mimic recording studio
v 0.1.1

Teknologi Mimic Open Source Mycroft adalah mesin teks-ke-pidato yang mengambil sepotong teks tertulis dan mengubahnya menjadi audio lisan. Generasi terbaru dari teknologi ini, Mimic 2, menggunakan teknik pembelajaran mesin untuk membuat model yang dapat berbicara bahasa tertentu, terdengar seperti suara yang dilatih.
Studio perekaman mimik menyederhanakan pengumpulan data pelatihan dari individu, yang masing -masing dapat digunakan untuk menghasilkan suara yang berbeda untuk Mimic.
git clone https://github.com/MycroftAI/mimic-recording-studio.gitcd mimic-recording-studiostart-windows.batMengapa Docker? Untuk membuat ini sangat mudah diatur dan menjalankan platform lintas.
git clone https://github.com/MycroftAI/mimic-recording-studio.git
cd mimic-recording-studio
docker-compose up untuk membangun dan menjalankan ( Catatan: Anda mungkin perlu menggunakan sudo docker-compose up tergantung pada distribusi Anda )
Atau, Anda dapat membangun dan menjalankan secara terpisah. docker-compose build kemudian docker-compose up
Di browser Anda, buka http://localhost:3000
Catatan: Eksekusi pertama dari docker-compose up akan memakan waktu beberapa saat karena perintah ini juga akan membangun wadah Docker. Eksekusi selanjutnya dari docker-compose up harus lebih cepat boot.
cd backend/pip install -r requirements.txtpython run.py cd frontend/npm install , yarn install alternatifnpm start , Alternatif yarn startOnline, http://mimic.mycroft.ai versi host yang membutuhkan pengaturan nol.
Audio disimpan sebagai file wav ke backend/audio_file/{uuid}/ direktori. Backend secara otomatis memangkas keheningan awal dan akhir untuk semua file WAV menggunakan FFMPEG.
Metadata juga disimpan ke backend/audio_file/{uuid}/ . File ini memetakan nama file WAV ke frasa yang diucapkan. Ini bersama dengan file WAV adalah apa yang Anda butuhkan untuk memulai pelatihan Mimic 2.
Untuk saat ini, kami memiliki corpus Inggris, english_corpus.csv tersedia yang dapat ditemukan di backend/prompt/ . Untuk menggunakan corpus Anda sendiri, ikuti langkah -langkah ini.
english_corpus.csv menggunakan tab ( t ) sebagai pembatas.backend/prompt .CORPUS dalam docker-compose.yml ke nama corpus Anda. Jika Anda ingin mengembangkan korpus dalam bahasa selain bahasa Inggris, maka meniru studio perekaman dapat digunakan untuk menghasilkan rekaman suara untuk suara TTS dalam bahasa tambahan. Jika Anda membangun corpus dalam bahasa selain bahasa Inggris, kami mendorong Anda untuk memilih frasa yang:
PENTING: Untuk saat ini, Anda harus mengatur ulang basis data sqlite untuk menggunakan corpus baru. Jika Anda telah merekam pada korpus lain dan ingin menyimpan data itu, Anda dapat mengganti nama sqlite DB Anda yang ditemukan di backend/db/ ke nama lain. Backend akan mendeteksi bahwa mimicstudio.db tidak ada dan membuat yang baru untuk Anda. Anda dapat terus merekam data untuk corpus baru Anda.
Web UI dibangun menggunakan JavaScript dan bereaksi dan membuat reaksi-reaksi sebagai alat perancah. Lihat CRA.MD untuk mengetahui lebih lanjut tentang cara menggunakan Create-React-App.
Layanan Web dibangun menggunakan Python, Flask sebagai kerangka backend, Gunicorn sebagai server web HTTP, dan SQLite sebagai database.
Docker digunakan untuk memuat kedua aplikasi. Secara default, frontend menggunakan port jaringan 3000 sementara backend menggunakan port jaringan 5000 . Anda dapat mengonfigurasi ini di file docker-compose.yml .
Catatan: Jika Anda menjalankan docker-registry , ini berjalan secara default pada port 5000 , jadi Anda perlu mengubah port mana yang Anda gunakan.
Menciptakan suara membutuhkan upaya yang dapat dicapai, tetapi signifikan. Seorang individu perlu merekam 15.000 - 20.000 frasa. Untuk mendapatkan suara mimik terbaik, rekaman harus bersih dan konsisten. Untuk itu, ikuti rekomendasi ini:
Mimic-Recording-Studio menulis semua rekaman dalam file database SQLite yang terletak di bawah/backend/db/. Ini dapat dibuka dengan alat basis data seperti DBeaver.
Basis data mencakup dua tabel.

