spikingjelly
1.0.0
英语| 中文(中文)
Spikingjelly是基于Pytorch的Spiking神经网络(SNN)的开源深度学习框架。
Spikingjelly的文档用英语和中文编写:https://spikingjelly.readthedocs.io。
请注意,Spikingjelly基于Pytorch。在安装Spikingjelly之前,请确保您已经安装了Pytorch。
版本注释
奇数版号是开发版本,使用github/openi存储库更新。均匀版本号是稳定版本,可在PYPI上找到。
默认文档适用于最新的开发版本。如果您使用的是稳定版本,请不要忘记在相应版本中切换到DOC。
从0.0.0.0.14版本中,包括clock_driven和event_driven在内的模块被重命名。请参考从旧版本迁移的教程。
如果您使用旧版本的Spikingjelly,则可能会遇到一些致命的错误。有关更多详细信息,请参阅带有版本的错误历史记录。
不同版本的文档:
从PYPI安装最后一个稳定版本:
pip install spikingjelly从源代码安装最新的开发版本:
来自Github:
git clone https://github.com/fangwei123456/spikingjelly.git
cd spikingjelly
python setup.py install来自Openi:
git clone https://openi.pcl.ac.cn/OpenI/spikingjelly.git
cd spikingjelly
python setup.py installSpikingjelly对用户友好。用Spikingjelly建造SNN就像在Pytorch中建造Ann一样简单:
nn . Sequential (
layer . Flatten (),
layer . Linear ( 28 * 28 , 10 , bias = False ),
neuron . LIFNode ( tau = tau , surrogate_function = surrogate . ATan ())
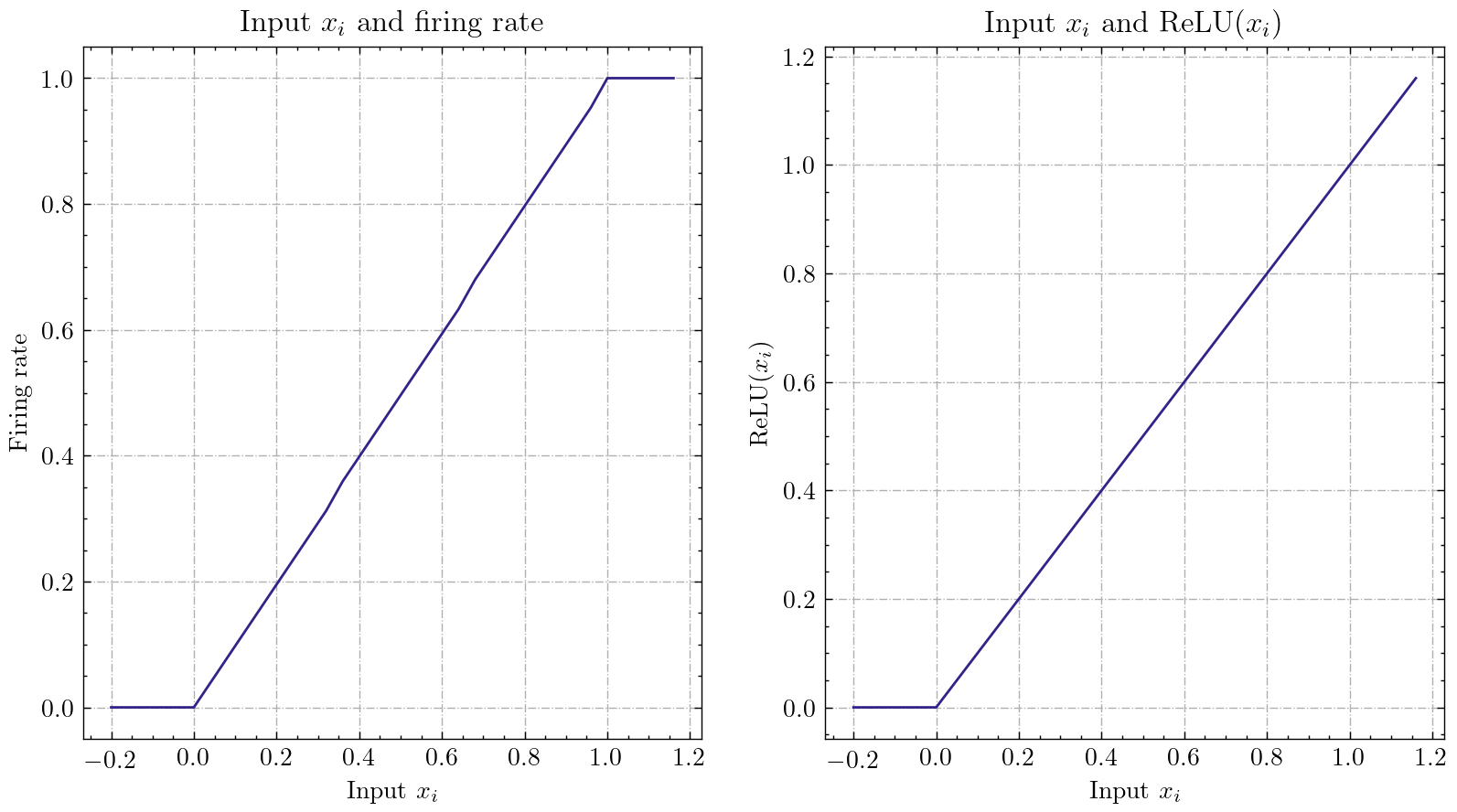
)这个带有泊松编码器的简单网络可以在MNIST测试数据集上实现92%的精度。阅读有关更多详细信息,请参阅教程。您还可以在Python终端中运行此代码,以进行分类的MNIST培训:
