GPTCache
v0.1.44
ลดค่าใช้จ่าย LLM API ของคุณ 10 เท่า? เพิ่มความเร็วด้วย 100x ⚡
- gptcache ได้รับการรวมเข้ากับ️? langchain! นี่คือคำแนะนำการใช้งานโดยละเอียด
- รูปภาพ Docker เซิร์ฟเวอร์ GPTCACHE ได้รับการเผยแพร่ซึ่งหมายความว่า ภาษาใด ๆ จะสามารถใช้ GPTCACHE!
- โครงการนี้อยู่ระหว่างการพัฒนาอย่างรวดเร็วและเช่นนี้ API อาจมีการเปลี่ยนแปลงได้ตลอดเวลา สำหรับข้อมูลที่ทันสมัยที่สุดโปรดดูเอกสารล่าสุดและบันทึกย่อล่าสุด
หมายเหตุ: เนื่องจากจำนวนรุ่นขนาดใหญ่เพิ่มขึ้นอย่างรวดเร็วและรูปร่าง API ของพวกเขามีการพัฒนาอย่างต่อเนื่องเราจะไม่เพิ่มการสนับสนุน API หรือรุ่นใหม่อีกต่อไป เราสนับสนุนให้ใช้การใช้ API Get and Set ใน gptcache นี่คือรหัสตัวอย่าง: https://github.com/zilliztech/gptcache/blob/main/examples/adapter/api.py
pip install gptcache
CHATGPT และโมเดลภาษาขนาดใหญ่ที่หลากหลาย (LLMS) มีความเก่งกาจอย่างไม่น่าเชื่อทำให้สามารถพัฒนาแอพพลิเคชั่นที่หลากหลาย อย่างไรก็ตามเมื่อแอปพลิเคชันของคุณได้รับความนิยมเพิ่มขึ้นและเผชิญหน้ากับระดับการจราจรที่สูงขึ้นค่าใช้จ่ายที่เกี่ยวข้องกับการโทร LLM API อาจกลายเป็นอย่างมาก นอกจากนี้บริการ LLM อาจแสดงเวลาตอบสนองที่ช้าโดยเฉพาะอย่างยิ่งเมื่อจัดการกับคำขอจำนวนมาก
เพื่อจัดการกับความท้าทายนี้เราได้สร้าง GPTCACHE ซึ่งเป็นโครงการที่อุทิศให้กับการสร้างแคชความหมายสำหรับการจัดเก็บคำตอบ LLM
บันทึก :
python --versionpython -m pip install --upgrade pip # clone GPTCache repo
git clone -b dev https://github.com/zilliztech/GPTCache.git
cd GPTCache
# install the repo
pip install -r requirements.txt
python setup.py installตัวอย่างเหล่านี้จะช่วยให้คุณเข้าใจวิธีการใช้การจับคู่ที่แน่นอนและคล้ายกันกับการแคช คุณยังสามารถเรียกใช้ตัวอย่างบน colab และตัวอย่างเพิ่มเติมที่คุณสามารถอ้างถึง bootcamp
ก่อนที่จะเรียกใช้ตัวอย่างตรวจสอบ ให้แน่ใจว่า ตัวแปรสภาพแวดล้อม OpenAI_API_KEY ถูกตั้งค่าโดยการดำเนินการ echo $OPENAI_API_KEY
หากยังไม่ได้ตั้งค่าไว้ก็สามารถตั้งค่าได้โดยใช้ export OPENAI_API_KEY=YOUR_API_KEY บนระบบ Unix/Linux/MacOS หรือ set OPENAI_API_KEY=YOUR_API_KEY บนระบบ Windows
เป็นสิ่งสำคัญที่จะต้องทราบว่าวิธีนี้มีประสิทธิภาพชั่วคราวเท่านั้นดังนั้นหากคุณต้องการเอฟเฟกต์ถาวรคุณจะต้องแก้ไขไฟล์การกำหนดค่าตัวแปรสภาพแวดล้อม ตัวอย่างเช่นบน Mac คุณสามารถแก้ไขไฟล์ที่อยู่ที่
