spikingjelly
1.0.0
영어 | 中文 (중국어)
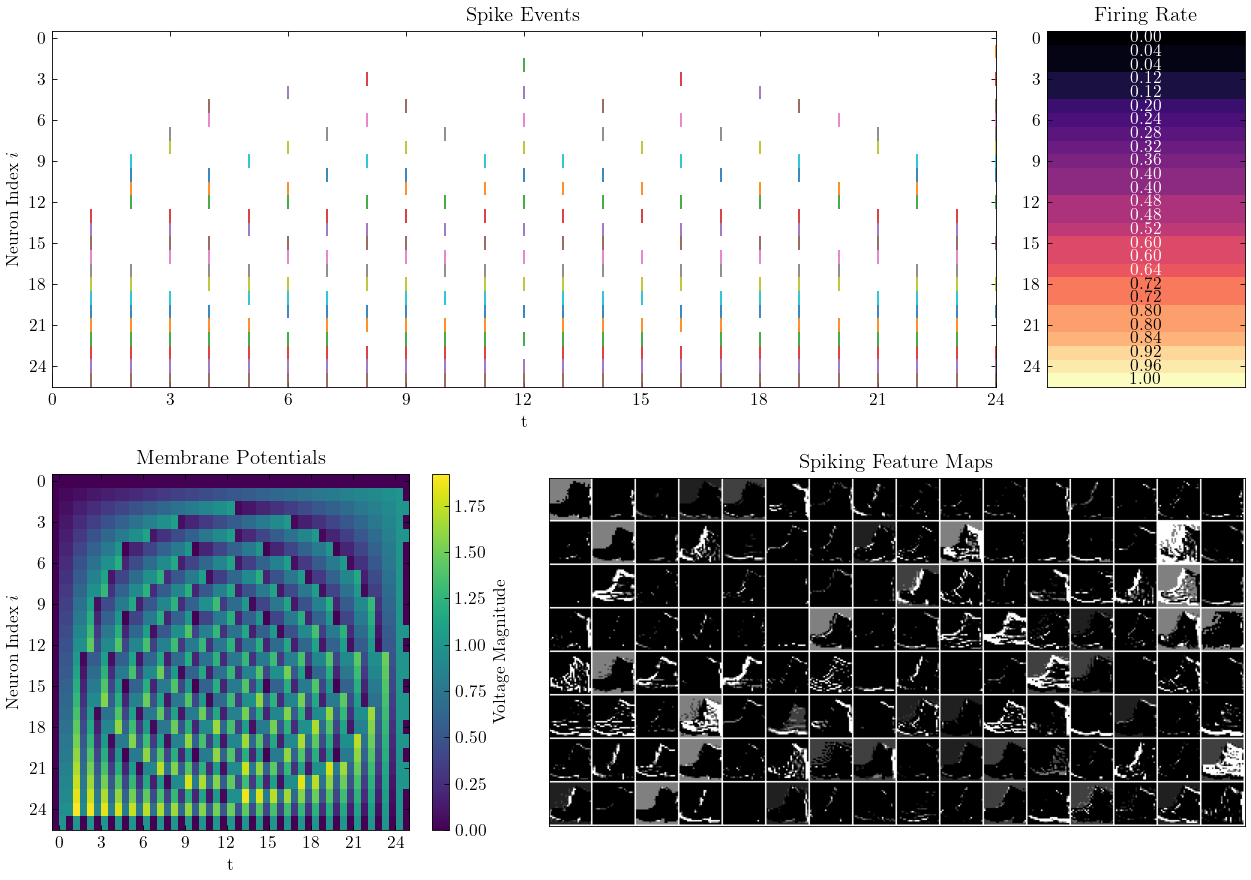
SpikingJelly는 Pytorch를 기반으로 한 SNN (Spiking Neural Network)을위한 오픈 소스 딥 러닝 프레임 워크입니다.
SpikingJelly의 문서는 영어와 중국어로 작성되었습니다 : https://spikingjelly.readthedocs.io.
Spikingjelly는 Pytorch를 기반으로합니다. SpikingJelly를 설치하기 전에 Pytorch를 설치했는지 확인하십시오.
버전 노트
홀수 버전 번호는 Github/Openi 저장소로 업데이트 된 개발 버전입니다. 짝수 버전 번호는 안정적인 버전이며 PYPI에서 사용할 수 있습니다.
기본 문서는 최신 개발 버전입니다. 안정적인 버전을 사용하는 경우 해당 버전에서 문서로 전환하는 것을 잊지 마십시오.
버전 0.0.0.0.14 에서 clock_driven 및 event_driven 포함한 모듈의 이름이 바뀌 었습니다. 이전 버전에서 튜토리얼 마이그레이션을 참조하십시오.
이전 버전의 SpikingJelly를 사용하는 경우 치명적인 버그가 발생할 수 있습니다. 자세한 내용은 릴리스와 함께 버그 기록을 참조하십시오.
다른 버전에 대한 문서 :
PYPI 에서 마지막 안정 버전을 설치하십시오 .
pip install spikingjelly소스 코드에서 최신 개발 버전을 설치하십시오 .
