GPTCache
v0.1.44
Setzen Sie Ihre LLM -API -Kosten um 10x?, Steigern Sie die Geschwindigkeit um 100x ⚡
? GPTCache wurde vollständig in? Euen Langchain integriert! Hier sind detaillierte Verwendungsanweisungen.
? Das GPTCache -Server -Docker -Bild wurde veröffentlicht, was bedeutet, dass jede Sprache GPTCache verwenden kann!
? Dieses Projekt wird schnell entwickelt, und als solche kann sich die API jederzeit ändern. Die aktuellsten Informationen finden Sie in der neuesten Dokumentation und Release-Notiz.
Hinweis: Wenn die Anzahl der großen Modelle explosionswachstum wächst und sich ihre API -Form ständig weiterentwickelt, fügen wir keine Unterstützung für neue API oder Modelle mehr hinzu. Wir ermutigen die Verwendung der Nutzung der GET -and -Set -API in GPTCache.
pip install gptcache
ChatGPT und verschiedene große Sprachmodelle (LLMs) bieten eine unglaubliche Vielseitigkeit, die die Entwicklung einer Vielzahl von Anwendungen ermöglicht. Da Ihre Anwendung jedoch immer beliebter wird und höhere Verkehrsniveaus begegnen, können die Ausgaben im Zusammenhang mit LLM -API -Aufrufen erheblich werden. Darüber hinaus können LLM -Dienste langsame Reaktionszeiten aufweisen, insbesondere wenn es sich um eine erhebliche Anzahl von Anfragen handelt.
Um diese Herausforderung zu bewältigen, haben wir GPTCache erstellt, ein Projekt, das sich dem Aufbau eines semantischen Cache für die Speicherung von LLM -Antworten widmet.
Notiz :
python --versionpython -m pip install --upgrade pip . # clone GPTCache repo
git clone -b dev https://github.com/zilliztech/GPTCache.git
cd GPTCache
# install the repo
pip install -r requirements.txt
python setup.py installDiese Beispiele helfen Ihnen dabei, zu verstehen, wie Sie genau und ähnliche Übereinstimmung mit dem Caching verwenden können. Sie können das Beispiel auch auf Colab ausführen. Und weitere Beispiele, die Sie auf den Bootcamp verweisen können
Stellen Sie vor dem Ausführen des Beispiels sicher , dass die Umgebungsvariable openai_api_key durch Ausführung von echo $OPENAI_API_KEY festgelegt wird.
Wenn es nicht bereits festgelegt ist, kann es mit export OPENAI_API_KEY=YOUR_API_KEY auf unix/linux/macos Systems oder set OPENAI_API_KEY=YOUR_API_KEY auf Windows -Systemen eingestellt werden.
Es ist wichtig zu beachten, dass diese Methode nur vorübergehend wirksam ist. Wenn Sie also einen dauerhaften Effekt wünschen, müssen Sie die Konfigurationsdatei der Umgebungsvariablen ändern. Zum Beispiel können Sie auf einem Mac die Datei AT
/etc/profileändern.
import os
import time
import openai
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
question = 'what‘s chatgpt'
# OpenAI API original usage
openai . api_key = os . getenv ( "OPENAI_API_KEY" )
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )Wenn Sie ChatGPT genau die gleichen zwei Fragen stellen, wird die Antwort auf die zweite Frage aus dem Cache erhalten, ohne erneut ChatGPT zu beantragen.
import time
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
print ( "Cache loading....." )
# To use GPTCache, that's all you need
# -------------------------------------------------
from gptcache import cache
from gptcache . adapter import openai
cache . init ()
cache . set_openai_key ()
# -------------------------------------------------
question = "what's github"
for _ in range ( 2 ):
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )Nachdem die Antworten auf nachfolgende Fragen eine Antwort von CHATGPT als Antwort auf mehrere ähnliche Fragen erhalten haben, können die Antworten auf nachfolgende Fragen aus dem Cache abgerufen werden, ohne dass ChatGPT erneut anfordern muss.
import time
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
from gptcache import cache
from gptcache . adapter import openai
from gptcache . embedding import Onnx
from gptcache . manager import CacheBase , VectorBase , get_data_manager
from gptcache . similarity_evaluation . distance import SearchDistanceEvaluation
print ( "Cache loading....." )
onnx = Onnx ()
data_manager = get_data_manager ( CacheBase ( "sqlite" ), VectorBase ( "faiss" , dimension = onnx . dimension ))
cache . init (
embedding_func = onnx . to_embeddings ,
data_manager = data_manager ,
similarity_evaluation = SearchDistanceEvaluation (),
)
cache . set_openai_key ()
questions = [
"what's github" ,
"can you explain what GitHub is" ,
"can you tell me more about GitHub" ,
"what is the purpose of GitHub"
]
for question in questions :
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )Sie können jederzeit einen Temperaturparameter übergeben, während Sie den API -Service oder das Modell anfordern.
