spikingjelly
1.0.0
Englisch | 中文 (Chinesisch)
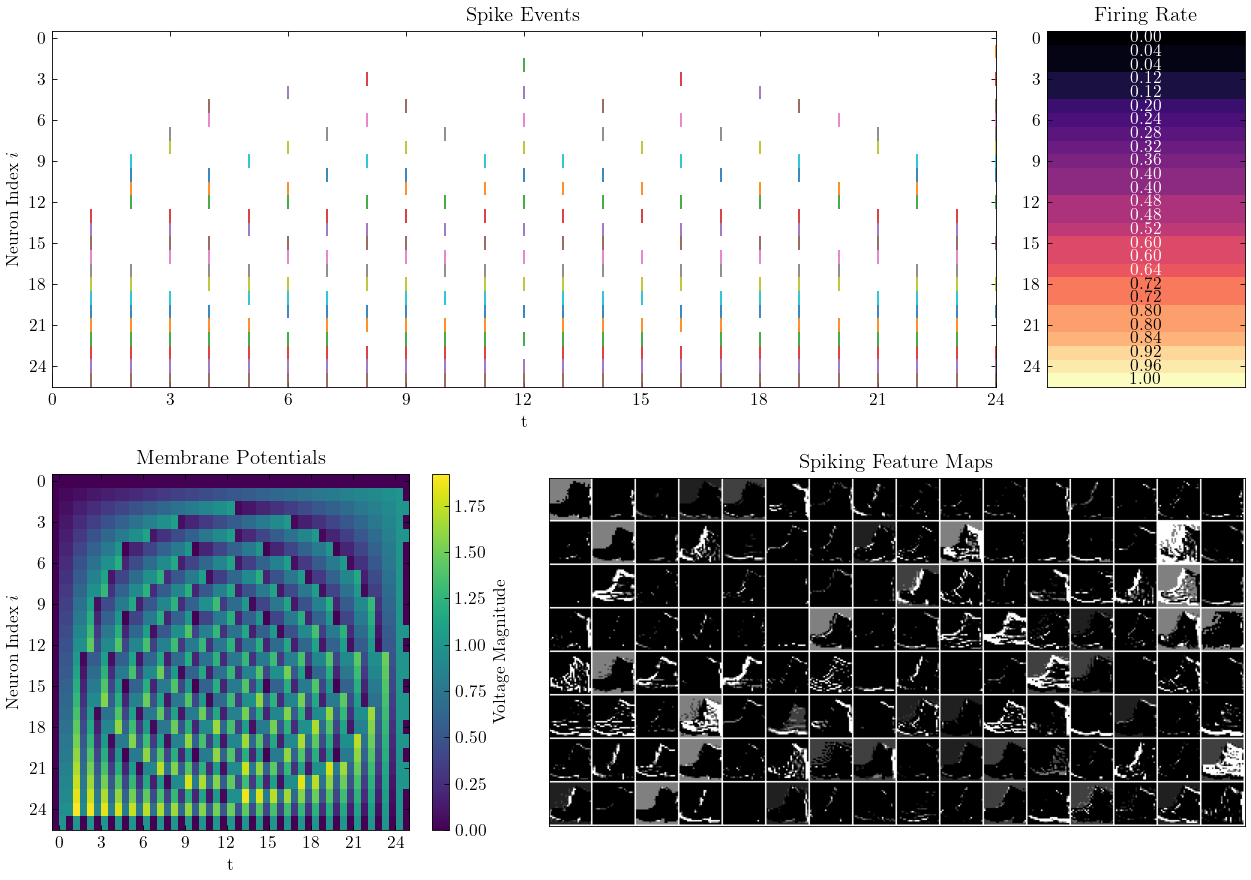
Spikingjelly ist ein Open-Source-Deep-Lern-Rahmen für Spiking Neural Network (SNN), das auf Pytorch basiert.
Die Dokumentation von Spikingjelly ist sowohl in Englisch als auch in Chinesisch geschrieben: https://spikingjelly.readthedocs.io.
Beachten Sie, dass Spikingjelly auf Pytorch basiert. Bitte stellen Sie sicher, dass Sie Pytorch installiert haben, bevor Sie Spikingjelly installieren.
Versionsnotizen
Die ungerade Versionsnummer ist die sich entwickelnde Version, die mit dem GitHub/Openi -Repository aktualisiert wird. Die gleichmäßige Versionsnummer ist die stabile Version und ist bei PYPI erhältlich.
Das Standarddoc ist für die neueste Entwicklungsversion. Wenn Sie die stabile Version verwenden, vergessen Sie nicht, in der entsprechenden Version zum DOC zu wechseln.
Aus der Version 0.0.0.0.14 werden Module einschließlich clock_driven und event_driven umbenannt. Bitte beachten Sie das Tutorial Migrate von alten Versionen.
Wenn Sie eine alte Version von Spikingjelly verwenden, können Sie auf tödliche Fehler stoßen. Weitere Informationen finden Sie in der Bugs -Geschichte mit Veröffentlichungen.
