GPTCache
v0.1.44
LLM APIコストを10倍に削減し、100倍の速度を上昇させる⚡
? gptcacheは?□langchainと完全に統合されています!詳細な使用手順は次のとおりです。
? GPTCache Server Docker画像がリリースされました。つまり、どの言語もGPTCacheを使用できます。
?このプロジェクトはSwift開発を行っているため、APIはいつでも変更される場合があります。最新の情報については、最新のドキュメントとリリースメモを参照してください。
注:大型モデルの数は爆発的に増加しており、APIの形状は絶えず進化しているため、新しいAPIやモデルのサポートはもはや追加されなくなりました。 gptcacheでget and set apiを使用することをお勧めします。ここにデモコードがあります:https://github.com/zilliztech/gptcache/blob/main/examples/adapter/api.py
pip install gptcache
ChatGptとさまざまな大規模な言語モデル(LLMS)は、幅広いアプリケーションの開発を可能にする信じられないほどの汎用性を誇っています。ただし、アプリケーションの人気が高まり、トラフィックレベルが高いため、LLM API呼び出しに関連する費用が大幅になる可能性があります。さらに、LLMサービスは、特にかなりの数のリクエストを扱う場合、応答時間が遅くなる可能性があります。
この課題に取り組むために、LLM応答を保存するためのセマンティックキャッシュの構築に特化したプロジェクトであるGptCacheを作成しました。
注記:
python --versionが3.8.1以上であることを確認してください。python -m pip install --upgrade pip実行します。 # clone GPTCache repo
git clone -b dev https://github.com/zilliztech/GPTCache.git
cd GPTCache
# install the repo
pip install -r requirements.txt
python setup.py installこれらの例は、キャッシングとの正確で同様のマッチングを使用する方法を理解するのに役立ちます。 Colabで例を実行することもできます。さらに、ブートキャンプを参照できます
例を実行する前に、 echo $OPENAI_API_KEYを実行してOpenai_Api_key環境変数が設定されていることを確認してください。
まだ設定されていない場合は、unix/linux/macosシステムでexport OPENAI_API_KEY=YOUR_API_KEYを使用するか、Windowsシステムでset OPENAI_API_KEY=YOUR_API_KEY設定できます。
この方法は一時的にのみ効果的であることに注意することが重要です。したがって、永続的な効果が必要な場合は、環境変数構成ファイルを変更する必要があります。たとえば、Macでは、
/etc/profileにあるファイルを変更できます。
import os
import time
import openai
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
question = 'what‘s chatgpt'
# OpenAI API original usage
openai . api_key = os . getenv ( "OPENAI_API_KEY" )
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )ChatGptにまったく同じ2つの質問を尋ねると、2番目の質問に対する答えは、ChatGPTを再度要求することなくキャッシュから得られます。
import time
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
print ( "Cache loading....." )
