spikingjelly
1.0.0
Anglais | 中文 (chinois)
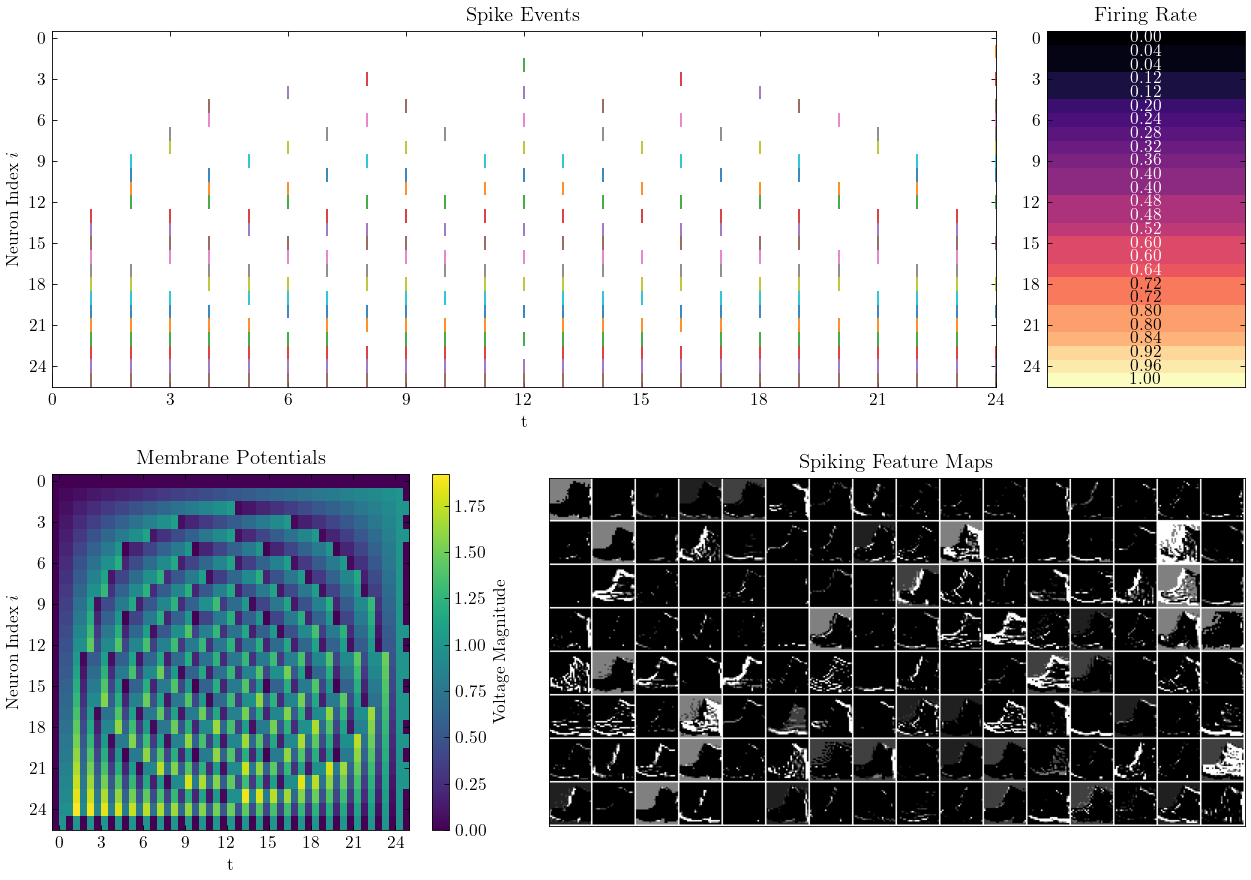
SPIKINGJELLY est un cadre d'apprentissage en profondeur open source pour le réseau neuronal de dopage (SNN) basé sur Pytorch.
La documentation de SpikingJelly est écrite en anglais et en chinois: https://spikingjelly.readthedocs.io.
Notez que SpikingJelly est basé sur Pytorch. Veuillez vous assurer que vous avez installé Pytorch avant d'installer SpikingJelly.
Notes de version
Le numéro de version impair est la version en développement, mise à jour avec le référentiel GitHub / OpenI. Le numéro de version uniforme est la version stable et est disponible chez PYPI.
Le DOC par défaut est pour la dernière version en développement. Si vous utilisez la version stable, n'oubliez pas de passer au DOC dans la version correspondante.
À partir de la version 0.0.0.0.14 , des modules tels que clock_driven et event_driven sont renommés. Veuillez vous référer au tutoriel migrer à partir des anciennes versions.
Si vous utilisez une ancienne version de SpikingJelly, vous pouvez rencontrer des bugs mortels. Reportez-vous à l'historique des bogues avec les versions pour plus de détails.
