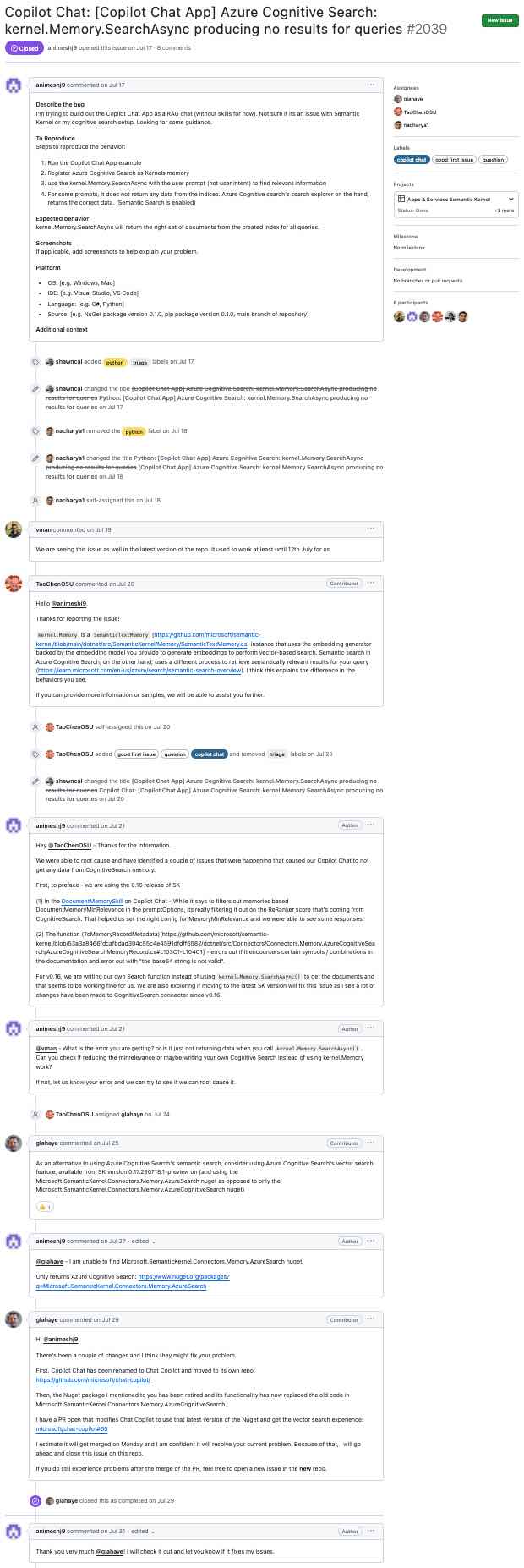
本节介绍了从类似GitHub问题进行的步骤(单击放大)...
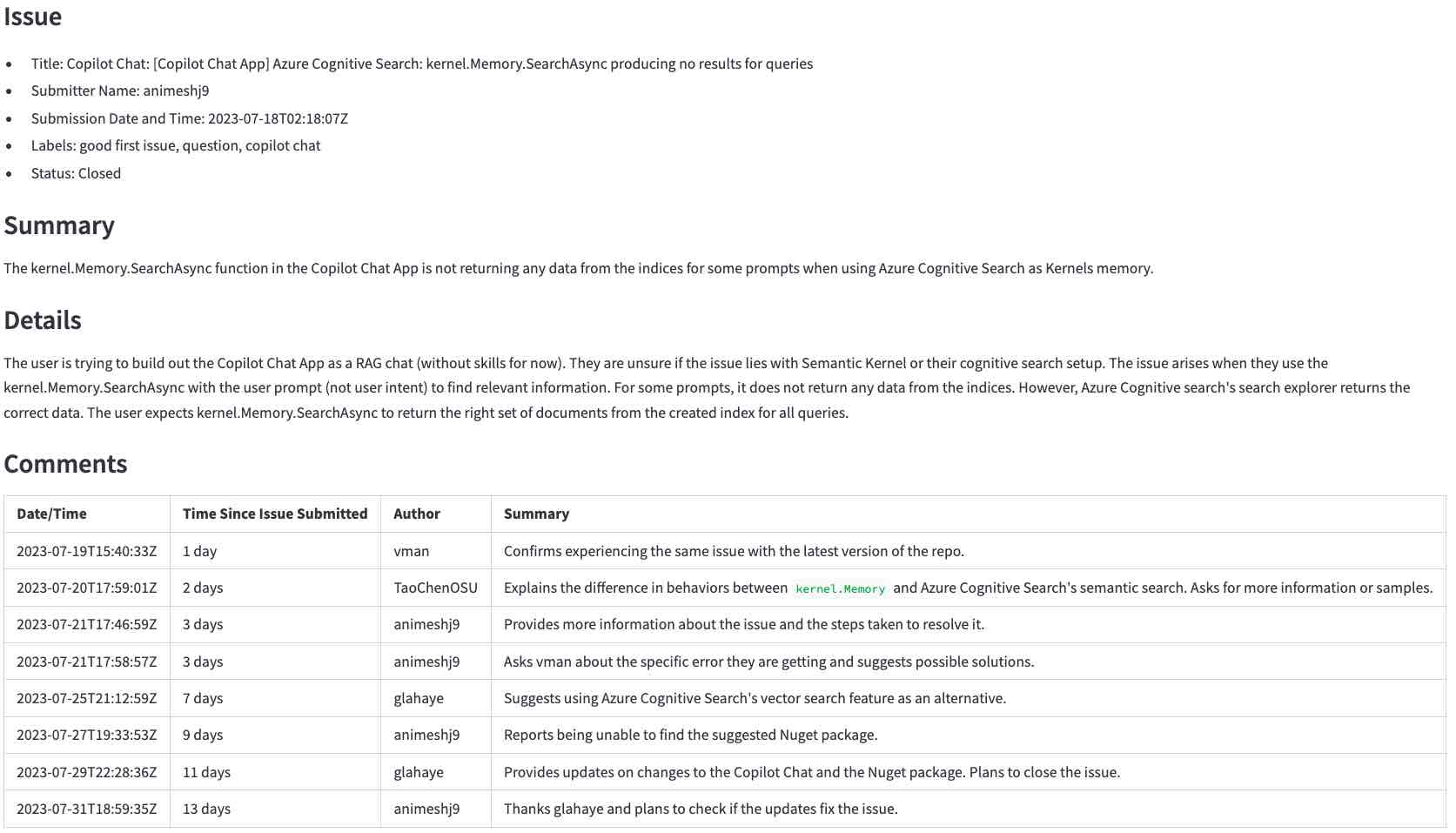
...要llm生成的摘要(单击以放大):
首先,如果您还没有这样做,请准备环境。
运行以下命令以激活环境并在浏览器中启动应用程序。
source venv/bin/activate
streamlit run app.py应用程序运行后,输入上述问题的URL, https://github.com/microsoft/semantic-kernel/issues/2039 ,然后单击Generate summary with <model>以生成摘要。要完成需要几秒钟。
注意:
在以下各节中,我们将在幕后查看应用程序的工作原理。
本节介绍了使用LLMS总结GitHub问题的步骤。我们将首先获取问题数据,预处理数据,建立适当的提示,将其发送到LLM,最后处理响应。
第一步是使用GitHub API获取原始数据。在此步骤中,我们将用户输入的URL转换为GitHub API URL,并请求该问题及其注释。例如,将URL https://github.com/microsoft/semantic-kernel/issues/2039转化为https://api.github.com/repos/microsoft/semantic-kernel/issues/2039 。 GitHub API返回带有问题的JSON对象。单击此处查看问题的JSON对象。
该问题具有指定的链接:
"comments_url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039/comments",
我们使用该URL请求评论并获取另一个JSON对象。单击此处查看评论的JSON对象。
JSON对象的信息超出了我们的需求。在将请求发送到LLM之前,我们需要出于以下原因提取所需的部分:
在此步骤中,我们将JSON对象转换为紧凑的文本格式。文本格式比JSON对象更容易处理,并且占用空间少。
这是GitHub API返回的JSON对象的开始。
{
"url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039",
"repository_url": "https://api.github.com/repos/microsoft/semantic-kernel",
"labels_url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039/labels{/name}",
"comments_url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039/comments",
"events_url": "https://api.github.com/repos/microsoft/semantic-kernel/issues/2039/events",
"html_url": "https://github.com/microsoft/semantic-kernel/issues/2039",
"id": 1808939848,
"node_id": "I_kwDOJDJ_Yc5r0jtI",
"number": 2039,
"title": "Copilot Chat: [Copilot Chat App] Azure Cognitive Search: kernel.Memory.SearchAsync producing no ...
"body": "**Describe the bug**rnI'm trying to build out the Copilot Chat App as a RAG chat (without
skills for now). Not sure if its an issue with Semantic Kernel or my cognitive search...
...many lines removed for brevity...
package version 0.1.0, pip package version 0.1.0, main branch of repository]rnrn**Additional
context**rn",
...