/etc/profile
import os
import time
import openai
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
question = 'what‘s chatgpt'
# OpenAI API original usage
openai . api_key = os . getenv ( "OPENAI_API_KEY" )
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )หากคุณถามคำถามสองข้อที่เหมือนกันคำตอบสำหรับคำถามที่สองจะได้รับจากแคชโดยไม่ต้องขอ CHATGPT อีกครั้ง
import time
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
print ( "Cache loading....." )
# To use GPTCache, that's all you need
# -------------------------------------------------
from gptcache import cache
from gptcache . adapter import openai
cache . init ()
cache . set_openai_key ()
# -------------------------------------------------
question = "what's github"
for _ in range ( 2 ):
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )หลังจากได้รับคำตอบจาก CHATGPT เพื่อตอบคำถามที่คล้ายกันหลายคำถามคำตอบสำหรับคำถามที่ตามมาสามารถดึงได้จากแคชโดยไม่จำเป็นต้องขอ ChatGPT อีกครั้ง
import time
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
from gptcache import cache
from gptcache . adapter import openai
from gptcache . embedding import Onnx
from gptcache . manager import CacheBase , VectorBase , get_data_manager
from gptcache . similarity_evaluation . distance import SearchDistanceEvaluation
print ( "Cache loading....." )
onnx = Onnx ()
data_manager = get_data_manager ( CacheBase ( "sqlite" ), VectorBase ( "faiss" , dimension = onnx . dimension ))
cache . init (
embedding_func = onnx . to_embeddings ,
data_manager = data_manager ,
similarity_evaluation = SearchDistanceEvaluation (),
)
cache . set_openai_key ()
questions = [
"what's github" ,
"can you explain what GitHub is" ,
"can you tell me more about GitHub" ,
"what is the purpose of GitHub"
]
for question in questions :
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )คุณสามารถผ่านพารามิเตอร์ของอุณหภูมิได้ตลอดเวลาในขณะที่ขอบริการ API หรือรุ่น
ช่วง
