spikingjelly
1.0.0
Inglés | 中文 (chino)
SpikkingJelly es un marco de aprendizaje profundo de código abierto para Spiking Neural Network (SNN) basado en Pytorch.
La documentación de Spikingjelly está escrita en inglés y chino: https://spikejelly.readthedocs.io.
Tenga en cuenta que Spikingjelly se basa en Pytorch. Asegúrese de que haya instalado Pytorch antes de instalar SpikeKJelly.
Notas de versión
El número de versión impar es la versión en desarrollo, actualizada con el repositorio GitHub/Openi. El número de versión par es la versión estable y está disponible en PYPI.
El documento predeterminado es para la última versión en desarrollo. Si está utilizando la versión estable, no olvide cambiar al DOC en la versión correspondiente.
De la versión 0.0.0.0.14 , se renombran los módulos que incluyen clock_driven y event_driven . Consulte el tutorial migrar de versiones antiguas.
Si usa una versión antigua de SpikingJelly, puede encontrar algunos insectos fatales. Consulte el historial de errores con versiones para más detalles.
Documentos para diferentes versiones:
Instale la última versión estable desde PYPI :
pip install spikingjellyInstale la última versión en desarrollo del código fuente :
De Github:
git clone https://github.com/fangwei123456/spikingjelly.git
cd spikingjelly
python setup.py installDesde Openi:
git clone https://openi.pcl.ac.cn/OpenI/spikingjelly.git
cd spikingjelly
python setup.py installSpikingjelly es fácil de usar. Construir SNN con Spikingjelly es tan simple como construir Ann en Pytorch:
nn . Sequential (
layer . Flatten (),
layer . Linear ( 28 * 28 , 10 , bias = False ),
neuron . LIFNode ( tau = tau , surrogate_function = surrogate . ATan ())
)Esta red simple con un codificador de Poisson puede lograr una precisión del 92% en el conjunto de datos de prueba MNIST. Lea Consulte el tutorial para obtener más detalles. También puede ejecutar este código en una terminal de Python para entrenar en la clasificación de MNIST:
python - m spikingjelly . activation_based . examples . lif_fc_mnist - tau 2.0 - T 100 - device cuda : 0 - b 64 - epochs 100 - data - dir < PATH to MNIST > - amp - opt adam - lr 1e-3 - j 8 Spikingjelly implementa una interfaz de conversión ANN-SNN relativamente general. Los usuarios pueden realizar la conversión a través de Pytorch. Además, los usuarios pueden personalizar el modo de conversión.
class ANN ( nn . Module ):
def __init__ ( self ):
super (). __init__ ()
self . network = nn . Sequential (
nn . Conv2d ( 1 , 32 , 3 , 1 ),
nn . BatchNorm2d ( 32 , eps = 1e-3 ),
nn . ReLU (),
nn . AvgPool2d ( 2 , 2 ),
nn . Conv2d ( 32 , 32 , 3 , 1 ),
nn . BatchNorm2d ( 32 , eps = 1e-3 ),
nn . ReLU (),
nn . AvgPool2d ( 2 , 2 ),
nn . Conv2d ( 32 , 32 , 3 , 1 ),
nn . BatchNorm2d ( 32 , eps = 1e-3 ),
nn . ReLU (),
nn . AvgPool2d ( 2 , 2 ),
nn . Flatten (),
nn . Linear ( 32 , 10 )
)
def forward ( self , x ):
x = self . network ( x )
return xEsta red simple con codificación analógica puede lograr una precisión del 98.44% después de la conversión en el conjunto de datos de prueba MNIST. Lea el tutorial para obtener más detalles. También puede ejecutar este código en una terminal de Python para entrenar en la clasificación de MNIST utilizando el modelo convertido:
> >> import spikingjelly . activation_based . ann2snn . examples . cnn_mnist as cnn_mnist
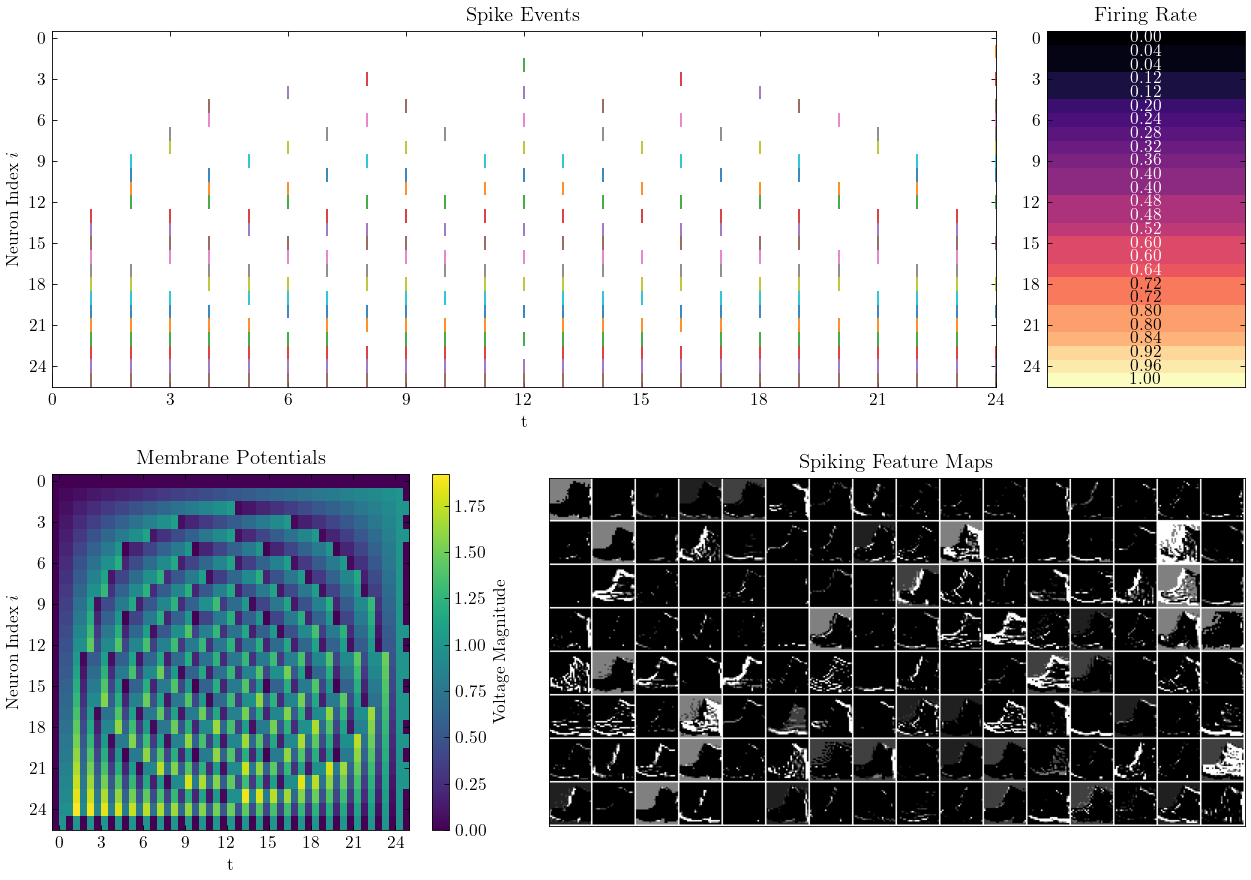
> >> cnn_mnist . main () Spikingjelly proporciona dos backends para neuronas de varios pasos. Puede usar el backend torch fácil de usar para codificar y depurar fácilmente y usar Backend cupy para una velocidad de entrenamiento más rápida.
La siguiente figura compara el tiempo de ejecución de dos backends de las neuronas LIF de múltiples pasos ( float32 ):
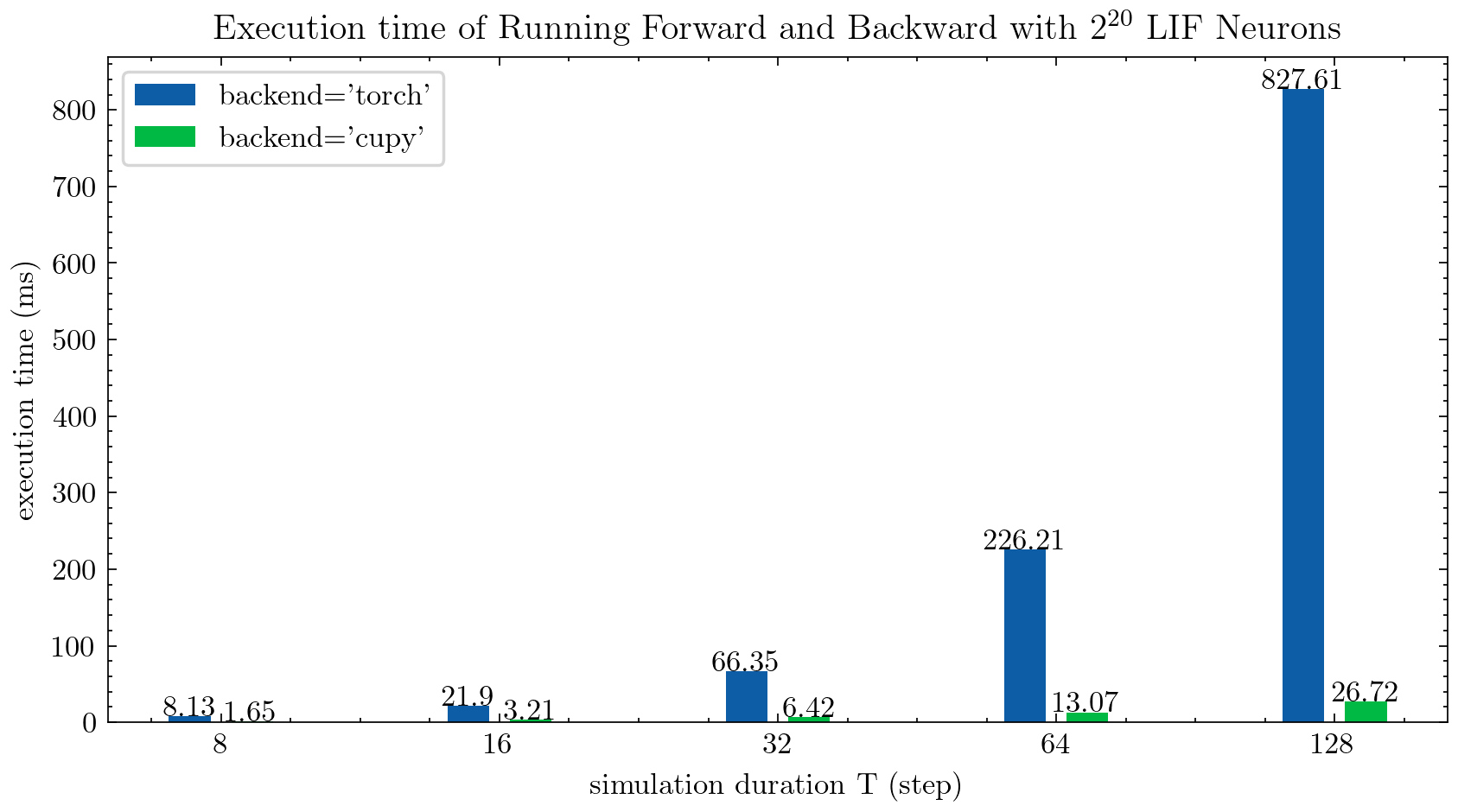
float16 también es proporcionado por el backend cupy y puede usarse en entrenamiento automático de precisión mixta.