这是我们从中创建的紧凑文本格式。
Title: Copilot Chat: [Copilot Chat App] Azure Cognitive Search: kernel.Memory.SearchAsync producing no
results for queries
Body (between '''):
'''
**Describe the bug**
I'm trying to build out the Copilot Chat App as a RAG chat (without skills for now). Not sure if its an
issue with Semantic Kernel or my cognitive search setup. Looking for some guidance.
...many lines removed for brevity...
要从JSON对象获得紧凑的文本格式,我们执行以下操作:
repository_url , node_id等。{"title": "Copilot Chat: [Copilot Chat App] Azure ...变为Title: Copilot Chat: [Copilot Chat App] Azure ...Body (between ''')告诉LLM问题的主体是在'''字符之间。单击此处查看此步骤的结果。与此问题的JSON对象进行比较,并评论以查看文本格式的较小程度。
提示告诉LLM如何做什么以及所需的数据。
我们的提示存储在此文件中。提示指示LLM总结我们想要的格式的问题和评论( “不要浪费...”部分来自此示例)。
You are an experienced developer familiar with GitHub issues.
The following text was parsed from a GitHub issue and its comments.
Extract the following information from the issue and comments:
- Issue: A list with the following items: title, the submitter name, the submission date and
time, labels, and status (whether the issue is still open or closed).