temperatureคือ [0, 2] ค่าเริ่มต้นคือ 0.0อุณหภูมิที่สูงขึ้นหมายถึงความเป็นไปได้ที่สูงขึ้นในการข้ามการค้นหาแคชและการร้องขอโมเดลขนาดใหญ่โดยตรง เมื่ออุณหภูมิคือ 2 มันจะข้ามแคชและส่งคำขอไปยังรุ่นใหญ่โดยตรงอย่างแน่นอน เมื่ออุณหภูมิเป็น 0 มันจะค้นหาแคชก่อนขอบริการรุ่นใหญ่
ค่าเริ่มต้น
post_process_messages_funcคือtemperature_softmaxในกรณีนี้อ้างอิงการอ้างอิง API เพื่อเรียนรู้เกี่ยวกับtemperatureที่มีผลต่อเอาต์พุต
import time
from gptcache import cache , Config
from gptcache . manager import manager_factory
from gptcache . embedding import Onnx
from gptcache . processor . post import temperature_softmax
from gptcache . similarity_evaluation . distance import SearchDistanceEvaluation
from gptcache . adapter import openai
cache . set_openai_key ()
onnx = Onnx ()
data_manager = manager_factory ( "sqlite,faiss" , vector_params = { "dimension" : onnx . dimension })
cache . init (
embedding_func = onnx . to_embeddings ,
data_manager = data_manager ,
similarity_evaluation = SearchDistanceEvaluation (),
post_process_messages_func = temperature_softmax
)
# cache.config = Config(similarity_threshold=0.2)
question = "what's github"
for _ in range ( 3 ):
start = time . time ()
response = openai . ChatCompletion . create (
model = "gpt-3.5-turbo" ,
temperature = 1.0 , # Change temperature here
messages = [{
"role" : "user" ,
"content" : question
}],
)
print ( "Time elapsed:" , round ( time . time () - start , 3 ))
print ( "Answer:" , response [ "choices" ][ 0 ][ "message" ][ "content" ])ในการใช้ GPTCACHE โดยเฉพาะจำเป็นต้องใช้รหัสบรรทัดต่อไปนี้และไม่จำเป็นต้องแก้ไขรหัสใด ๆ ที่มีอยู่
from gptcache import cache
from gptcache . adapter import openai
cache . init ()
cache . set_openai_key ()เอกสารเพิ่มเติม:
GPTCACHE เสนอประโยชน์หลักต่อไปนี้:
บริการออนไลน์มักจะแสดงสถานที่ข้อมูลโดยผู้ใช้มักจะเข้าถึงเนื้อหายอดนิยมหรือได้รับความนิยม ระบบแคชใช้ประโยชน์จากพฤติกรรมนี้โดยการจัดเก็บข้อมูลที่เข้าถึงได้ทั่วไปซึ่งจะช่วยลดเวลาในการดึงข้อมูลปรับปรุงเวลาตอบสนองและลดภาระของเซิร์ฟเวอร์แบ็กเอนด์ ระบบแคชแบบดั้งเดิมโดยทั่วไปใช้การจับคู่ที่แน่นอนระหว่างแบบสอบถามใหม่และแบบสอบถามแคชเพื่อตรวจสอบว่าเนื้อหาที่ร้องขอมีอยู่ในแคชก่อนที่จะดึงข้อมูลหรือไม่