# To use GPTCache, that's all you need
# -------------------------------------------------
from gptcache import cache
from gptcache . adapter import openai
cache . init ()
cache . set_openai_key ()
# -------------------------------------------------
question = "what's github"
for _ in range ( 2 ):
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )いくつかの同様の質問に応答してChatGPTから回答を取得した後、後続の質問に対する回答は、CHATGPTを再度リクエストする必要なく、キャッシュから取得できます。
import time
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
from gptcache import cache
from gptcache . adapter import openai
from gptcache . embedding import Onnx
from gptcache . manager import CacheBase , VectorBase , get_data_manager
from gptcache . similarity_evaluation . distance import SearchDistanceEvaluation
print ( "Cache loading....." )
onnx = Onnx ()
data_manager = get_data_manager ( CacheBase ( "sqlite" ), VectorBase ( "faiss" , dimension = onnx . dimension ))
cache . init (
embedding_func = onnx . to_embeddings ,
data_manager = data_manager ,
similarity_evaluation = SearchDistanceEvaluation (),
)
cache . set_openai_key ()
questions = [
"what's github" ,
"can you explain what GitHub is" ,
"can you tell me more about GitHub" ,
"what is the purpose of GitHub"
]
for question in questions :
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )APIサービスまたはモデルを要求しながら、いつでも温度のパラメーターを渡すことができます。
temperatureの範囲は[0、2]、デフォルト値は0.0です。温度が高いということは、キャッシュの検索をスキップして大規模なモデルを直接要求する可能性が高いことを意味します。温度が2の場合、キャッシュをスキップして、確実に直接大きなモデルにリクエストを送信します。温度が0の場合、大規模なモデルサービスをリクエストする前にキャッシュを検索します。
デフォルトの
post_process_messages_funcはtemperature_softmaxです。この場合、API参照を参照して、temperature出力にどのように影響するかについて学習します。
import time
from gptcache import cache , Config
from gptcache . manager import manager_factory
from gptcache . embedding import Onnx
from gptcache . processor . post import temperature_softmax