- Summary: A summary of the issue in precisely one short sentence of no more than 50 words.
- Details: A longer summary of the issue. If code has been provided, list the pieces of code
that cause the issue in the summary.
- Comments: A table with a summary of each comment in chronological order with the columns:
date/time, time since the issue was submitted, author, and a summary of the comment.
Don't waste words. Use short, clear, complete sentences. Use active voice. Maximize detail, meaning focus on the content. Quote code snippets if they are relevant.
Answer in markdown with section headers separating each of the parts above.
现在,我们需要将请求发送到LLM所需的所有部分。不同的LLM具有不同的API,但其中大多数具有以下参数的变化:
这些是我们在这个项目中使用的主要项目。我们可以针对其他用例调整其他参数。
这是llm.py中的相关代码:
completion = client . chat . completions . create (
model = model ,
messages = [
{ "role" : "system" , "content" : prompt },
{ "role" : "user" , "content" : user_input },
],
temperature = 0.0 # We want precise and repeatable results
)LLM返回带有响应和使用数据的JSON对象。我们显示对用户的响应,并使用使用数据来计算请求的成本。
这是LLM(使用OpenAI API)的示例响应:
ChatCompletion (..., choices = [ Choice ( finish_reason = 'stop' , index = 0 , message = ChatCompletionMessage ( content =