Github에서 :
git clone https://github.com/fangwei123456/spikingjelly.git
cd spikingjelly
python setup.py installOpeni에서 :
git clone https://openi.pcl.ac.cn/OpenI/spikingjelly.git
cd spikingjelly
python setup.py installSpikingJelly는 사용자 친화적입니다. Spikingjelly와 함께 SNN을 짓는 것은 Pytorch에서 Ann을 짓는 것만 큼 간단합니다.
nn . Sequential (
layer . Flatten (),
layer . Linear ( 28 * 28 , 10 , bias = False ),
neuron . LIFNode ( tau = tau , surrogate_function = surrogate . ATan ())
)Poisson Encoder가있는이 간단한 네트워크는 MNIST 테스트 데이터 세트에서 92% 정확도를 달성 할 수 있습니다. 자세한 내용은 튜토리얼을 참조하십시오. MNIST 분류에 대한 교육을 위해이 코드를 Python 터미널에서 실행할 수도 있습니다.
python - m spikingjelly . activation_based . examples . lif_fc_mnist - tau 2.0 - T 100 - device cuda : 0 - b 64 - epochs 100 - data - dir < PATH to MNIST > - amp - opt adam - lr 1e-3 - j 8 SpikingJelly는 비교적 일반적인 Ann-SNN 변환 인터페이스를 구현합니다. 사용자는 Pytorch를 통해 전환을 실현할 수 있습니다. 또한 사용자는 변환 모드를 사용자 정의 할 수 있습니다.
class ANN ( nn . Module ):
def __init__ ( self ):
super (). __init__ ()
self . network = nn . Sequential (
nn . Conv2d ( 1 , 32 , 3 , 1 ),
nn . BatchNorm2d ( 32 , eps = 1e-3 ),
nn . ReLU (),
nn . AvgPool2d ( 2 , 2 ),
nn . Conv2d ( 32 , 32 , 3 , 1 ),
nn . BatchNorm2d ( 32 , eps = 1e-3 ),
nn . ReLU (),
nn . AvgPool2d ( 2 , 2 ),
nn . Conv2d ( 32 , 32 , 3 , 1 ),
nn . BatchNorm2d ( 32 , eps = 1e-3 ),
nn . ReLU (),
nn . AvgPool2d ( 2 , 2 ),
nn . Flatten (),
nn . Linear ( 32 , 10 )
)
def forward ( self , x ):
x = self . network ( x )
return x아날로그 인코딩이있는이 간단한 네트워크는 MNIST 테스트 데이터 세트에서 변환 후 98.44% 정확도를 달성 할 수 있습니다. 자세한 내용은 튜토리얼을 읽으십시오. 변환 된 모델을 사용하여 MNIST 분류에 대한 교육을 위해이 코드를 Python 터미널에서 실행할 수도 있습니다.
> >> import spikingjelly . activation_based . ann2snn . examples . cnn_mnist as cnn_mnist
> >> cnn_mnist . main () SpikingJelly는 다중 단계 뉴런에 대해 두 가지 백엔드를 제공합니다. 사용자 친화적 인 torch 백엔드를 사용하여 쉽게 코딩하고 디버깅하고 cupy 백엔드를 사용하여 더 빠른 교육 속도를 사용할 수 있습니다.
다음 그림은 다중 단계 LIF 뉴런 ( float32 )의 두 개의 백엔드의 실행 시간을 비교합니다.
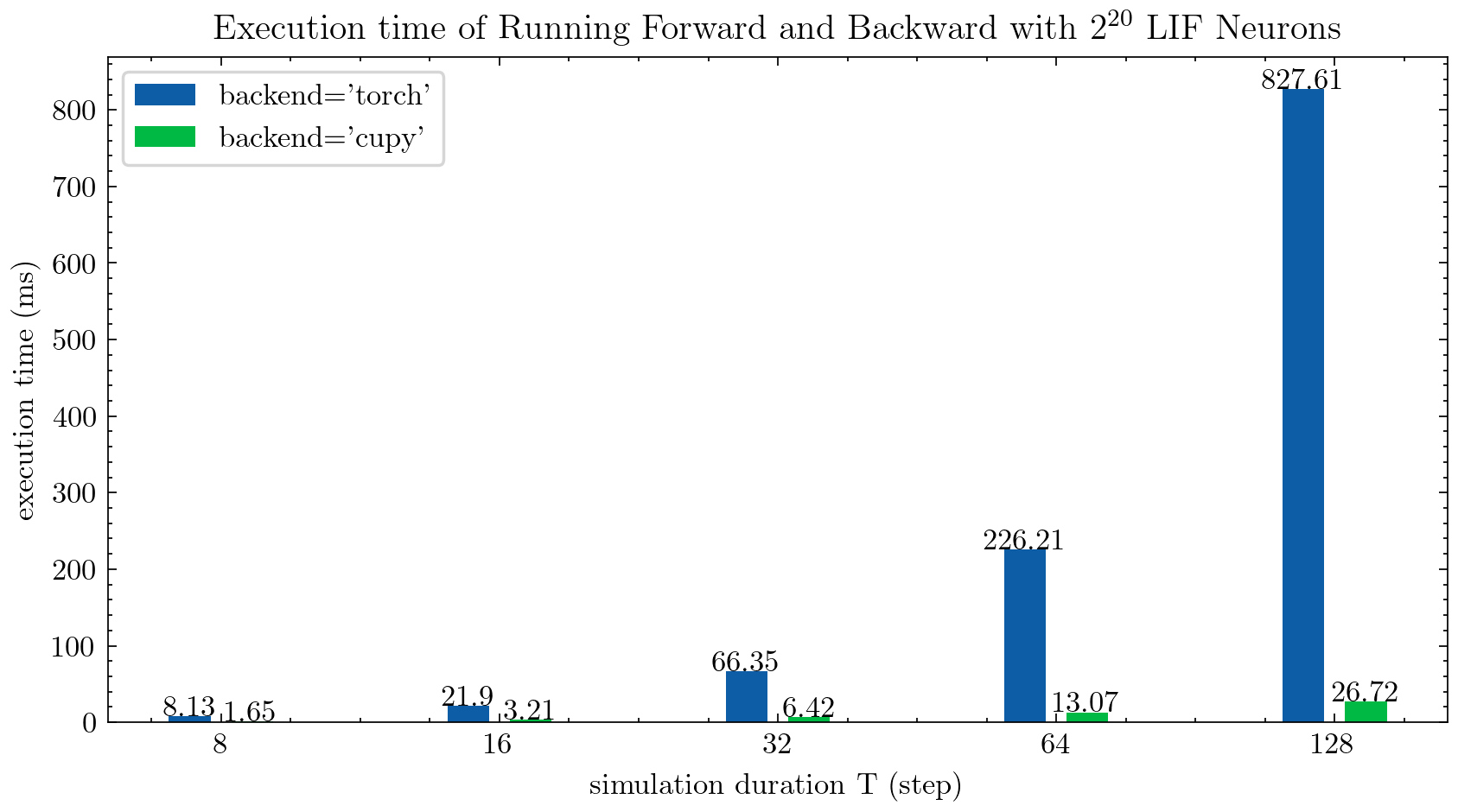
float16 cupy 백엔드에서도 제공되며 자동 혼합 정밀 훈련에 사용할 수 있습니다.