Para usar el backend cupy , instale Cupy. Tenga en cuenta que el backend cupy solo admite GPU, mientras que el backend torch admite CPU y GPU.
Tan simple como usar pytorch.
> >> net = nn . Sequential ( layer . Flatten (), layer . Linear ( 28 * 28 , 10 , bias = False ), neuron . LIFNode ( tau = tau ))
> >> net = net . to ( device ) # Can be CPU or CUDA devices SpikingJelly incluye los siguientes conjuntos de datos neuromórficos:
| Conjunto de datos | Fuente |
|---|---|
| ASL-DVS | Clasificación de objetos basados en gráficos para la detección de la visión neuromórfica |
| CIFAR10-DVS | CIFAR10-DVS: un conjunto de datos de transmisión de eventos para la clasificación de objetos |
| Gesto DVS128 | Un sistema de reconocimiento de gestos de baja potencia y totalmente basado en eventos |
| Es-iMagenet | ES-Imagenet: un millón de datos de clasificación de transmisión de eventos para aumentar las redes neuronales |
| Vías duras | HardVS: revisando el reconocimiento de la actividad humana con sensores de visión dinámicos |
| N-CalCe101 | Convertir conjuntos de datos de imágenes estáticas a conjuntos de datos neuromórficos de pico utilizando sacadas |
| N-mnist | Convertir conjuntos de datos de imágenes estáticas a conjuntos de datos neuromórficos de pico utilizando sacadas |
| Gesto de navegación | Reconocimiento de gestos basado en eventos con supresión de fondo dinámico utilizando capacidades computacionales de teléfonos inteligentes |
| APOKING HEIDELBERG DIGITS (SHD) | Los conjuntos de datos de picos de Heidelberg para la evaluación sistemática de las redes neuronales de picos |
| Dvs-lip | Características espacio-temporales múltiples para la lectura de labios basada en eventos |
Los usuarios pueden usar los datos de eventos de origen y los datos de cuadros integrados por SpikeKJelly:
import torch
from torch . utils . data import DataLoader
from spikingjelly . datasets import pad_sequence_collate , padded_sequence_mask
from spikingjelly . datasets . dvs128_gesture import DVS128Gesture
# Set the root directory for the dataset
root_dir = 'D:/datasets/DVS128Gesture'
# Load event dataset
event_set = DVS128Gesture ( root_dir , train = True , data_type = 'event' )
event , label = event_set [ 0 ]
# Print the keys and their corresponding values in the event data
for k in event . keys ():
print ( k , event [ k ])
# t [80048267 80048277 80048278 ... 85092406 85092538 85092700]
# x [49 55 55 ... 60 85 45]
# y [82 92 92 ... 96 86 90]
# p [1 0 0 ... 1 0 0]
# label 0
# Load a dataset with fixed frame numbers
fixed_frames_number_set = DVS128Gesture ( root_dir , train = True , data_type = 'frame' , frames_number = 20 , split_by = 'number' )
# Randomly select two frames and print their shapes
rand_index = torch . randint ( low = 0 , high = fixed_frames_number_set . __len__ (), size = [ 2 ])
for i in rand_index :
frame , label = fixed_frames_number_set [ i ]
print ( f'frame[ { i } ].shape=[T, C, H, W]= { frame . shape } ' )
# frame[308].shape=[T, C, H, W]=(20, 2, 128, 128)
# frame[453].shape=[T, C, H, W]=(20, 2, 128, 128)
# Load a dataset with a fixed duration and print the shapes of the first 5 samples
fixed_duration_frame_set = DVS128Gesture ( root_dir , data_type = 'frame' , duration = 1000000 , train = True )
for i in range ( 5 ):
x , y = fixed_duration_frame_set [ i ]
print ( f'x[ { i } ].shape=[T, C, H, W]= { x . shape } ' )
# x[0].shape=[T, C, H, W]=(6, 2, 128, 128)
# x[1].shape=[T, C, H, W]=(6, 2, 128, 128)
# x[2].shape=[T, C, H, W]=(5, 2, 128, 128)
# x[3].shape=[T, C, H, W]=(5, 2, 128, 128)
# x[4].shape=[T, C, H, W]=(7, 2, 128, 128)
# Create a data loader for the fixed duration frame dataset and print the shapes and sequence lengths
train_data_loader = DataLoader ( fixed_duration_frame_set , collate_fn = pad_sequence_collate , batch_size = 5 )
for x , y , x_len in train_data_loader :
print ( f'x.shape=[N, T, C, H, W]= { tuple ( x . shape ) } ' )
print ( f'x_len= { x_len } ' )
mask = padded_sequence_mask ( x_len ) # mask.shape = [T, N]
print ( f'mask= n { mask . t (). int () } ' )