อย่างไรก็ตามการใช้วิธีการจับคู่ที่แน่นอนสำหรับแคช LLM นั้นมีประสิทธิภาพน้อยกว่าเนื่องจากความซับซ้อนและความแปรปรวนของการสืบค้น LLM ส่งผลให้อัตราการตีแคชต่ำ เพื่อแก้ไขปัญหานี้ GPTCACHE ใช้กลยุทธ์ทางเลือกเช่นการแคชความหมาย การแคชความหมายระบุและจัดเก็บแบบสอบถามที่คล้ายกันหรือที่เกี่ยวข้องซึ่งจะเป็นการเพิ่มความน่าจะเป็นของแคชและเพิ่มประสิทธิภาพการแคชโดยรวม
GPTCACHE ใช้อัลกอริทึมการฝังเพื่อแปลงการสืบค้นเป็น EMBEDDINGS และใช้ร้านค้าเวกเตอร์สำหรับการค้นหาความคล้ายคลึงกันในการฝังตัวเหล่านี้ กระบวนการนี้ช่วยให้ GPTCache สามารถระบุและดึงข้อความค้นหาที่คล้ายกันหรือที่เกี่ยวข้องจากที่เก็บแคชดังแสดงในส่วนโมดูล
มีการออกแบบแบบแยกส่วน GPTCache ทำให้ผู้ใช้สามารถปรับแต่งแคชความหมายของตัวเองได้ง่าย ระบบนำเสนอการใช้งานที่หลากหลายสำหรับแต่ละโมดูลและผู้ใช้สามารถพัฒนาการใช้งานของตนเองเพื่อให้เหมาะกับความต้องการเฉพาะของพวกเขา
ในแคชความหมายคุณอาจพบกับข้อดีที่ผิดพลาดในระหว่างการตีแคชและเชิงลบที่ผิดพลาดในระหว่างการพลาดแคช GPTCACHE เสนอสามเมตริกเพื่อวัดประสิทธิภาพซึ่งเป็นประโยชน์สำหรับนักพัฒนาในการเพิ่มประสิทธิภาพระบบแคชของพวกเขา:
เกณฑ์มาตรฐานตัวอย่างรวมอยู่สำหรับผู้ใช้ในการเริ่มต้นด้วยการประเมินประสิทธิภาพของแคชความหมายของพวกเขา
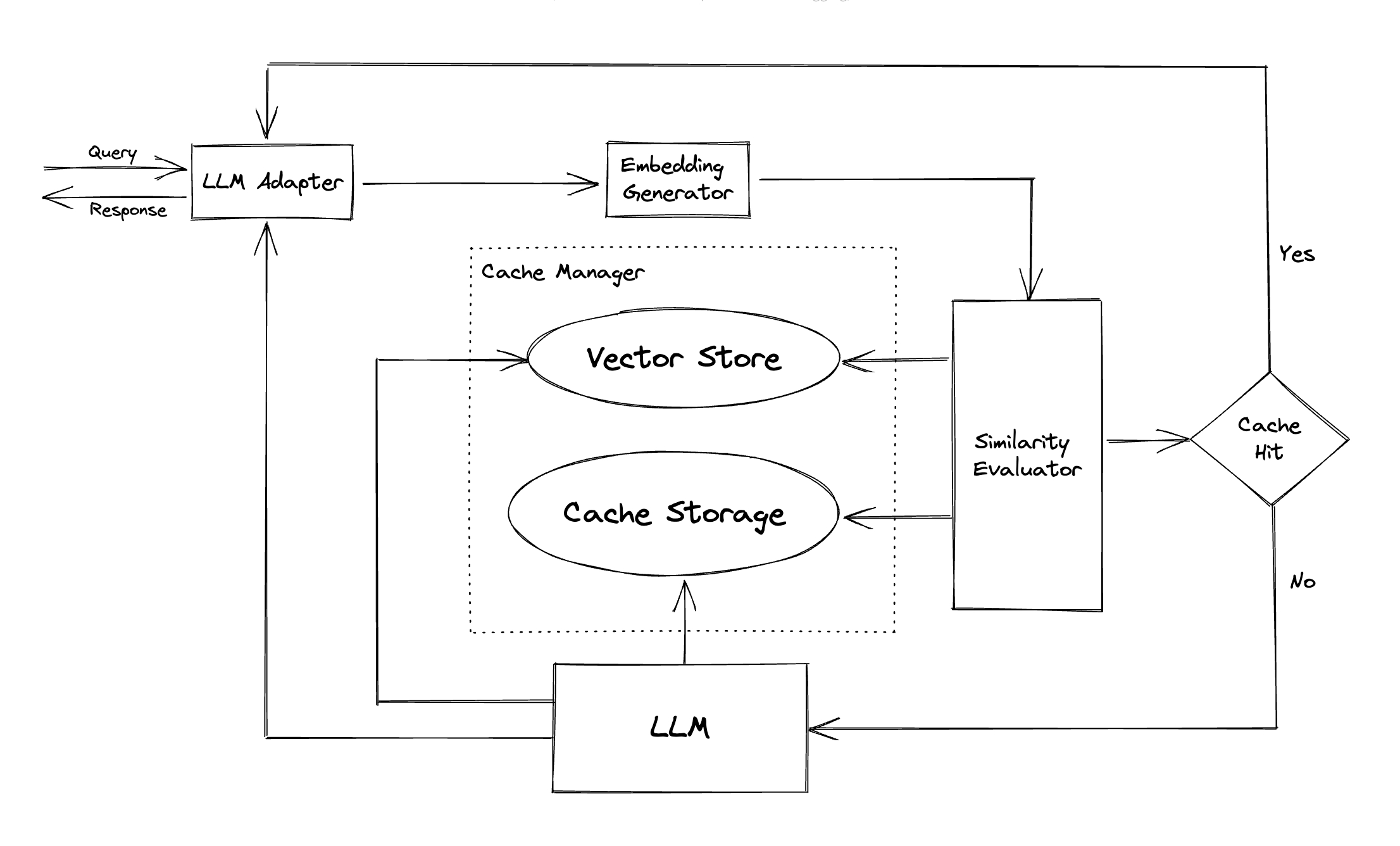
อะแดปเตอร์ LLM : อะแดปเตอร์ LLM ได้รับการออกแบบมาเพื่อรวมโมเดล LLM ที่แตกต่างกันโดยการรวม APIs และคำขอโปรโตคอล GPTCACHE นำเสนออินเทอร์เฟซที่เป็นมาตรฐานสำหรับจุดประสงค์นี้พร้อมการสนับสนุนในปัจจุบันสำหรับการรวม ChatGPT
อะแดปเตอร์ Multimodal (การทดลอง) : อะแดปเตอร์แบบหลายรูปแบบได้รับการออกแบบมาเพื่อรวมโมเดลขนาดใหญ่หลายรูปแบบที่แตกต่างกันโดยการรวม APIs และคำขอโปรโตคอล GPTCACHE นำเสนออินเทอร์เฟซที่เป็นมาตรฐานสำหรับจุดประสงค์นี้ด้วยการสนับสนุนในปัจจุบันสำหรับการรวมการสร้างภาพการถอดรหัสเสียง
Embedding Generator : โมดูลนี้ถูกสร้างขึ้นเพื่อแยกการฝังตัวจากคำขอสำหรับการค้นหาความคล้ายคลึงกัน GPTCACHE นำเสนออินเทอร์เฟซทั่วไปที่รองรับ API แบบฝังหลายตัวและนำเสนอโซลูชั่นที่หลากหลายให้เลือก