Der
temperaturebeträgt [0, 2], der Standardwert 0,0.Eine höhere Temperatur bedeutet eine höhere Möglichkeit, die Cache -Suche zu überspringen und ein großes Modell direkt anzufordern. Wenn die Temperatur 2 ist, überspringt sie Cache und sendet die Anforderung mit Sicherheit direkt an ein großes Modell. Wenn die Temperatur 0 ist, wird Cache durchsucht, bevor er einen großen Modelldienst anfordert.
Der Standard
post_process_messages_funcisttemperature_softmax. In diesem Fall finden Sie in der API -Referenz, um zu erfahren, wie sichtemperatureauswirkt.
import time
from gptcache import cache , Config
from gptcache . manager import manager_factory
from gptcache . embedding import Onnx
from gptcache . processor . post import temperature_softmax
from gptcache . similarity_evaluation . distance import SearchDistanceEvaluation
from gptcache . adapter import openai
cache . set_openai_key ()
onnx = Onnx ()
data_manager = manager_factory ( "sqlite,faiss" , vector_params = { "dimension" : onnx . dimension })
cache . init (
embedding_func = onnx . to_embeddings ,
data_manager = data_manager ,
similarity_evaluation = SearchDistanceEvaluation (),
post_process_messages_func = temperature_softmax
)
# cache.config = Config(similarity_threshold=0.2)
question = "what's github"
for _ in range ( 3 ):
start = time . time ()
response = openai . ChatCompletion . create (
model = "gpt-3.5-turbo" ,
temperature = 1.0 , # Change temperature here
messages = [{
"role" : "user" ,
"content" : question
}],
)
print ( "Time elapsed:" , round ( time . time () - start , 3 ))
print ( "Answer:" , response [ "choices" ][ 0 ][ "message" ][ "content" ])Um GPTCache ausschließlich zu verwenden, sind nur die folgenden Codezeilen erforderlich, und es ist nicht erforderlich, einen vorhandenen Code zu ändern.
from gptcache import cache
from gptcache . adapter import openai
cache . init ()
cache . set_openai_key ()Weitere Dokumente:
GPTCache bietet die folgenden Hauptvorteile:
Online -Dienste zeigen häufig Datenlokalität, wobei Benutzer häufig auf beliebte oder trendige Inhalte zugreifen. Cache -Systeme nutzen dieses Verhalten, indem sie häufig zugegriffene Daten speichern, die wiederum die Datenabnahmezeit verkürzen, die Reaktionszeiten verbessert und die Belastung für Backend -Server erleichtert. Herkömmliche Cache -Systeme verwenden normalerweise eine genaue Übereinstimmung zwischen einer neuen Abfrage und einer zwischengespeicherten Abfrage, um festzustellen, ob der angeforderte Inhalt vor dem Abholen der Daten im Cache verfügbar ist.
Die Verwendung eines exakten Übereinstimmungsansatzes für LLM -Caches ist jedoch aufgrund der Komplexität und Variabilität von LLM -Abfragen weniger effektiv, was zu einer niedrigen Cache -Trefferquote führt. Um dieses Problem anzugehen, übernimmt GPTCache alternative Strategien wie das semantische Caching. Das semantische Caching identifiziert und speichert ähnliche oder verwandte Abfragen, wodurch die Wahrscheinlichkeit der Cache erhöht und die Gesamt -Caching -Effizienz verbessert wird.
GPTCACHE setzt Algorithmen ein, um Abfragen in Einbettungsdings umzuwandeln, und verwendet einen Vektorspeicher zur Ähnlichkeitssuche zu diesen Einbettungen. Dieser Prozess ermöglicht es GPTCache, ähnliche oder verwandte Abfragen aus dem Cache -Speicher zu identifizieren und abzurufen, wie im Abschnitt Module dargestellt.
Mit einem modularen Design erleichtert GPTCache den Benutzern, ihren eigenen semantischen Cache anzupassen. Das System bietet verschiedene Implementierungen für jedes Modul an, und Benutzer können sogar ihre eigenen Implementierungen entwickeln, die ihren spezifischen Anforderungen entsprechen.