cupy 백엔드를 사용하려면 Cupy를 설치하십시오. cupy 백엔드는 GPU 만 지원하는 반면 torch 백엔드는 CPU 및 GPU를 모두 지원합니다.
Pytorch를 사용하는 것만 큼 간단합니다.
> >> net = nn . Sequential ( layer . Flatten (), layer . Linear ( 28 * 28 , 10 , bias = False ), neuron . LIFNode ( tau = tau ))
> >> net = net . to ( device ) # Can be CPU or CUDA devices SpikingJelly에는 다음과 같은 신경 형태 데이터 세트가 포함됩니다.
| 데이터 세트 | 원천 |
|---|---|
| ASL-DVS | 신경성 시력 감지를위한 그래프 기반 객체 분류 |
| CIFAR10-DVS | CIFAR10-DVS : 객체 분류를위한 이벤트 스트림 데이터 세트 |
| DVS128 제스처 | 저전력, 완전 이벤트 기반 제스처 인식 시스템 |
| ES-Imagenet | ES-Imagenet : 신경 네트워크 스파이킹을위한 백만 이벤트 스트림 분류 데이터 세트 |
| Hardvs | HardVS : 동적 시력 센서로 인간 활동 인식 재 방문 |
| N-Caltech101 | 정적 이미지 데이터 세트를 Saccade를 사용하여 스파이크 신경 형태 데이터 세트로 변환 |
| n-mnist | 정적 이미지 데이터 세트를 Saccade를 사용하여 스파이크 신경 형태 데이터 세트로 변환 |
| NAV 제스처 | 스마트 폰 계산 기능을 사용한 동적 배경 억제로 이벤트 기반 제스처 인식 |
| 스파이크 하이델베르그 숫자 (SHD) | 스파이크 신경망의 체계적인 평가를위한 Heidelberg 스파이 킹 데이터 세트 |
| DVS-LIP | 이벤트 기반 립 리딩을위한 다중 곡물 시공간 특징 인식 된 네트워크 |
사용자는 Origin 이벤트 데이터와 SpikingJelly가 통합 한 프레임 데이터를 모두 사용할 수 있습니다.
import torch
from torch . utils . data import DataLoader
from spikingjelly . datasets import pad_sequence_collate , padded_sequence_mask
from spikingjelly . datasets . dvs128_gesture import DVS128Gesture
# Set the root directory for the dataset
root_dir = 'D:/datasets/DVS128Gesture'
# Load event dataset
event_set = DVS128Gesture ( root_dir , train = True , data_type = 'event' )
event , label = event_set [ 0 ]
# Print the keys and their corresponding values in the event data
for k in event . keys ():
print ( k , event [ k ])
# t [80048267 80048277 80048278 ... 85092406 85092538 85092700]
# x [49 55 55 ... 60 85 45]
# y [82 92 92 ... 96 86 90]
# p [1 0 0 ... 1 0 0]
# label 0
# Load a dataset with fixed frame numbers
fixed_frames_number_set = DVS128Gesture ( root_dir , train = True , data_type = 'frame' , frames_number = 20 , split_by = 'number' )
# Randomly select two frames and print their shapes
rand_index = torch . randint ( low = 0 , high = fixed_frames_number_set . __len__ (), size = [ 2 ])
for i in rand_index :
frame , label = fixed_frames_number_set [ i ]
print ( f'frame[ { i } ].shape=[T, C, H, W]= { frame . shape } ' )
# frame[308].shape=[T, C, H, W]=(20, 2, 128, 128)
# frame[453].shape=[T, C, H, W]=(20, 2, 128, 128)
# Load a dataset with a fixed duration and print the shapes of the first 5 samples
fixed_duration_frame_set = DVS128Gesture ( root_dir , data_type = 'frame' , duration = 1000000 , train = True )
for i in range ( 5 ):
x , y = fixed_duration_frame_set [ i ]
print ( f'x[ { i } ].shape=[T, C, H, W]= { x . shape } ' )
# x[0].shape=[T, C, H, W]=(6, 2, 128, 128)
# x[1].shape=[T, C, H, W]=(6, 2, 128, 128)
# x[2].shape=[T, C, H, W]=(5, 2, 128, 128)
# x[3].shape=[T, C, H, W]=(5, 2, 128, 128)
# x[4].shape=[T, C, H, W]=(7, 2, 128, 128)
# Create a data loader for the fixed duration frame dataset and print the shapes and sequence lengths
train_data_loader = DataLoader ( fixed_duration_frame_set , collate_fn = pad_sequence_collate , batch_size = 5 )
for x , y , x_len in train_data_loader :
print ( f'x.shape=[N, T, C, H, W]= { tuple ( x . shape ) } ' )
print ( f'x_len= { x_len } ' )
mask = padded_sequence_mask ( x_len ) # mask.shape = [T, N]
print ( f'mask= n { mask . t (). int () } ' )
