mimic recording studio
v 0.1.1

Las tecnologías MIMIC de código abierto de Mycroft son motores de texto a voz que toman un texto escrito y lo convierten en audio hablado. La última generación de esta tecnología, MIMIC 2, utiliza técnicas de aprendizaje automático para crear un modelo que puede hablar un lenguaje específico, que suena como la voz en la que fue entrenada.
El estudio de grabación MIMIC simplifica la recopilación de datos de capacitación de individuos, cada uno de los cuales puede usarse para producir una voz distinta para MIMIC.
git clone https://github.com/MycroftAI/mimic-recording-studio.gitcd mimic-recording-studiostart-windows.bat¿Por qué Docker? Para que esto sea súper fácil de configurar y ejecutar plataformas cruzadas.
git clone https://github.com/MycroftAI/mimic-recording-studio.git
cd mimic-recording-studio
docker-compose up hasta la construcción y ejecución ( nota: es posible que deba usar sudo docker-compose up dependiendo de su distribución )
Alternativamente, puede construir y ejecutar por separado. docker-compose build luego docker-compose up
En su navegador, vaya a http://localhost:3000
Nota: La primera ejecución de docker-compose up llevará un tiempo, ya que este comando también construirá los contenedores Docker. Las ejecuciones posteriores de docker-compose up deben ser más rápidas de arrancar.
cd backend/pip install -r requirements.txtpython run.py cd frontend/npm install , alternativamente yarn installnpm start , alternativamente yarn startEn línea, http://mimic.mycroft.ai Versión alojada que requiere una configuración cero.
El audio se guarda como archivos WAV en el directorio backend/audio_file/{uuid}/ . El backend recorta automáticamente el comienzo y finaliza el silencio para todos los archivos WAV usando FFMPEG.
Los metadatos también se guardan para backend/audio_file/{uuid}/ . Este archivo asigna el nombre del archivo WAV a la frase hablada. Esto junto con los archivos WAV son lo que necesitaba para comenzar en la capacitación MIMIC 2.
Por ahora, tenemos un Corpus en inglés, english_corpus.csv disponible que se puede encontrar en backend/prompt/ . Para usar su propio corpus, siga estos pasos.
english_corpus.csv usando pestañas ( t ) como delimitador.backend/prompt .CORPUS en docker-compose.yml al nombre de su cuerpo. Si desea desarrollar un corpus en un idioma que no sea inglés, entonces MIMIC Recording Studio puede usarse para producir grabaciones de voz para voces TTS en idiomas adicionales. Si está construyendo un corpus en un idioma que no sea inglés, le recomendamos que elija frases que:
IMPORTANTE: Por ahora, debe restablecer la base de datos sqlite para usar un nuevo corpus. Si ha grabado en otro corpus y desea guardar esos datos, simplemente puede cambiar el nombre de su DB sqlite que se encuentra en backend/db/ a otro nombre. El backend detectará que mimicstudio.db no está allí y creará uno nuevo para usted. Puede continuar grabando datos para su nuevo corpus.
La interfaz de usuario web se construye con JavaScript y React y crea a la aplicación como una herramienta de andamio. Consulte Cra.MD para obtener más información sobre cómo usar Create-React-App.
El servicio web se crea con Python, Flask como el marco de backend, Gunicorn como servidor web HTTP y SQLite como base de datos.
Docker se usa para contenedorizar ambas aplicaciones. Por defecto, el frontend usa el puerto de red 3000 mientras que el backend utiliza el puerto de red 5000 . Puede configurarlos en el archivo docker-compose.yml .
Nota: Si está ejecutando docker-registry , esto se ejecuta de forma predeterminada en el puerto 5000 , por lo que deberá cambiar qué puerto usa.
Crear una voz requiere un esfuerzo alcanzable pero significativo. Un individuo necesitará registrar de 15,000 a 20,000 frases. Para obtener la mejor voz de imitación posible, las grabaciones deben ser limpias y consistentes. Con ese fin, siga estas recomendaciones:
MIMIC-Recording-Studio escribe todas las grabaciones en un archivo de base de datos SQLite ubicado en/backend/db/. Esto se puede abrir con herramientas de base de datos como Dbeaver.
La base de datos incluye dos tablas.

Todas las grabaciones se persisten en esta tabla con
La base de datos se puede usar para consultar sus grabaciones.