Docs pour différentes versions:
Installez la dernière version stable de PYPI :
pip install spikingjellyInstallez la dernière version en développement à partir du code source :
De GitHub:
git clone https://github.com/fangwei123456/spikingjelly.git
cd spikingjelly
python setup.py installD'OpenI:
git clone https://openi.pcl.ac.cn/OpenI/spikingjelly.git
cd spikingjelly
python setup.py installSPIKINGJELLY est convivial. Bâtiment SNN avec SpikingJelly est aussi simple que le bâtiment Ann à Pytorch:
nn . Sequential (
layer . Flatten (),
layer . Linear ( 28 * 28 , 10 , bias = False ),
neuron . LIFNode ( tau = tau , surrogate_function = surrogate . ATan ())
)Ce réseau simple avec un encodeur de Poisson peut atteindre une précision de 92% sur l'ensemble de données de test MNIST. Lire Reportez-vous au tutoriel pour plus de détails. Vous pouvez également exécuter ce code dans un terminal Python pour une formation sur la classification de MNIST:
python - m spikingjelly . activation_based . examples . lif_fc_mnist - tau 2.0 - T 100 - device cuda : 0 - b 64 - epochs 100 - data - dir < PATH to MNIST > - amp - opt adam - lr 1e-3 - j 8 SPIKINGJELLY met en œuvre une interface de conversion Ann-SNN relativement générale. Les utilisateurs peuvent réaliser la conversion via Pytorch. De plus, les utilisateurs peuvent personnaliser le mode de conversion.
class ANN ( nn . Module ):
def __init__ ( self ):
super (). __init__ ()
self . network = nn . Sequential (
nn . Conv2d ( 1 , 32 , 3 , 1 ),
nn . BatchNorm2d ( 32 , eps = 1e-3 ),
nn . ReLU (),
nn . AvgPool2d ( 2 , 2 ),
nn . Conv2d ( 32 , 32 , 3 , 1 ),
nn . BatchNorm2d ( 32 , eps = 1e-3 ),
nn . ReLU (),
nn . AvgPool2d ( 2 , 2 ),
nn . Conv2d ( 32 , 32 , 3 , 1 ),
nn . BatchNorm2d ( 32 , eps = 1e-3 ),
nn . ReLU (),
nn . AvgPool2d ( 2 , 2 ),
nn . Flatten (),
nn . Linear ( 32 , 10 )
)
def forward ( self , x ):
x = self . network ( x )
return xCe réseau simple avec codage analogique peut atteindre une précision de 98,44% après conversion sur l'ensemble de données de test MNIST. Lisez le tutoriel pour plus de détails. Vous pouvez également exécuter ce code dans un terminal Python pour une formation sur la classification du MNIST en utilisant le modèle converti:
> >> import spikingjelly . activation_based . ann2snn . examples . cnn_mnist as cnn_mnist
> >> cnn_mnist . main () SPIKINGJELLY fournit deux backends pour les neurones en plusieurs étapes. Vous pouvez utiliser le backend torch convivial pour le codage et le débogage et l'utilisation de backend cupy pour une vitesse de formation plus rapide.
La figure suivante compare le temps d'exécution de deux backends des neurones LIF en plusieurs étapes ( float32 ):
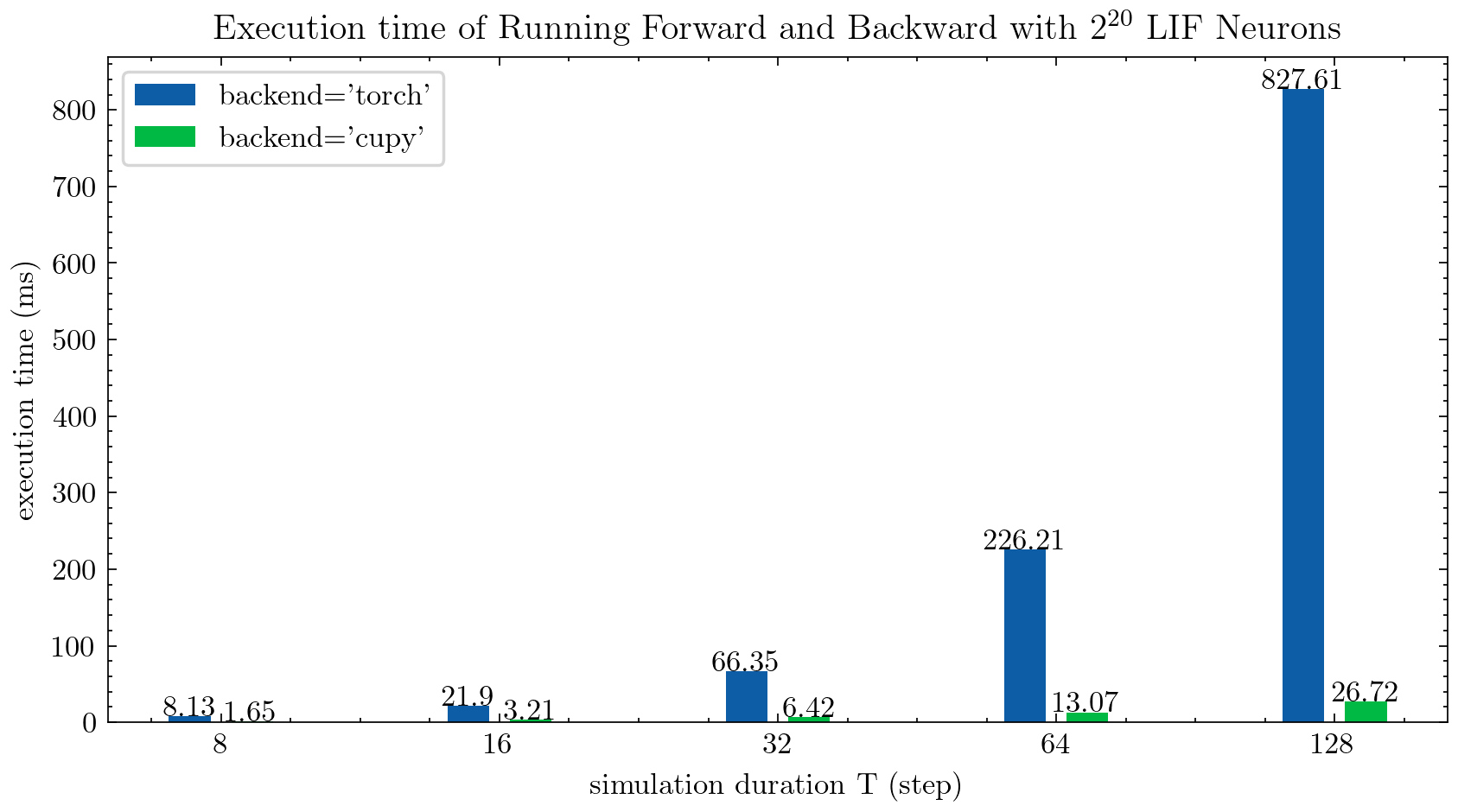
float16 est également fourni par le backend cupy et peut être utilisé dans l'entraînement automatique de précision mixte.