break
# x.shape=[N, T, C, H, W]=(5, 7, 2, 128, 128)
# x_len=tensor([6, 6, 5, 5, 7])
# mask=
# tensor([[1, 1, 1, 1, 1, 1, 0],
# [1, 1, 1, 1, 1, 1, 0],
# [1, 1, 1, 1, 1, 0, 0],
# [1, 1, 1, 1, 1, 0, 0],
# [1, 1, 1, 1, 1, 1, 1]], dtype=torch.int32)앞으로 더 많은 데이터 세트가 포함될 것입니다.
일부 사용자가 일부 데이터 세트의 다운로드 링크를 사용할 수없는 경우 사용자는 Openi 미러에서 다운로드 할 수 있습니다.
https://openi.pcl.ac.cn/openi/spikingjelly/datasets?type=0
Openi 미러에 저장된 모든 데이터 세트는 라이센스 또는 저자의 계약에 의해 허용됩니다.
SpikingJelly는 정교한 자습서를 제공합니다. 몇 가지 튜토리얼은 다음과 같습니다.
| 수치 | 지도 시간 |
|---|---|
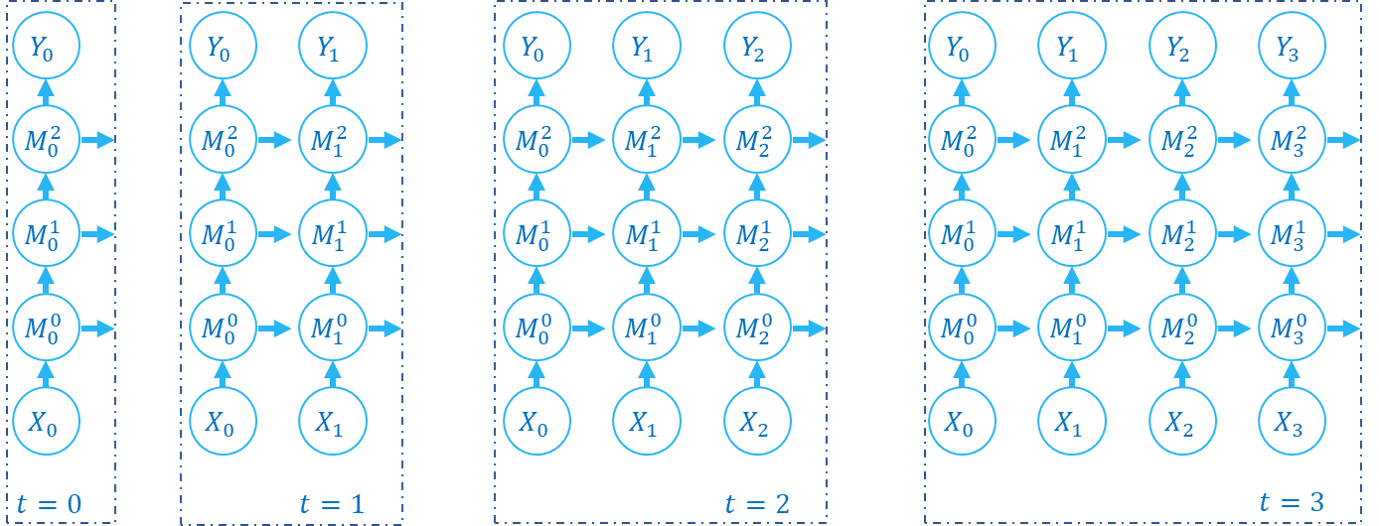 | 기본 개념 |
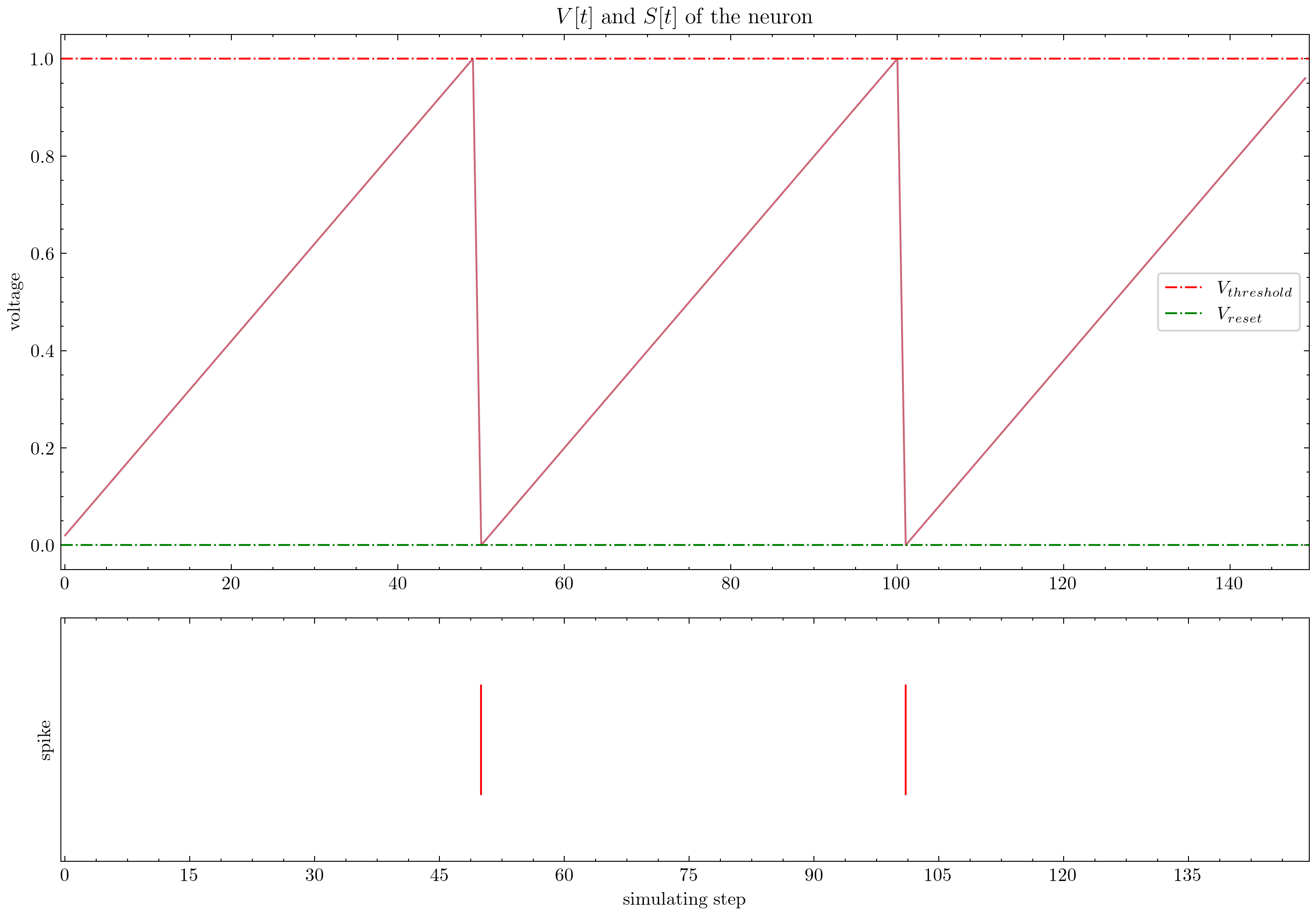 | 뉴런 |
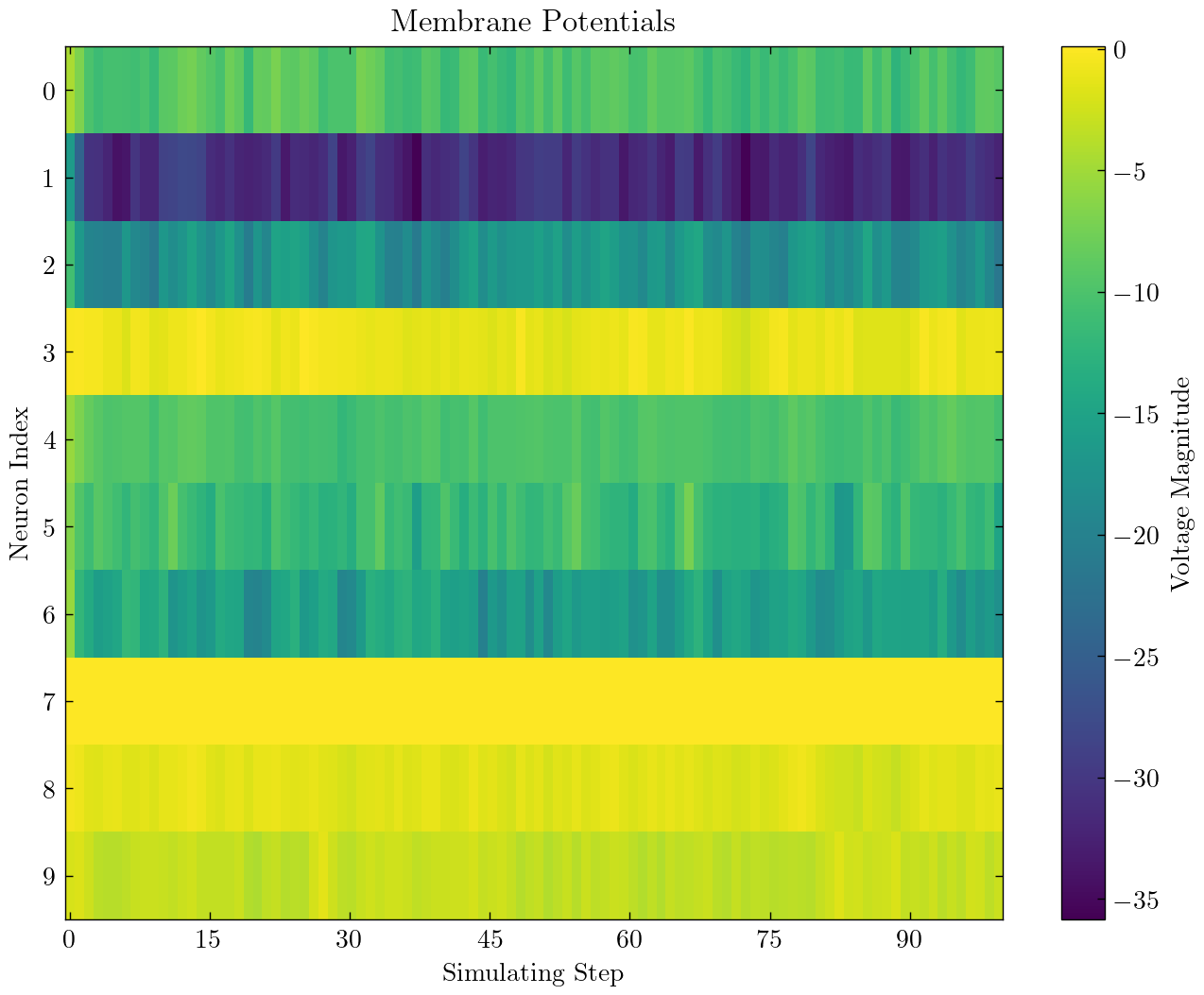 | MNIST를 분류하기 위해 단일 완전히 연결된 층 SNN |