In einem semantischen Cache können Sie bei Cache -Hits und falsch negativen Fehlschlägen auf falsch positive Aspekte stoßen. GPTCache bietet drei Metriken, um seine Leistung zu messen, die für Entwickler hilfreich sind, um ihre Caching -Systeme zu optimieren:
Ein Beispiel -Benchmark ist für Benutzer enthalten, um mit der Bewertung der Leistung ihres semantischen Cache zu beginnen.
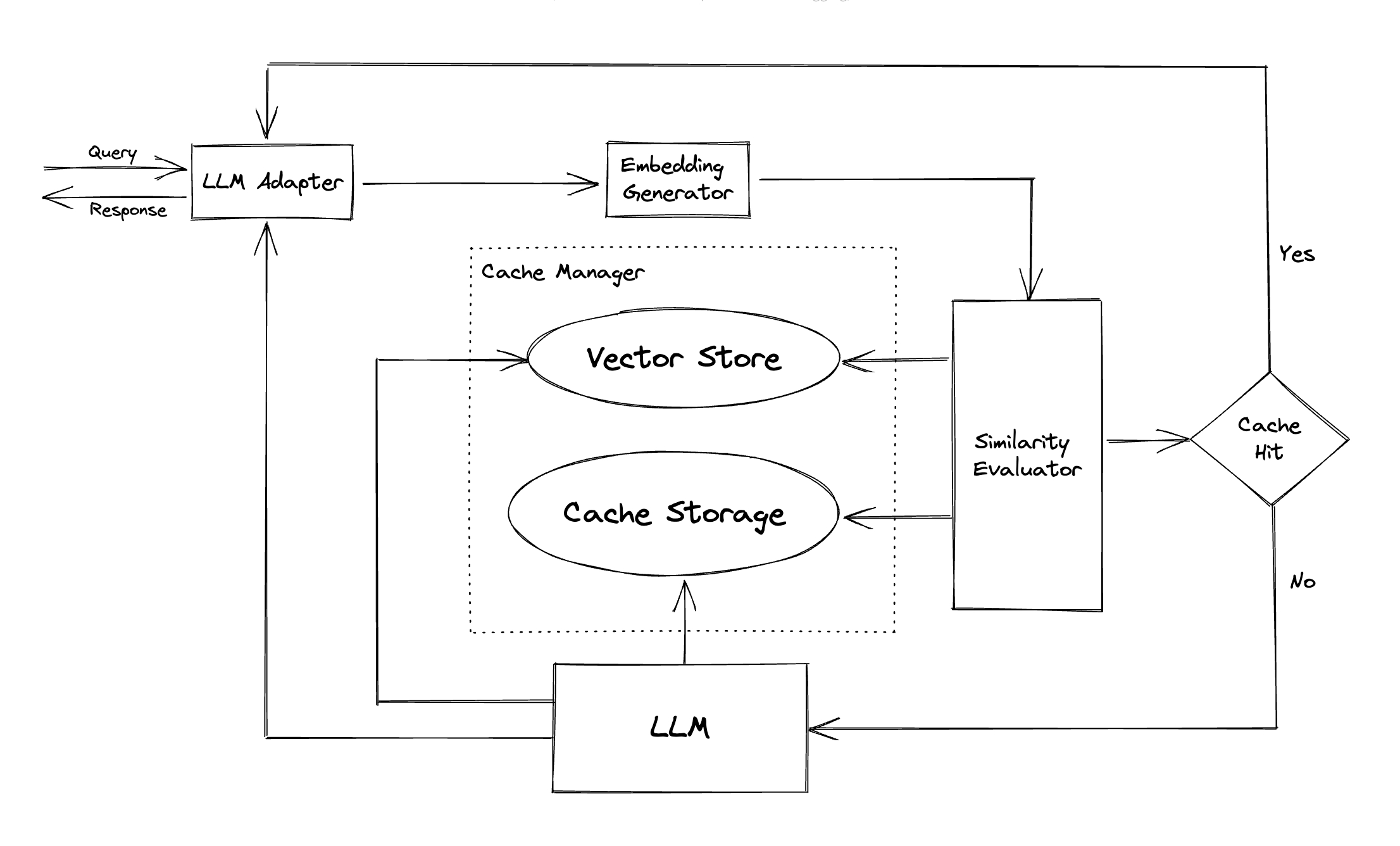
LLM -Adapter : Der LLM -Adapter ist so konzipiert, dass sie verschiedene LLM -Modelle integrieren, indem sie ihre APIs vereinigen und Protokolle anfordern. GPTCache bietet eine standardisierte Schnittstelle zu diesem Zweck mit aktueller Unterstützung für die ChatGPT -Integration.