Pour utiliser le backend cupy , veuillez installer Cupy. Notez que le backend cupy ne prend en charge que GPU, tandis que le backend torch prend en charge le CPU et le GPU.
Aussi simple que l'utilisation de pytorch.
> >> net = nn . Sequential ( layer . Flatten (), layer . Linear ( 28 * 28 , 10 , bias = False ), neuron . LIFNode ( tau = tau ))
> >> net = net . to ( device ) # Can be CPU or CUDA devices SPIKINGJELLY comprend les ensembles de données neuromorphes suivants:
| Ensemble de données | Source |
|---|---|
| ASL-DV | Classification d'objets basée sur des graphiques pour la détection de vision neuromorphe |
| CIFAR10-DVS | CIFAR10-DVS: un ensemble de données d'événements pour la classification des objets |
| Geste DVS128 | Un système de reconnaissance des gestes à faible puissance et entièrement basé sur des événements |
| Es-imagenet | ES-IMagenet: un million de données de classification des flux d'événements pour les réseaux de neurones à pointe |
| Hardvs | Hardvs: Revisiter la reconnaissance d'activité humaine avec des capteurs de vision dynamique |
| N-Caltech101 | Convertir des ensembles de données d'image statiques en ensembles de données neuromorphes à l'aide de saccades |
| N-mnist | Convertir des ensembles de données d'image statiques en ensembles de données neuromorphes à l'aide de saccades |
| Geste de navigation | Reconnaissance des gestes basée sur des événements avec suppression de fond dynamique à l'aide de capacités de calcul du smartphone |
| Disponte des chiffres de Heidelberg (SHD) | Les ensembles de données de dopage Heidelberg pour l'évaluation systématique des réseaux de neurones à dopage |
| Dvs-lip | Caractéristiques spatio-temporelles multi-grains du réseau perçu pour la lecture des lèvres basée sur des événements |
Les utilisateurs peuvent utiliser à la fois les données de l'événement d'origine et les données de trame intégrées par SpikingJelly:
import torch
from torch . utils . data import DataLoader
from spikingjelly . datasets import pad_sequence_collate , padded_sequence_mask
from spikingjelly . datasets . dvs128_gesture import DVS128Gesture
# Set the root directory for the dataset
root_dir = 'D:/datasets/DVS128Gesture'
# Load event dataset
event_set = DVS128Gesture ( root_dir , train = True , data_type = 'event' )
event , label = event_set [ 0 ]
# Print the keys and their corresponding values in the event data
for k in event . keys ():
print ( k , event [ k ])
# t [80048267 80048277 80048278 ... 85092406 85092538 85092700]
# x [49 55 55 ... 60 85 45]
# y [82 92 92 ... 96 86 90]
# p [1 0 0 ... 1 0 0]
# label 0
# Load a dataset with fixed frame numbers
fixed_frames_number_set = DVS128Gesture ( root_dir , train = True , data_type = 'frame' , frames_number = 20 , split_by = 'number' )
# Randomly select two frames and print their shapes
rand_index = torch . randint ( low = 0 , high = fixed_frames_number_set . __len__ (), size = [ 2 ])
for i in rand_index :
frame , label = fixed_frames_number_set [ i ]
print ( f'frame[ { i } ].shape=[T, C, H, W]= { frame . shape } ' )
# frame[308].shape=[T, C, H, W]=(20, 2, 128, 128)
# frame[453].shape=[T, C, H, W]=(20, 2, 128, 128)
# Load a dataset with a fixed duration and print the shapes of the first 5 samples
fixed_duration_frame_set = DVS128Gesture ( root_dir , data_type = 'frame' , duration = 1000000 , train = True )
for i in range ( 5 ):
x , y = fixed_duration_frame_set [ i ]
print ( f'x[ { i } ].shape=[T, C, H, W]= { x . shape } ' )
# x[0].shape=[T, C, H, W]=(6, 2, 128, 128)
# x[1].shape=[T, C, H, W]=(6, 2, 128, 128)
# x[2].shape=[T, C, H, W]=(5, 2, 128, 128)
# x[3].shape=[T, C, H, W]=(5, 2, 128, 128)
# x[4].shape=[T, C, H, W]=(7, 2, 128, 128)
# Create a data loader for the fixed duration frame dataset and print the shapes and sequence lengths
train_data_loader = DataLoader ( fixed_duration_frame_set , collate_fn = pad_sequence_collate , batch_size = 5 )
for x , y , x_len in train_data_loader :
print ( f'x.shape=[N, T, C, H, W]= { tuple ( x . shape ) } ' )
print ( f'x_len= { x_len } ' )
mask = padded_sequence_mask ( x_len ) # mask.shape = [T, N]
print ( f'mask= n { mask . t (). int () } ' )