Dokumente für verschiedene Versionen:
Installieren Sie die letzte stabile Version von PYPI :
pip install spikingjellyInstallieren Sie die neueste Entwicklungsversion aus dem Quellcode :
Von Github:
git clone https://github.com/fangwei123456/spikingjelly.git
cd spikingjelly
python setup.py installVon openi:
git clone https://openi.pcl.ac.cn/OpenI/spikingjelly.git
cd spikingjelly
python setup.py installSpikingjelly ist benutzerfreundlich. Der Bau von SNN mit Spikingjelly ist so einfach wie das Bau von Ann in Pytorch:
nn . Sequential (
layer . Flatten (),
layer . Linear ( 28 * 28 , 10 , bias = False ),
neuron . LIFNode ( tau = tau , surrogate_function = surrogate . ATan ())
)Dieses einfache Netzwerk mit einem Poisson -Encoder kann im MNIST -Testdatensatz 92% Genauigkeit erreichen. Lesen Sie im Tutorial finden Sie weitere Informationen. Sie können diesen Code auch in einem Python -Terminal ausführen, um MNIST zu klassifizieren:
python - m spikingjelly . activation_based . examples . lif_fc_mnist - tau 2.0 - T 100 - device cuda : 0 - b 64 - epochs 100 - data - dir < PATH to MNIST > - amp - opt adam - lr 1e-3 - j 8 Spikejelly implementiert eine relativ allgemeine Ann-SNN-Umwandlungsschnittstelle. Benutzer können die Konvertierung über Pytorch erkennen. Darüber hinaus können Benutzer den Conversion -Modus anpassen.
class ANN ( nn . Module ):
def __init__ ( self ):
super (). __init__ ()
self . network = nn . Sequential (
nn . Conv2d ( 1 , 32 , 3 , 1 ),
nn . BatchNorm2d ( 32 , eps = 1e-3 ),
nn . ReLU (),
nn . AvgPool2d ( 2 , 2 ),
nn . Conv2d ( 32 , 32 , 3 , 1 ),
nn . BatchNorm2d ( 32 , eps = 1e-3 ),
nn . ReLU (),
nn . AvgPool2d ( 2 , 2 ),
nn . Conv2d ( 32 , 32 , 3 , 1 ),
nn . BatchNorm2d ( 32 , eps = 1e-3 ),
nn . ReLU (),
nn . AvgPool2d ( 2 , 2 ),
nn . Flatten (),
nn . Linear ( 32 , 10 )
)
def forward ( self , x ):
x = self . network ( x )
return xDieses einfache Netzwerk mit analoge Codierung kann nach der Konvertierung im MNIST -Testdatensatz eine Genauigkeit von 98,44% erreichen. Lesen Sie das Tutorial für weitere Details. Sie können diesen Code auch in einem Python -Terminal ausführen, um MNIST mithilfe des konvertierten Modells zu trainieren:
> >> import spikingjelly . activation_based . ann2snn . examples . cnn_mnist as cnn_mnist
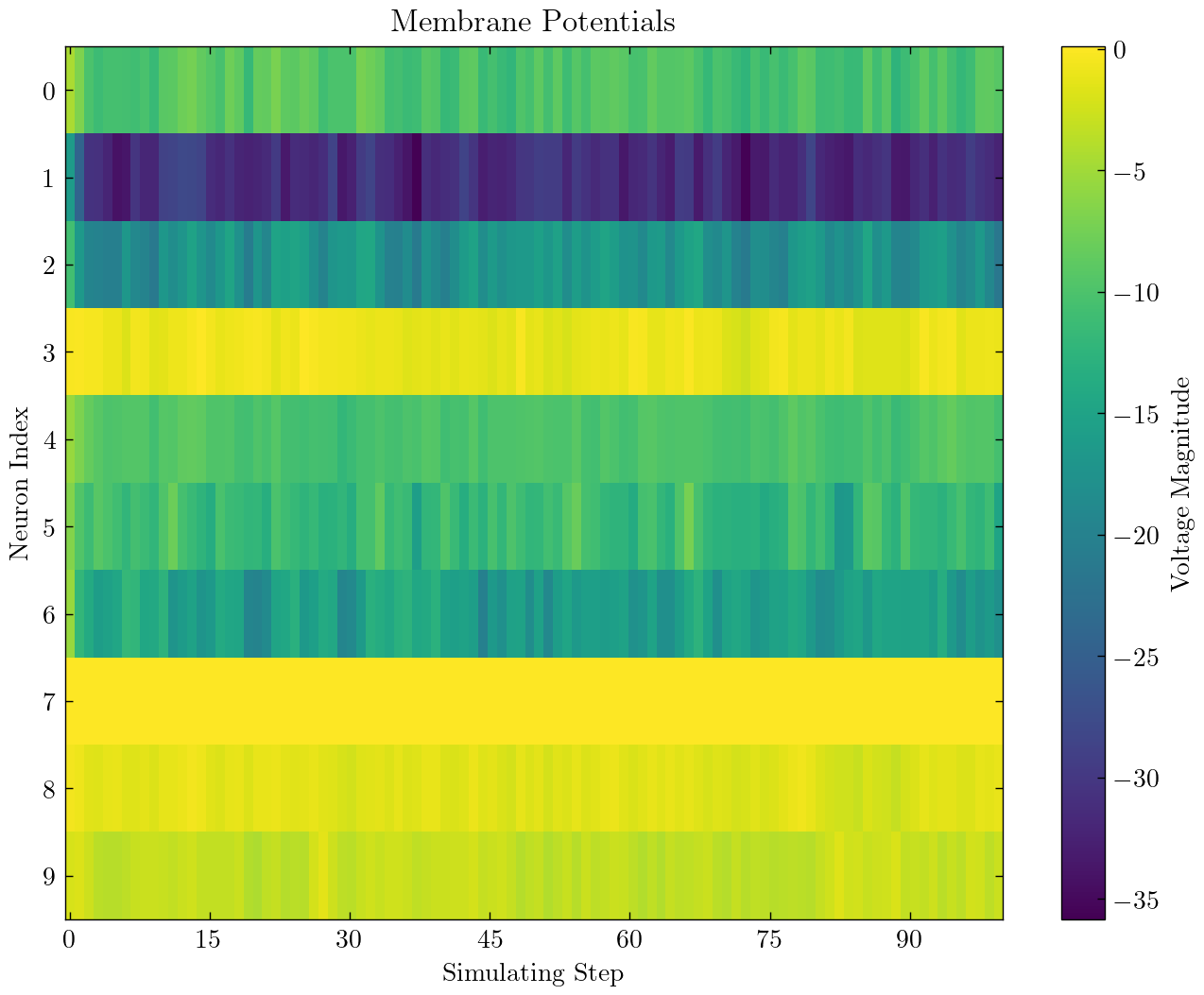
> >> cnn_mnist . main () Spikingjelly bietet zwei Backends für mehrstufige Neuronen. Sie können das benutzerfreundliche torch -Backend zum einfachen Codieren und Debuggen verwenden und cupy Backend für eine schnellere Trainingsgeschwindigkeit verwenden.
