GPTCache
v0.1.44
Slash Your LLM API costos en 10x?, Boost Speed en 100x ⚡
? GPTCACHE se ha integrado completamente con? ️ Langchain! Aquí hay instrucciones de uso detalladas.
? ¡Se ha lanzado la imagen de Docker del servidor GPTCACHE, lo que significa que cualquier idioma podrá usar GPTCACHE!
? Este proyecto está experimentando un desarrollo rápido y, como tal, la API puede estar sujeta a cambios en cualquier momento. Para obtener la información más actualizada, consulte la última nota de documentación y lanzamiento.
Nota: A medida que el número de modelos grandes está creciendo explosivamente y su forma de API evoluciona constantemente, ya no agregamos soporte para nuevas API o modelos. Fomentamos el uso del uso de la API Get and Set en GPTCACHE, aquí está el código de demostración: https://github.com/zilliztech/gptcache/blob/main/examples/adapter/api.py
pip install gptcache
CHATGPT y varios modelos de idiomas grandes (LLMS) cuentan con una increíble versatilidad, lo que permite el desarrollo de una amplia gama de aplicaciones. Sin embargo, a medida que su aplicación crece en popularidad y encuentra niveles de tráfico más altos, los gastos relacionados con las llamadas de API de LLM pueden volverse sustanciales. Además, los servicios de LLM pueden exhibir tiempos de respuesta lentos, especialmente cuando se trata de un número significativo de solicitudes.
Para abordar este desafío, hemos creado GPTCache, un proyecto dedicado a construir un caché semántico para almacenar respuestas LLM.
Nota :
python --versionpython -m pip install --upgrade pip . # clone GPTCache repo
git clone -b dev https://github.com/zilliztech/GPTCache.git
cd GPTCache
# install the repo
pip install -r requirements.txt
python setup.py installEstos ejemplos lo ayudarán a comprender cómo usar una coincidencia exacta y similar con el almacenamiento en caché. También puede ejecutar el ejemplo en Colab. Y más ejemplos puede consultar el bootcamp
Antes de ejecutar el ejemplo, asegúrese de que la variable de entorno OpenAI_API_KEY se establezca ejecutando echo $OPENAI_API_KEY .
Si aún no está configurado, se puede configurar utilizando export OPENAI_API_KEY=YOUR_API_KEY en sistemas UNIX/Linux/MacOS o set OPENAI_API_KEY=YOUR_API_KEY en los sistemas Windows.
Es importante tener en cuenta que este método solo es efectivo temporalmente, por lo que si desea un efecto permanente, deberá modificar el archivo de configuración de la variable de entorno. Por ejemplo, en una Mac, puede modificar el archivo ubicado en
/etc/profile.
import os
import time
import openai
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
question = 'what‘s chatgpt'
# OpenAI API original usage
openai . api_key = os . getenv ( "OPENAI_API_KEY" )
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )Si le hace a ChatGPT exactamente las mismas dos preguntas, la respuesta a la segunda pregunta se obtendrá de la memoria caché sin solicitar a ChatGPT nuevamente.
import time
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
print ( "Cache loading....." )
# To use GPTCache, that's all you need
# -------------------------------------------------
from gptcache import cache
from gptcache . adapter import openai
cache . init ()
cache . set_openai_key ()
# -------------------------------------------------
question = "what's github"
for _ in range ( 2 ):
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )Después de obtener una respuesta de ChatGPT en respuesta a varias preguntas similares, las respuestas a preguntas posteriores se pueden recuperar del caché sin la necesidad de solicitar ChatGPT nuevamente.
import time
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
from gptcache import cache
from gptcache . adapter import openai
from gptcache . embedding import Onnx
from gptcache . manager import CacheBase , VectorBase , get_data_manager
from gptcache . similarity_evaluation . distance import SearchDistanceEvaluation
print ( "Cache loading....." )
onnx = Onnx ()
data_manager = get_data_manager ( CacheBase ( "sqlite" ), VectorBase ( "faiss" , dimension = onnx . dimension ))
cache . init (
embedding_func = onnx . to_embeddings ,
data_manager = data_manager ,
similarity_evaluation = SearchDistanceEvaluation (),
)
cache . set_openai_key ()
questions = [
"what's github" ,
"can you explain what GitHub is" ,
"can you tell me more about GitHub" ,
"what is the purpose of GitHub"
]
for question in questions :
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )Siempre puede pasar un parámetro de temperatura al solicitar el servicio o modelo API.