from gptcache . similarity_evaluation . distance import SearchDistanceEvaluation
from gptcache . adapter import openai
cache . set_openai_key ()
onnx = Onnx ()
data_manager = manager_factory ( "sqlite,faiss" , vector_params = { "dimension" : onnx . dimension })
cache . init (
embedding_func = onnx . to_embeddings ,
data_manager = data_manager ,
similarity_evaluation = SearchDistanceEvaluation (),
post_process_messages_func = temperature_softmax
)
# cache.config = Config(similarity_threshold=0.2)
question = "what's github"
for _ in range ( 3 ):
start = time . time ()
response = openai . ChatCompletion . create (
model = "gpt-3.5-turbo" ,
temperature = 1.0 , # Change temperature here
messages = [{
"role" : "user" ,
"content" : question
}],
)
print ( "Time elapsed:" , round ( time . time () - start , 3 ))
print ( "Answer:" , response [ "choices" ][ 0 ][ "message" ][ "content" ])GPTCacheのみを使用するには、次のコード行のみが必要であり、既存のコードを変更する必要はありません。
from gptcache import cache
from gptcache . adapter import openai
cache . init ()
cache . set_openai_key ()その他のドキュメント:
gptcacheは次の主要な利点を提供します。
オンラインサービスは、多くの場合、データの地域を示し、ユーザーは人気のあるコンテンツやトレンドコンテンツに頻繁にアクセスします。キャッシュシステムは、一般的にアクセスされるデータを保存することにより、この動作を活用します。これにより、データの検索時間が短縮され、応答時間が改善され、バックエンドサーバーの負担が緩和されます。従来のキャッシュシステムは通常、新しいクエリとキャッシュクエリの正確な一致を利用して、データを取得する前に要求されたコンテンツがキャッシュで利用可能かどうかを判断します。
ただし、LLMキャッシュの正確な一致アプローチを使用すると、LLMクエリの複雑さと変動性があるため、キャッシュヒット率が低くなります。この問題に対処するために、GPTCacheはセマンティックキャッシュなどの代替戦略を採用しています。セマンティックキャッシングは、類似または関連するクエリを識別および保存し、それによりキャッシュが確率を増やし、全体的なキャッシング効率を高めます。
GPTCacheは、埋め込みアルゴリズムを使用してクエリを埋め込みに変換し、これらの埋め込みの類似性検索にベクターストアを使用します。このプロセスにより、GPTCacheは、モジュールセクションに示すように、キャッシュストレージから類似または関連するクエリを識別および取得できます。
モジュラーデザインを備えたGPTCacheを使用すると、ユーザーが独自のセマンティックキャッシュを簡単にカスタマイズできます。このシステムは、各モジュールにさまざまな実装を提供し、ユーザーは特定のニーズに合わせて独自の実装を開発することもできます。
セマンティックキャッシュでは、キャッシュヒット中に誤検知とキャッシュミス中に偽陰性に遭遇する可能性があります。 GptCacheは、パフォーマンスを評価するための3つのメトリックを提供します。これは、開発者がキャッシュシステムを最適化するのに役立ちます。