Die folgende Abbildung vergleicht die Ausführungszeit von zwei Backends von mehrstufigen LIF-Neuronen ( float32 ):
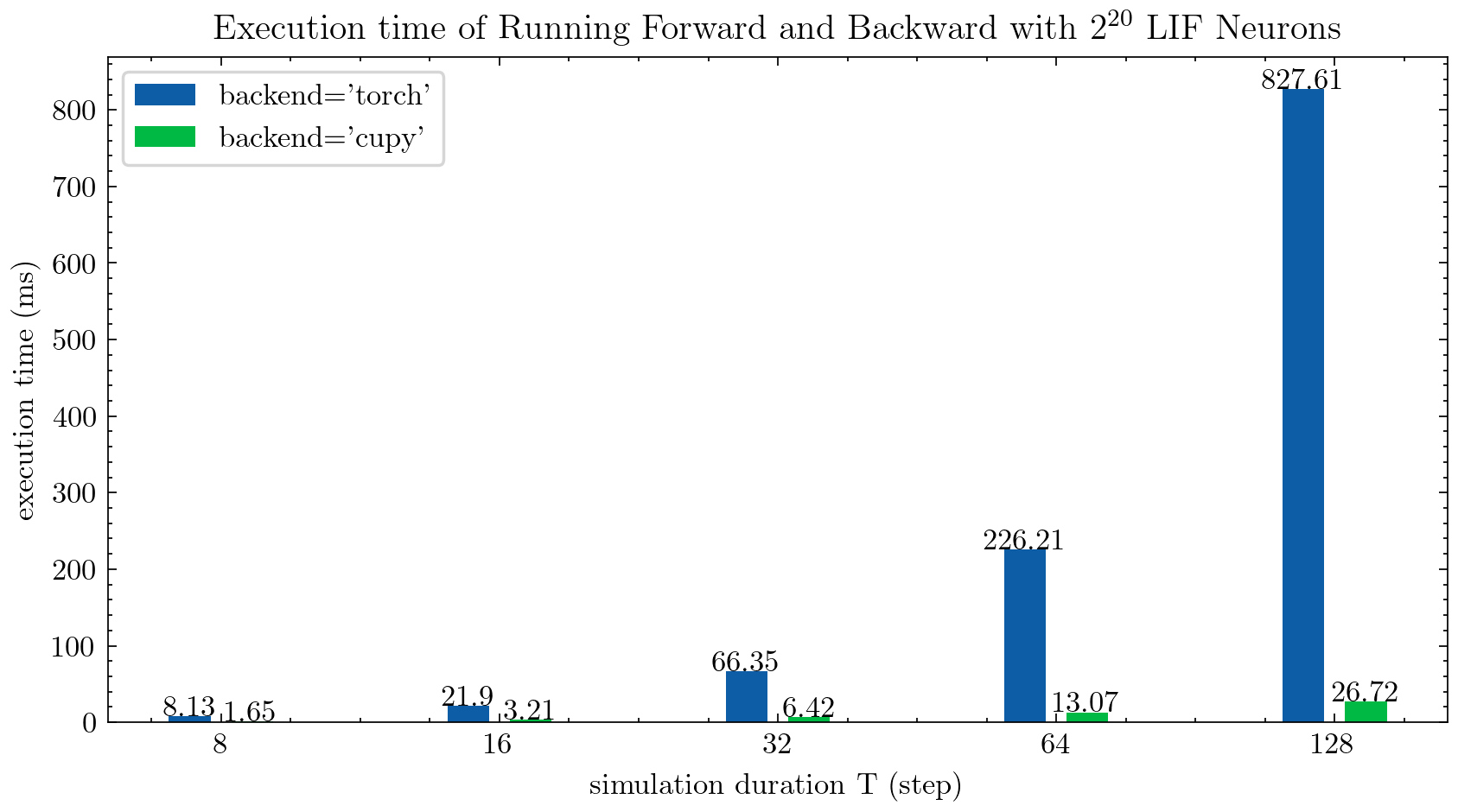
float16 wird auch vom cupy -Backend bereitgestellt und kann im automatischen Mischpräzisionstraining verwendet werden.
Um das cupy -Backend zu verwenden, installieren Sie bitte Cupy. Beachten Sie, dass das cupy -Backend nur die GPU unterstützt, während das torch -Backend sowohl CPU als auch GPU unterstützt.
So einfach wie die Verwendung von Pytorch.