El rango de
temperaturees [0, 2], el valor predeterminado es 0.0.Una temperatura más alta significa una mayor posibilidad de omitir la búsqueda de caché y solicitar un modelo grande directamente. Cuando la temperatura es 2, saltará el caché y enviará una solicitud al modelo grande directamente con seguridad. Cuando la temperatura es 0, buscará caché antes de solicitar un servicio de modelo grande.
El
post_process_messages_funcpredeterminado estemperature_softmax. En este caso, consulte la referencia de API para aprender sobre cómotemperatureafecta la salida.
import time
from gptcache import cache , Config
from gptcache . manager import manager_factory
from gptcache . embedding import Onnx
from gptcache . processor . post import temperature_softmax
from gptcache . similarity_evaluation . distance import SearchDistanceEvaluation
from gptcache . adapter import openai
cache . set_openai_key ()
onnx = Onnx ()
data_manager = manager_factory ( "sqlite,faiss" , vector_params = { "dimension" : onnx . dimension })
cache . init (
embedding_func = onnx . to_embeddings ,
data_manager = data_manager ,
similarity_evaluation = SearchDistanceEvaluation (),
post_process_messages_func = temperature_softmax
)
# cache.config = Config(similarity_threshold=0.2)
question = "what's github"
for _ in range ( 3 ):
start = time . time ()
response = openai . ChatCompletion . create (
model = "gpt-3.5-turbo" ,
temperature = 1.0 , # Change temperature here
messages = [{
"role" : "user" ,
"content" : question
}],
)
print ( "Time elapsed:" , round ( time . time () - start , 3 ))
print ( "Answer:" , response [ "choices" ][ 0 ][ "message" ][ "content" ])Para usar GPTCACHE exclusivamente, solo se requieren las siguientes líneas de código, y no es necesario modificar ningún código existente.
from gptcache import cache
from gptcache . adapter import openai
cache . init ()
cache . set_openai_key ()Más documentos:
GPTCACHE ofrece los siguientes beneficios principales:
Los servicios en línea a menudo exhiben localidad de datos, con los usuarios que frecuentemente acceden a contenido popular o de tendencia. Los sistemas de caché aprovechan este comportamiento almacenando datos de acceso común, lo que a su vez reduce el tiempo de recuperación de datos, mejora los tiempos de respuesta y facilita la carga de los servidores de backend. Los sistemas de caché tradicionales generalmente utilizan una coincidencia exacta entre una nueva consulta y una consulta en caché para determinar si el contenido solicitado está disponible en el caché antes de obtener los datos.
Sin embargo, el uso de un enfoque de coincidencia exacta para los cachés de LLM es menos efectivo debido a la complejidad y variabilidad de las consultas LLM, lo que resulta en una tasa de golpe de caché baja. Para abordar este problema, GPTCache adopta estrategias alternativas como el almacenamiento en caché semántico. El almacenamiento en caché semántico identifica y almacena consultas similares o relacionadas, aumentando así la probabilidad de golpes de caché y mejorando la eficiencia general del almacenamiento en caché.
GPTCACHE emplea algoritmos de incrustación para convertir consultas en embedidas y utiliza un almacén vectorial para una búsqueda de similitud en estos incrustaciones. Este proceso permite a GPTCACHE identificar y recuperar consultas similares o relacionadas del almacenamiento de caché, como se ilustra en la sección Módulos.