python - m spikingjelly . activation_based . examples . lif_fc_mnist - tau 2.0 - T 100 - device cuda : 0 - b 64 - epochs 100 - data - dir < PATH to MNIST > - amp - opt adam - lr 1e-3 - j 8 Spikingjelly实现了相对一般的ANN-SNN转换接口。用户可以通过Pytorch实现转换。此外,用户可以自定义转换模式。
class ANN ( nn . Module ):
def __init__ ( self ):
super (). __init__ ()
self . network = nn . Sequential (
nn . Conv2d ( 1 , 32 , 3 , 1 ),
nn . BatchNorm2d ( 32 , eps = 1e-3 ),
nn . ReLU (),
nn . AvgPool2d ( 2 , 2 ),
nn . Conv2d ( 32 , 32 , 3 , 1 ),
nn . BatchNorm2d ( 32 , eps = 1e-3 ),
nn . ReLU (),
nn . AvgPool2d ( 2 , 2 ),
nn . Conv2d ( 32 , 32 , 3 , 1 ),
nn . BatchNorm2d ( 32 , eps = 1e-3 ),
nn . ReLU (),
nn . AvgPool2d ( 2 , 2 ),
nn . Flatten (),
nn . Linear ( 32 , 10 )
)
def forward ( self , x ):
x = self . network ( x )
return x在MNIST测试数据集上转换后,使用模拟编码的简单网络可以达到98.44%的精度。阅读教程以获取更多详细信息。您还可以在Python终端中运行此代码,以使用转换的模型对MNIST进行分类:
> >> import spikingjelly . activation_based . ann2snn . examples . cnn_mnist as cnn_mnist