break
# x.shape=[N, T, C, H, W]=(5, 7, 2, 128, 128)
# x_len=tensor([6, 6, 5, 5, 7])
# mask=
# tensor([[1, 1, 1, 1, 1, 1, 0],
# [1, 1, 1, 1, 1, 1, 0],
# [1, 1, 1, 1, 1, 0, 0],
# [1, 1, 1, 1, 1, 0, 0],
# [1, 1, 1, 1, 1, 1, 1]], dtype=torch.int32)Se incluirán más conjuntos de datos en el futuro.
Si los enlaces de descarga de algunos conjuntos de datos no están disponibles para algunos usuarios, los usuarios pueden descargar desde Openi Mirror:
https://openi.pcl.ac.cn/openi/spikingjelly/datasets?type=0
Todos los conjuntos de datos guardados en el Mirror Openi están permitidos por su licencia o acuerdo del autor.
Spikingjelly ofrece tutoriales elaborados. Aquí hay algunos tutoriales:
| Cifra | Tutorial |
|---|---|
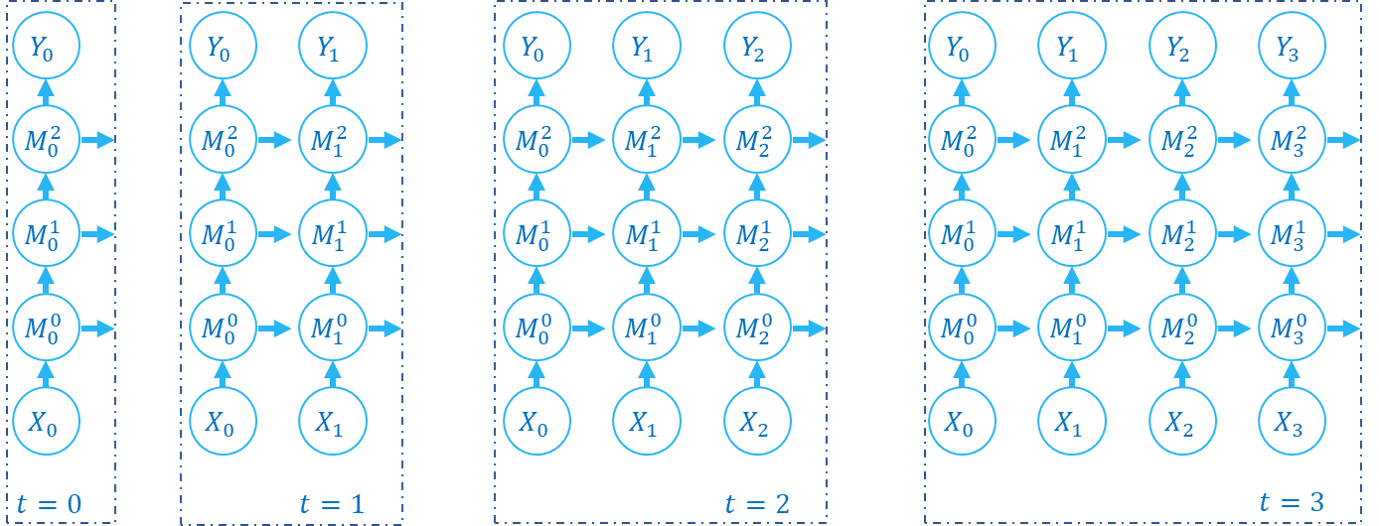 | Concepción básica |
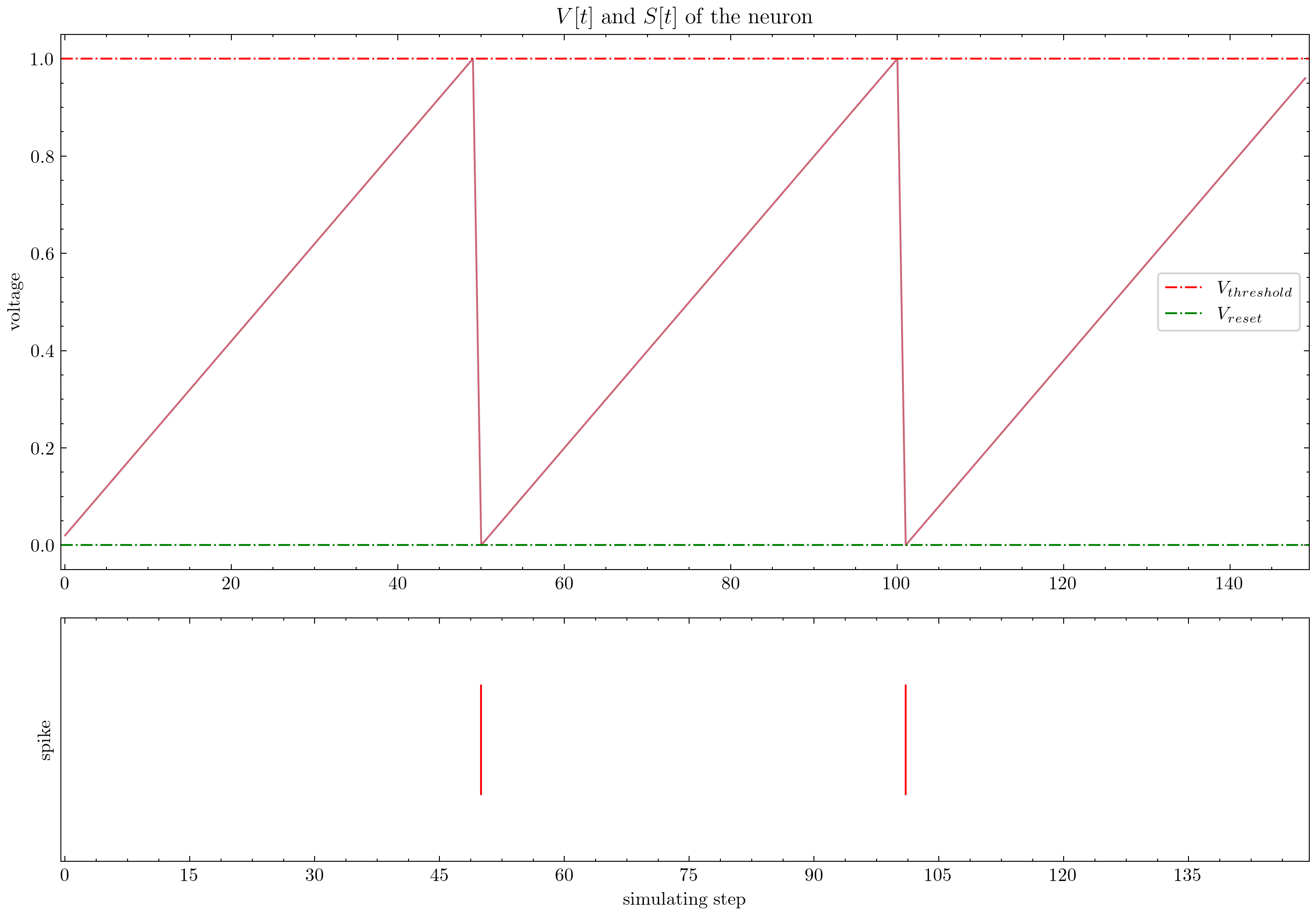 | Neurona |
