mimic recording studio
v 0.1.1

MycroftのオープンソースMimic Technologiesは、書かれたテキストを撮影し、音声オーディオに変換するテキストツースピーチエンジンです。このテクノロジーの最新世代であるMimic 2は、機械学習技術を使用して、特定の言語を話すことができるモデルを作成し、訓練された声のように聞こえます。
Mimic Recording Studioは、個人からのトレーニングデータのコレクションを簡素化します。それぞれを使用して、Mimicの明確な音声を作成できます。
git clone https://github.com/MycroftAI/mimic-recording-studio.gitcd mimic-recording-studiostart-windows.batなぜDocker?これを非常に簡単にセットアップしてクロスプラットフォームを実行できます。
git clone https://github.com/MycroftAI/mimic-recording-studio.git
cd mimic-recording-studio
docker-compose up build and run(注:分布に応じてsudo docker-compose up使用する必要がある場合があります)
または、個別に構築および実行することもできます。 docker-compose build使用してから、 docker-compose up
ブラウザでは、 http://localhost:3000にアクセスしてください
注: docker-compose upの最初の実行には、このコマンドがDockerコンテナも構築するため、しばらく時間がかかります。 docker-compose upのその後の実行は、起動するのが迅速でなければなりません。
cd backend/pip install -r requirements.txtpython run.py cd frontend/npm install 、代わりにyarn installnpm start 、代わりにyarn startオンライン、http://mimic.mycroft.aiホストバージョンはゼロセットアップを必要とします。
オーディオはbackend/audio_file/{uuid}/ディレクトリにWAVファイルとして保存されます。バックエンドは、FFMPEGを使用してすべてのWAVファイルの開始と終了の沈黙を自動的にトリミングします。
メタデータもbackend/audio_file/{uuid}/に保存されます。このファイルは、WAVファイル名を話したフレーズにマッピングします。これは、WAVファイルとともに、Mimic 2のトレーニングを開始するために必要なものです。
今のところ、英語のコーパス、 english_corpus.csvが利用可能になりましたbackend/prompt/独自のコーパスを使用するには、これらの手順に従ってください。
t )を使用して、 english_corpus.csvと同じ形式でCSVファイルを作成します。backend/promptディレクトリに追加します。docker-compose.ymlのCORPUS環境変数をコーパス名に変更します。 英語以外の言語でコーパスを開発したい場合は、模倣レコーディングスタジオを使用して、追加の言語でTTSボイスの音声録音を作成できます。英語以外の言語でコーパスを構築している場合は、次のフレーズを選択することをお勧めします。
重要:今のところ、 sqliteデータベースをリセットして新しいコーパスを使用する必要があります。別のコーパスに記録し、そのデータを保存したい場合は、 backend/db/にあるsqlite DBを別の名前に変更するだけです。バックエンドは、 mimicstudio.dbがそこにないことを検出し、あなたのために新しいものを作成します。新しいコーパスのデータの記録を継続できます。
Web UIは、JavaScriptを使用して構築され、反応および作成反応アプリを足場ツールとして作成します。 CRA.MDを参照して、Create-React-Appの使用方法について詳しく調べてください。
Webサービスは、Python、Flaskをバックエンドフレームワークとして、GunicornをHTTP Webサーバーとして、SQLiteをデータベースとして使用して構築されています。