> >> cnn_mnist . main ()Spikingjelly为多步神经元提供了两个后端。您可以使用用户友好的torch后端来轻松编码和调试,并使用cupy后端进行更快的训练速度。
下图比较了多步LIF神经元的两个后端的执行时间( float32 ):
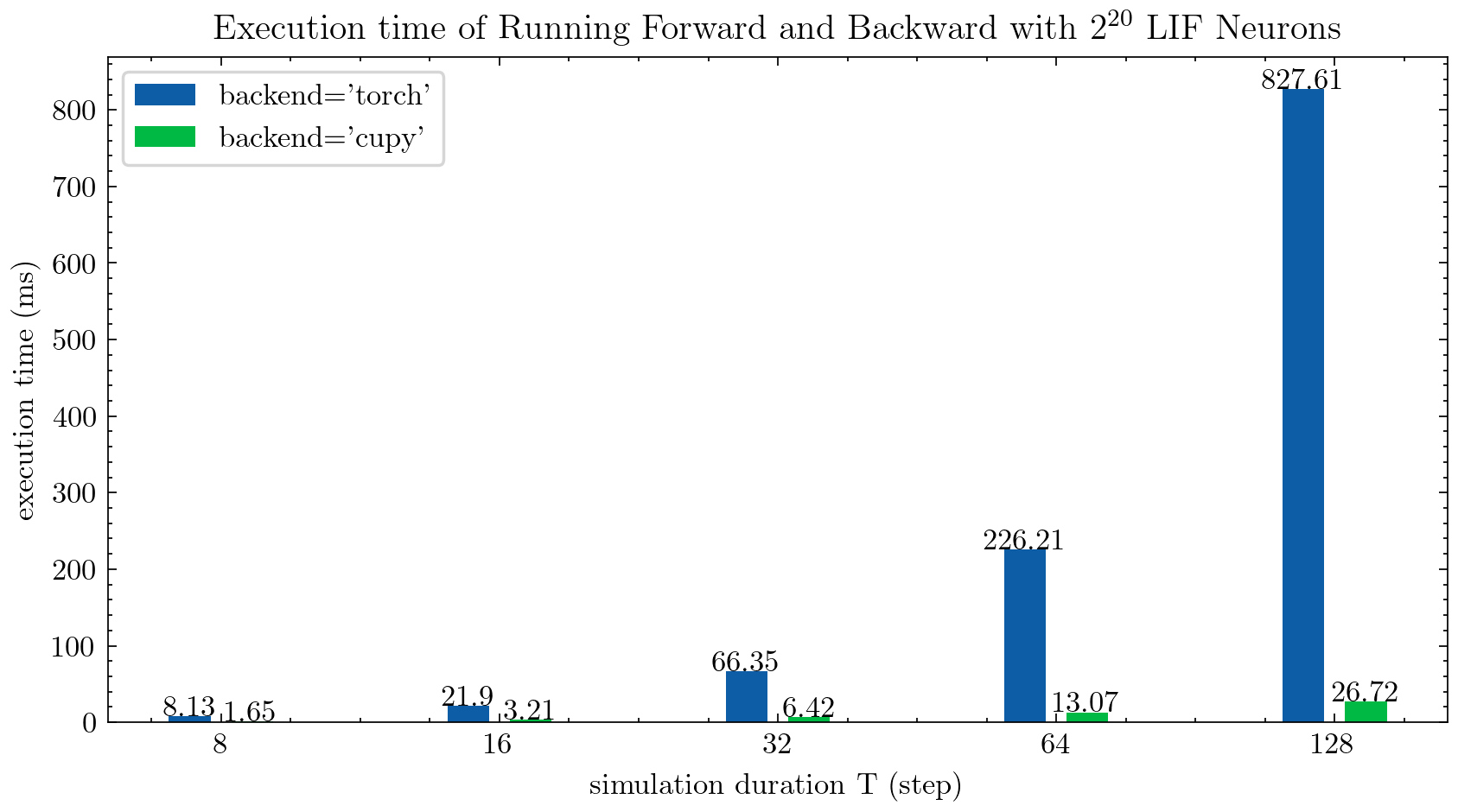
float16还由cupy后端提供,可用于自动混合精确训练。
要使用cupy后端,请安装Cupy。请注意, cupy后端仅支持GPU,而torch后端则支持CPU和GPU。
就像使用pytorch一样简单。
> >> net = nn . Sequential ( layer . Flatten (), layer . Linear ( 28 * 28 , 10 , bias = False ), neuron . LIFNode ( tau = tau ))
> >> net = net . to ( device ) # Can be CPU or CUDA devices Spikingjelly包括以下神经形态数据集:
| 数据集 | 来源 |
|---|---|
| ASL-DVS | 基于图的神经形态视觉传感的对象分类 |
| CIFAR10-DVS | CIFAR10-DVS:用于对象分类的事件流数据集 |
| DVS128手势 | 低功率,完全基于事件的手势识别系统 |
| ES-IMAGENET | ES-IMAGENET:一百万个用于尖峰神经网络的事件流分类数据集 |
| hardvs | HARDVS:通过动态视觉传感器重新审视人类活动识别 |
| N-Caltech101 | 将静态图像数据集转换为使用扫视的神经形态数据集 |
| N-MNIST | 将静态图像数据集转换为使用扫视的神经形态数据集 |
| 导航手势 | 基于事件的手势识别具有智能手机计算功能的动态背景抑制 |
| 尖刺海德堡数字(SHD) | 海德堡尖峰数据集用于尖峰神经网络的系统评估 |
| DVS-LIP | 用于基于事件的唇部阅读的多元格式时空特征感知到的网络 |
用户可以使用Spikingjelly集成的原始事件数据和框架数据:
import torch
from torch . utils . data import DataLoader
from spikingjelly . datasets import pad_sequence_collate , padded_sequence_mask