'<response removed to save space>' , role = 'assistant' , function_call = None ))], created = 1698528558 ,
model = 'gpt-3.5-turbo-0613' , object = 'chat.completion' , usage = CompletionUsage ( completion_tokens = 304 ,
prompt_tokens = 1301 , total_tokens = 1605 ))除了响应外,我们还获得了令牌用法。成本不是回应的一部分。我们必须根据已发表的定价规则来计算自己。
在这一点上,我们拥有向用户显示响应所需的一切。
在本节中,我们将回顾一些如何在应用程序中使用LLM的示例。我们将从效果很好的简单案例开始,然后继续进行事物的行为不像预期以及如何围绕它们工作的情况。
这是以下各节所涵盖的摘要。
我们将从一个简单的案例开始,以了解LLM的总结。
使用以下命令启动用户界面。
source venv/bin/activate
streamlit run app.py然后在样本列表中选择第一个问题, <https://github.com/openai/openai-python/issues/488> (simple example) ,然后单击“使用...生成摘要”按钮。
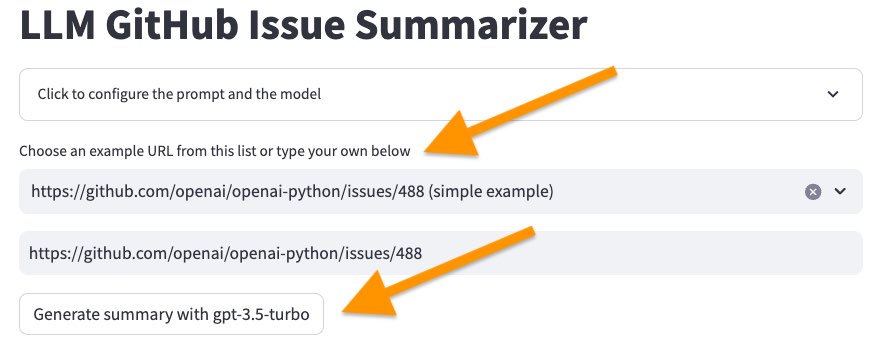
几秒钟后,我们应该得到以下图片的摘要。在顶部,我们可以看到令牌计数,成本(源自令牌计数)以及LLM生成摘要所需的时间。之后,我们看到LLM的回应。与原始的GitHub问题相比,LLM总结了问题要点和评论的出色工作。乍一看,我们可以看到问题的要点及其评论。
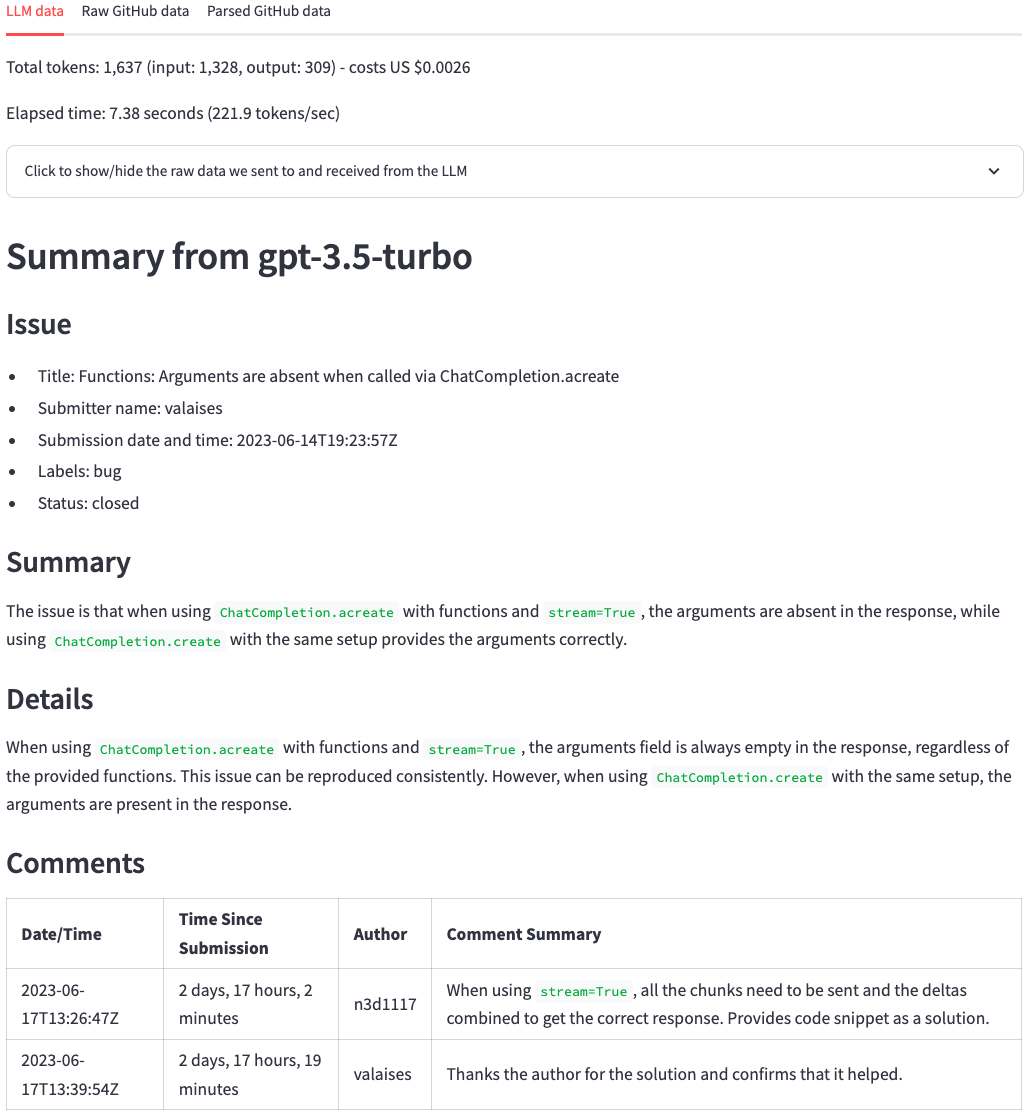
现在选择问题https://github.com/scikit-learn/scikit-learn/issues/9354 ... ,然后单击“使用...生成摘要”按钮。请勿更改LLM模型。
由于此错误,它将失败:
