torchmetrics
Minor patch release

用于分布式,可扩展的Pytorch应用程序的机器学习指标。
什么是火炬器•实施度量•内置指标•文档•社区•许可证

PYPI的简单安装
pip install torchmetrics使用conda安装
conda install -c conda-forge torchmetrics来自来源的PIP
# with git
pip install git+https://github.com/Lightning-AI/torchmetrics.git@release/stable来自档案的pip
pip install https://github.com/Lightning-AI/torchmetrics/archive/refs/heads/release/stable.zip专门指标的额外依赖性:
pip install torchmetrics[audio]
pip install torchmetrics[image]
pip install torchmetrics[text]
pip install torchmetrics[all] # install all of the above安装最新开发人员版本
pip install https://github.com/Lightning-AI/torchmetrics/archive/master.zipTorchmetrics是100多个Pytorch指标实现的集合和易于使用的API,可创建自定义指标。它提供:
您可以将Torchmetrics与任何Pytorch型号或Pytorch Lightning一起使用,以享受其他功能,例如:
基于模块的指标包含内部度量状态(类似于Pytorch模块的参数),它们可以自动化跨设备的积累和同步!
这可以在CPU,单个GPU或Multi-GPU上运行!
对于单个GPU/CPU案例:
import torch
# import our library
import torchmetrics
# initialize metric
metric = torchmetrics . classification . Accuracy ( task = "multiclass" , num_classes = 5 )
# move the metric to device you want computations to take place
device = "cuda" if torch . cuda . is_available () else "cpu"
metric . to ( device )
n_batches = 10
for i in range ( n_batches ):
# simulate a classification problem
preds = torch . randn ( 10 , 5 ). softmax ( dim = - 1 ). to ( device )
target = torch . randint ( 5 , ( 10 ,)). to ( device )
# metric on current batch
acc = metric ( preds , target )
print ( f"Accuracy on batch { i } : { acc } " )
# metric on all batches using custom accumulation
acc = metric . compute ()
print ( f"Accuracy on all data: { acc } " )使用多个GPU或多个节点时,模块度量使用率保持不变。
import os
import torch
import torch . distributed as dist
import torch . multiprocessing as mp
from torch import nn
from torch . nn . parallel import DistributedDataParallel as DDP
import torchmetrics
def metric_ddp ( rank , world_size ):
os . environ [ "MASTER_ADDR" ] = "localhost"
os . environ [ "MASTER_PORT" ] = "12355"
# create default process group
dist . init_process_group ( "gloo" , rank = rank , world_size = world_size )
# initialize model
metric = torchmetrics . classification . Accuracy ( task = "multiclass" , num_classes = 5 )
# define a model and append your metric to it
# this allows metric states to be placed on correct accelerators when
# .to(device) is called on the model
model = nn . Linear ( 10 , 10 )
model . metric = metric
model = model . to ( rank )
# initialize DDP
model = DDP ( model , device_ids = [ rank ])
n_epochs = 5
# this shows iteration over multiple training epochs
for n in range ( n_epochs ):
# this will be replaced by a DataLoader with a DistributedSampler
n_batches = 10
for i in range ( n_batches ):
# simulate a classification problem
preds = torch . randn ( 10 , 5 ). softmax ( dim = - 1 )
target = torch . randint ( 5 , ( 10 ,))
# metric on current batch
acc = metric ( preds , target )
if rank == 0 : # print only for rank 0
print ( f"Accuracy on batch { i } : { acc } " )
# metric on all batches and all accelerators using custom accumulation
# accuracy is same across both accelerators
acc = metric . compute ()
print ( f"Accuracy on all data: { acc } , accelerator rank: { rank } " )
# Resetting internal state such that metric ready for new data
metric . reset ()
# cleanup
dist . destroy_process_group ()
if __name__ == "__main__" :
world_size = 2 # number of gpus to parallelize over
mp . spawn ( metric_ddp , args = ( world_size ,), nprocs = world_size , join = True )实施自己的指标就像对torch.nn.Module子类别一样容易。 torchmetrics.Metric update compute
import torch
from torchmetrics import Metric
class MyAccuracy ( Metric ):
def __init__ ( self ):
# remember to call super
super (). __init__ ()
# call `self.add_state`for every internal state that is needed for the metrics computations
# dist_reduce_fx indicates the function that should be used to reduce
# state from multiple processes
self . add_state ( "correct" , default = torch . tensor ( 0 ), dist_reduce_fx = "sum" )
self . add_state ( "total" , default = torch . tensor ( 0 ), dist_reduce_fx = "sum" )
def update ( self , preds : torch . Tensor , target : torch . Tensor ) -> None :
# extract predicted class index for computing accuracy
preds = preds . argmax ( dim = - 1 )
assert preds . shape == target . shape
# update metric states
self . correct += torch . sum ( preds == target )
self . total += target . numel ()
def compute ( self ) -> torch . Tensor :
# compute final result
return self . correct . float () / self . total
my_metric = MyAccuracy ()
preds = torch . randn ( 10 , 5 ). softmax ( dim = - 1 )
target = torch . randint ( 5 , ( 10 ,))
print ( my_metric ( preds , target ))与torch.nn类似,大多数指标都具有基于模块的功能版本。功能版本是简单的python函数,当输入带有torch.tensor。
import torch
# import our library
import torchmetrics
# simulate a classification problem
preds = torch . randn ( 10 , 5 ). softmax ( dim = - 1 )
target = torch . randint ( 5 , ( 10 ,))
acc = torchmetrics . functional . classification . multiclass_accuracy (
preds , target , num_classes = 5
)Torchmetrics总共包含100多个指标,其中涵盖以下域:
每个域可能需要一些其他依赖项,这些依赖项可以通过pip install torchmetrics[audio] , pip install torchmetrics['image']等安装。
指标的可视化对于帮助了解机器学习算法的情况很重要。 Torchmetrics具有内置的绘图支持(使用pip install torchmetrics[visual]安装依赖项),几乎通过.plot方法为所有模块化指标。只需调用该方法即可获得任何度量的简单可视化!