from spikingjelly . datasets . dvs128_gesture import DVS128Gesture
# Set the root directory for the dataset
root_dir = 'D:/datasets/DVS128Gesture'
# Load event dataset
event_set = DVS128Gesture ( root_dir , train = True , data_type = 'event' )
event , label = event_set [ 0 ]
# Print the keys and their corresponding values in the event data
for k in event . keys ():
print ( k , event [ k ])
# t [80048267 80048277 80048278 ... 85092406 85092538 85092700]
# x [49 55 55 ... 60 85 45]
# y [82 92 92 ... 96 86 90]
# p [1 0 0 ... 1 0 0]
# label 0
# Load a dataset with fixed frame numbers
fixed_frames_number_set = DVS128Gesture ( root_dir , train = True , data_type = 'frame' , frames_number = 20 , split_by = 'number' )
# Randomly select two frames and print their shapes
rand_index = torch . randint ( low = 0 , high = fixed_frames_number_set . __len__ (), size = [ 2 ])
for i in rand_index :
frame , label = fixed_frames_number_set [ i ]
print ( f'frame[ { i } ].shape=[T, C, H, W]= { frame . shape } ' )
# frame[308].shape=[T, C, H, W]=(20, 2, 128, 128)
# frame[453].shape=[T, C, H, W]=(20, 2, 128, 128)
# Load a dataset with a fixed duration and print the shapes of the first 5 samples
fixed_duration_frame_set = DVS128Gesture ( root_dir , data_type = 'frame' , duration = 1000000 , train = True )
for i in range ( 5 ):
x , y = fixed_duration_frame_set [ i ]
print ( f'x[ { i } ].shape=[T, C, H, W]= { x . shape } ' )
# x[0].shape=[T, C, H, W]=(6, 2, 128, 128)
# x[1].shape=[T, C, H, W]=(6, 2, 128, 128)
# x[2].shape=[T, C, H, W]=(5, 2, 128, 128)
# x[3].shape=[T, C, H, W]=(5, 2, 128, 128)
# x[4].shape=[T, C, H, W]=(7, 2, 128, 128)
# Create a data loader for the fixed duration frame dataset and print the shapes and sequence lengths
train_data_loader = DataLoader ( fixed_duration_frame_set , collate_fn = pad_sequence_collate , batch_size = 5 )
for x , y , x_len in train_data_loader :
print ( f'x.shape=[N, T, C, H, W]= { tuple ( x . shape ) } ' )
print ( f'x_len= { x_len } ' )
mask = padded_sequence_mask ( x_len ) # mask.shape = [T, N]