break
# x.shape=[N, T, C, H, W]=(5, 7, 2, 128, 128)
# x_len=tensor([6, 6, 5, 5, 7])
# mask=
# tensor([[1, 1, 1, 1, 1, 1, 0],
# [1, 1, 1, 1, 1, 1, 0],
# [1, 1, 1, 1, 1, 0, 0],
# [1, 1, 1, 1, 1, 0, 0],
# [1, 1, 1, 1, 1, 1, 1]], dtype=torch.int32)D'autres ensembles de données seront inclus dans le futur.
Si certains liens de téléchargement de certains ensembles de données ne sont pas disponibles pour certains utilisateurs, les utilisateurs peuvent télécharger à partir du miroir OpenI:
https://openi.pcl.ac.cn/openi/spikingjelly/datasets?type=0
Tous les ensembles de données enregistrés dans le miroir OpenI sont autorisés par leur licence ou l'accord de l'auteur.
SPIKINGJELLY fournit des tutoriels élaborés. Voici quelques tutoriels:
| Chiffre | Tutoriel |
|---|---|
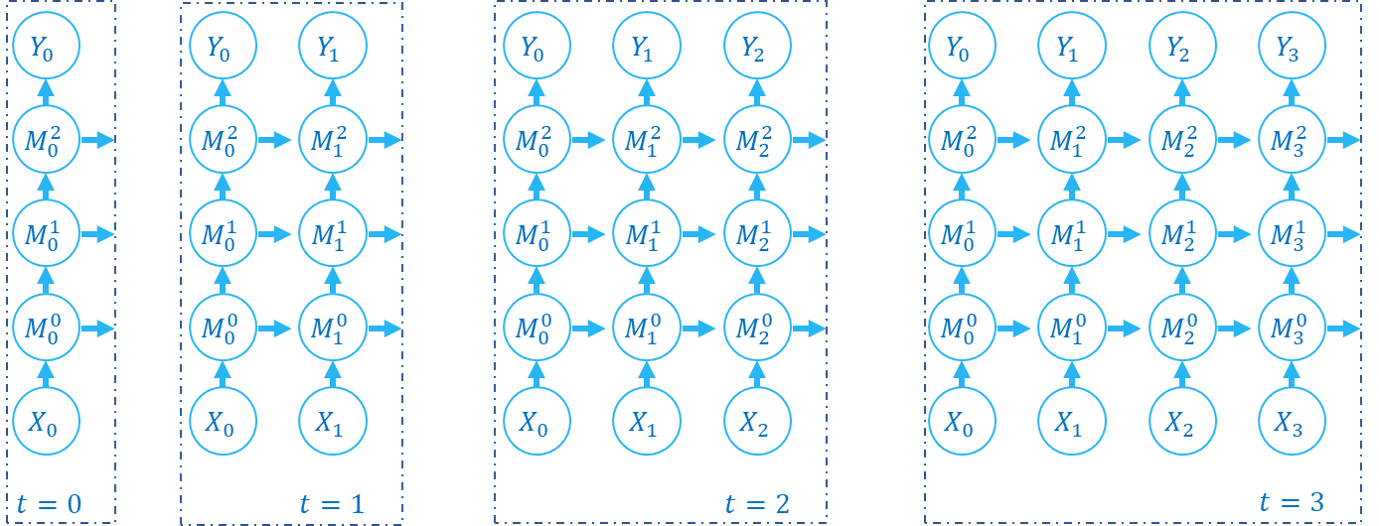 | Conception de base |
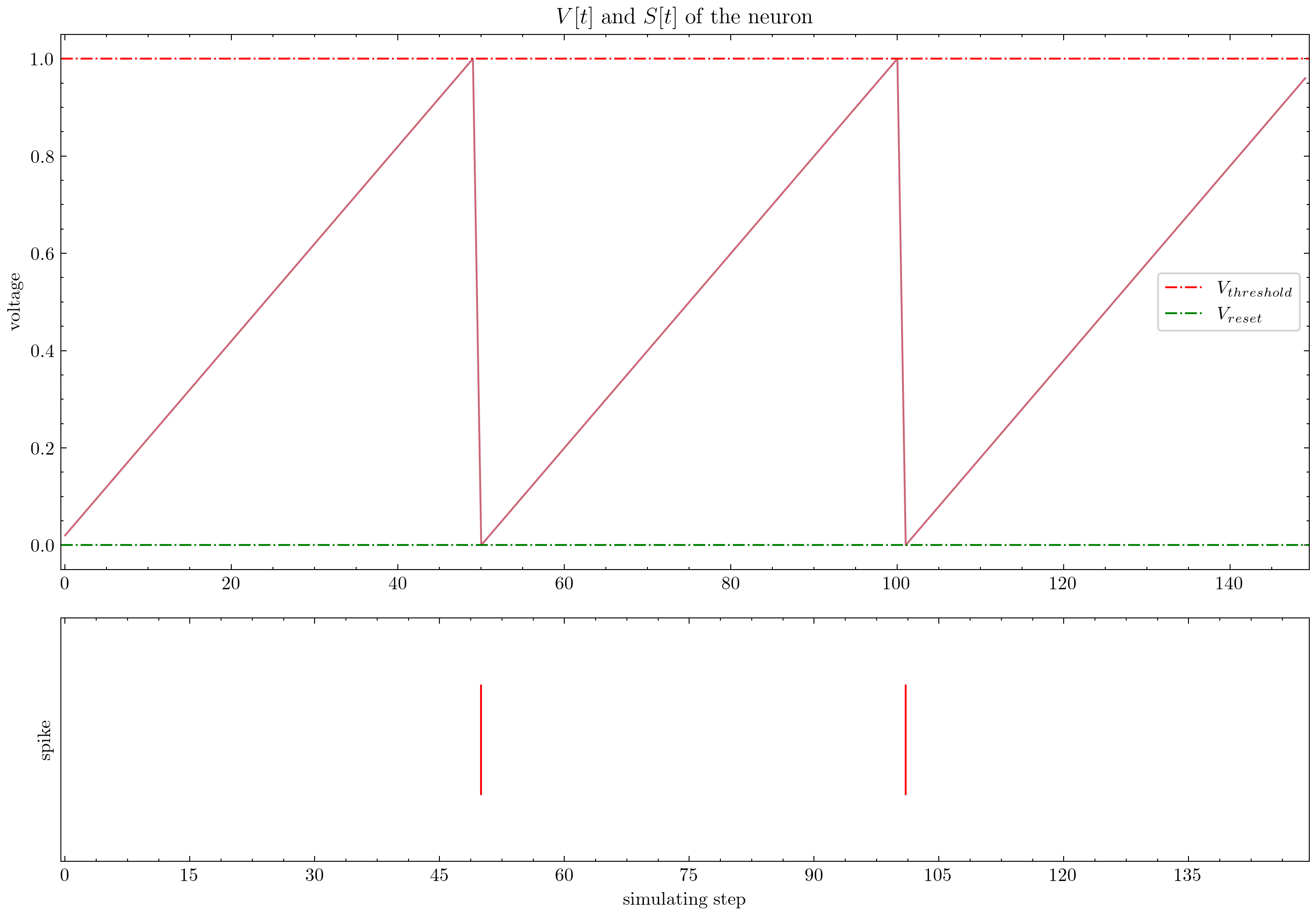 | Neurone |