Aquí hay algunas consultas de ejemplo:
-- List all recordings
SELECT * FROM audiomodel;
-- Lists recordings from january 2020 order by phrase
SELECT * FROM audiomodel WHERE created_date BETWEEN ' 2020-01-01 ' AND ' 2020-01-31 ' ORDER BY prompt;
-- Lists number of recordings per day
SELECT DATE (created_date), COUNT ( * ) AS RecordingsPerDay
FROM audiomodel
GROUP BY DATE (created_date )
ORDER BY DATE (created_date)
-- Shows average text length of recordings
SELECT AVG (LENGTH(prompt)) AS avgLength FROM audiomodelHay muchas maneras en que consultar la base de datos SQLite podría ser útil. Por ejemplo, buscar grabaciones en un rango de tiempo específico podría ayudar a eliminar las grabaciones hechas en un entorno malo.
MIMIC-Recording-Studio puede ser utilizado por más de un altavoz utilizando el mismo archivo de base de datos SQLite.
Estas tablas proporcionan las siguientes información por altavoz:
Estos valores se utilizan para calcular las métricas. Por ejemplo, el ritmo de hablar puede mostrar si la frase grabada es demasiado rápida o lenta en comparación con las grabaciones anteriores.
Tabla de consulta "Usermodel" para obtener una lista de oradores que incluyen UUID y algunas estadísticas de grabación sobre ellos.
SELECT user_name AS [name], uuid FROM usermodel;
El navegador solía grabar sus frases persiste el uuid y name de los usuarios en su almacenamiento local para mantenerlo sincrónico con SQLite y el sistema de archivos.
Si se produce un problema y su navegador pierde/cambia el mapeo de UUID para el estudio de grabación de MIMIC, podría tener dificultades para continuar una sesión de grabación previa. Luego actualice los siguientes dos atributos en LocalStorage de su navegador:
Abra Mimic Recording-Studio en su navegador, salte a las opciones de desarrollador web, LocalStorage y establezca el nombre y UUID a los valores originales.
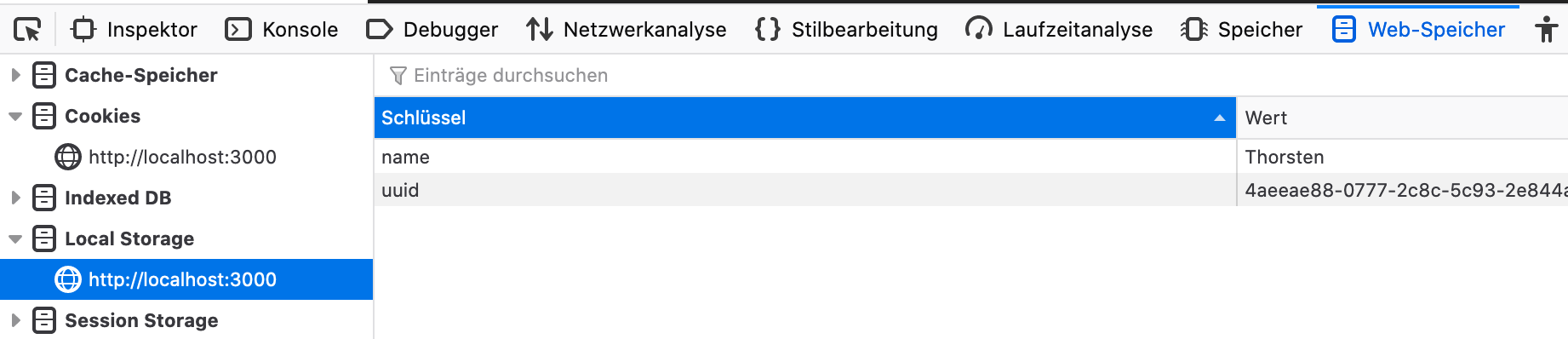
Después de eso, debería poder continuar su sesión de grabación anterior sin más problemas.
Agradecemos sus donaciones de voz a Mycroft para su uso en aplicaciones de texto a voz. Si desea proporcionar sus grabaciones de voz, debe licenciarlas bajo la licencia de dominio público Creative Commons CC0 para que podamos utilizarlas en voces TTS, que son obras derivadas. Si está listo para donar sus grabaciones de voz, envíenos un correo electrónico a [email protected].
¡Las relaciones públicas son con gusto aceptadas!
Puede obtener ayuda y apoyo con Mimic Recording Studio AT;