import torch
from torchmetrics . classification import MulticlassAccuracy , MulticlassConfusionMatrix
num_classes = 3
# this will generate two distributions that comes more similar as iterations increase
w = torch . randn ( num_classes )
target = lambda it : torch . multinomial (( it * w ). softmax ( dim = - 1 ), 100 , replacement = True )
preds = lambda it : torch . multinomial (( it * w ). softmax ( dim = - 1 ), 100 , replacement = True )
acc = MulticlassAccuracy ( num_classes = num_classes , average = "micro" )
acc_per_class = MulticlassAccuracy ( num_classes = num_classes , average = None )
confmat = MulticlassConfusionMatrix ( num_classes = num_classes )
# plot single value
for i in range ( 5 ):
acc_per_class . update ( preds ( i ), target ( i ))
confmat . update ( preds ( i ), target ( i ))
fig1 , ax1 = acc_per_class . plot ()
fig2 , ax2 = confmat . plot ()
# plot multiple values
values = []
for i in range ( 10 ):
values . append ( acc ( preds ( i ), target ( i )))
fig3 , ax3 = acc . plot ( values )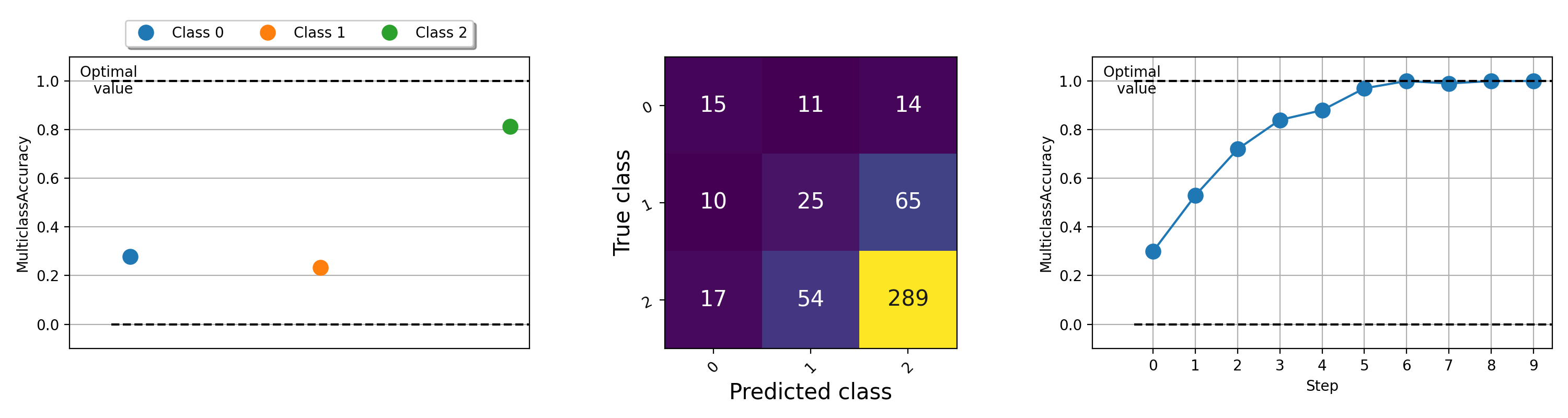
有关绘制不同指标的示例,请尝试运行此示例文件。
Lightning + Torchmetrics团队努力添加更多指标。但是,我们正在寻找像您这样的令人难以置信的贡献者来提交新的指标并改善现有指标!
加入我们的不和谐以获得贡献者的帮助!
如有帮助或疑问,请加入我们的巨大社区不和谐!
我们很高兴能继续坚强的开源软件遗产,并受到Caffe,Theano,Keras,Pytorch,Torchbearer,Ignite,Ignite,Sklearn和Fast.ai的启发。
如果您想引用此框架,请随时使用GitHub的内置引用选项来基于此文件生成Bibtex或APA风格的引用(但前提是您喜欢它?)。
请观察此存储库中列出的Apache 2.0许可证。此外,闪电框架是申请专利。