print ( f'mask= n { mask . t (). int () } ' )
break
# x.shape=[N, T, C, H, W]=(5, 7, 2, 128, 128)
# x_len=tensor([6, 6, 5, 5, 7])
# mask=
# tensor([[1, 1, 1, 1, 1, 1, 0],
# [1, 1, 1, 1, 1, 1, 0],
# [1, 1, 1, 1, 1, 0, 0],
# [1, 1, 1, 1, 1, 0, 0],
# [1, 1, 1, 1, 1, 1, 1]], dtype=torch.int32)将来将包含更多数据集。
如果某些数据集的下载链接不适用于某些用户,则用户可以从Openi Mirror下载:
https://openi.pcl.ac.cn/openi/spikingjelly/datasets?type=0
通过其许可证或作者的协议允许所有保存在Openi镜中的数据集。
Spikingjelly提供精心设计的教程。以下是一些教程:
| 数字 | 教程 |
|---|---|
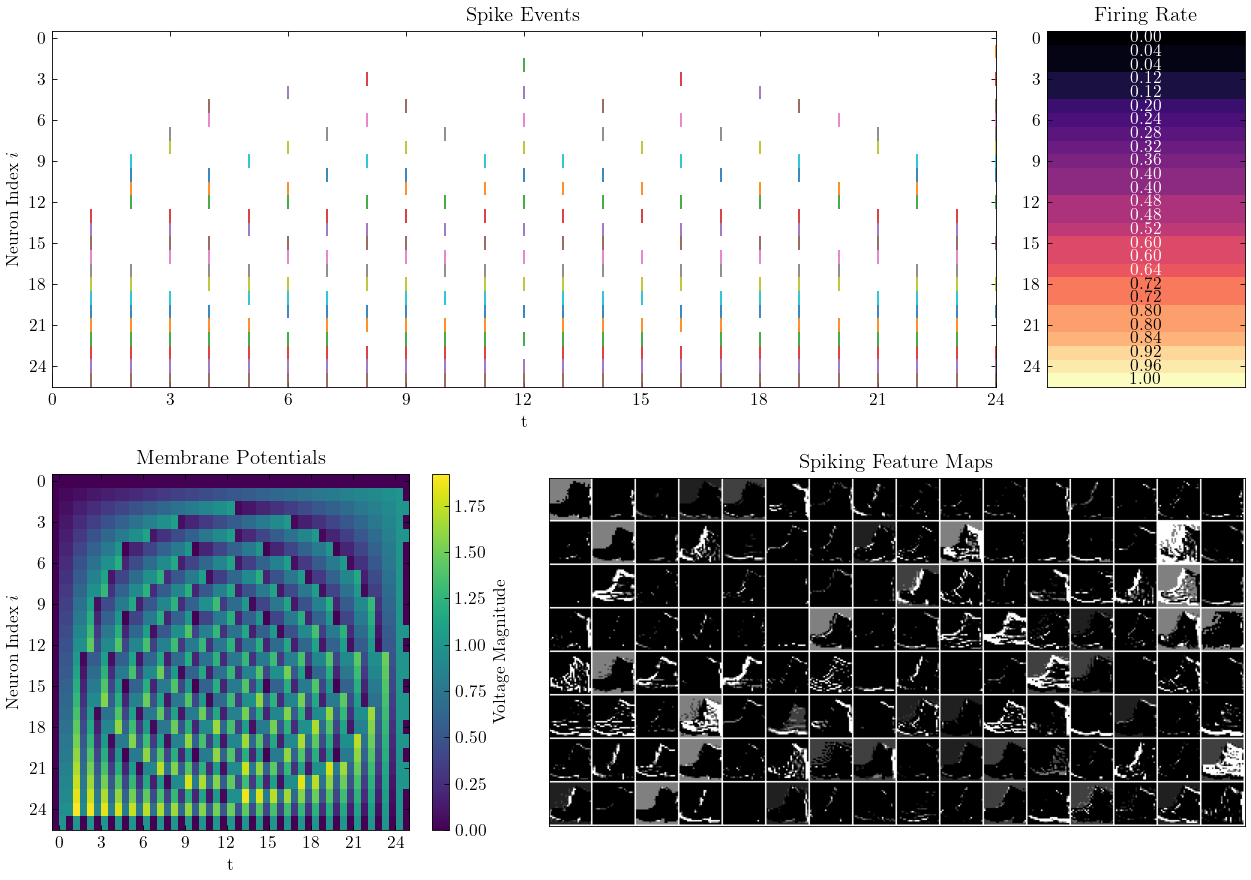
 | 基本概念 |
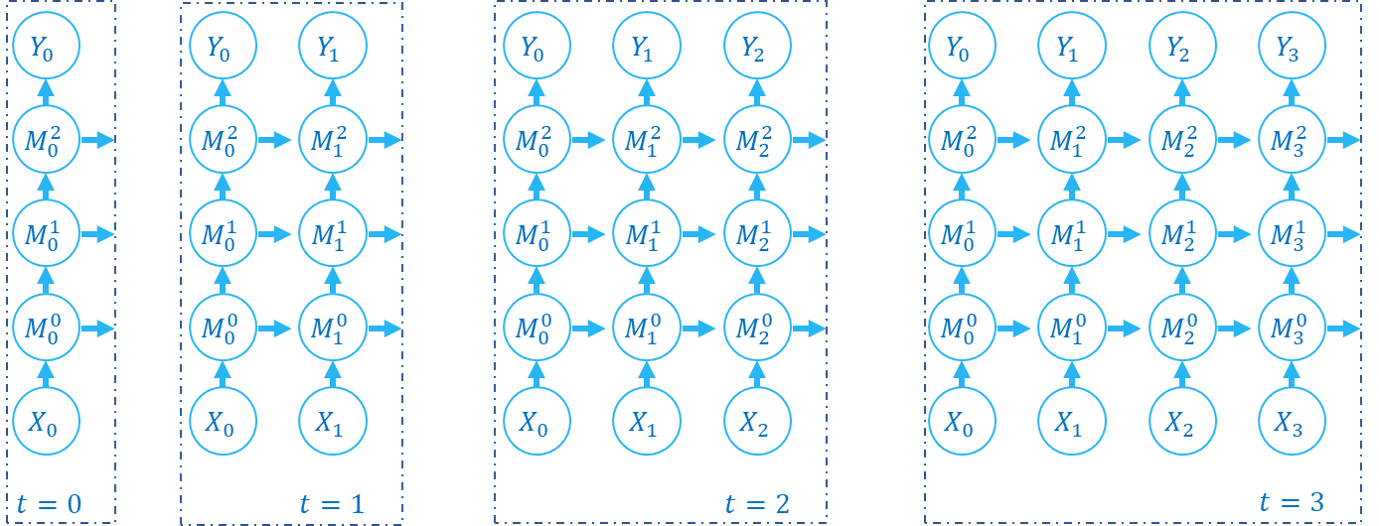
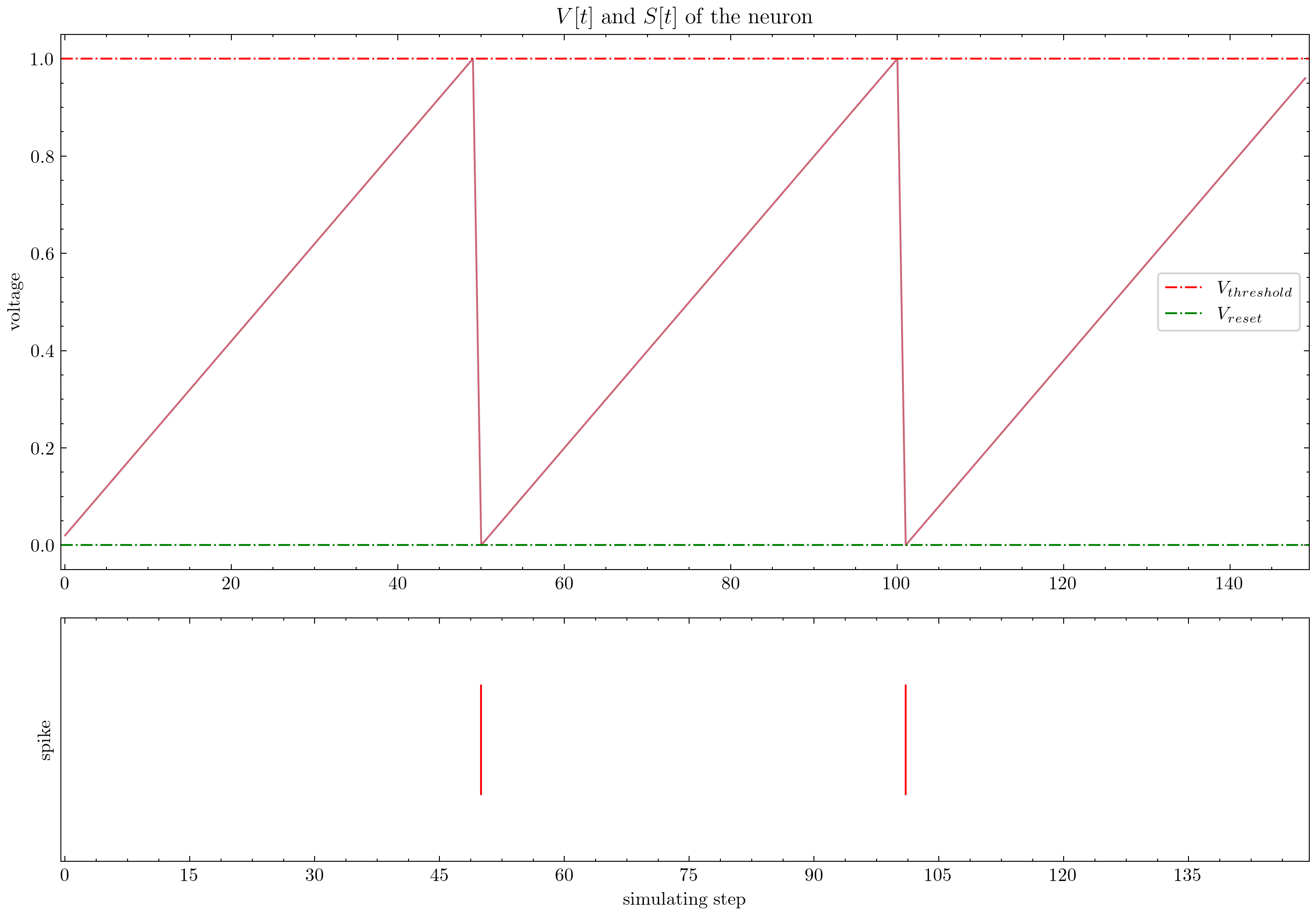 | 神经元 |
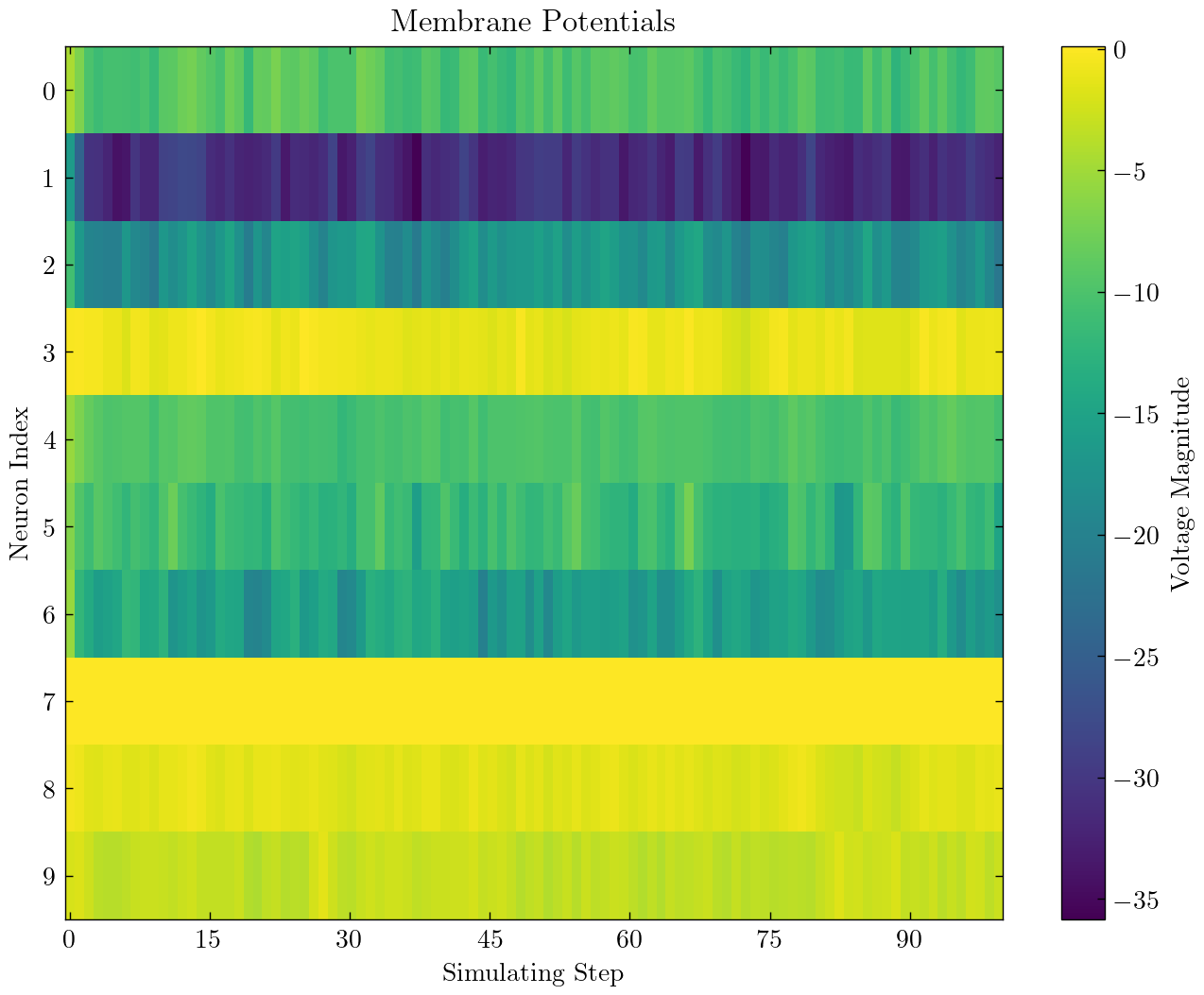 | 单个完全连接的层SNN分类MNIST |
 | 卷积SNN分类fmnist |
 | Ann2snn |
 | 神经形态数据集处理 |
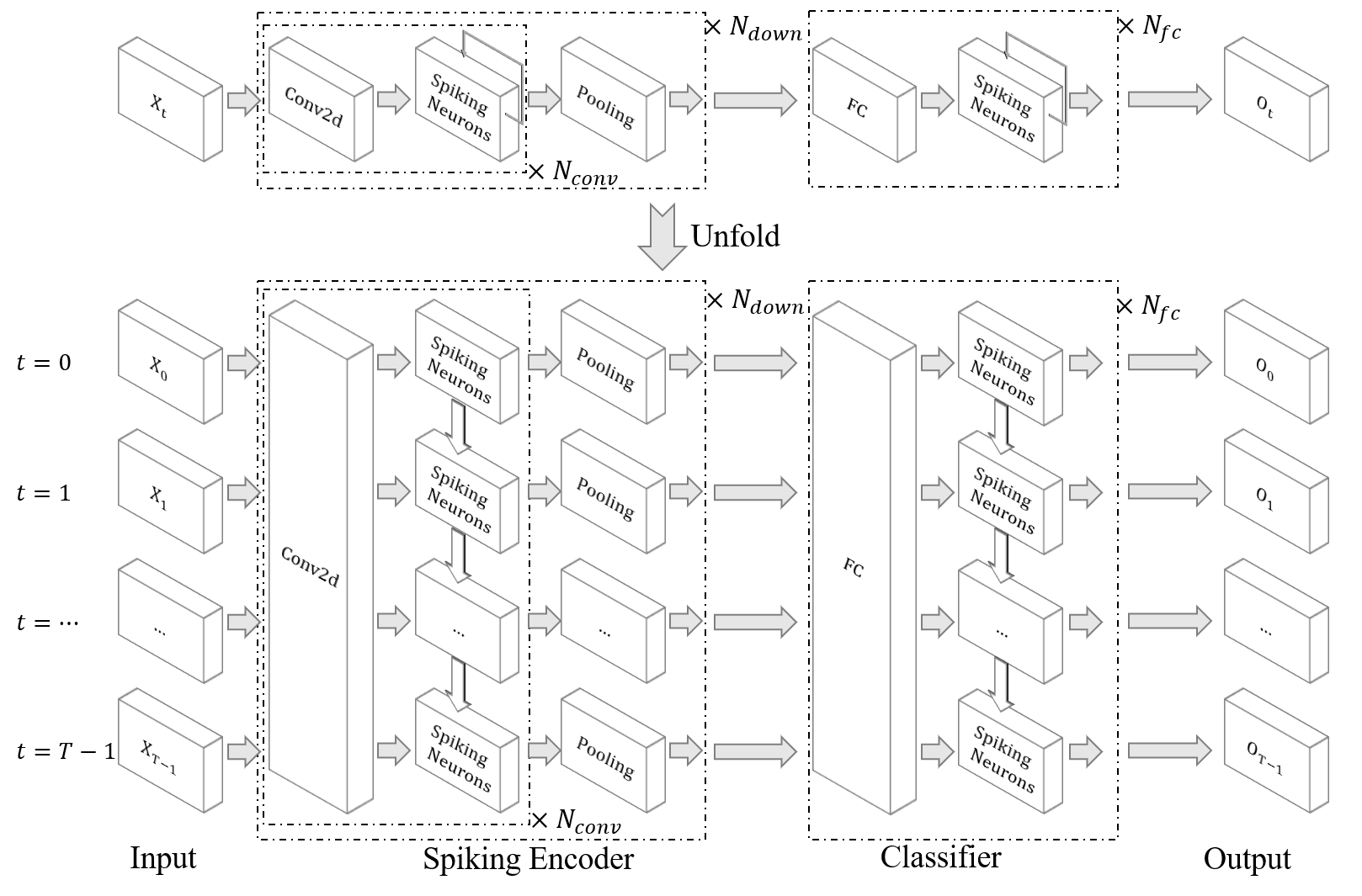 | 对DVS手势进行分类 |
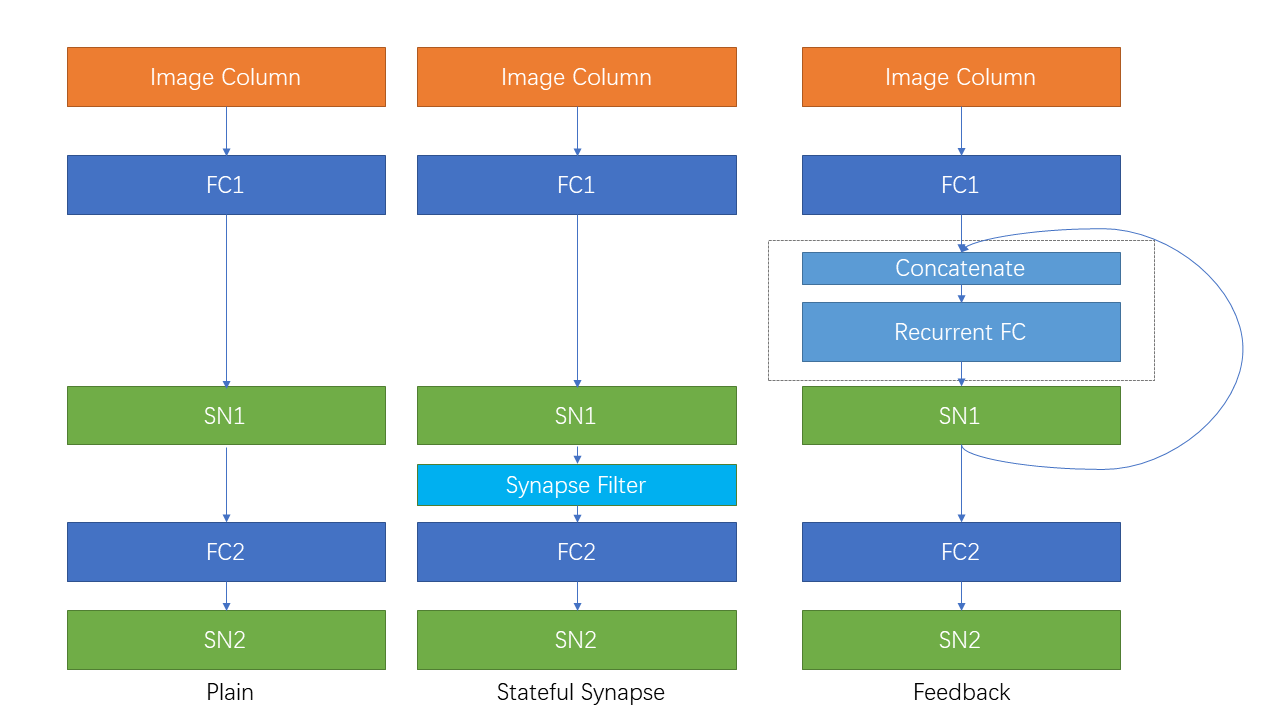 | 经常连接和状态突触 |
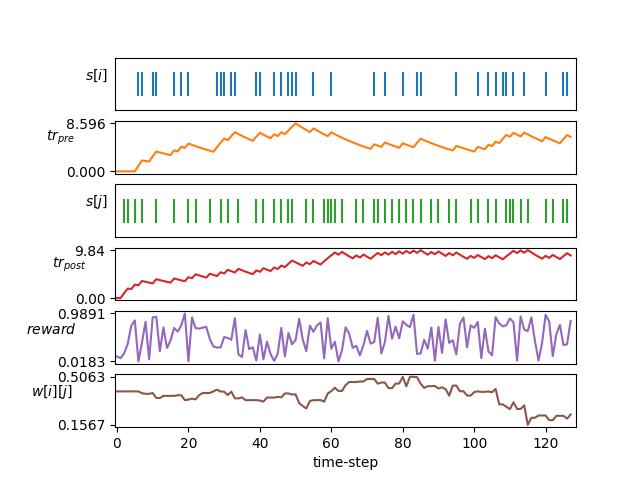 | STDP学习 |
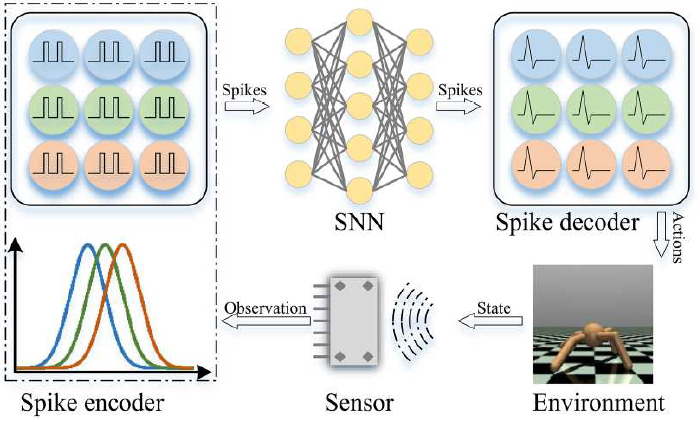 | 强化学习 |
此处未列出的其他教程也可以在文档https://spikingjelly.readthedocs.io上找到。