Error code: 400 - {'error': {'message': "This model's maximum context length is 16385 tokens. However, your messages resulted in 20437 tokens. Please reduce the length of the messages.", 'type': 'invalid_request_error', 'param': 'messages', 'code': 'context_length_exceeded'}}
每个LLM一次可以处理的令牌数量限制。此限制是上下文窗口大小。上下文窗口必须符合我们要汇总的信息和摘要本身。如果我们要汇总的信息大于上下文窗口,如我们在这种情况下所见,LLM将拒绝请求。
有几种解决此问题的方法:
我们将使用第二个选项。单击屏幕顶部的“单击以配置提示和模型” ,选择GPT-4O模型,然后单击“使用GPT-4O生成摘要”按钮。
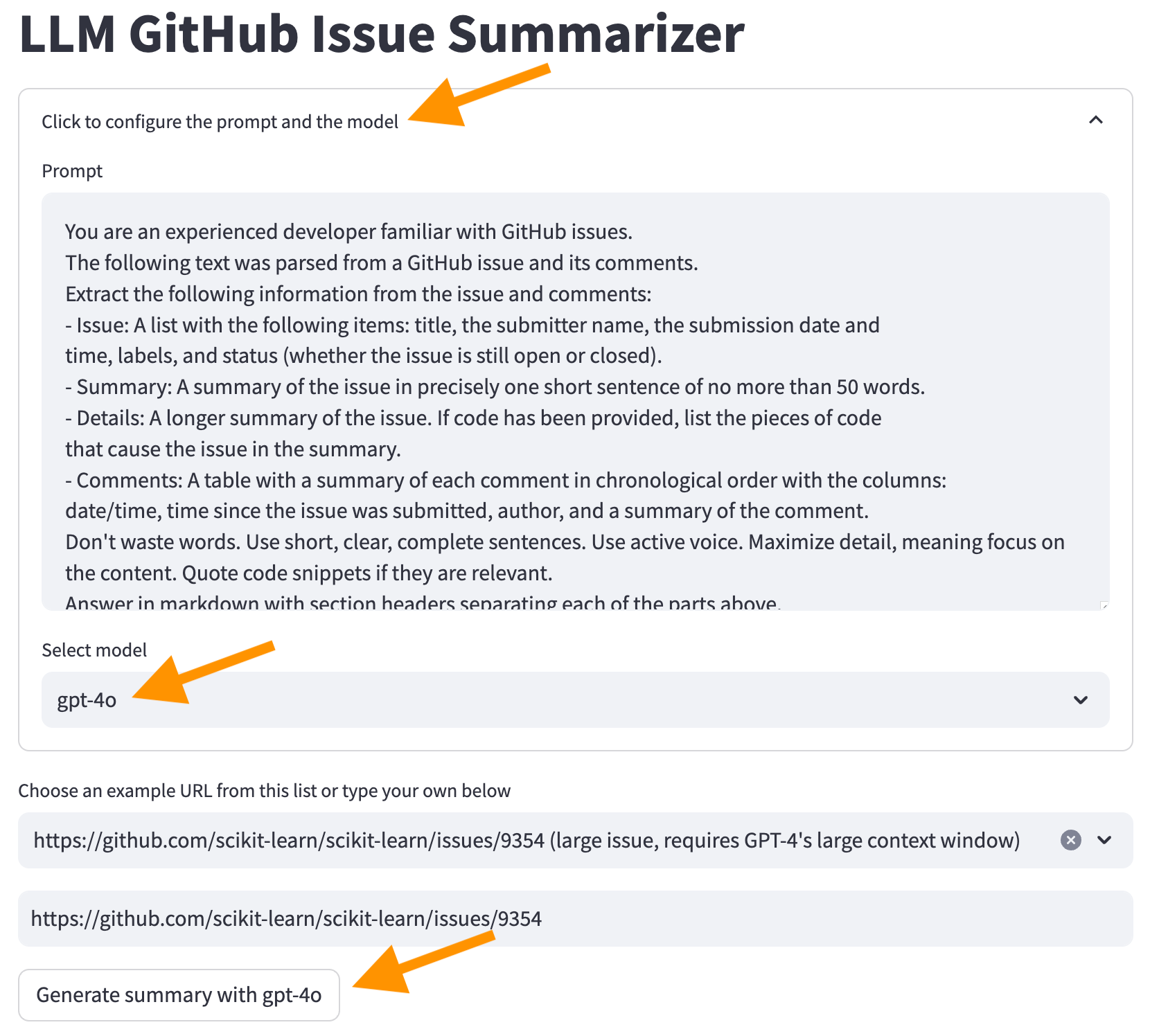
现在,我们从LLM获得了一个摘要。但是,请注意,生成摘要并成本更高将需要更长的时间。
我们为什么不从GPT-4O开始以避免此类问题?钱。通常,具有较大上下文Windows的LLMS成本更高。如果我们使用诸如OpenAI之类的AI提供商,则必须为每个令牌支付更多。如果我们自己运行模型,我们需要购买更强大的硬件。无论哪种方式,使用较大的上下文窗口的成本更高。
由于使用GPT-4O,我们也获得了更好的摘要。
为什么我们从一开始就不使用GPT-4O?除上述原因(金钱)外,还有更高的延迟。通常,更好的模型也更大。他们需要更多的硬件来运行,转化为每个令牌的成本更高,并更长的时间来产生响应。
我们可以看到比较令牌计数,成本和时间的差异,以生成GPT-3.5-Turbo和GPT-4O模型之间的摘要。
我们如何选择模型?这取决于用例。从产生良好结果的最小(因此更便宜,更快)的模型开始。创建一些启发式方法来决定何时使用更强大的模型。例如,如果注释大于某个尺寸,并且用户愿意等待更长的结果(有时平均结果更快比以后的完美结果更好),请切换到更大的模型。
先前的部分将GPT-3.5 Turbo与GPT-4O进行了比较,以强调较小模型和较大模型之间的差异。但是,在2024年7月,OpenAI推出了GPT-4O Mini型号。它具有与GPT-4O型号相同的128K令牌上下文窗口,但成本要低得多。它甚至比GPT-3.5型号便宜。有关详细信息,请参见OpenAI API定价。
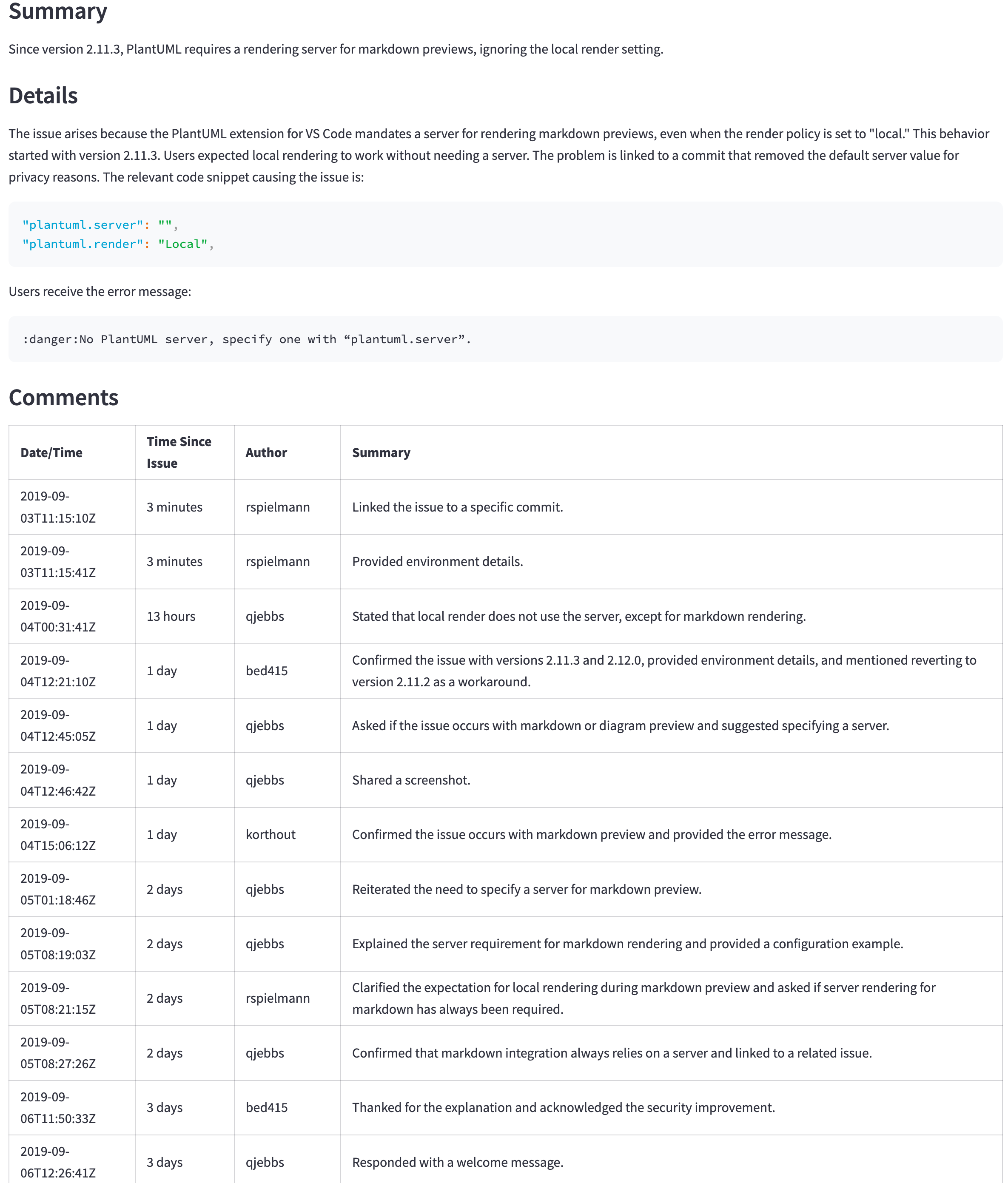
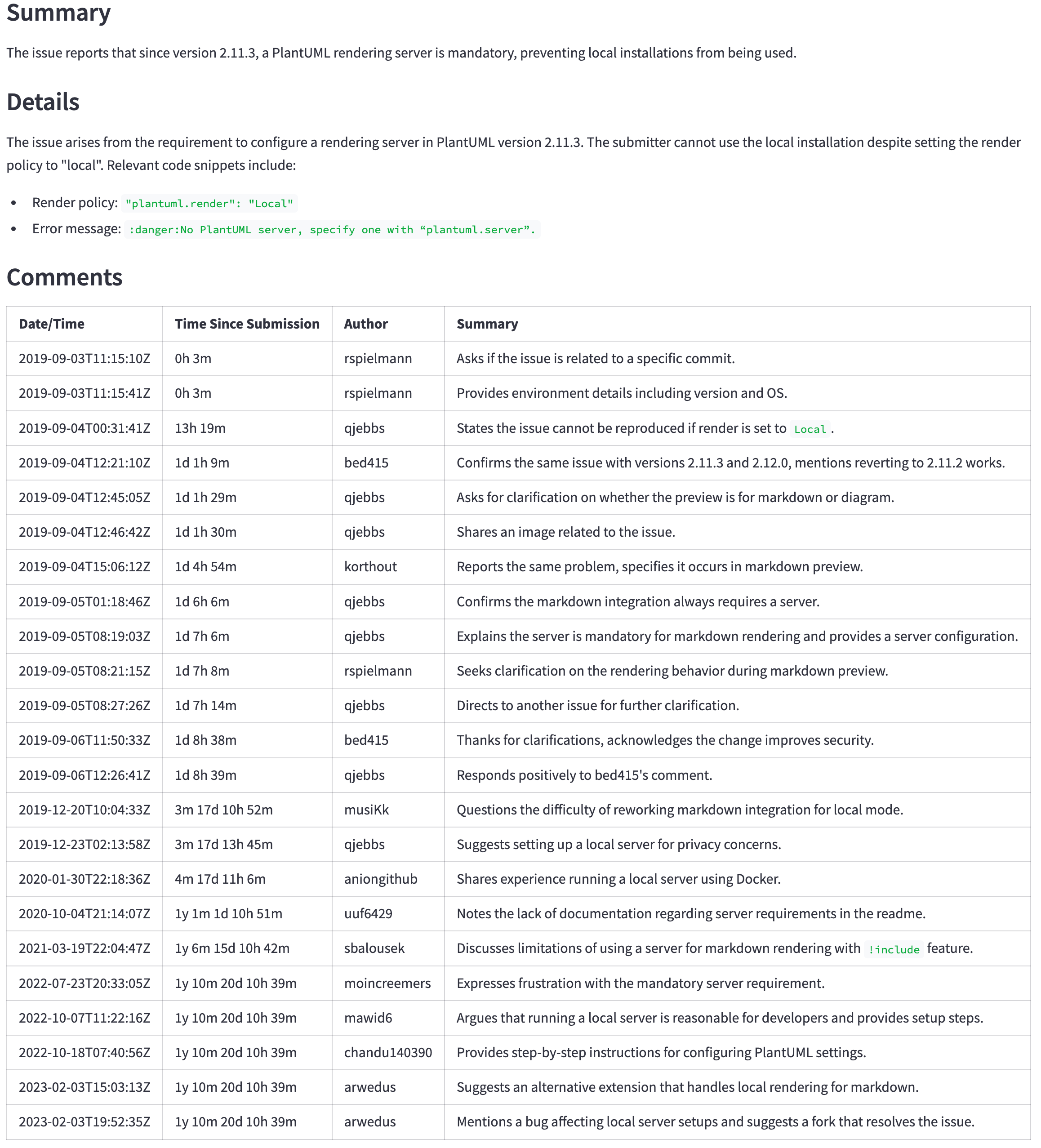
