mimic recording studio
v 0.1.1

As tecnologias Mimic Mimic de código aberto do Mycroft são mecanismos de texto em fala que pegam um texto escrito e o convertem em áudio falado. A última geração dessa tecnologia, Mimic 2, usa técnicas de aprendizado de máquina para criar um modelo que pode falar um idioma específico, parecendo a voz na qual foi treinada.
O Mimic Recording Studio simplifica a coleta de dados de treinamento de indivíduos, cada um dos quais pode ser usado para produzir uma voz distinta para imitar.
git clone https://github.com/MycroftAI/mimic-recording-studio.gitcd mimic-recording-studiostart-windows.batPor que Docker? Para facilitar a configuração e a execução deste super fácil.
git clone https://github.com/MycroftAI/mimic-recording-studio.git
cd mimic-recording-studio
docker-compose up para construir e executar ( NOTA: Pode ser necessário usar sudo docker-compose up dependendo da sua distribuição )
Como alternativa, você pode construir e executar separadamente. docker-compose build e depois docker-compose up
No seu navegador, vá para http://localhost:3000
NOTA: A primeira execução do docker-compose up demorará um pouco, pois esse comando também criará os contêineres do Docker. As execuções subsequentes do docker-compose up devem ser mais rápidas de inicializar.
cd backend/pip install -r requirements.txtpython run.py cd frontend/npm install , alternativamente yarn installnpm start , alternativamente yarn startOnline, http://mimic.mycroft.ai versão hospedada, exigindo uma configuração zero.
O áudio é salvo como arquivos WAV no backend/audio_file/{uuid}/ diretório. O back -end reduz automaticamente o silêncio inicial e final para todos os arquivos WAV usando o FFMPEG.
Os metadados também são salvos no backend/audio_file/{uuid}/ . Este arquivo mapeia o nome do arquivo WAV para a frase falada. Isso, juntamente com os arquivos WAV, é o que você precisou para começar o treinamento Mimic 2.
Por enquanto, temos um corpus inglês, english_corpus.csv disponibilizado, que pode ser encontrado no backend/prompt/ . Para usar seu próprio corpus, siga estas etapas.
english_corpus.csv usando guias ( t ) que o delimitador.backend/prompt .CORPUS no docker-compose.yml para o nome do seu corpus. Se você deseja desenvolver um corpus em um idioma que não seja o inglês, o Mimic Recording Studio pode ser usado para produzir gravações de voz para vozes TTS em idiomas adicionais. Se você está construindo um corpus em um idioma que não seja o inglês, incentivamos você a escolher frases que:
IMPORTANTE: Por enquanto, você deve redefinir o banco de dados sqlite para usar um novo corpus. Se você gravou em outro corpus e gostaria de salvar esses dados, basta renomear seu db sqlite encontrado no backend/db/ em outro nome. O back -end detectará que mimicstudio.db não está lá e criará um novo para você. Você pode continuar registrando dados para o seu novo corpus.
A interface do usuário da web é criada usando JavaScript e reagir e criar-react-app como uma ferramenta de andaimes. Consulte o CRA.MD para saber mais sobre como usar o Create-React-App.
O serviço da web é construído usando Python, Flask como estrutura de back -end, Gunicorn como um servidor da Web HTTP e SQLite como banco de dados.
O Docker é usado para recipiente de ambos os aplicativos. Por padrão, o front -end usa a porta de rede 3000 enquanto o back -end usa a porta 5000 da rede. Você pode configurá-los no arquivo docker-compose.yml .
Nota: Se você estiver executando docker-registry , isso é executado por padrão na porta 5000 , portanto, precisará alterar qual porta usa.
Criar uma voz requer um esforço possível, mas significativo. Um indivíduo precisará registrar 15.000 a 20.000 frases. Para obter a melhor voz imitadora possível, as gravações precisam ser limpas e consistentes. Para esse fim, siga estas recomendações:
O Mimic-Recording-Studio grava todas as gravações em um arquivo de banco de dados SQLite localizado em/back-end/db/. Isso pode ser aberto com ferramentas de banco de dados como o DBeaver.
O banco de dados inclui duas tabelas.

Todas as gravações são persistidas nesta tabela com
O banco de dados pode ser usado para consultar suas gravações.