Con un diseño modular, GPTCache facilita a los usuarios personalizar su propio caché semántico. El sistema ofrece varias implementaciones para cada módulo, y los usuarios incluso pueden desarrollar sus propias implementaciones para satisfacer sus necesidades específicas.
En un caché semántico, puede encontrar falsos positivos durante los golpes de caché y falsos negativos durante las fallas de caché. GPTCACHE ofrece tres métricas para medir su rendimiento, que son útiles para que los desarrolladores optimicen sus sistemas de almacenamiento en caché:
Se incluye un punto de referencia de muestra para que los usuarios comiencen a evaluar el rendimiento de su caché semántico.
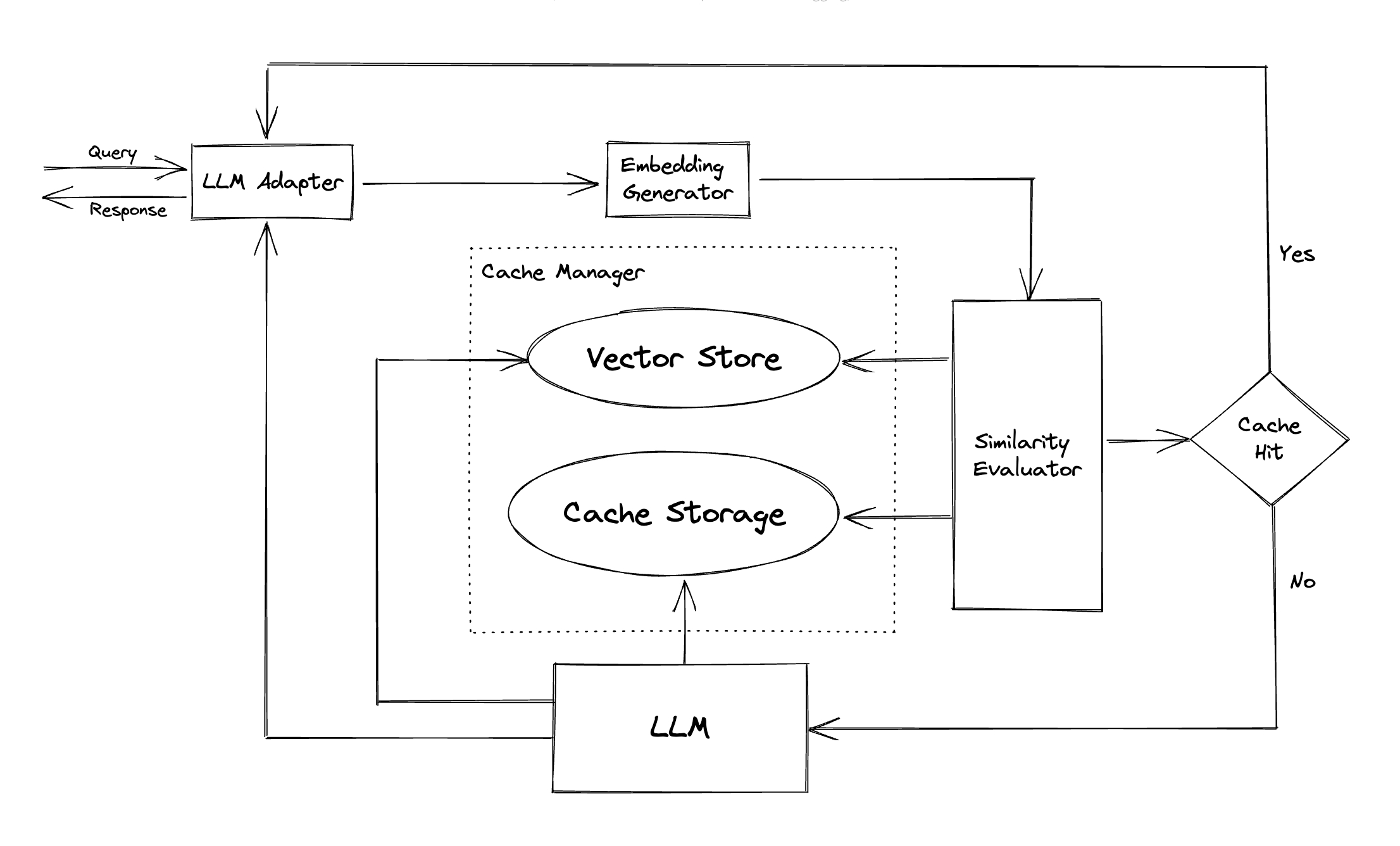
Adaptador LLM : el adaptador LLM está diseñado para integrar diferentes modelos LLM unificando sus API y sus protocolos de solicitud. GPTCACHE ofrece una interfaz estandarizada para este propósito, con soporte actual para la integración de ChatGPT.