> >> net = nn . Sequential ( layer . Flatten (), layer . Linear ( 28 * 28 , 10 , bias = False ), neuron . LIFNode ( tau = tau ))
> >> net = net . to ( device ) # Can be CPU or CUDA devices Spikingjelly enthält die folgenden neuromorphen Datensätze:
| Datensatz | Quelle |
|---|---|
| ASL-DVS | Graph-basierte Objektklassifizierung für die neuromorphe Seherkennung |
| CIFAR10-DVS | CIFAR10-DVS: Ein Ereignisstromdatensatz für die Objektklassifizierung |
| DVS128 Geste | Ein vollwertiges, voll ereignisbasiertes Gestenerkennungssystem |
| Es-Imagenet | ES-Imagenet: Eine Million Event-Stream-Klassifizierungsdatensatz für die Spike neuronaler Netze |
| Hardvs | Hardvs: Überprüfung der menschlichen Aktivitätserkennung mit dynamischen Sehsensoren |
| N-Caltech101 | Konvertieren statischer Bilddatensätze in spitzende neuromorphe Datensätze mithilfe von Sakkaden |
| N-Mnist | Konvertieren statischer Bilddatensätze in spitzende neuromorphe Datensätze mithilfe von Sakkaden |
| NAV -Geste | Ereignisbasierte Gestenerkennung mit dynamischer Hintergrundunterdrückung mithilfe von Smartphone-Rechenfunktionen |
| Heidelberg -Ziffern (SHD) spitzen | Die Heidelberg -Spike -Datensätze zur systematischen Bewertung von Spike -neuronalen Netzwerken |
| DVS-LIP | Multi-verbereitete räumlich-zeitliche Funktionen wahrgenommenes Netzwerk für ereignisbasiertes Lippenlesen |
Benutzer können sowohl die von Spikingjelly integrierten Origin -Ereignisdaten als auch die Rahmendaten verwenden:
import torch
from torch . utils . data import DataLoader
from spikingjelly . datasets import pad_sequence_collate , padded_sequence_mask
from spikingjelly . datasets . dvs128_gesture import DVS128Gesture
# Set the root directory for the dataset
root_dir = 'D:/datasets/DVS128Gesture'
# Load event dataset
event_set = DVS128Gesture ( root_dir , train = True , data_type = 'event' )
event , label = event_set [ 0 ]
# Print the keys and their corresponding values in the event data
for k in event . keys ():
print ( k , event [ k ])
# t [80048267 80048277 80048278 ... 85092406 85092538 85092700]
# x [49 55 55 ... 60 85 45]
# y [82 92 92 ... 96 86 90]
# p [1 0 0 ... 1 0 0]
# label 0
# Load a dataset with fixed frame numbers
fixed_frames_number_set = DVS128Gesture ( root_dir , train = True , data_type = 'frame' , frames_number = 20 , split_by = 'number' )
# Randomly select two frames and print their shapes
rand_index = torch . randint ( low = 0 , high = fixed_frames_number_set . __len__ (), size = [ 2 ])
for i in rand_index :
frame , label = fixed_frames_number_set [ i ]
print ( f'frame[ { i } ].shape=[T, C, H, W]= { frame . shape } ' )
# frame[308].shape=[T, C, H, W]=(20, 2, 128, 128)
# frame[453].shape=[T, C, H, W]=(20, 2, 128, 128)
# Load a dataset with a fixed duration and print the shapes of the first 5 samples
fixed_duration_frame_set = DVS128Gesture ( root_dir , data_type = 'frame' , duration = 1000000 , train = True )
for i in range ( 5 ):
x , y = fixed_duration_frame_set [ i ]
print ( f'x[ { i } ].shape=[T, C, H, W]= { x . shape } ' )
# x[0].shape=[T, C, H, W]=(6, 2, 128, 128)
# x[1].shape=[T, C, H, W]=(6, 2, 128, 128)
# x[2].shape=[T, C, H, W]=(5, 2, 128, 128)
# x[3].shape=[T, C, H, W]=(5, 2, 128, 128)
# x[4].shape=[T, C, H, W]=(7, 2, 128, 128)
# Create a data loader for the fixed duration frame dataset and print the shapes and sequence lengths
train_data_loader = DataLoader ( fixed_duration_frame_set , collate_fn = pad_sequence_collate , batch_size = 5 )
for x , y , x_len in train_data_loader :
print ( f'x.shape=[N, T, C, H, W]= { tuple ( x . shape ) } ' )
print ( f'x_len= { x_len } ' )
mask = padded_sequence_mask ( x_len ) # mask.shape = [T, N]
print ( f'mask= n { mask . t (). int () } ' )
break
# x.shape=[N, T, C, H, W]=(5, 7, 2, 128, 128)
# x_len=tensor([6, 6, 5, 5, 7])
# mask=
# tensor([[1, 1, 1, 1, 1, 1, 0],
# [1, 1, 1, 1, 1, 1, 0],
# [1, 1, 1, 1, 1, 0, 0],
# [1, 1, 1, 1, 1, 0, 0],
# [1, 1, 1, 1, 1, 1, 1]], dtype=torch.int32)Weitere Datensätze werden in Zukunft enthalten sein.
Wenn für einige Benutzer keine Datensätze herunterladen, können die Benutzer vom OpenI Mirror herunterladen:
https://openi.pcl.ac.cn/openi/spikingjelly/datasets?type=0
Alle im Openi Mirror gespeicherten Datensätze sind durch ihre Lizenz oder Autorvereinbarung zulässig.
