mimic recording studio
v 0.1.1

Mycroft开源模拟技术是文本到语音引擎,它们采用书面文本并将其转换为口语音频。该技术的最新一代模仿2使用机器学习技术来创建一个可以说特定语言的模型,听起来像是对其训练的声音。
模仿录音室简化了来自个人的培训数据的收集,每个人都可以用来为模仿产生独特的声音。
git clone https://github.com/MycroftAI/mimic-recording-studio.gitcd mimic-recording-studiostart-windows.bat为什么要码头?为了使此超级设置并运行跨平台。
git clone https://github.com/MycroftAI/mimic-recording-studio.git
cd mimic-recording-studio
docker-compose up以构建和运行(注意:您可能需要根据您的分配使用sudo docker-compose up )
另外,您可以单独构建和运行。 docker-compose build然后docker-compose up
在您的浏览器中,转到http://localhost:3000
注意: docker-compose up的第一次执行将需要一段时间,因为此命令还将构建Docker容器。随后的docker-compose up的执行应更快地启动。
cd backend/pip install -r requirements.txtpython run.py cd frontend/npm install ,或者yarn installnpm start ,或者yarn start在线,http://mimic.mycroft.ai托管版本需要零设置。
音频作为WAV文件保存到backend/audio_file/{uuid}/ Directory。后端会使用FFMPEG自动修剪所有WAV文件的开始和结束。
元数据也保存到backend/audio_file/{uuid}/ 。该文件将WAV文件名映射到说话的短语。这与WAV文件一起是您开始训练模拟2所需的。
目前,我们有一个英语语料库,可以在backend/prompt/中找到english_corpus.csv 。要使用自己的语料库,请遵循以下步骤。
t )作为定界符,以与english_corpus.csv相同的格式创建一个CSV文件。backend/prompt目录中。docker-compose.yml中的CORPUS环境变量更改为您的语料库名称。 如果您想用英语以外的语言开发语料库,则可以使用模拟录音室来制作其他语言的TTS声音录音。如果您正在用英语以外的语言构建语料库,我们鼓励您选择以下短语:
重要的是:目前,您必须重置sqlite数据库以使用新的语料库。如果您在另一个语料库上录制并想保存该数据,则可以简单地将backend/db/中的sqlite DB重命名为另一个名称。后端将检测到mimicstudio.db不存在,并为您创建一个新的。您可以继续录制新语料库的数据。
Web UI是使用JavaScript构建的,并作为脚手架工具进行了反应和创建反应应用。请参阅CRA.MD,以了解有关如何使用Create-React-App的更多信息。
Web服务是使用Python,Flask作为后端框架,Gunicorn作为HTTP Weberver和SQLite作为数据库构建的。
Docker用于容器化这两个应用程序。默认情况下,前端使用网络端口3000而后端使用网络端口5000 。您可以在docker-compose.yml文件中配置这些。
注意:如果您正在运行docker-registry ,则默认情况下在端口5000上运行,因此您需要更改所使用的端口。
创建声音需要可实现但巨大的努力。一个人需要记录15,000-20,000个短语。为了获得最佳的模仿声音,录音需要保持清洁和一致。为此,请遵循以下建议:
模拟录制局局将在/后端/db/下的SQLite数据库文件中写入所有记录。可以使用DBEAVER等数据库工具打开。
数据库包括两个表。

所有录音都持续在此表中
该数据库可用于查询您的录音。
以下是一些示例查询:
-- List all recordings
SELECT * FROM audiomodel;
-- Lists recordings from january 2020 order by phrase
SELECT * FROM audiomodel WHERE created_date BETWEEN ' 2020-01-01 ' AND ' 2020-01-31 ' ORDER BY prompt;
-- Lists number of recordings per day
SELECT DATE (created_date), COUNT ( * ) AS RecordingsPerDay
FROM audiomodel
GROUP BY DATE (created_date )
ORDER BY DATE (created_date)
-- Shows average text length of recordings
SELECT AVG (LENGTH(prompt)) AS avgLength FROM audiomodel查询SQLITE数据库的方法有很多。例如,在特定时间范围内寻找录音可能有助于删除在不良环境中制作的录音。
使用相同的SQLITE数据库文件可以使用多个扬声器使用模拟记录工作组。
该表提供以下每个发言人的信息:
这些值用于计算指标。例如,与以前的录音相比,语言节奏可能表明录制的短语太快还是缓慢。
查询表“ usermodel”以获取包括uuid在内的扬声器列表以及其中一些记录统计信息。
SELECT user_name AS [name], uuid FROM usermodel;
用于记录您的短语的浏览器持续使用了用户的uuid和localStorage中的name ,以使其与sqlite和filesystem同步。
如果出现问题,并且您的浏览器会在模仿录制局部使用/更改UUID映射,则可能很难继续上一个录制会话。然后在浏览器的localstorage中更新以下两个属性:
在您的浏览器中打开Mimic recording-studio,跳到Web-Developter选项,LocalStorage并将名称和UUID设置为原始值。
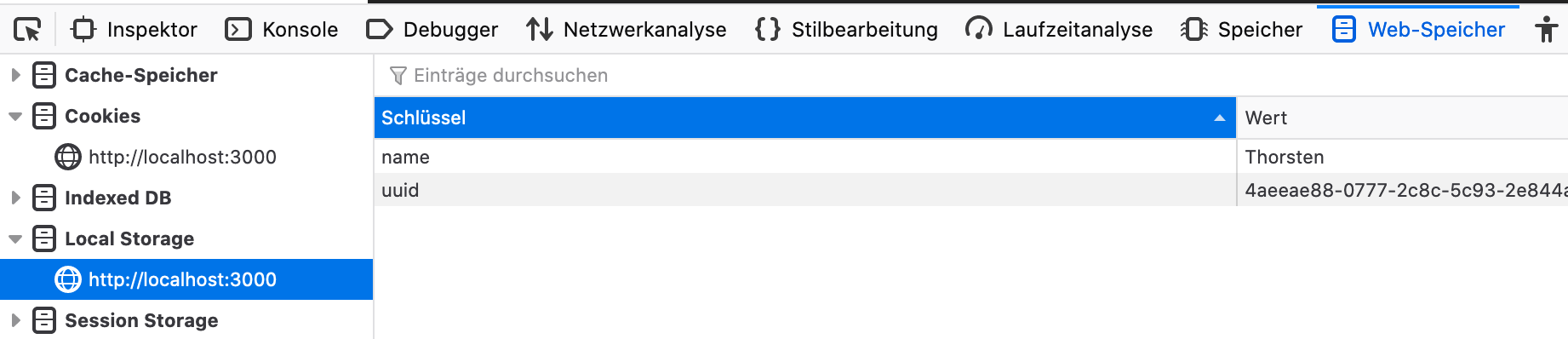
之后,您应该能够在没有进一步问题的情况下继续上一个录制会议。
我们欢迎您向Mycroft捐赠的语音捐赠,以用于文本到语音应用程序。如果您想提供您的语音录音,则必须根据CCC0 CC0公共领域许可证将其许可给我们,以便我们可以在TTS声音中使用它们 - 这是衍生作品。如果您准备捐赠您的语音录音,请发送电子邮件至[email protected]。
公关很高兴被接受!
您可以通过模拟录音室获得帮助和支持;


