torchmetrics
Minor patch release

Metriken für maschinelles Lernen für verteilte, skalierbare Pytorch -Anwendungen.
Was ist TorchMetrics • Implementierung einer Metrik • integrierte Metriken • Dokumente • Community • Lizenz

Einfache Installation von PYPI
pip install torchmetricsMit Conda installieren
conda install -c conda-forge torchmetricsPip aus der Quelle
# with git
pip install git+https://github.com/Lightning-AI/torchmetrics.git@release/stablePip aus dem Archiv
pip install https://github.com/Lightning-AI/torchmetrics/archive/refs/heads/release/stable.zipZusätzliche Abhängigkeiten für spezialisierte Metriken:
pip install torchmetrics[audio]
pip install torchmetrics[image]
pip install torchmetrics[text]
pip install torchmetrics[all] # install all of the aboveInstallieren Sie die neueste Entwicklerversion
pip install https://github.com/Lightning-AI/torchmetrics/archive/master.zipTorchMetrics ist eine Sammlung von mehr als 100 Pytorch-Metriken implementiert und eine benutzerfreundliche API, um benutzerdefinierte Metriken zu erstellen. Es bietet:
Sie können TorchMetrics mit jedem Pytorch -Modell oder mit Pytorch Lightning verwenden, um zusätzliche Funktionen zu genießen, wie z. B.:
Die modulbasierten Metriken enthalten interne metrische Zustände (ähnlich den Parametern des Pytorch-Moduls), die die Akkumulation und Synchronisation über Geräte automatisieren!
Dies kann auf CPU, Single GPU oder Multi-GPUs ausgeführt werden!
Für den einzelnen GPU/CPU -Fall:
import torch
# import our library
import torchmetrics
# initialize metric
metric = torchmetrics . classification . Accuracy ( task = "multiclass" , num_classes = 5 )
# move the metric to device you want computations to take place
device = "cuda" if torch . cuda . is_available () else "cpu"
metric . to ( device )
n_batches = 10
for i in range ( n_batches ):
# simulate a classification problem
preds = torch . randn ( 10 , 5 ). softmax ( dim = - 1 ). to ( device )
target = torch . randint ( 5 , ( 10 ,)). to ( device )
# metric on current batch
acc = metric ( preds , target )
print ( f"Accuracy on batch { i } : { acc } " )
# metric on all batches using custom accumulation
acc = metric . compute ()
print ( f"Accuracy on all data: { acc } " )Die modulmetrische Verwendung bleibt bei Verwendung mehrerer GPUs oder mehrerer Knoten gleich.
import os
import torch
import torch . distributed as dist
import torch . multiprocessing as mp
from torch import nn
from torch . nn . parallel import DistributedDataParallel as DDP
import torchmetrics
def metric_ddp ( rank , world_size ):
os . environ [ "MASTER_ADDR" ] = "localhost"
os . environ [ "MASTER_PORT" ] = "12355"
# create default process group
dist . init_process_group ( "gloo" , rank = rank , world_size = world_size )
# initialize model
metric = torchmetrics . classification . Accuracy ( task = "multiclass" , num_classes = 5 )
# define a model and append your metric to it
# this allows metric states to be placed on correct accelerators when
# .to(device) is called on the model
model = nn . Linear ( 10 , 10 )
model . metric = metric
model = model . to ( rank )
# initialize DDP
model = DDP ( model , device_ids = [ rank ])
n_epochs = 5
# this shows iteration over multiple training epochs
for n in range ( n_epochs ):
# this will be replaced by a DataLoader with a DistributedSampler
n_batches = 10
