GPTCache
v0.1.44
將您的LLM API削減10倍?,提高速度升至100倍⚡
? gptcache已與?l蘭班(Langchain)完全集成在一起!以下是詳細的用法說明。
? GPTCache Server Docker映像已發布,這意味著任何語言都可以使用GPTCACHE!
?該項目正在進行迅速發展,因此,API可能隨時發生變化。有關最新信息,請參閱最新文檔和發行說明。
注意:由於大型模型的數量正在爆炸性地增長,並且它們的API形狀不斷發展,因此我們不再為新的API或型號增加支持。我們鼓勵使用GPTCACHE中使用GET和設置API,這是演示代碼:https://github.com/zilliztech/gptcache/blob/blob/main/main/examples/adapter/api.py.py.py.py.py.py.py.py.py
pip install gptcache
Chatgpt和各種大型語言模型(LLMS)具有令人難以置信的多功能性,從而可以開發廣泛的應用程序。但是,隨著您的應用程序的普及並遇到較高的流量水平,與LLM API呼叫有關的費用可能會變得巨大。此外,LLM服務可能會表現出緩慢的響應時間,尤其是在處理大量請求時。
為了應對這一挑戰,我們創建了GPTCACHE,該項目致力於構建用於存儲LLM響應的語義緩存。
筆記:
python --versionpython -m pip install --upgrade pip 。 # clone GPTCache repo
git clone -b dev https://github.com/zilliztech/GPTCache.git
cd GPTCache
# install the repo
pip install -r requirements.txt
python setup.py install這些示例將幫助您了解如何使用緩存的精確匹配和類似的匹配。您也可以在Colab上運行示例。還有更多示例您可以參考訓練營
在運行示例之前,請確保通過執行echo $OPENAI_API_KEY設置OpenAI_API_KEY環境變量。
如果尚未設置它,則可以通過使用Unix/Linux/MacOS系統上的export OPENAI_API_KEY=YOUR_API_KEY進行設置,或在Windows Systems上set OPENAI_API_KEY=YOUR_API_KEY 。
重要的是要注意,此方法僅暫時有效,因此,如果您想要永久效果,則需要修改環境變量配置文件。例如,在Mac上,您可以修改位於
/etc/profile文件。
import os
import time
import openai
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
question = 'what‘s chatgpt'
# OpenAI API original usage
openai . api_key = os . getenv ( "OPENAI_API_KEY" )
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )如果您向chatgpt提出完全相同的兩個問題,則第二個問題的答案將從緩存中獲得,而無需再次要求chatgpt。
import time
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
print ( "Cache loading....." )
# To use GPTCache, that's all you need
# -------------------------------------------------
from gptcache import cache
from gptcache . adapter import openai
cache . init ()
cache . set_openai_key ()
# -------------------------------------------------
question = "what's github"
for _ in range ( 2 ):
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )在回答幾個類似問題的Chatgpt答案之後,可以從緩存中檢索到後續問題的答案,而無需再次請求ChatGpt。