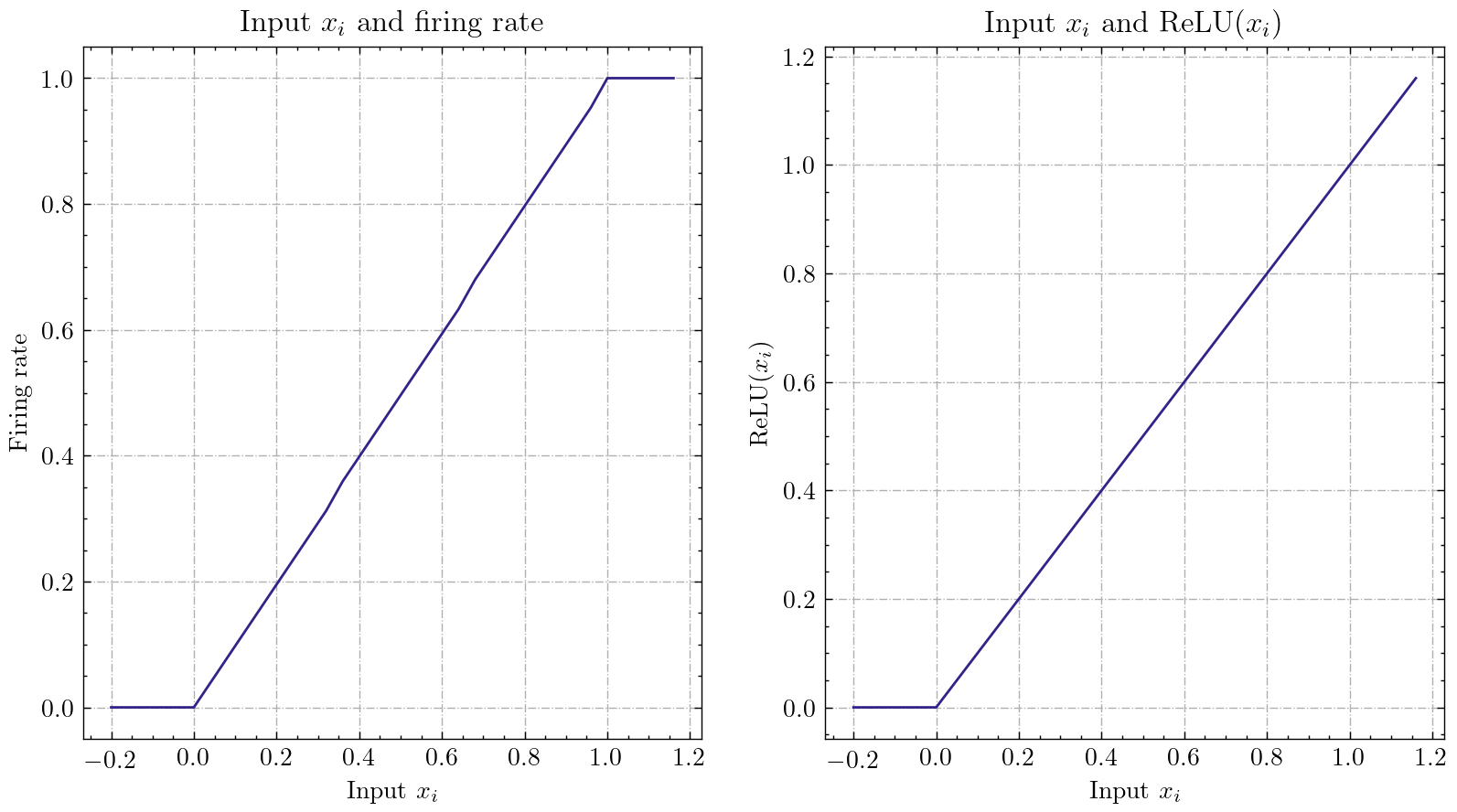
Spikingjelly bietet ausführliche Tutorials. Hier sind einige Tutorials:
| Figur | Tutorial |
|---|---|
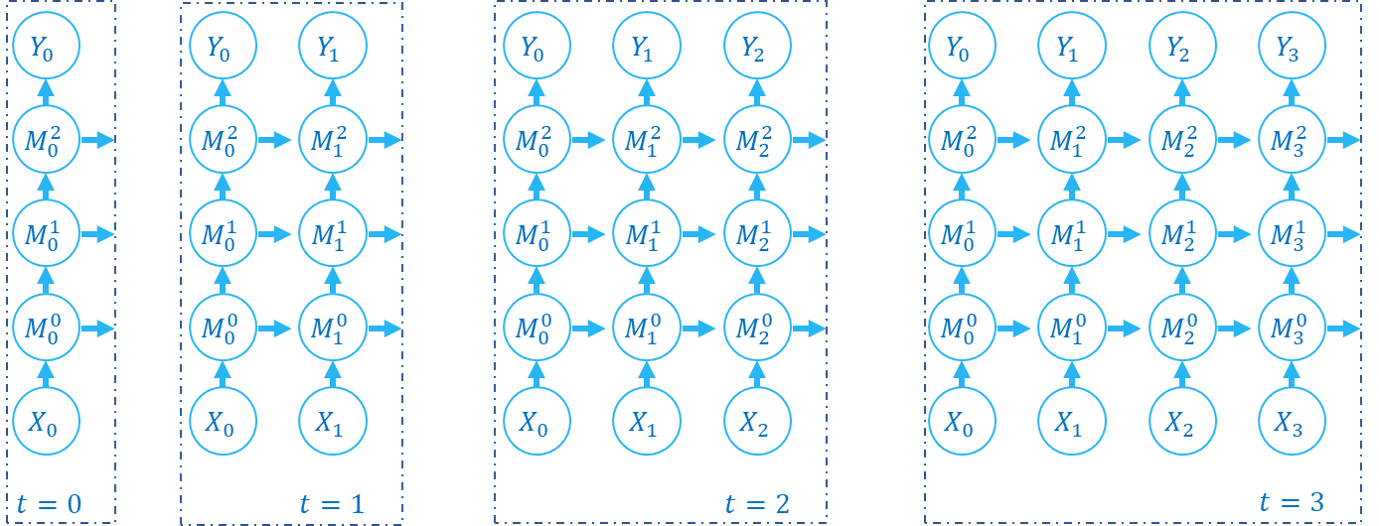 | Grundlegende Konzeption |
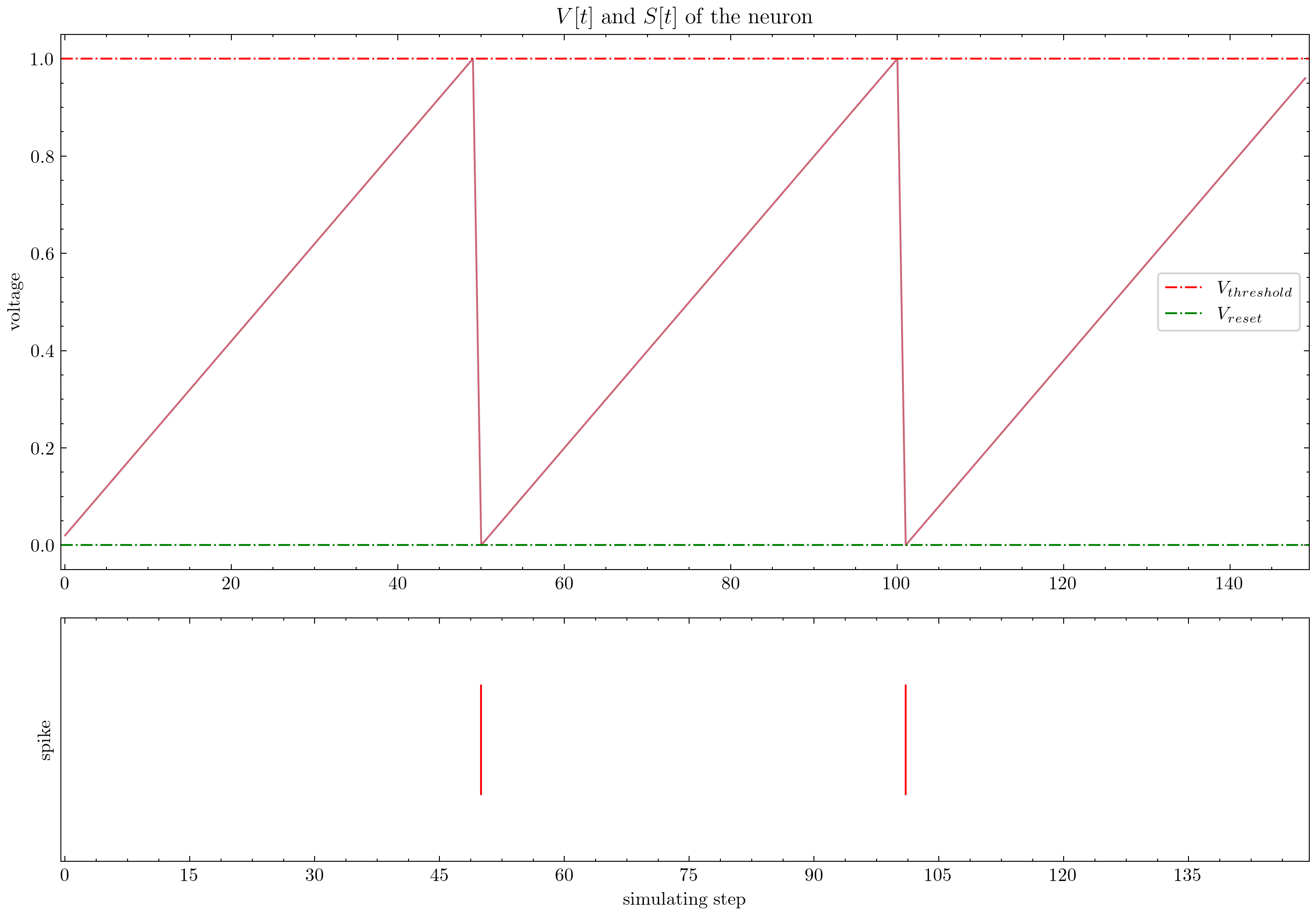 | Neuron |
 | Single vollständig verbundene Schicht SNN, um MNIST zu klassifizieren |
 | Faltungs -SNN, um den FMNisten zu klassifizieren |
 | Ann2Snn |
 | Neuromorphe Datensätzeverarbeitung |
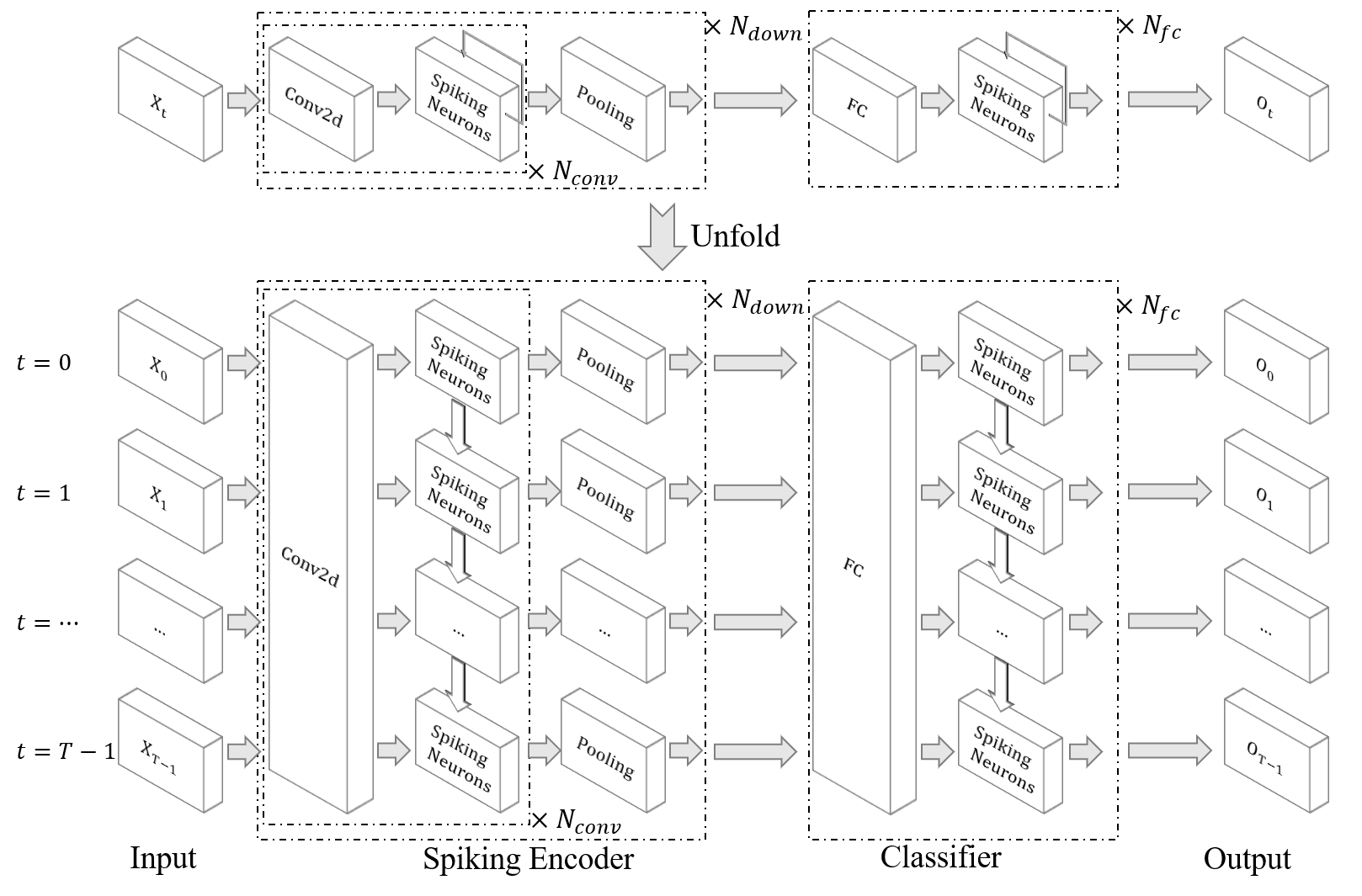 | Klassifizieren Sie die DVS -Geste |
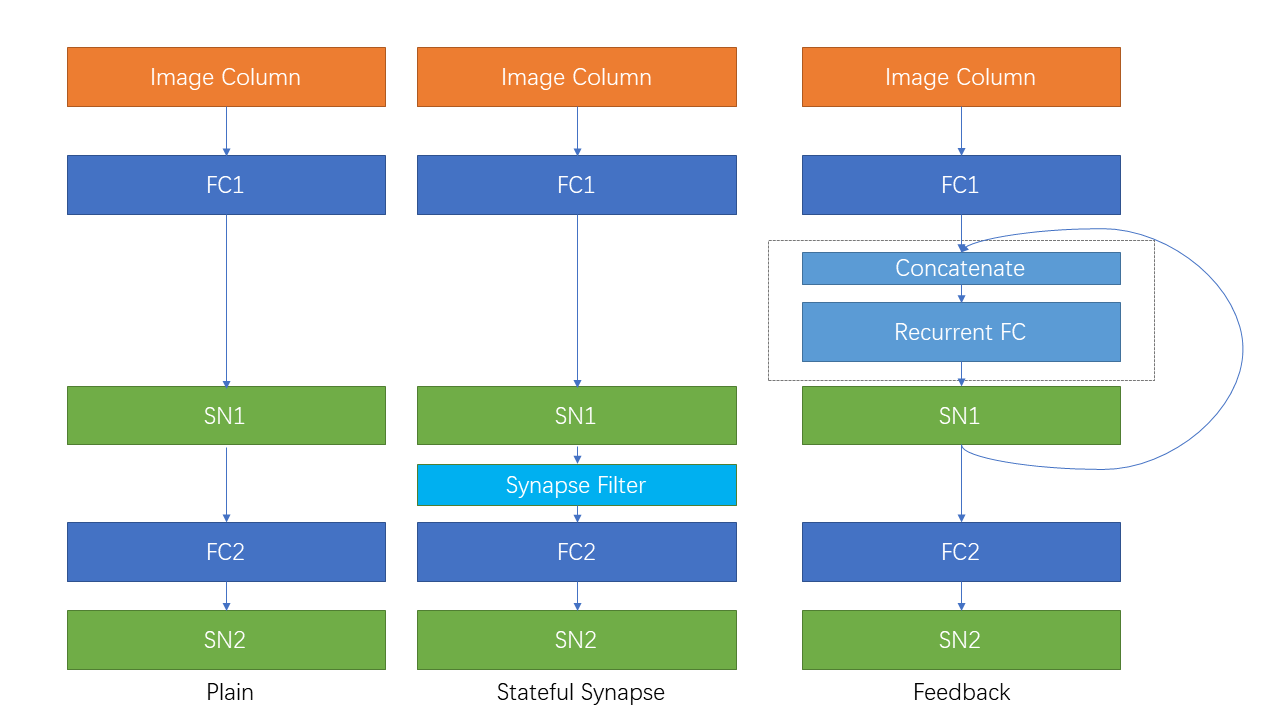 | Wiederkehrende Verbindung und staatliche Synapse |
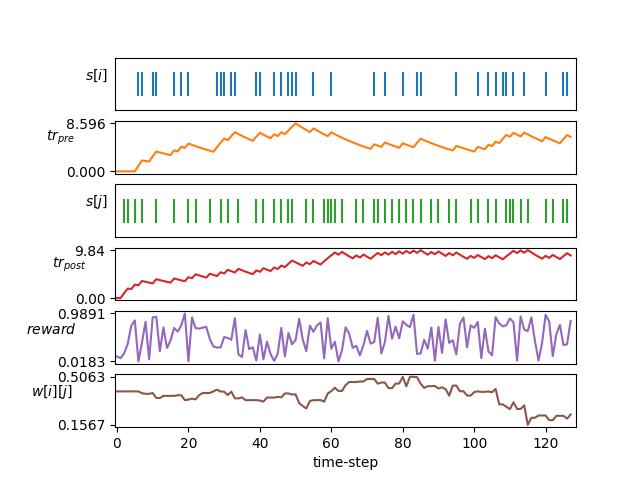 | STDP -Lernen |
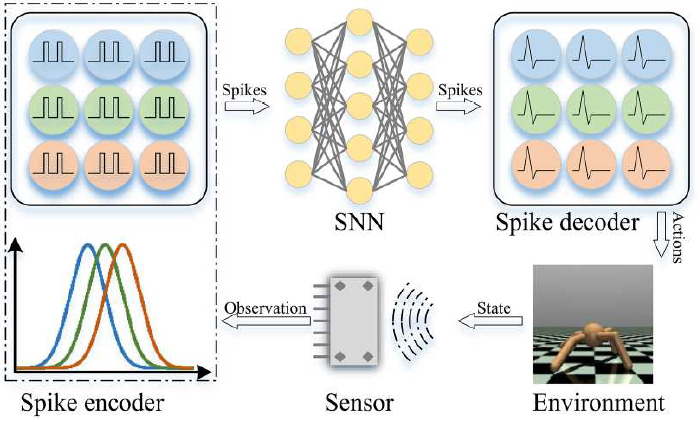 | Verstärkungslernen |
Andere Tutorials, die hier nicht aufgeführt sind, sind ebenfalls im Dokument https://spikingjelly.readthedocs.io verfügbar.