Aqui estão algumas consultas de exemplo:
-- List all recordings
SELECT * FROM audiomodel;
-- Lists recordings from january 2020 order by phrase
SELECT * FROM audiomodel WHERE created_date BETWEEN ' 2020-01-01 ' AND ' 2020-01-31 ' ORDER BY prompt;
-- Lists number of recordings per day
SELECT DATE (created_date), COUNT ( * ) AS RecordingsPerDay
FROM audiomodel
GROUP BY DATE (created_date )
ORDER BY DATE (created_date)
-- Shows average text length of recordings
SELECT AVG (LENGTH(prompt)) AS avgLength FROM audiomodelHá muitas maneiras de consultar o banco de dados SQLite pode ser útil. Por exemplo, procurar gravações em um intervalo de tempo específico pode ajudar a remover gravações feitas em um ambiente ruim.
O Mimic-Recording-Studio pode ser usado por mais de um alto-falante usando o mesmo arquivo de banco de dados SQLite.
Esta tabelas fornece informações a seguir por orador:
Esses valores são usados para calcular métricas. Por exemplo, o ritmo de falar pode mostrar se a frase gravada for muito rápida ou lenta em comparação com as gravações anteriores.
Tabela de consulta "Usermodel" para obter uma lista de palestrantes, incluindo UUID e algumas estatísticas de gravação sobre eles.
SELECT user_name AS [name], uuid FROM usermodel;
O navegador usado para gravar suas frases persiste os usuários uuid e name em seu local de armazenamento para mantê -lo síncrono com o SQLite e o FileSystem.
Se ocorrer um problema e seu navegador perde/altera o mapeamento UUID para o Mimic-Recording-Studio, você poderá ter dificuldades para continuar uma sessão de gravação anterior. Em seguida, atualize os dois atributos a seguir no LocalSorage do seu navegador:
Open Mimic-Recording-Studio no seu navegador, pule para as opções de desenvolvedor da Web, LocalStorage e Define Name e Uuid para os valores originais.
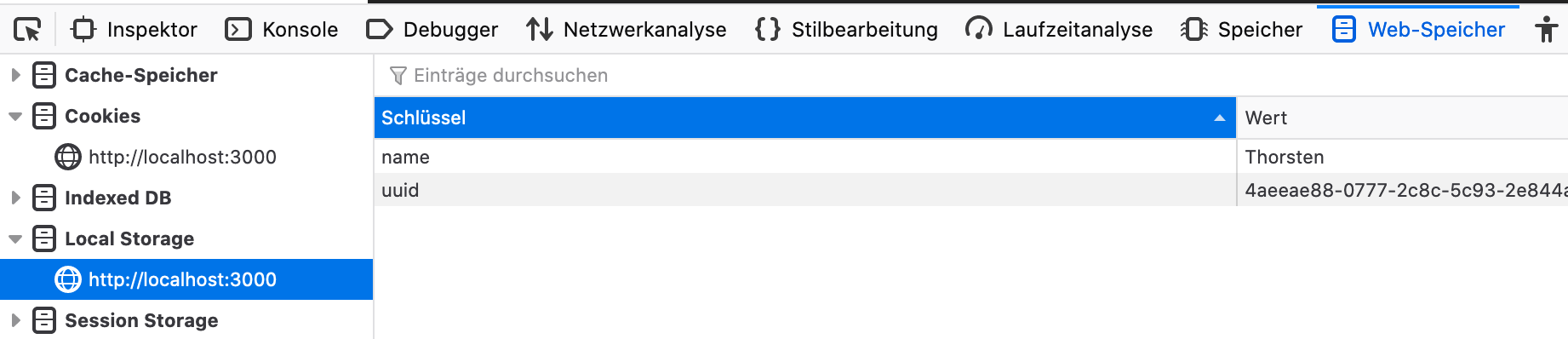
Depois disso, você poderá continuar sua sessão de gravação anterior sem mais problemas.
Congratulamo-nos com suas doações de voz a Mycroft para uso em aplicativos de texto em fala. Se você deseja fornecer suas gravações de voz, deve licenciá -las sob a licença Creative Commons CC0 Public Domain, para que possamos utilizá -las nas vozes do TTS - que são obras derivadas. Se você estiver pronto para doar suas gravações de voz, envie um email para [email protected].
Os PRs são aceitos de bom grado!
Você pode obter ajuda e suporte no Mimic Recording Studio em;