import time
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
from gptcache import cache
from gptcache . adapter import openai
from gptcache . embedding import Onnx
from gptcache . manager import CacheBase , VectorBase , get_data_manager
from gptcache . similarity_evaluation . distance import SearchDistanceEvaluation
print ( "Cache loading....." )
onnx = Onnx ()
data_manager = get_data_manager ( CacheBase ( "sqlite" ), VectorBase ( "faiss" , dimension = onnx . dimension ))
cache . init (
embedding_func = onnx . to_embeddings ,
data_manager = data_manager ,
similarity_evaluation = SearchDistanceEvaluation (),
)
cache . set_openai_key ()
questions = [
"what's github" ,
"can you explain what GitHub is" ,
"can you tell me more about GitHub" ,
"what is the purpose of GitHub"
]
for question in questions :
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )在請求API服務或型號時,您始終可以傳遞溫度參數。
temperature範圍為[0,2],默認值為0.0。較高的溫度意味著更高的可能跳過緩存搜索並直接要求大型模型。當溫度為2時,它將跳過緩存,並肯定會直接將請求發送到大型型號。當溫度為0時,它將在請求大型型號服務之前搜索緩存。
默認的
post_process_messages_func是temperature_softmax。在這種情況下,請參閱API引用以了解temperature如何影響輸出。
import time
from gptcache import cache , Config
from gptcache . manager import manager_factory
from gptcache . embedding import Onnx
from gptcache . processor . post import temperature_softmax
from gptcache . similarity_evaluation . distance import SearchDistanceEvaluation
from gptcache . adapter import openai
cache . set_openai_key ()
onnx = Onnx ()
data_manager = manager_factory ( "sqlite,faiss" , vector_params = { "dimension" : onnx . dimension })
cache . init (
embedding_func = onnx . to_embeddings ,
data_manager = data_manager ,
similarity_evaluation = SearchDistanceEvaluation (),
post_process_messages_func = temperature_softmax
)
# cache.config = Config(similarity_threshold=0.2)
question = "what's github"
for _ in range ( 3 ):
start = time . time ()
response = openai . ChatCompletion . create (
model = "gpt-3.5-turbo" ,
temperature = 1.0 , # Change temperature here