Veröffentlichungen mit Spikingjelly werden in Veröffentlichungen aufgezeichnet. Wenn Sie Spikejelly in Ihrem Papier verwenden, können Sie es auch mit Pull -Anfrage zu dieser Tabelle hinzufügen.
Wenn Sie Spikingjelly in Ihrer Arbeit verwenden, zitieren Sie es bitte wie folgt:
@article{
doi:10.1126/sciadv.adi1480,
author = {Wei Fang and Yanqi Chen and Jianhao Ding and Zhaofei Yu and Timothée Masquelier and Ding Chen and Liwei Huang and Huihui Zhou and Guoqi Li and Yonghong Tian },
title = {SpikingJelly: An open-source machine learning infrastructure platform for spike-based intelligence},
journal = {Science Advances},
volume = {9},
number = {40},
pages = {eadi1480},
year = {2023},
doi = {10.1126/sciadv.adi1480},
URL = {https://www.science.org/doi/abs/10.1126/sciadv.adi1480},
eprint = {https://www.science.org/doi/pdf/10.1126/sciadv.adi1480},
abstract = {Spiking neural networks (SNNs) aim to realize brain-inspired intelligence on neuromorphic chips with high energy efficiency by introducing neural dynamics and spike properties. As the emerging spiking deep learning paradigm attracts increasing interest, traditional programming frameworks cannot meet the demands of automatic differentiation, parallel computation acceleration, and high integration of processing neuromorphic datasets and deployment. In this work, we present the SpikingJelly framework to address the aforementioned dilemma. We contribute a full-stack toolkit for preprocessing neuromorphic datasets, building deep SNNs, optimizing their parameters, and deploying SNNs on neuromorphic chips. Compared to existing methods, the training of deep SNNs can be accelerated 11×, and the superior extensibility and flexibility of SpikingJelly enable users to accelerate custom models at low costs through multilevel inheritance and semiautomatic code generation. SpikingJelly paves the way for synthesizing truly energy-efficient SNN-based machine intelligence systems, which will enrich the ecology of neuromorphic computing. Motivation and introduction of the software framework SpikingJelly for spiking deep learning.}}
Sie können die Probleme lesen und die Probleme lösen und die neuesten Entwicklungspläne. Wir begrüßen alle Benutzer, sich der Diskussion über Entwicklungspläne anzuschließen, Probleme zu lösen und Pull -Anfragen zu senden.
Nicht alle API -Dokumente sind sowohl in Englisch als auch in Chinesisch geschrieben. Wir begrüßen Benutzer, um die Übersetzung (von Englisch über Chinesisch oder Chinesisch bis Englisch) abzuschließen.
Multimedia Learning Group, Institute of Digital Media (NELVT), Peking University und Peng Cheng Laboratory sind die Hauptentwickler von Spikingjelly.


Die Liste der Entwickler finden Sie hier.