 | fmnist를 분류하기위한 Convolutional SNN |
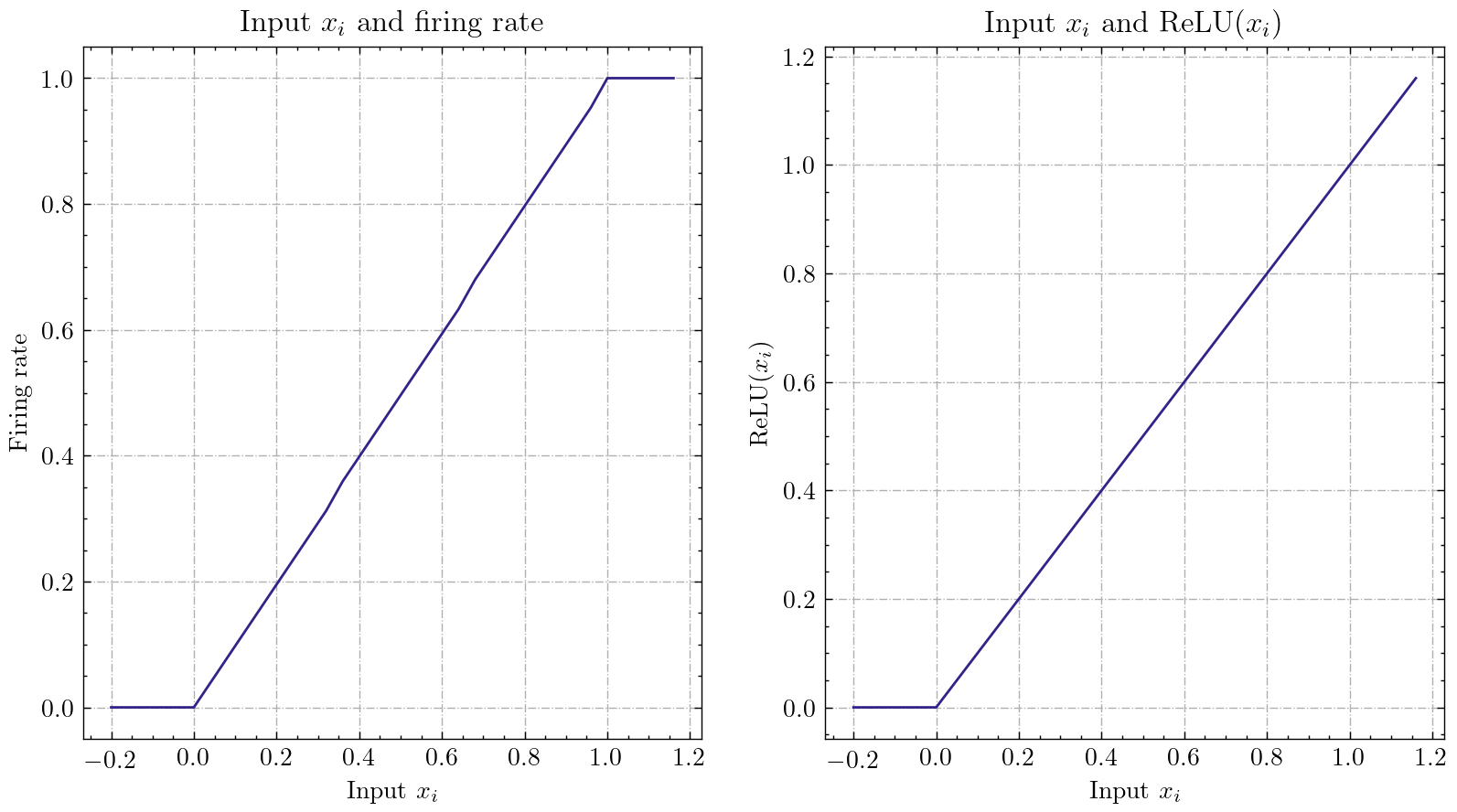 | Ann2Snn |
 | 신경 형성 데이터 세트 처리 |
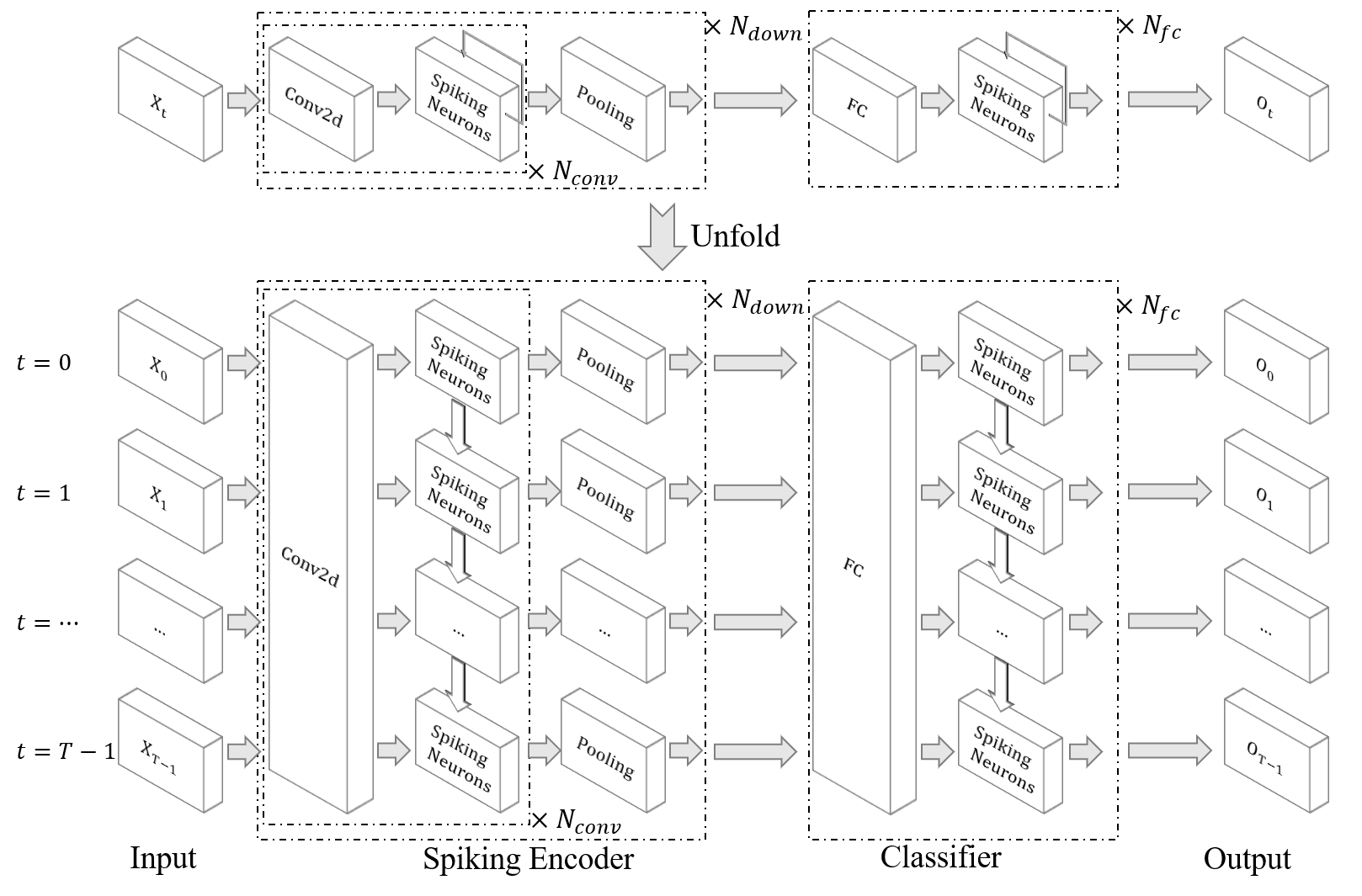 | DVS 제스처를 분류하십시오 |
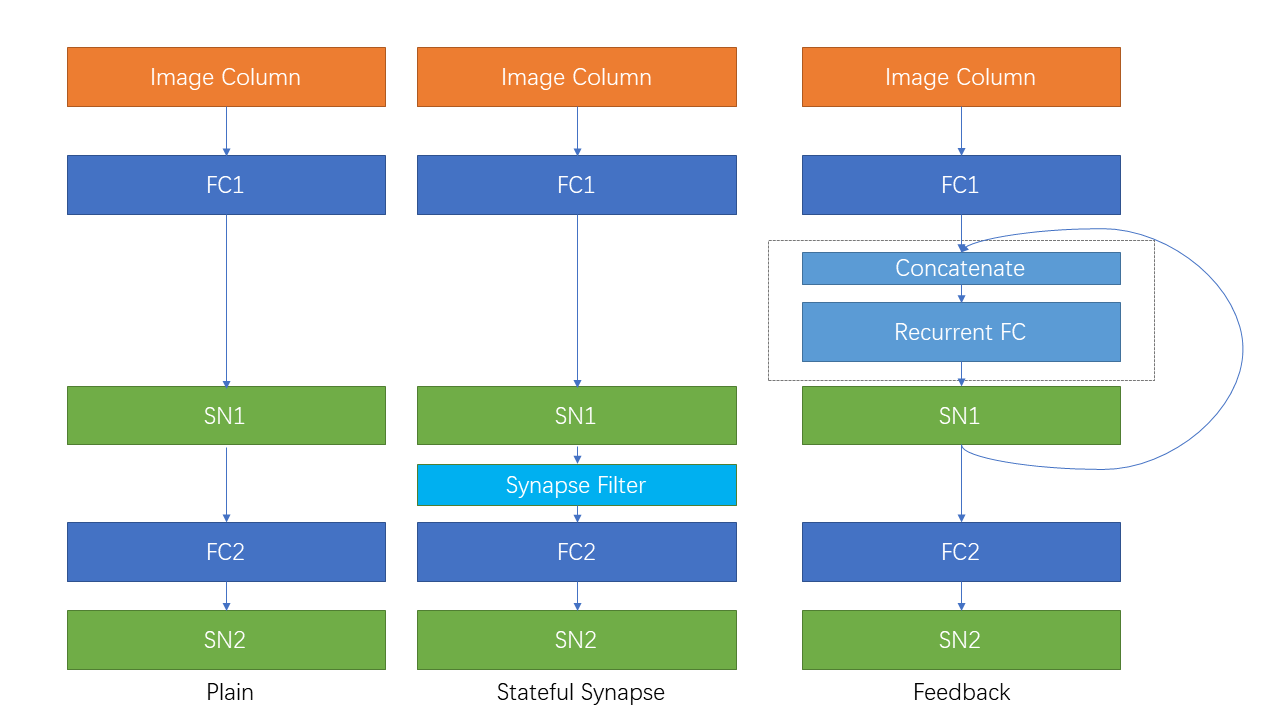 | 반복 연결 및 상태가 많은 시냅스 |
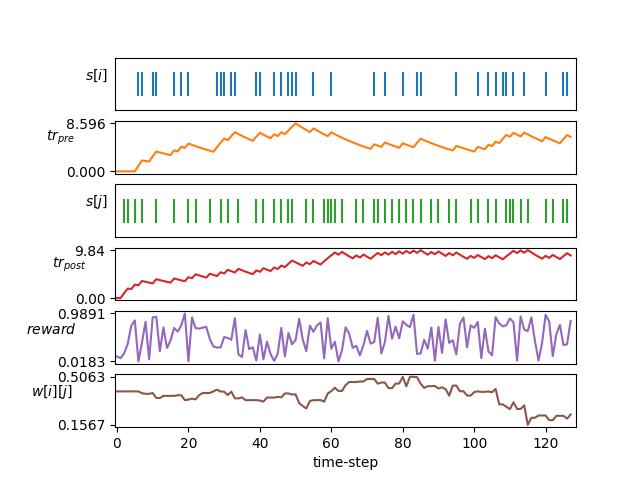 | STDP 학습 |
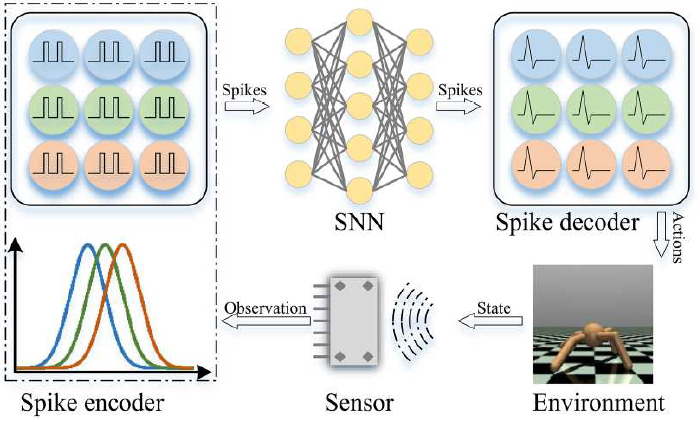 | 강화 학습 |
여기에 나열되지 않은 다른 튜토리얼은 문서 https://spikingjelly.readthedocs.io에서도 제공됩니다.
SpikingJelly를 사용한 출판물은 출판물에 기록됩니다. 종이에 SpikingJelly를 사용하는 경우 풀 요청 으로이 테이블에 추가 할 수도 있습니다.
작업에서 SpikingJelly를 사용하는 경우 다음과 같이 인용하십시오.
@article{
doi:10.1126/sciadv.adi1480,