ユーザーがセマンティックキャッシュのパフォーマンスを評価することを開始するためのサンプルベンチマークが含まれています。
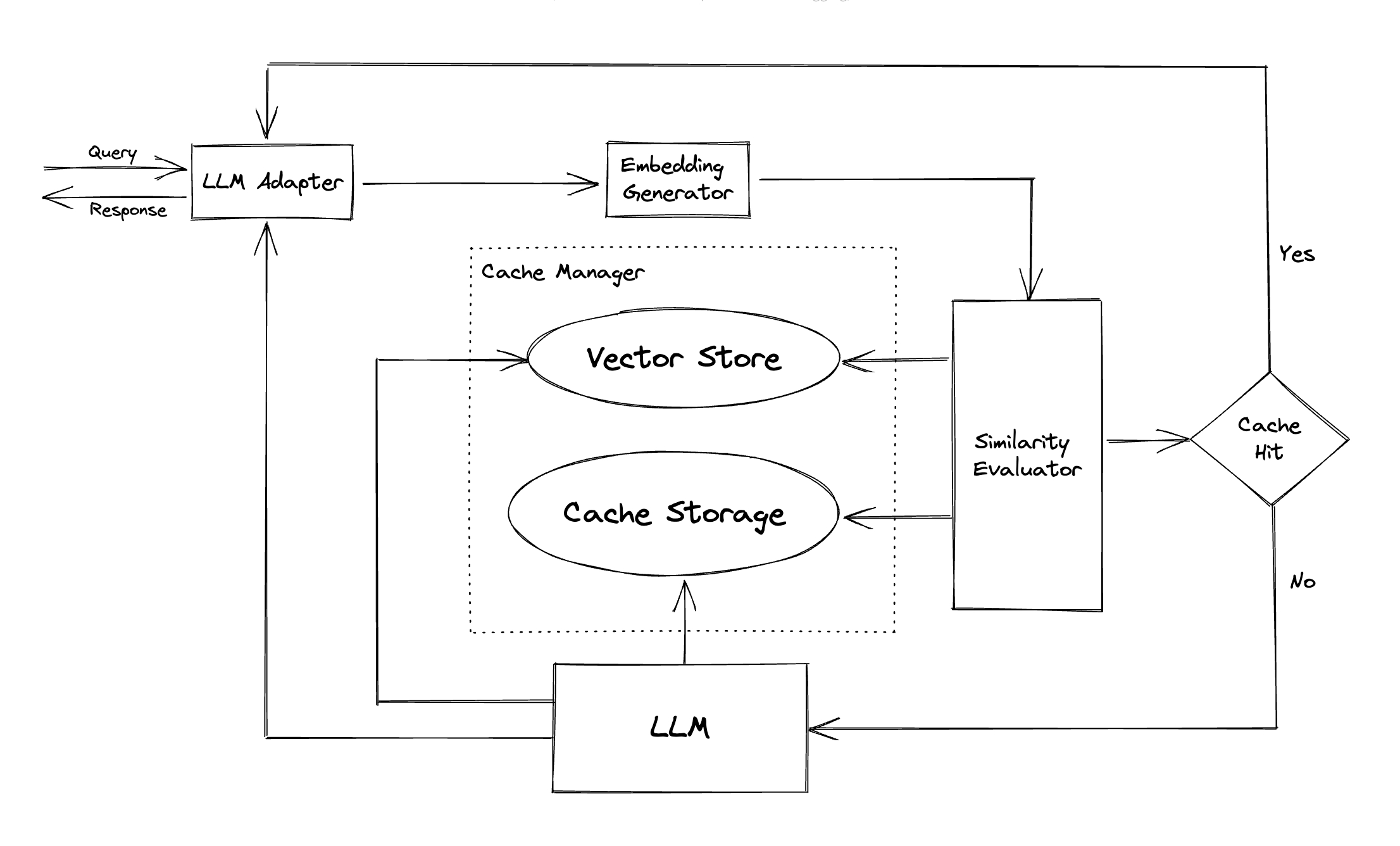
LLMアダプター:LLMアダプターは、APIとリクエストプロトコルを統合することにより、異なるLLMモデルを統合するように設計されています。 GptCacheは、ChatGPT統合を最新のサポートで、この目的のために標準化されたインターフェイスを提供します。
マルチモーダルアダプター(実験) :マルチモーダルアダプターは、APIとリクエストプロトコルを統合することにより、異なる大規模なマルチモーダルモデルを統合するように設計されています。 GPTCacheは、この目的のために標準化されたインターフェイスを提供し、画像生成、オーディオ転写の統合をサポートしています。
埋め込みジェネレーター:このモジュールは、類似性検索のリクエストから埋め込みを抽出するために作成されます。 GptCacheは、複数の埋め込みAPIをサポートする汎用インターフェイスを提供し、選択できるさまざまなソリューションを提供します。
キャッシュストレージ:キャッシュストレージは、ChatGPTなどのLLMSからの応答が保存される場所です。キャッシュされた応答は、類似性の評価を支援するために取得され、良いセマンティックマッチがある場合はリクエスターに返されます。現在、GPTCacheはSQLiteをサポートし、このモジュールを拡張するための普遍的にアクセス可能なインターフェイスを提供しています。
Vector Store : Vector Storeモジュールは、入力要求の抽出された埋め込みから最も類似したリクエストを見つけるのに役立ちます。結果は、類似性を評価するのに役立ちます。 GPTCacheは、Milvus、Zilliz Cloud、FAISSなどのさまざまなベクターストアをサポートするユーザーフレンドリーなインターフェイスを提供します。将来、より多くのオプションが利用可能になります。
キャッシュマネージャー:キャッシュマネージャーは、キャッシュストレージとベクトルストアの両方の動作を制御する責任があります。
cachetoolsを使用して、またはRedisをキー価値ストアとしてRedisを使用して分散型ファッションでメモリで管理できます。現在、GptCacheは、回線の数のみに基づいて、立ち退きについて決定を下しています。このアプローチは、リソース評価が不正確になる可能性があり、メモリ(OOM)エラーを引き起こす可能性があります。私たちは、より洗練された戦略を積極的に調査し、開発しています。
メモリ内キャッシングを使用して、GPTCacheの展開を水平方向にスケーリングする場合、それは不可能です。キャッシュされた情報は単一のポッドに限定されるためです。
分散キャッシュを使用すると、キャッシュ情報がすべてのレプリカで一貫しています。Redisなどの分散キャッシュストアを使用できます。
類似性評価者:このモジュールは、キャッシュストレージとベクトルストアの両方からデータを収集し、さまざまな戦略を使用して、入力要求とベクトルストアからのリクエストの類似性を決定します。この類似性に基づいて、要求がキャッシュと一致するかどうかを決定します。 GPTCacheは、使用する実装のコレクションとともに、さまざまな戦略を統合するための標準化されたインターフェイスを提供します。現在、以下の類似性の定義がサポートされているか、将来サポートされています。
注:異なるモジュールのすべての組み合わせが互いに互換性があるわけではありません。たとえば、埋め込み抽出器を無効にする場合、ベクトルストアは意図したとおりに機能しない場合があります。現在、 GPTCacheのSANITY CHECKの組み合わせの実装に取り組んでいます。
近日公開!乞うご期待!
新機能、強化されたインフラストラクチャ、または改善されたドキュメントなど、貢献に対して非常にオープンです。
貢献方法に関する包括的な指示については、貢献ガイドを参照してください。