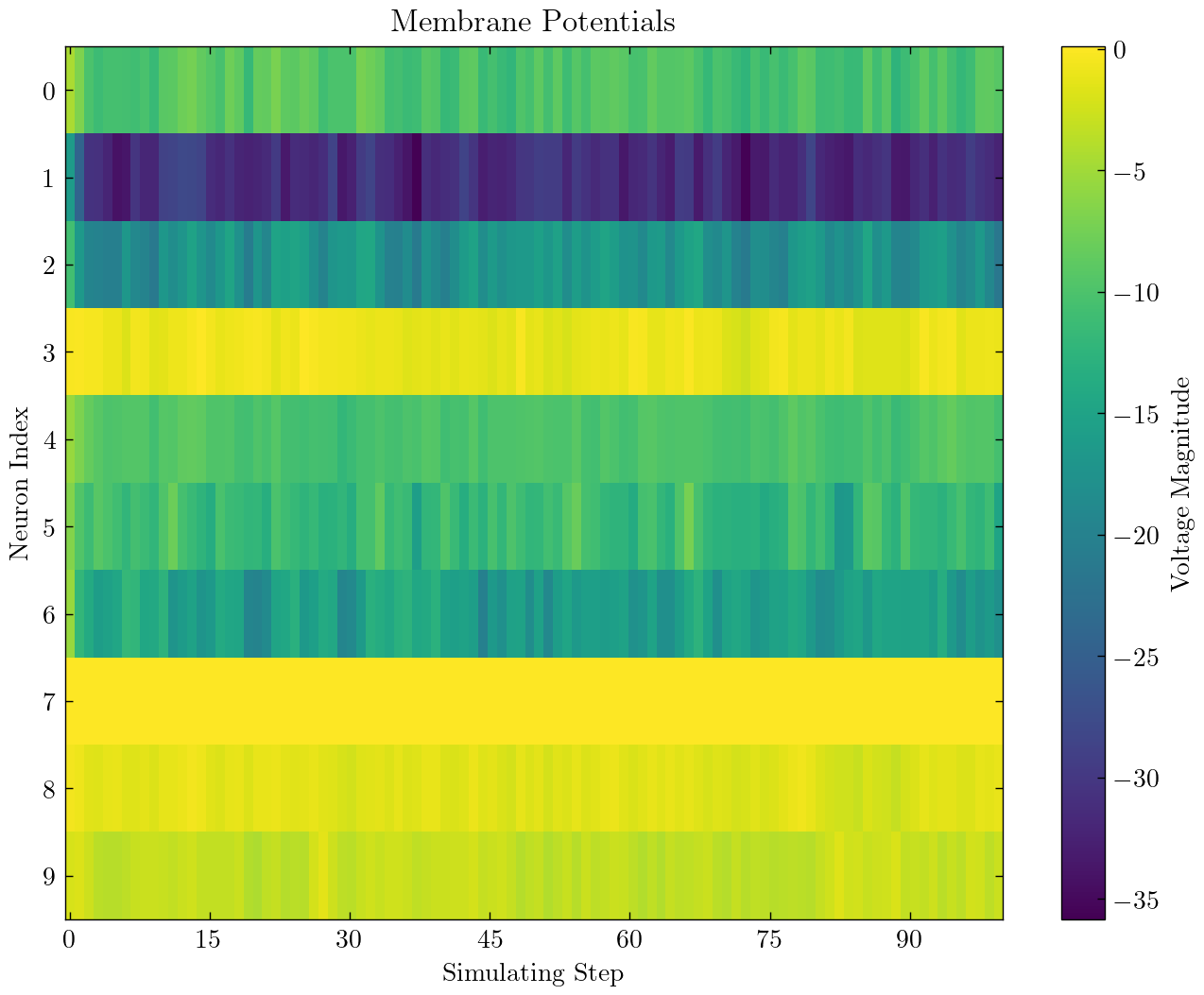 | SNN de capa totalmente conectada para clasificar MNIST |
 | SNN convolucional para clasificar fmnist |
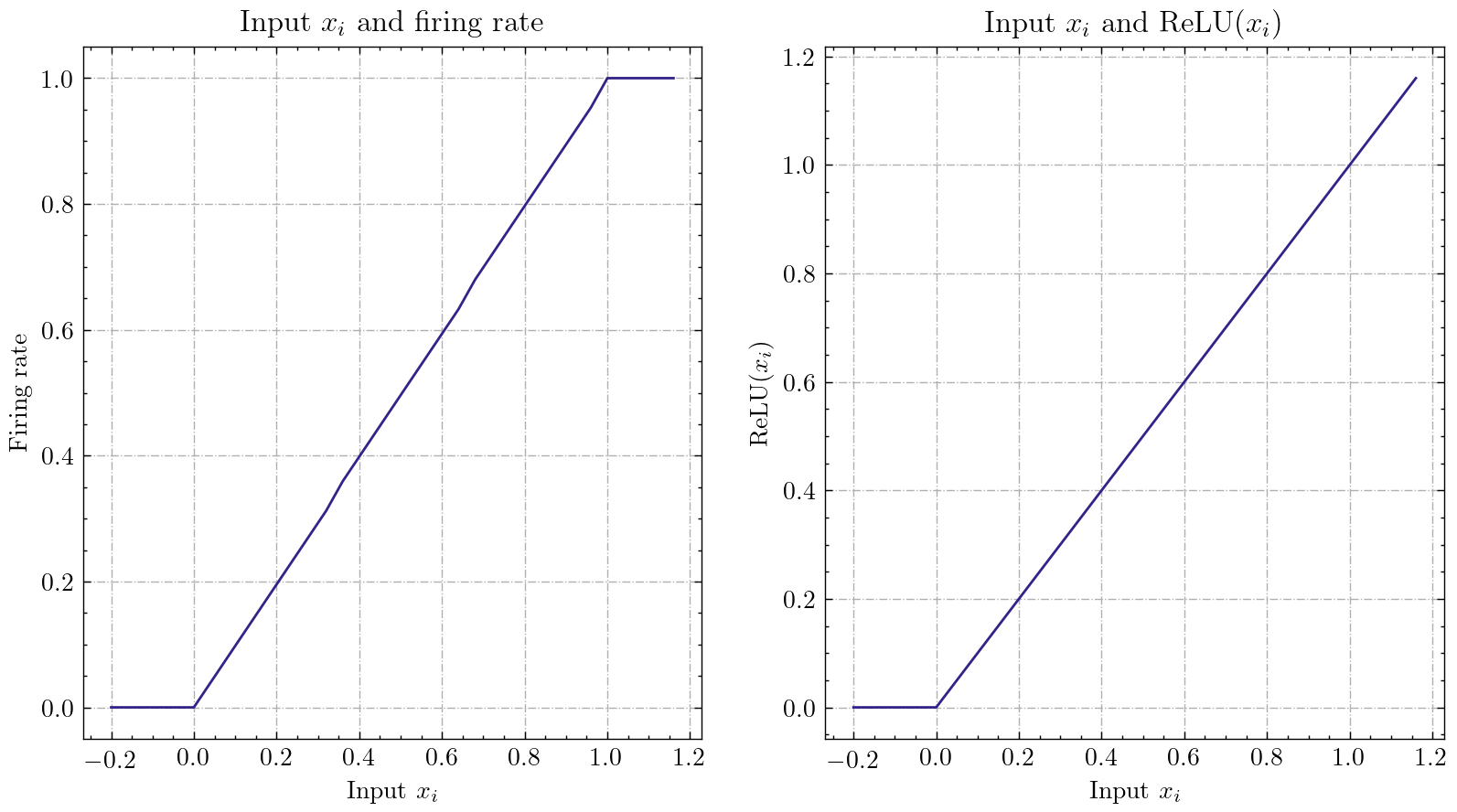 | Ann2snn |
 | Procesamiento de conjuntos de datos neuromórficos |
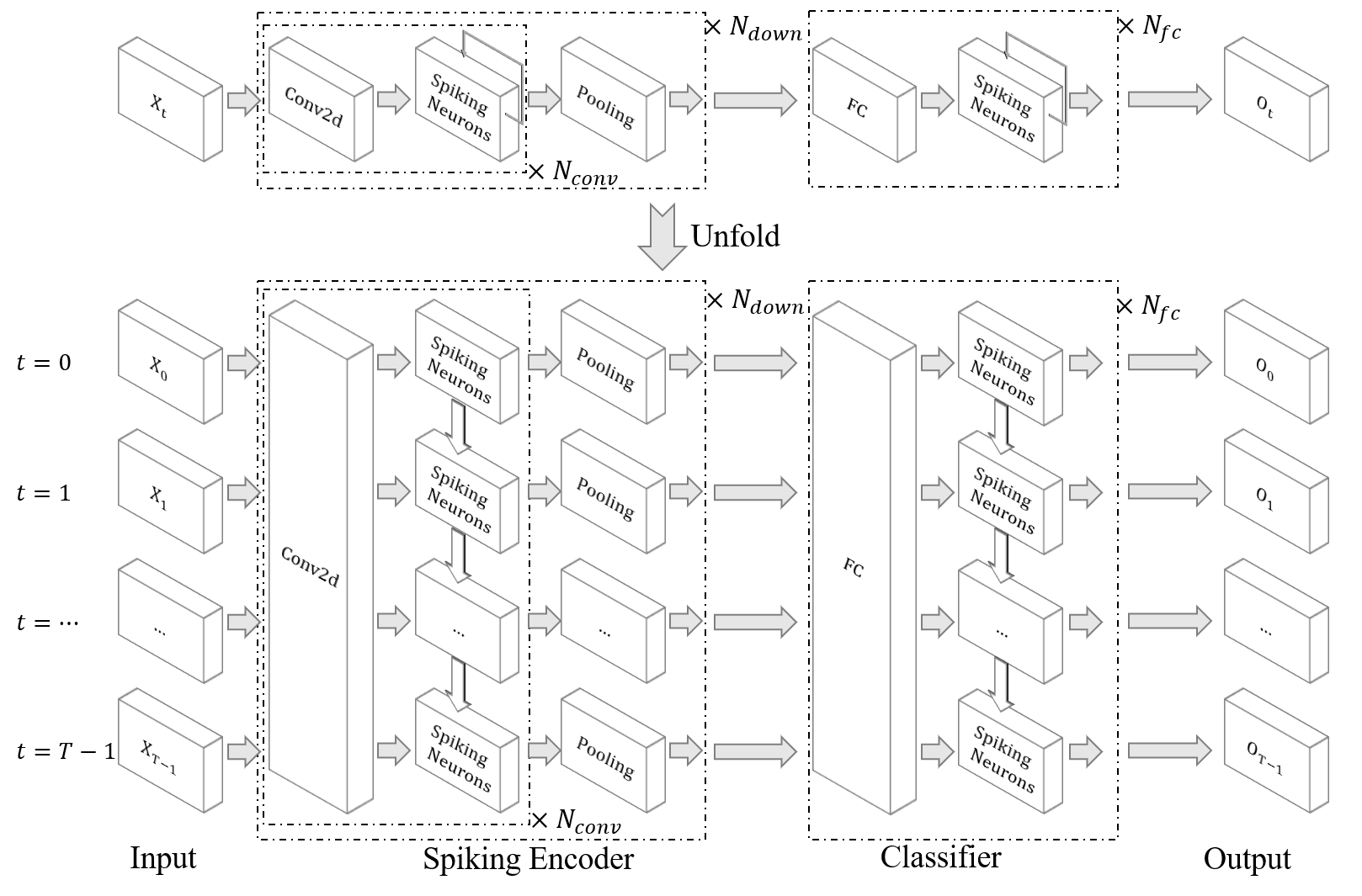 | Clasificar el gesto de DVS |
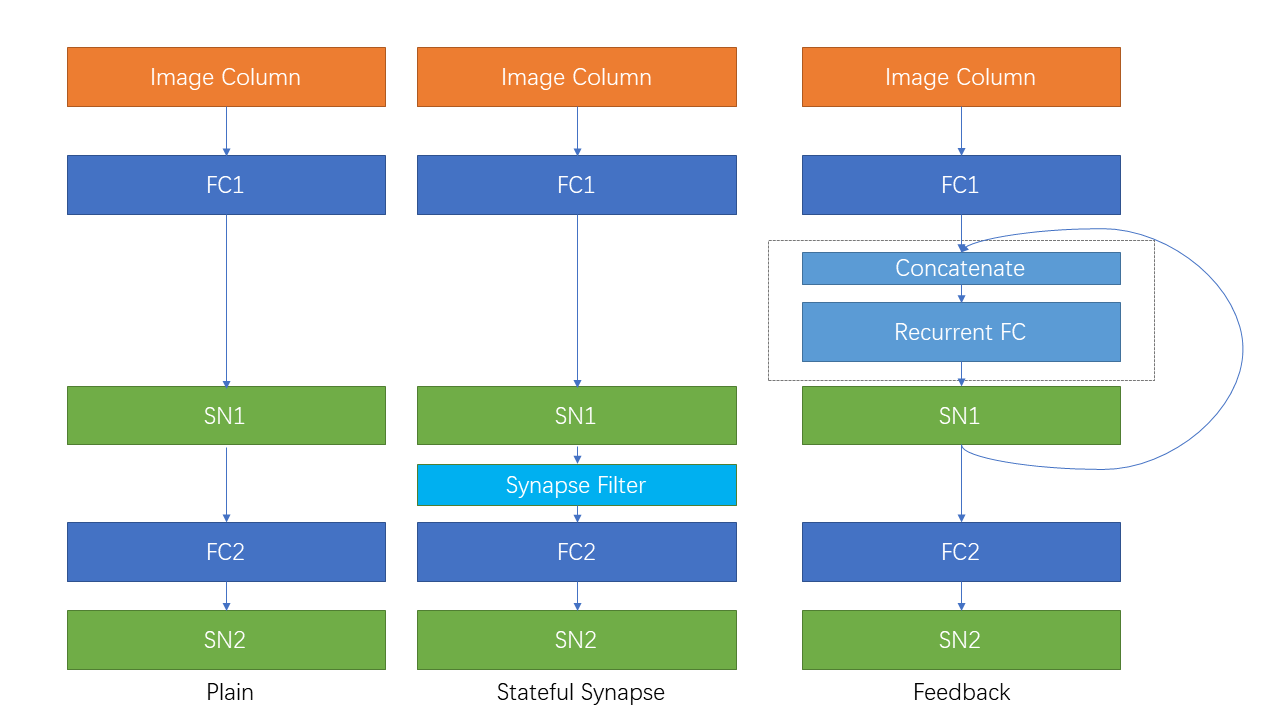 | Conexión recurrente y sinapsis con estado |
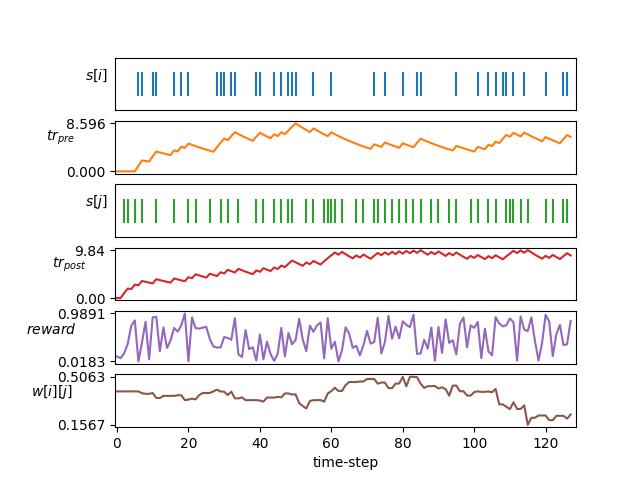 | Aprendizaje STDP |
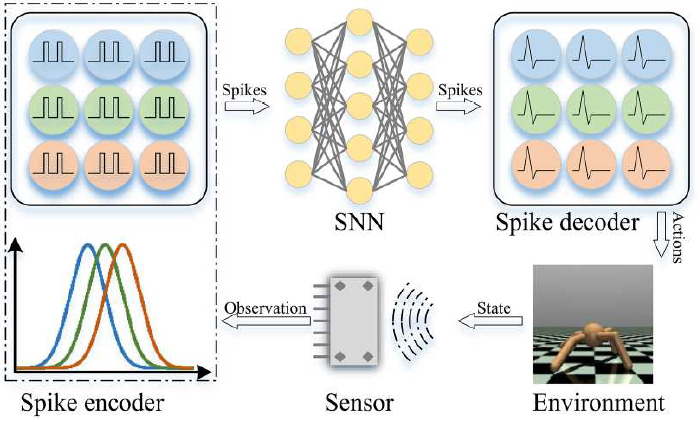 | Aprendizaje de refuerzo |
Otros tutoriales que no se enumeran aquí también están disponibles en el documento https://spikingjelly.readthedocs.io.
Las publicaciones que usan SpikingJelly se registran en publicaciones. Si usa SpiChingJelly en su artículo, también puede agregarlo a esta tabla mediante la solicitud de extracción.