author = {Wei Fang and Yanqi Chen and Jianhao Ding and Zhaofei Yu and Timothée Masquelier and Ding Chen and Liwei Huang and Huihui Zhou and Guoqi Li and Yonghong Tian },
title = {SpikingJelly: An open-source machine learning infrastructure platform for spike-based intelligence},
journal = {Science Advances},
volume = {9},
number = {40},
pages = {eadi1480},
year = {2023},
doi = {10.1126/sciadv.adi1480},
URL = {https://www.science.org/doi/abs/10.1126/sciadv.adi1480},
eprint = {https://www.science.org/doi/pdf/10.1126/sciadv.adi1480},
abstract = {Spiking neural networks (SNNs) aim to realize brain-inspired intelligence on neuromorphic chips with high energy efficiency by introducing neural dynamics and spike properties. As the emerging spiking deep learning paradigm attracts increasing interest, traditional programming frameworks cannot meet the demands of automatic differentiation, parallel computation acceleration, and high integration of processing neuromorphic datasets and deployment. In this work, we present the SpikingJelly framework to address the aforementioned dilemma. We contribute a full-stack toolkit for preprocessing neuromorphic datasets, building deep SNNs, optimizing their parameters, and deploying SNNs on neuromorphic chips. Compared to existing methods, the training of deep SNNs can be accelerated 11×, and the superior extensibility and flexibility of SpikingJelly enable users to accelerate custom models at low costs through multilevel inheritance and semiautomatic code generation. SpikingJelly paves the way for synthesizing truly energy-efficient SNN-based machine intelligence systems, which will enrich the ecology of neuromorphic computing. Motivation and introduction of the software framework SpikingJelly for spiking deep learning.}}
문제를 읽고 문제를 해결하고 최신 개발 계획을 세울 수 있습니다. 모든 사용자가 개발 계획에 대한 토론에 참여하고 문제를 해결하며 풀 요청을 보내도록 환영합니다.
모든 API 문서가 영어와 중국어로 작성된 것은 아닙니다. 우리는 사용자가 번역을 완료하도록 환영합니다 (영어에서 중국어, 중국어에서 영어로).
멀티미디어 학습 그룹, NELVT (Institute of Digital Media), Peking University 및 Peng Cheng Laboratory가 Spikingjelly의 주요 개발자입니다.


개발자 목록은 여기에서 찾을 수 있습니다.