使用Spikingjelly的出版物记录在出版物中。如果您在纸张中使用Spikingjelly,也可以通过拉请请求将其添加到该表中。
如果您在工作中使用Spikingjelly,请如下引用:
@article{
doi:10.1126/sciadv.adi1480,
author = {Wei Fang and Yanqi Chen and Jianhao Ding and Zhaofei Yu and Timothée Masquelier and Ding Chen and Liwei Huang and Huihui Zhou and Guoqi Li and Yonghong Tian },
title = {SpikingJelly: An open-source machine learning infrastructure platform for spike-based intelligence},
journal = {Science Advances},
volume = {9},
number = {40},
pages = {eadi1480},
year = {2023},
doi = {10.1126/sciadv.adi1480},
URL = {https://www.science.org/doi/abs/10.1126/sciadv.adi1480},
eprint = {https://www.science.org/doi/pdf/10.1126/sciadv.adi1480},
abstract = {Spiking neural networks (SNNs) aim to realize brain-inspired intelligence on neuromorphic chips with high energy efficiency by introducing neural dynamics and spike properties. As the emerging spiking deep learning paradigm attracts increasing interest, traditional programming frameworks cannot meet the demands of automatic differentiation, parallel computation acceleration, and high integration of processing neuromorphic datasets and deployment. In this work, we present the SpikingJelly framework to address the aforementioned dilemma. We contribute a full-stack toolkit for preprocessing neuromorphic datasets, building deep SNNs, optimizing their parameters, and deploying SNNs on neuromorphic chips. Compared to existing methods, the training of deep SNNs can be accelerated 11×, and the superior extensibility and flexibility of SpikingJelly enable users to accelerate custom models at low costs through multilevel inheritance and semiautomatic code generation. SpikingJelly paves the way for synthesizing truly energy-efficient SNN-based machine intelligence systems, which will enrich the ecology of neuromorphic computing. Motivation and introduction of the software framework SpikingJelly for spiking deep learning.}}
您可以阅读问题并获取要解决的问题以及最新的开发计划。我们欢迎所有用户加入开发计划,解决问题并发送拉力请求的讨论。
并非所有的API文档都用英语和中文编写。我们欢迎用户完成翻译(从英语到中文或英语)。
多媒体学习小组,数字媒体研究所(NELVT),北京大学和彭本实验室是Spikingjelly的主要开发商。


可以在此处找到开发人员列表。