Si usa SpiChingJelly en su trabajo, cíquelo de la siguiente manera:
@article{
doi:10.1126/sciadv.adi1480,
author = {Wei Fang and Yanqi Chen and Jianhao Ding and Zhaofei Yu and Timothée Masquelier and Ding Chen and Liwei Huang and Huihui Zhou and Guoqi Li and Yonghong Tian },
title = {SpikingJelly: An open-source machine learning infrastructure platform for spike-based intelligence},
journal = {Science Advances},
volume = {9},
number = {40},
pages = {eadi1480},
year = {2023},
doi = {10.1126/sciadv.adi1480},
URL = {https://www.science.org/doi/abs/10.1126/sciadv.adi1480},
eprint = {https://www.science.org/doi/pdf/10.1126/sciadv.adi1480},
abstract = {Spiking neural networks (SNNs) aim to realize brain-inspired intelligence on neuromorphic chips with high energy efficiency by introducing neural dynamics and spike properties. As the emerging spiking deep learning paradigm attracts increasing interest, traditional programming frameworks cannot meet the demands of automatic differentiation, parallel computation acceleration, and high integration of processing neuromorphic datasets and deployment. In this work, we present the SpikingJelly framework to address the aforementioned dilemma. We contribute a full-stack toolkit for preprocessing neuromorphic datasets, building deep SNNs, optimizing their parameters, and deploying SNNs on neuromorphic chips. Compared to existing methods, the training of deep SNNs can be accelerated 11×, and the superior extensibility and flexibility of SpikingJelly enable users to accelerate custom models at low costs through multilevel inheritance and semiautomatic code generation. SpikingJelly paves the way for synthesizing truly energy-efficient SNN-based machine intelligence systems, which will enrich the ecology of neuromorphic computing. Motivation and introduction of the software framework SpikingJelly for spiking deep learning.}}
Puede leer los problemas y obtener los problemas para resolverse y los últimos planes de desarrollo. Agradecemos a todos los usuarios para unirse a la discusión de los planes de desarrollo, resolver problemas y enviar solicitudes de extracción.
No todos los documentos API están escritos en inglés y chino. Damos la bienvenida a los usuarios para completar la traducción (del inglés al chino o del chino al inglés).
Multimedia Learning Group, Institute of Digital Media (NELVT), la Universidad de Pekín y el Laboratorio Peng Cheng son los principales desarrolladores de Spikkingjelly.


La lista de desarrolladores se puede encontrar aquí.