messages = [{
"role" : "user" ,
"content" : question
}],
)
print ( "Time elapsed:" , round ( time . time () - start , 3 ))
print ( "Answer:" , response [ "choices" ][ 0 ][ "message" ][ "content" ])要專門使用GPTCACHE,僅需要以下代碼行,並且無需修改任何現有代碼。
from gptcache import cache
from gptcache . adapter import openai
cache . init ()
cache . set_openai_key ()更多文檔:
GPTCACHE提供以下主要好處:
在線服務經常展示數據局部性,用戶經常訪問流行或流行的內容。緩存系統通過存儲通常訪問的數據來利用此行為,從而減少數據檢索時間,改善響應時間並減輕後端服務器的負擔。傳統的緩存系統通常使用新查詢和緩存查詢之間的精確匹配來確定在獲取數據之前是否可以在緩存中可用的內容可用。
但是,由於LLM查詢的複雜性和可變性,使用精確的LLM緩存方法效率較小,從而導致較低的高速緩存命中率。為了解決這個問題,GPTCACHE採用語義緩存等替代策略。語義緩存識別和存儲相似或相關的查詢,從而增加了緩存命中率並提高了總體緩存效率。
GPTCACHE採用嵌入算法將查詢轉換為嵌入式,並使用向量存儲在這些嵌入式上進行相似性搜索。此過程使GPTCACHE可以從緩存存儲中識別和檢索相似或相關的查詢,如模塊部分所示。
GPTCACHE具有模塊化設計,使用戶可以輕鬆自定義自己的語義緩存。該系統為每個模塊提供了各種實現,用戶甚至可以開發自己的實現以適應其特定需求。
在語義緩存中,您可能會在緩存命中期間遇到誤報,而在緩存錯過期間的假否定性。 GPTCACHE提供了三個指標來衡量其性能,這對於開發人員優化其緩存系統很有幫助:
包括樣本基準,以供用戶開始評估其語義緩存的性能。
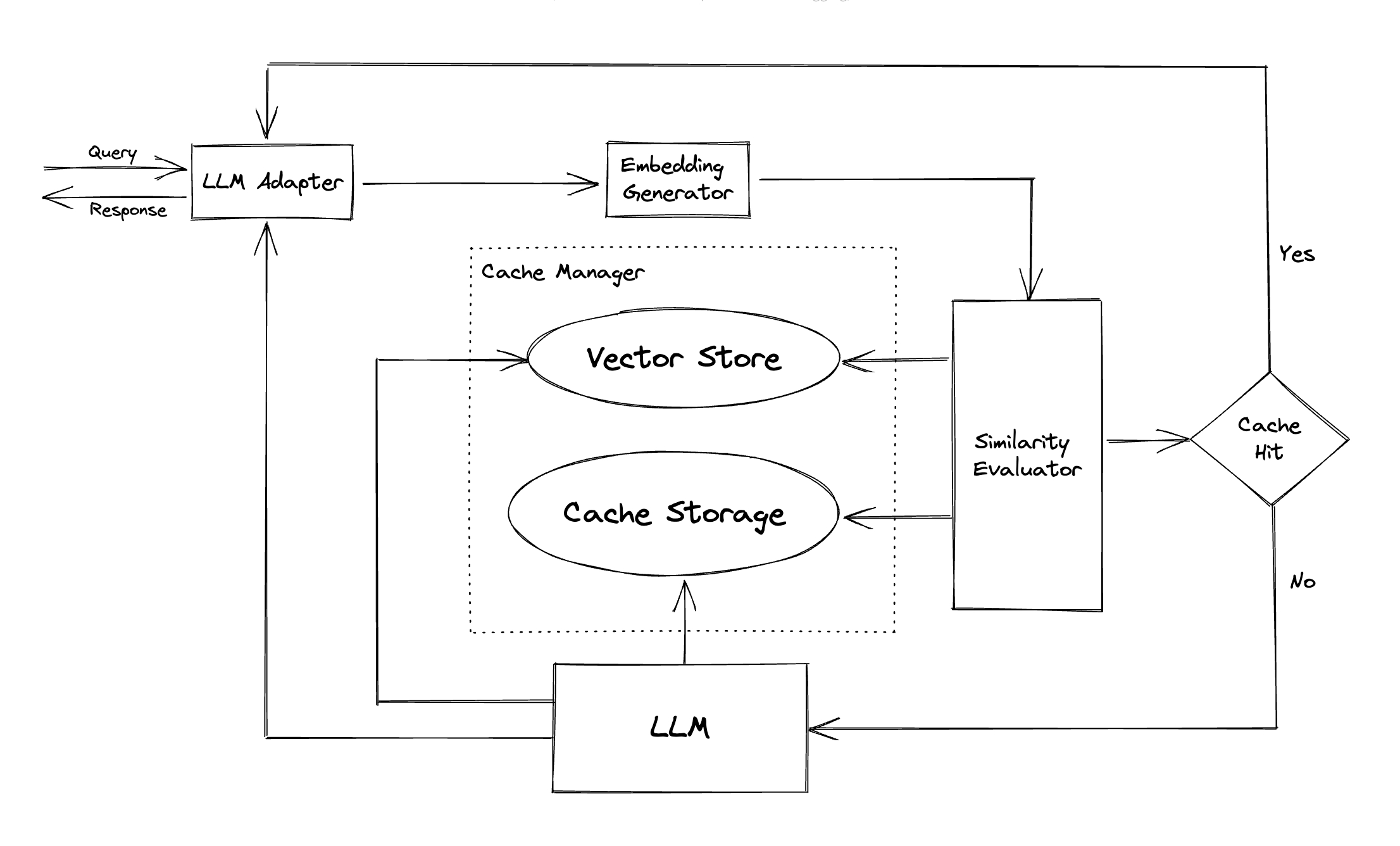
LLM適配器:LLM適配器旨在通過統一其API和請求協議來整合不同的LLM模型。 GPTCACHE為此目的提供了標準化的接口,並提供了ChatGPT集成的當前支持。
多模式適配器(實驗) :多模式適配器旨在通過統一其API和請求協議來整合不同的大型多模型。 GPTCACHE為此目的提供了標準化的接口,並提供了對圖像生成,音頻轉錄集成的當前支持。
嵌入生成器:創建此模塊是為了從請求中提取嵌入式以進行相似性搜索。 GPTCACHE提供了一個通用接口,該接口支持多個嵌入API,並提供一系列可供選擇的解決方案。
緩存存儲:緩存存儲是存儲LLM的響應的地方,例如ChatGpt。檢索緩存的響應以幫助評估相似性,並在有良好的語義匹配的情況下返回請求者。目前,GPTCACHE支持SQLite,並提供了一個通用的接口,用於擴展此模塊。
向量存儲:矢量存儲模塊可幫助從輸入請求的提取的嵌入中找到k最相似的請求。結果可以幫助評估相似性。 GPTCACHE提供了一個用戶友好的接口,該接口支持各種向量商店,包括Milvus,Zilliz Cloud和Faiss。將來還會有更多選項。
緩存管理器:高速緩存管理器負責控制緩存存儲和向量存儲的操作。
cachetools或以Redis作為鑰匙值商店的方式在內存中管理緩存驅逐。當前,GPTCACHE僅根據行數做出決定。這種方法可能導致資源評估不准確,並可能導致內置(OOM)錯誤。我們正在積極調查和製定更複雜的策略。
如果您使用內存中的緩存可以水平擴展GPTCACHE部署,那將是不可能的。由於緩存的信息將僅限於單個POD。
使用分佈式緩存,緩存信息在所有復製品中都一致,我們可以使用Redis等分佈式緩存商店。
相似性評估器:此模塊從緩存存儲和向量存儲中收集數據,並使用各種策略來確定輸入請求與矢量存儲的請求之間的相似性。基於此相似性,它決定了請求是否匹配緩存。 GPTCACHE提供了一個標準化的接口,用於集成各種策略,以及用於使用的實現集合。目前支持或將來將支持以下相似性定義:
注意:並非不同模塊的所有組合都可以彼此兼容。例如,如果我們禁用嵌入式提取器,則矢量存儲可能無法按預期運行。我們目前正在努力實施GPTCACHE的組合理智檢查。
即將推出!敬請關注!
通過新功能,增強的基礎架構或改進的文檔,我們對貢獻非常開放。
有關如何貢獻的全面說明,請參閱我們的貢獻指南。