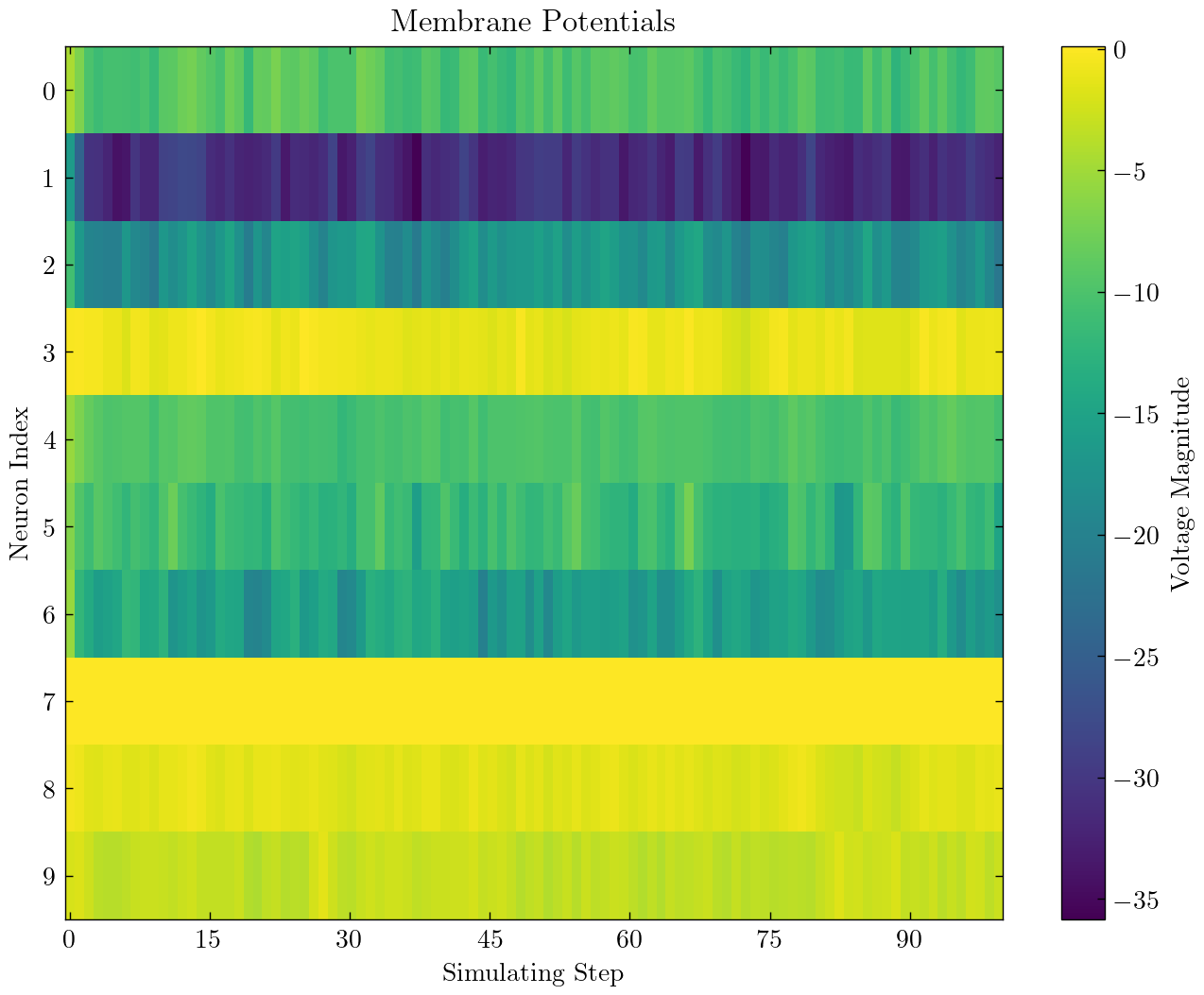 | SNN de couche unique entièrement connectée pour classer MNIST |
 | SNN convolutionnel pour classer FMNIST |
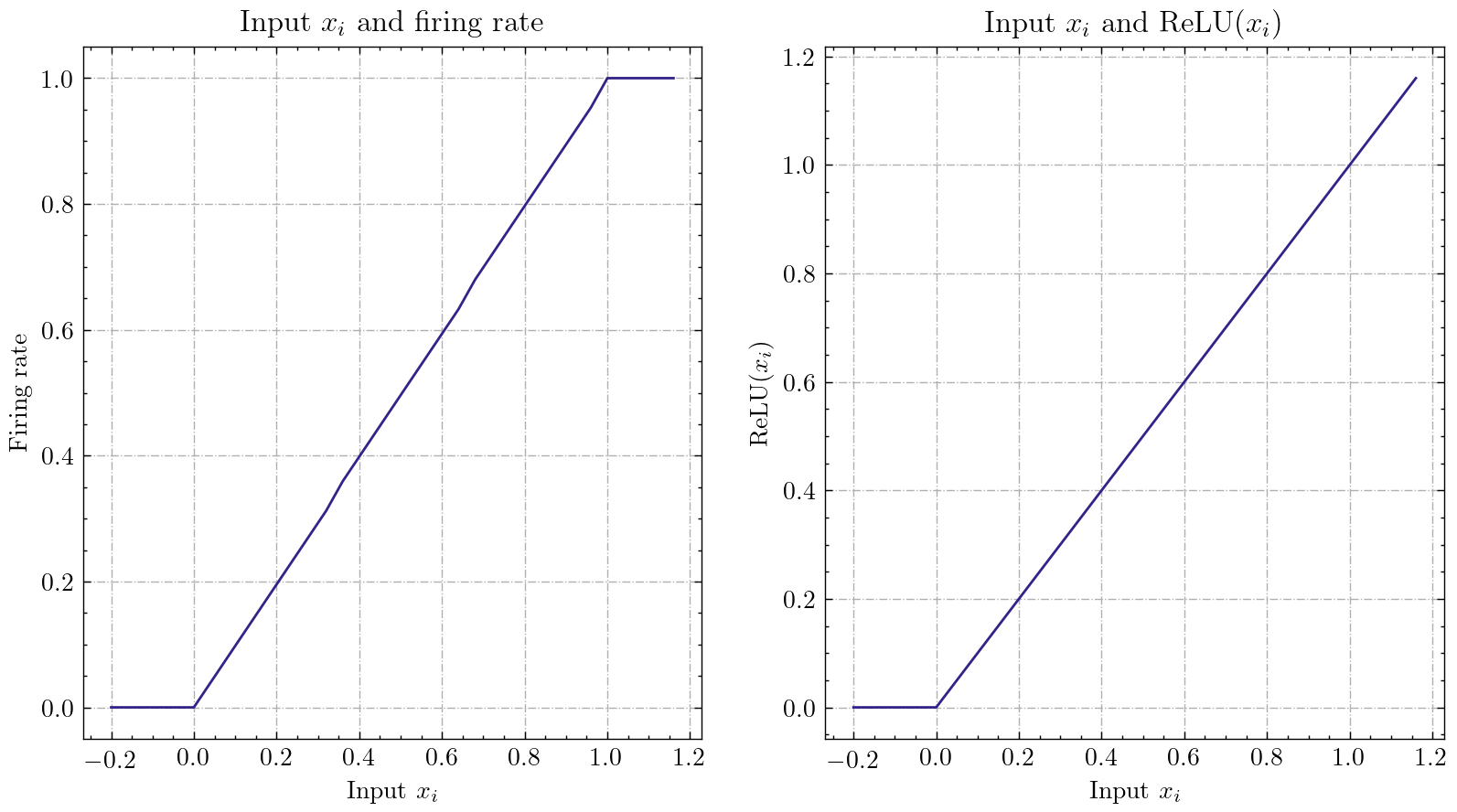 | Ann2snn |
 | Traitement des ensembles de données neuromorphes |
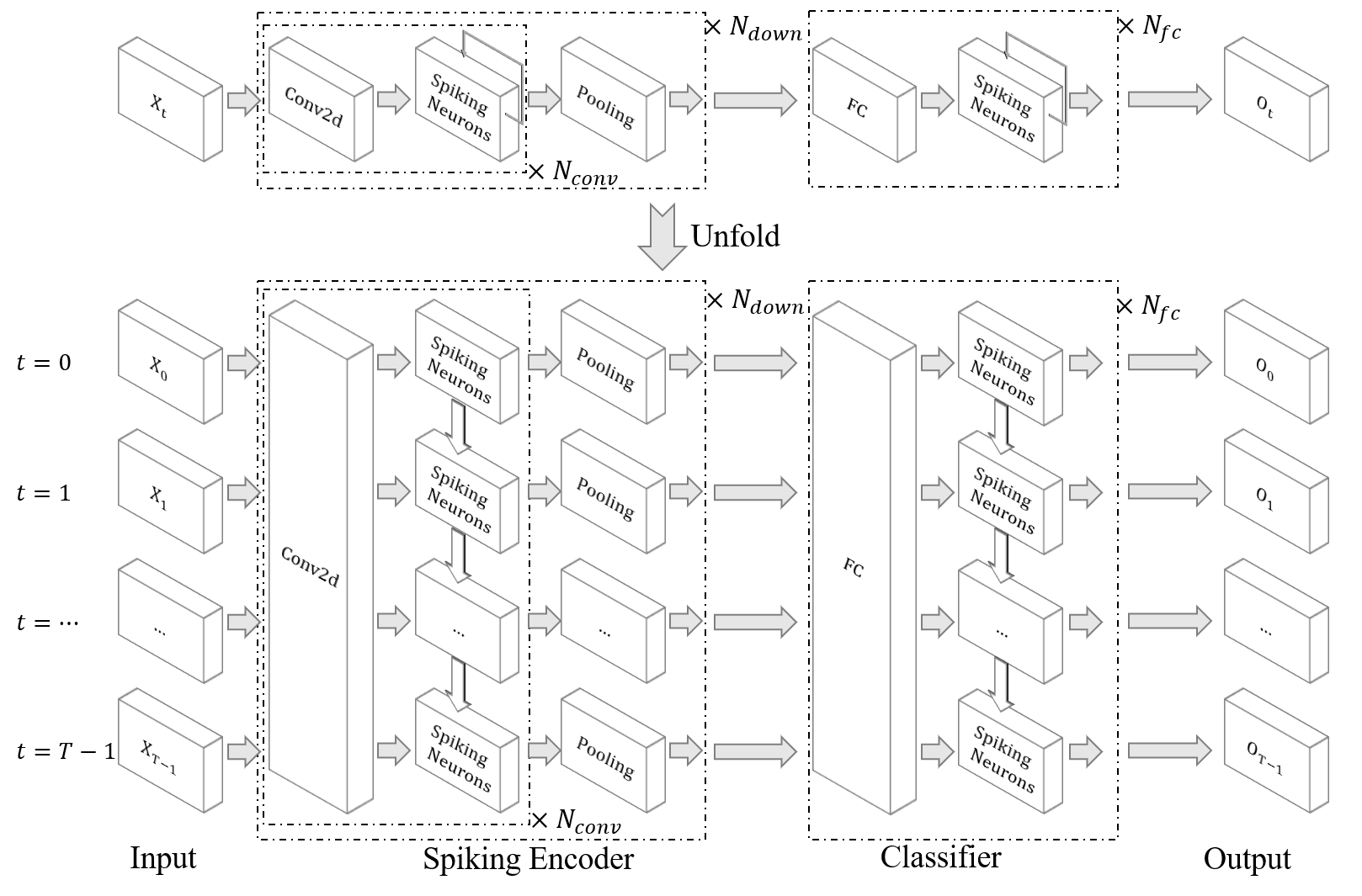 | Classifier le geste DVS |
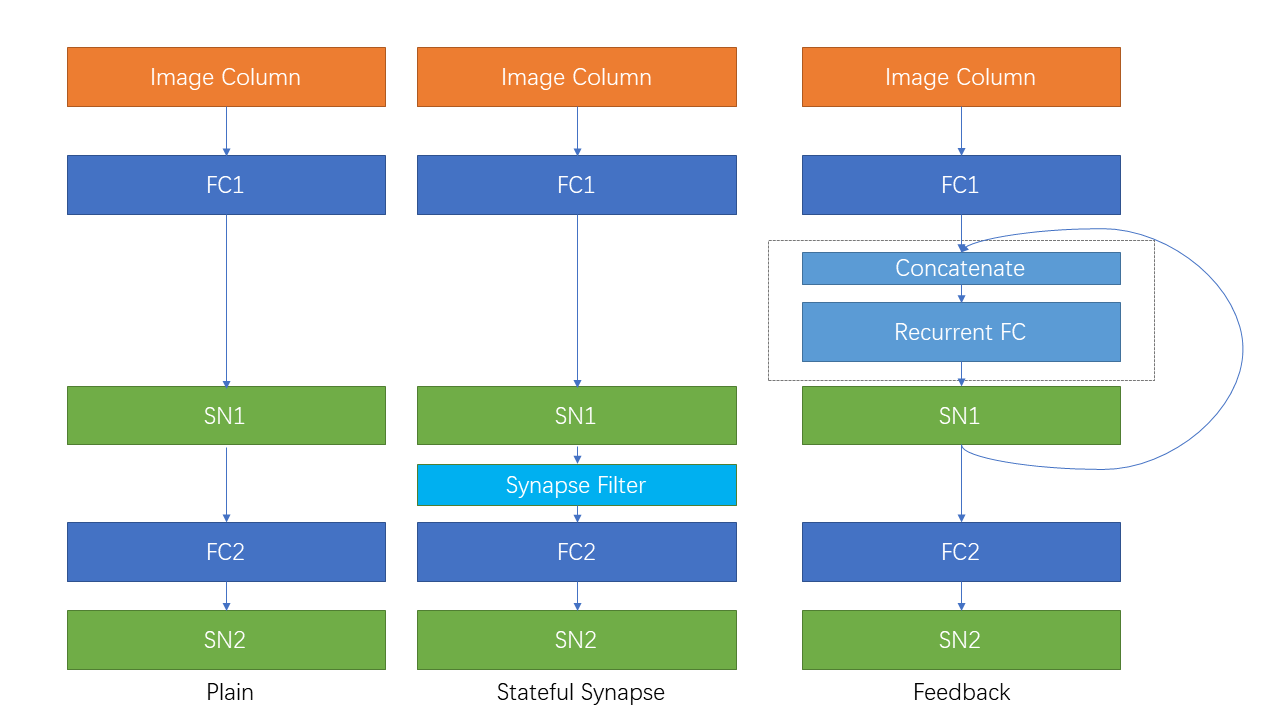 | Connexion récurrente et synapse avec état |
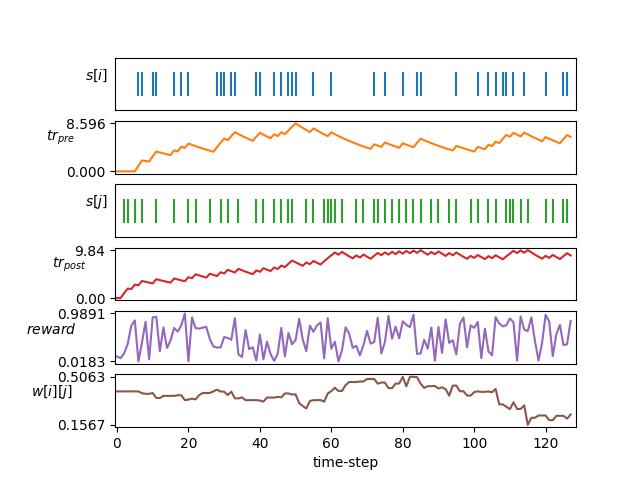 | Apprentissage du STDP |
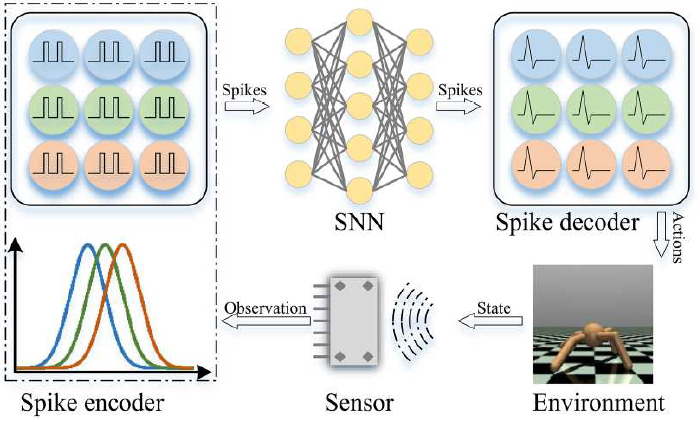 | Apprentissage du renforcement |
D'autres tutoriels qui ne sont pas répertoriés ici sont également disponibles dans le document https://spikingjelly.readthedocs.io.
Les publications utilisant SpikingJelly sont enregistrées dans des publications. Si vous utilisez SpikingJelly dans votre papier, vous pouvez également l'ajouter à ce tableau par demande de traction.