for i in range ( n_batches ):
# simulate a classification problem
preds = torch . randn ( 10 , 5 ). softmax ( dim = - 1 )
target = torch . randint ( 5 , ( 10 ,))
# metric on current batch
acc = metric ( preds , target )
if rank == 0 : # print only for rank 0
print ( f"Accuracy on batch { i } : { acc } " )
# metric on all batches and all accelerators using custom accumulation
# accuracy is same across both accelerators
acc = metric . compute ()
print ( f"Accuracy on all data: { acc } , accelerator rank: { rank } " )
# Resetting internal state such that metric ready for new data
metric . reset ()
# cleanup
dist . destroy_process_group ()
if __name__ == "__main__" :
world_size = 2 # number of gpus to parallelize over
mp . spawn ( metric_ddp , args = ( world_size ,), nprocs = world_size , join = True ) Die Implementierung Ihrer eigenen Metrik ist so einfach wie die Unterklasse einer torch.nn.Module . Einfach, subklassigen torchmetrics.Metric und einfach die update und compute Methoden implementieren:
import torch
from torchmetrics import Metric
class MyAccuracy ( Metric ):
def __init__ ( self ):
# remember to call super
super (). __init__ ()
# call `self.add_state`for every internal state that is needed for the metrics computations
# dist_reduce_fx indicates the function that should be used to reduce
# state from multiple processes
self . add_state ( "correct" , default = torch . tensor ( 0 ), dist_reduce_fx = "sum" )
self . add_state ( "total" , default = torch . tensor ( 0 ), dist_reduce_fx = "sum" )
def update ( self , preds : torch . Tensor , target : torch . Tensor ) -> None :
# extract predicted class index for computing accuracy
preds = preds . argmax ( dim = - 1 )
assert preds . shape == target . shape
# update metric states
self . correct += torch . sum ( preds == target )
self . total += target . numel ()
def compute ( self ) -> torch . Tensor :
# compute final result
return self . correct . float () / self . total
my_metric = MyAccuracy ()
preds = torch . randn ( 10 , 5 ). softmax ( dim = - 1 )
target = torch . randint ( 5 , ( 10 ,))
print ( my_metric ( preds , target )) Ähnlich wie torch.nn haben die meisten Metriken sowohl eine modulbasierte als auch eine funktionale Version. Die funktionalen Versionen sind einfache Pythonfunktionen, die als Eingabe toler.tensoren nehmen und die entsprechende Metrik als Taschenleiter zurückgeben.
import torch
# import our library
import torchmetrics
# simulate a classification problem
preds = torch . randn ( 10 , 5 ). softmax ( dim = - 1 )
target = torch . randint ( 5 , ( 10 ,))
acc = torchmetrics . functional . classification . multiclass_accuracy (
preds , target , num_classes = 5
)In Total TorchMetrics enthält 100+ Metriken, die die folgenden Domänen abdecken:
Jede Domäne benötigt möglicherweise einige zusätzliche Abhängigkeiten, die mit pip install torchmetrics[audio] , pip install torchmetrics['image'] usw. installiert werden können.
Die Visualisierung von Metriken kann wichtig sein, um zu verstehen, was mit Ihren Algorithmen für maschinelles Lernen vor sich geht. TorchMetrics verfügt über integrierte Plot-Unterstützung (Installieren Sie Abhängigkeiten mit pip install torchmetrics[visual] ) für nahezu alle modularen Metriken über die .plot Methode. Rufen Sie einfach die Methode auf, um eine einfache Visualisierung einer Metrik zu erhalten!