ที่เก็บแคช : ที่เก็บแคช เป็นที่ที่การตอบสนองจาก LLMs เช่น chatgpt ถูกเก็บไว้ การตอบกลับแคชจะถูกเรียกคืนเพื่อช่วยในการประเมินความคล้ายคลึงกันและจะถูกส่งกลับไปยังผู้ร้องขอหากมีการจับคู่ความหมายที่ดี ในปัจจุบัน GPTCACHE รองรับ SQLITE และเสนออินเตอร์เฟสที่เข้าถึงได้ง่ายสำหรับการขยายโมดูลนี้
Vector Store : โมดูล Vector Store ช่วยค้นหาคำขอ K ที่คล้ายกันมากที่สุดจากการฝังตัวของคำขออินพุต ผลลัพธ์สามารถช่วยประเมินความคล้ายคลึงกัน GPTCACHE ให้บริการอินเทอร์เฟซที่ใช้งานง่ายซึ่งรองรับร้านค้าเวกเตอร์ต่าง ๆ รวมถึง Milvus, Zilz Cloud และ FAISS ตัวเลือกเพิ่มเติมจะพร้อมใช้งานในอนาคต
Cache Manager : Cache Manager มีหน้าที่ควบคุมการทำงานของ ที่เก็บแคช และ ร้านค้าเวกเตอร์
cachetools ของ Python หรือในแบบกระจายโดยใช้ Redis เป็นร้านค้าคีย์-ค่าปัจจุบัน GPTCACHE ตัดสินใจเกี่ยวกับการขับไล่ตามจำนวนบรรทัดเท่านั้น วิธีการนี้อาจส่งผลให้เกิดการประเมินทรัพยากรที่ไม่ถูกต้องและอาจทำให้เกิดข้อผิดพลาดนอกหน่วยความจำ (OOM) เรากำลังตรวจสอบและพัฒนากลยุทธ์ที่ซับซ้อนมากขึ้นอย่างแข็งขัน
หากคุณต้องขยายการปรับใช้ GPTCache ในแนวนอนโดยใช้การแคชในหน่วยความจำมันจะเป็นไปไม่ได้ เนื่องจากข้อมูลแคชจะถูก จำกัด ไว้ที่พ็อดเดี่ยว
ด้วยการแคชแบบกระจายข้อมูลแคชที่สอดคล้องกันในแบบจำลองทั้งหมดเราสามารถใช้ร้านค้าแคชแบบกระจายเช่น Redis
ผู้ประเมินความคล้ายคลึงกัน : โมดูลนี้รวบรวมข้อมูลจาก ที่เก็บแคช และ ที่เก็บเวกเตอร์ และใช้กลยุทธ์ต่าง ๆ เพื่อกำหนดความคล้ายคลึงกันระหว่างคำขออินพุตและคำขอจาก ร้านค้าเวกเตอร์ ขึ้นอยู่กับความคล้ายคลึงกันนี้จะกำหนดว่าคำขอตรงกับแคชหรือไม่ GPTCACHE จัดเตรียมอินเทอร์เฟซที่ได้มาตรฐานสำหรับการรวมกลยุทธ์ต่าง ๆ เข้าด้วยกันพร้อมกับการรวบรวมการใช้งานที่จะใช้ คำจำกัดความความคล้ายคลึงกันต่อไปนี้ได้รับการสนับสนุนในปัจจุบันหรือจะได้รับการสนับสนุนในอนาคต:
หมายเหตุ : การรวมกันของโมดูลที่แตกต่างกันทั้งหมดอาจเข้ากันได้กับกันและกัน ตัวอย่างเช่นหากเราปิดใช้งาน ตัวแยกการฝังตัวที่ เก็บเวกเตอร์ อาจไม่ทำงานตามที่ตั้งใจไว้ ขณะนี้เรากำลังดำเนินการในการใช้การตรวจสอบความมีสติแบบผสมผสานสำหรับ GPTCACHE
เร็วๆ นี้! คอยติดตาม!
เราเปิดกว้างอย่างมากสำหรับการมีส่วนร่วมไม่ว่าจะผ่านคุณสมบัติใหม่โครงสร้างพื้นฐานที่ปรับปรุงแล้วหรือเอกสารที่ได้รับการปรับปรุง
สำหรับคำแนะนำที่ครอบคลุมเกี่ยวกับวิธีการมีส่วนร่วมโปรดดูคู่มือการบริจาคของเรา