Si vous utilisez SPIKINGJELLY dans votre travail, veuillez le citer comme suit:
@article{
doi:10.1126/sciadv.adi1480,
author = {Wei Fang and Yanqi Chen and Jianhao Ding and Zhaofei Yu and Timothée Masquelier and Ding Chen and Liwei Huang and Huihui Zhou and Guoqi Li and Yonghong Tian },
title = {SpikingJelly: An open-source machine learning infrastructure platform for spike-based intelligence},
journal = {Science Advances},
volume = {9},
number = {40},
pages = {eadi1480},
year = {2023},
doi = {10.1126/sciadv.adi1480},
URL = {https://www.science.org/doi/abs/10.1126/sciadv.adi1480},
eprint = {https://www.science.org/doi/pdf/10.1126/sciadv.adi1480},
abstract = {Spiking neural networks (SNNs) aim to realize brain-inspired intelligence on neuromorphic chips with high energy efficiency by introducing neural dynamics and spike properties. As the emerging spiking deep learning paradigm attracts increasing interest, traditional programming frameworks cannot meet the demands of automatic differentiation, parallel computation acceleration, and high integration of processing neuromorphic datasets and deployment. In this work, we present the SpikingJelly framework to address the aforementioned dilemma. We contribute a full-stack toolkit for preprocessing neuromorphic datasets, building deep SNNs, optimizing their parameters, and deploying SNNs on neuromorphic chips. Compared to existing methods, the training of deep SNNs can be accelerated 11×, and the superior extensibility and flexibility of SpikingJelly enable users to accelerate custom models at low costs through multilevel inheritance and semiautomatic code generation. SpikingJelly paves the way for synthesizing truly energy-efficient SNN-based machine intelligence systems, which will enrich the ecology of neuromorphic computing. Motivation and introduction of the software framework SpikingJelly for spiking deep learning.}}
Vous pouvez lire les problèmes et résoudre les problèmes et les derniers plans de développement. Nous accueillons tous les utilisateurs à rejoindre la discussion des plans de développement, à résoudre les problèmes et à envoyer des demandes de traction.
Tous les documents API ne sont pas écrits en anglais et en chinois. Nous nous réjouissons des utilisateurs pour terminer la traduction (de l'anglais au chinois ou du chinois à l'anglais).
Multimedia Learning Group, Institute of Digital Media (NELVT), Peking University et Peng Cheng Laboratory sont les principaux développeurs de SpikingJelly.


La liste des développeurs peut être trouvée ici.