import torch
from torchmetrics . classification import MulticlassAccuracy , MulticlassConfusionMatrix
num_classes = 3
# this will generate two distributions that comes more similar as iterations increase
w = torch . randn ( num_classes )
target = lambda it : torch . multinomial (( it * w ). softmax ( dim = - 1 ), 100 , replacement = True )
preds = lambda it : torch . multinomial (( it * w ). softmax ( dim = - 1 ), 100 , replacement = True )
acc = MulticlassAccuracy ( num_classes = num_classes , average = "micro" )
acc_per_class = MulticlassAccuracy ( num_classes = num_classes , average = None )
confmat = MulticlassConfusionMatrix ( num_classes = num_classes )
# plot single value
for i in range ( 5 ):
acc_per_class . update ( preds ( i ), target ( i ))
confmat . update ( preds ( i ), target ( i ))
fig1 , ax1 = acc_per_class . plot ()
fig2 , ax2 = confmat . plot ()
# plot multiple values
values = []
for i in range ( 10 ):
values . append ( acc ( preds ( i ), target ( i )))
fig3 , ax3 = acc . plot ( values )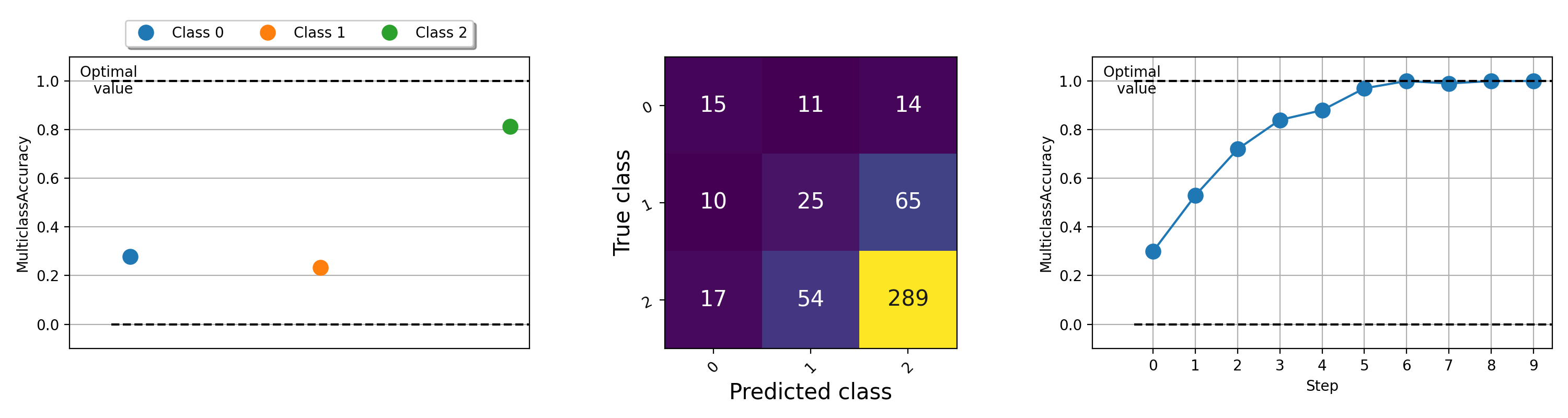
Beispiele für die Darstellung verschiedener Metriken versuchen Sie, diese Beispieldatei auszuführen.
Das Lightning + TorchMetrics -Team ist schwierig, noch mehr Metriken hinzuzufügen. Aber wir suchen nach unglaublichen Mitwirkenden wie Ihnen, um neue Metriken einzureichen und bestehende zu verbessern!
Schließen Sie sich unserer Zwietracht an, um Hilfe beim Mitwirkenden zu erhalten!
Für Hilfe oder Fragen schließen Sie sich unserer riesigen Gemeinschaft auf Zwietracht an!
Wir freuen uns, das starke Erbe der Open -Source -Software fortzusetzen, und haben uns im Laufe der Jahre von Caffe, Theano, Keras, Pytorch, Torchträger, Zündung, Sklearn und Fast.ai.
Wenn Sie dieses Framework zitieren möchten, können Sie die integrierte Zitieroption von Github verwenden, um basierend auf dieser Datei ein Bibtex- oder APA-Zitat zu generieren (aber nur wenn Sie es geliebt haben?).
Bitte beachten Sie die in diesem Repository aufgeführte Apache 2.0 -Lizenz. Darüber hinaus ist das Blitzgerüst ein Patent anhängig.