Adaptador multimodal (experimental) : el adaptador multimodal está diseñado para integrar diferentes modelos multimodales grandes al unificar sus API y solicitudes de solicitud. GPTCACHE ofrece una interfaz estandarizada para este propósito, con soporte actual para integraciones de generación de imágenes, transcripción de audio.
Generador de incrustación : este módulo se crea para extraer incrustaciones de las solicitudes de búsqueda de similitud. GPTCACHE ofrece una interfaz genérica que admite múltiples API de incrustación y presenta una gama de soluciones para elegir.
Almacenamiento de caché : el almacenamiento de caché es donde se almacena la respuesta de LLMS, como ChatGPT. Las respuestas almacenadas en caché se recuperan para ayudar a evaluar la similitud y se devuelven al solicitante si hay una buena coincidencia semántica. En la actualidad, GPTCache admite SQLite y ofrece una interfaz universalmente accesible para la extensión de este módulo.
Tienda vectorial : el módulo de la tienda Vector ayuda a encontrar las K más similares de la inscripción extraída de la solicitud de entrada. Los resultados pueden ayudar a evaluar la similitud. GPTCACHE proporciona una interfaz fácil de usar que admite varias tiendas vectoriales, incluidas Milvus, Zilliz Cloud y Faiss. Habrá más opciones disponibles en el futuro.
Cache Manager : el Administrador de caché es responsable de controlar el funcionamiento tanto del almacenamiento de caché como de la tienda vectorial .
cachetools de Python o de manera distribuida utilizando Redis como una tienda de valor clave.Actualmente, GPTCache toma decisiones sobre los desalojos basados únicamente en el número de líneas. Este enfoque puede dar lugar a una evaluación de recursos inexacta y puede causar errores fuera de memoria (OOM). Estamos investigando y desarrollando activamente una estrategia más sofisticada.
Si tuviera que escalar su implementación de GPTCACHE horizontalmente utilizando el almacenamiento en caché en memoria, no será posible. Dado que la información en caché se limitaría a la cápsula única.
Con el almacenamiento en caché distribuido, la información de caché consistente en todas las réplicas, podemos usar tiendas de caché distribuidas como Redis.
Evaluador de similitud : este módulo recopila datos tanto del almacenamiento de caché como del almacén vectorial , y utiliza diversas estrategias para determinar la similitud entre la solicitud de entrada y las solicitudes del almacén Vector . Según esta similitud, determina si una solicitud coincide con el caché. GPTCACHE proporciona una interfaz estandarizada para integrar varias estrategias, junto con una colección de implementaciones para usar. Las siguientes definiciones de similitud son compatibles actualmente o serán compatibles en el futuro:
Nota : No todas las combinaciones de diferentes módulos pueden ser compatibles entre sí. Por ejemplo, si deshabilitamos el extractor de incrustación , el almacén vectorial puede no funcionar según lo previsto. Actualmente estamos trabajando en la implementación de una verificación combinada de cordura para GPTCache .
¡Muy pronto! ¡Manténganse al tanto!
Estamos extremadamente abiertos a contribuciones, ya sea a través de nuevas características, infraestructura mejorada o documentación mejorada.
Para obtener instrucciones completas sobre cómo contribuir, consulte nuestra guía de contribución.