Dockerは、両方のアプリケーションのコンテナ化に使用されます。デフォルトでは、フロントエンドはネットワークポート3000使用し、バックエンドはネットワークポート5000使用します。これらをdocker-compose.ymlファイルで構成できます。
注: docker-registryを実行している場合、これはポート5000でデフォルトで実行されるため、使用するポートを変更する必要があります。
音声を作成するには、達成可能であるが多大な努力が必要です。個人は15,000〜20,000のフレーズを記録する必要があります。可能な限り最高の模倣音声を得るためには、録音は清潔で一貫性がある必要があります。そのために、次の推奨事項に従ってください。
Mimic-Recording-studioは、/backend/db/の下にあるSQLiteデータベースファイルにすべての録画を書き込みます。これは、dbeaverなどのデータベースツールで開くことができます。
データベースには2つのテーブルが含まれています。

このテーブルでは、すべての録音が持続します
データベースを使用して録音を照会できます。
クエリの例を次に示します。
-- List all recordings
SELECT * FROM audiomodel;
-- Lists recordings from january 2020 order by phrase
SELECT * FROM audiomodel WHERE created_date BETWEEN ' 2020-01-01 ' AND ' 2020-01-31 ' ORDER BY prompt;
-- Lists number of recordings per day
SELECT DATE (created_date), COUNT ( * ) AS RecordingsPerDay
FROM audiomodel
GROUP BY DATE (created_date )
ORDER BY DATE (created_date)
-- Shows average text length of recordings
SELECT AVG (LENGTH(prompt)) AS avgLength FROM audiomodelSQLiteデータベースをクエリすることが役立つかもしれない多くの方法があります。たとえば、特定の時間範囲で録音を探すことは、悪い環境で行われた録音を削除するのに役立つかもしれません。
Mimic-Recording-studioは、同じSQLiteデータベースファイルを使用して複数のスピーカーで使用できます。
このテーブルは、スピーカーごとに次の情報を提供します。
これらの値は、メトリックを計算するために使用されます。たとえば、録音されたフレーズが以前の録音と比較して速すぎるか遅すぎるかどうかを示す場合があります。
クエリテーブル「USERMODEL」では、UUIDを含むスピーカーのリストとそれらに関するいくつかの記録統計を取得します。
SELECT user_name AS [name], uuid FROM usermodel;
フレーズを録画するために使用されるブラウザは、sqliteとファイルシステムと同期し続けるために、ユーザーのuuidとname localStorageに持続させます。
問題が発生し、ブラウザが模倣録音の順にuuidマッピングを失う/変更すると、以前の録音セッションを継続するのが困難になる可能性があります。次に、ブラウザのLocalStorageで次の2つの属性を更新します。
ブラウザで模倣録画のstudioを開き、Webデベロイのオプション、LocalStorage、およびSet name and uuidにジャンプして元の値に合わせます。
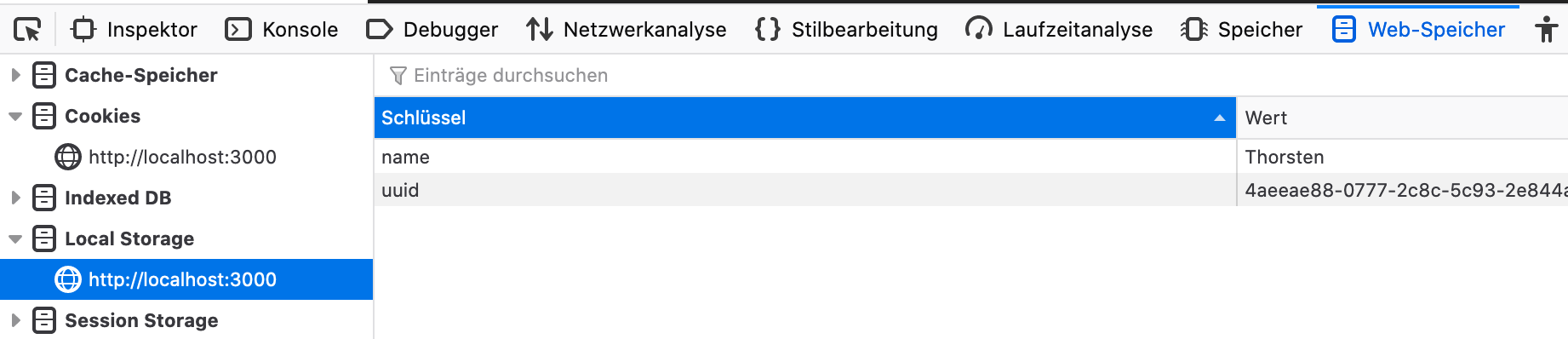
その後、これ以上の問題なく以前の録音セッションを継続できるはずです。
テキストからスピーチのアプリケーションで使用するために、Mycroftへの声の寄付を歓迎します。音声録音を提供したい場合は、Creative Commons CC0パブリックドメインライセンスの下でそれらをライセンスして、TTS Voicesでそれらを利用できるようにする必要があります。音声録音を寄付する準備ができている場合は、[email protected]にメールしてください。
PRは喜んで受け入れられます!
Mimic Recording Studioでヘルプとサポートを得ることができます。