GPT-4O(非迷你)仍然是一个更好的模型,但其价格和延迟可能无法证明更好的结果是合理的。例如,下表显示了一个大问题的摘要( https://github.com/qjebbs/vscode-plantuml/issues/255 )。 GPT-4O在左侧,GPT-4O Mini在Mini上。成本的差异是惊人的,但是结果并没有太大不同。
消息是,除非您有使用GPT-3.5 Turbo的特定原因,否则应使用GPT-4O Mini模型开始一个新项目。它将产生与GPT-4O相当的结果,而少于GPT-3.5涡轮增压成本。
| GPT-4O摘要 | GPT-4O迷你摘要 |
|---|---|
| 3,859代币,US $ 0.0303 | 4,060,令牌,US $ 0.0012 |
 |  |
提示中的精确说明对于获得良好的结果很重要。为了说明好提示带来的区别:
https://github.com/openai/openai-python/issues/488 。我们得到这样的评论的摘要。

如果我们从提示中删除“不要浪费单词。请使用简短,清晰,完整的句子。使用主动语音。最大化细节,意思是关注内容。引用代码片段(如果相关)。” ,我们得到这个摘要。注意文本如何更详细,并且确实是“浪费单词”。

要删除该行,请单击屏幕顶部的“单击以配置提示和模型” ,然后从提示符中删除行,然后再次单击“使用...生成摘要”按钮。重新加载页面以还原行。
正确的提示仍然是一个实验过程。它以及时工程的名称为名。这些是一些参考,以了解有关及时工程的更多信息。
一旦我们得知我们可以用LLM总结文本,我们就可以将其用于所有内容。假设我们还想知道有关该问题的评论数量。我们可以通过将其添加到提示中来询问LLM。
单击屏幕顶部的“单击以配置提示和模型” ,然后添加行- Number of comments in the issue到下面的提示。将所有其他线保持不变。
You are an experienced developer familiar with GitHub issues.
The following text was parsed from a GitHub issue and its comments.
Extract the following information from the issue and comments:
- Issue: A list with the following items: title, the submitter name, the submission date and