Multimodaler Adapter (experimentell) : Der multimodale Adapter ist so konzipiert, dass sie verschiedene große multimodale Modelle integrieren, indem sie ihre APIs und die Anfrageprotokolle vereinen. GPTCache bietet eine standardisierte Schnittstelle zu diesem Zweck mit aktueller Unterstützung für Integrationen der Bildgenerierung und Audio -Transkription.
Einbettungsgenerator : Dieses Modul wird erstellt, um Ausbettungen aus Anfragen nach Ähnlichkeitssuche zu extrahieren. GPTCache bietet eine generische Schnittstelle, die mehrere Einbettungs -APIs unterstützt und eine Reihe von Lösungen zur Auswahl darstellt.
Cache -Speicher : Der Cache -Speicher wird in der Antwort von LLMs wie ChatGPT gespeichert. Zwischengespeicherte Antworten sind abgerufen, um die Ähnlichkeit zu bewerten, und werden bei einem guten semantischen Spiel an den Antragsteller zurückgegeben. Derzeit unterstützt GPTCache SQLite und bietet eine allgemein zugängliche Schnittstelle für die Erweiterung dieses Moduls.
Vektorspeicher : Das Vektorspeichermodul hilft dabei, die ähnlichen Anfragen aus der extrahierten Ausbettung der Eingabebestellung zu finden. Die Ergebnisse können dazu beitragen, Ähnlichkeit zu bewerten. GPTCache bietet eine benutzerfreundliche Schnittstelle, die verschiedene Vektorspeicher unterstützt, darunter Milvus, Zilliz Cloud und Faiss. In Zukunft werden weitere Optionen verfügbar sein.
Cache -Manager : Der Cache -Manager ist für die Steuerung des Betriebs des Cache -Speichers und des Vektorspeichers verantwortlich.
cachetools oder verteilt unter Verwendung von Redis als Schlüsselwertgeschäft verwaltet werden.Derzeit trifft GPTCache Entscheidungen über Räumungen, die ausschließlich auf der Anzahl der Linien beruhen. Dieser Ansatz kann zu einer ungenauen Ressourcenbewertung führen und zu Fehlern außerhalb des Memory (OOM) führen. Wir untersuchen und entwickeln aktiv eine ausgefeiltere Strategie.
Wenn Sie Ihre GPTCACHE-Bereitstellung horizontal mit einem In-Memory-Caching skalieren möchten, ist dies nicht möglich. Da die zwischengespeicherten Informationen auf den einzelnen Pod beschränkt sind.
Mit verteiltem Caching können Cache -Informationen, die über alle Repliken konsistent sind, verteilte Cache -Stores wie Redis verwenden.
Ähnlichkeitsbewerter : Dieses Modul sammelt Daten sowohl aus dem Cache -Speicher- als auch aus dem Vektorspeicher und verwendet verschiedene Strategien, um die Ähnlichkeit zwischen der Eingabeanforderung und den Anforderungen aus dem Vektorspeicher zu bestimmen. Basierend auf dieser Ähnlichkeit bestimmt sie, ob eine Anforderung mit dem Cache übereinstimmt. GPTCache bietet eine standardisierte Schnittstelle zur Integration verschiedener Strategien sowie eine Sammlung von Implementierungen. Die folgenden Ähnlichkeitsdefinitionen werden derzeit unterstützt oder in Zukunft unterstützt:
Hinweis : Nicht alle Kombinationen verschiedener Module können miteinander kompatibel sein. Wenn wir beispielsweise den Einbettungs -Extraktor deaktivieren, kann der Vektorspeicher möglicherweise nicht wie beabsichtigt funktionieren. Derzeit arbeiten wir an der Implementierung einer Kombinationsprüfung für GPTCache .
Bald kommen! Bleiben Sie dran!
Wir sind äußerst offen für Beiträge, sei es durch neue Funktionen, eine verbesserte Infrastruktur oder eine verbesserte Dokumentation.
Um umfassende Anweisungen zum Beitrag zu erhalten, finden Sie in unserem Beitragsführer.