Semua rekaman tetap ada di tabel ini dengan
Basis data dapat digunakan untuk menanyakan rekaman Anda.
Berikut adalah beberapa contoh pertanyaan:
-- List all recordings
SELECT * FROM audiomodel;
-- Lists recordings from january 2020 order by phrase
SELECT * FROM audiomodel WHERE created_date BETWEEN ' 2020-01-01 ' AND ' 2020-01-31 ' ORDER BY prompt;
-- Lists number of recordings per day
SELECT DATE (created_date), COUNT ( * ) AS RecordingsPerDay
FROM audiomodel
GROUP BY DATE (created_date )
ORDER BY DATE (created_date)
-- Shows average text length of recordings
SELECT AVG (LENGTH(prompt)) AS avgLength FROM audiomodelAda banyak cara yang menanyakan database SQLite mungkin berguna. Misalnya, mencari rekaman dalam rentang waktu tertentu dapat membantu menghapus rekaman yang dibuat di lingkungan yang buruk.
Mimic-Recording-Studio dapat digunakan oleh lebih dari satu speaker menggunakan file database SQLite yang sama.
Tabel ini memberikan informasi berikut per speaker:
Nilai -nilai ini digunakan untuk menghitung metrik. Misalnya, kecepatan berbicara dapat menunjukkan jika frasa yang direkam terlalu cepat atau lambat dibandingkan dengan rekaman sebelumnya.
Tabel kueri "usermodel" untuk mendapatkan daftar pembicara termasuk UUID dan beberapa statistik perekaman pada mereka.
SELECT user_name AS [name], uuid FROM usermodel;
Browser yang digunakan untuk merekam frasa Anda tetap ada pengguna uuid dan name di LocalStorage untuk membuatnya tetap sinkron dengan SQLite dan sistem file.
Jika masalah terjadi dan browser Anda kehilangan/mengubah pemetaan UUID untuk studio perekaman mimik Anda dapat mengalami kesulitan untuk melanjutkan sesi perekaman sebelumnya. Kemudian perbarui dua atribut berikut di LocalStorage di browser Anda:
Buka Mimic-Recording-Studio di browser Anda, lompat ke opsi pengembang web, LocalStorage dan atur nama dan UUID ke nilai asli.
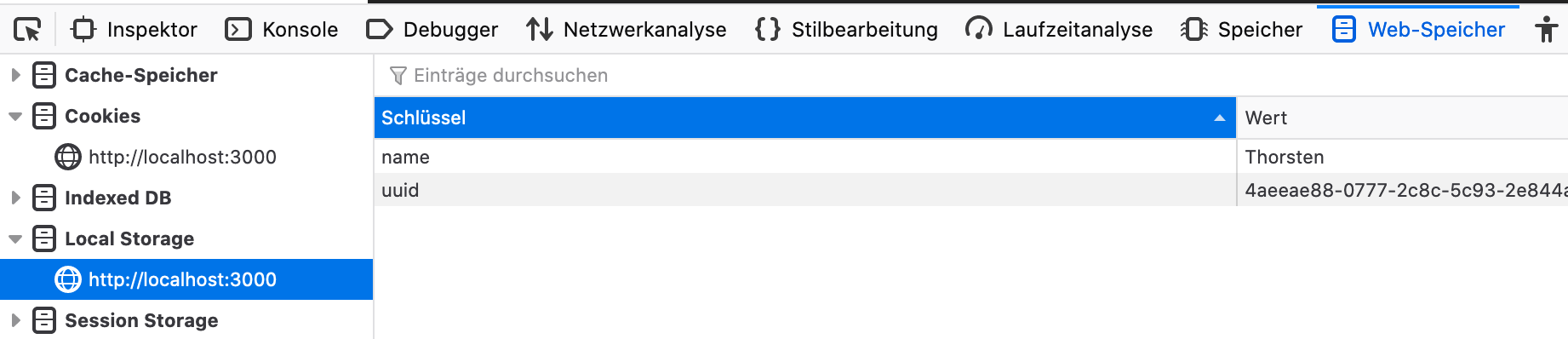
Setelah itu Anda harus dapat melanjutkan sesi perekaman sebelumnya tanpa masalah lebih lanjut.
Kami menyambut donasi suara Anda ke MyCroft untuk digunakan dalam aplikasi teks-ke-pidato. Jika Anda ingin memberikan rekaman suara Anda, Anda harus melisensikannya kepada kami di bawah lisensi domain publik Creative Commons CC0 sehingga kami dapat menggunakannya dalam suara TTS - yang merupakan karya turunan. Jika Anda siap menyumbangkan rekaman suara Anda, email kami di [email protected].
PR diterima dengan senang hati!
Anda bisa mendapatkan bantuan dan dukungan dengan Mimic Recording Studio di;