time, labels, and status (whether the issue is still open or closed).
- Number of comments in the issue <-- ** ADD THIS LINE **
...remainder of the lines...
LLM将返回许多评论,但通常会错。例如,从样本列表中选择“问题” https://github.com/qjebbs/vscode-plantuml/issues/255 。这些模型均未正确获得评论的数量。
为什么?由于LLMS不是“执行”指令,因此它们只是一次生成一个令牌。
这是一个重要的概念。 LLM不了解文本的含义。他们只是根据以前的象征选择下一个令牌。它们不是代码的替代品。
代替该怎么办?如果我们可以轻松访问所需的信息,则应使用它。在这种情况下,我们可以从GitHub API响应中获取评论数量。
issue , comments = get_github_data ( st . session_state . issue_url )
num_comments = len ( comments ) # <--- This is all we need 使用cli.py中的CLI代码测试对代码的修改。在CLI中调试代码比精简应用程序更容易。代码在CLI中工作后,请调整简化应用程序。
这是一个一次性步骤。如果您已经这样做了,只需使用source venv/bin/activate激活虚拟环境。
准备环境有两个步骤。
运行以下命令以创建虚拟环境并安装所需的软件包。
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install -r requirements.txt该代码使用OpenAI GPT模型生成摘要。目前,这是开始使用LLM的最简单方法之一。虽然OpenAI用于API访问费用,但它给出了5美元的信贷,可以在使用GPT-4O Mini型号的小型项目中走很长一段路。为了避免账单,您可以设置支出限额。
如果您已经拥有OpenAI帐户,请在此处创建一个API密钥。如果您没有帐户,请在此处创建一个帐户。
拥有OpenAI API密钥后,请在项目根目录中创建一个.env文件,其中包含以下内容。
OPENAI_API_KEY= < your key >在这里添加密钥是安全的。它永远不会致力于存储库。
该项目使您可以在文档上询问问题,并从LLM获得答案。它使用与此项目类似的技术,但具有显着差异:LLM在您的计算机上本地运行。


