org ai
1.0.0
emacs org模式的次要模式,可访问生成AI模型。当前支持的是
在组织内部的缓冲区内您可以
注意:要使用OpenAI API,您需要一个OpenAI帐户,并且需要获得API令牌。据我所知,当前免费层的使用限制使您遥遥无期。
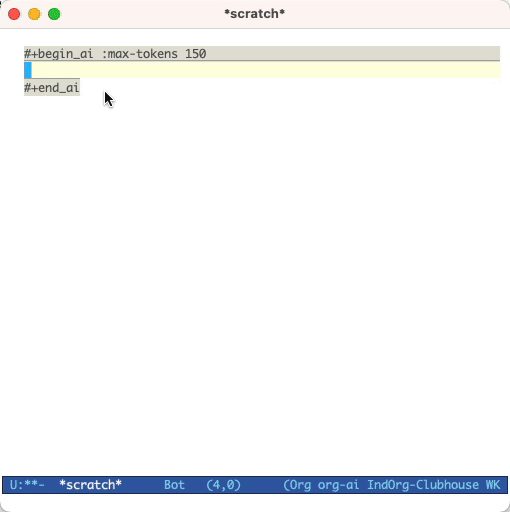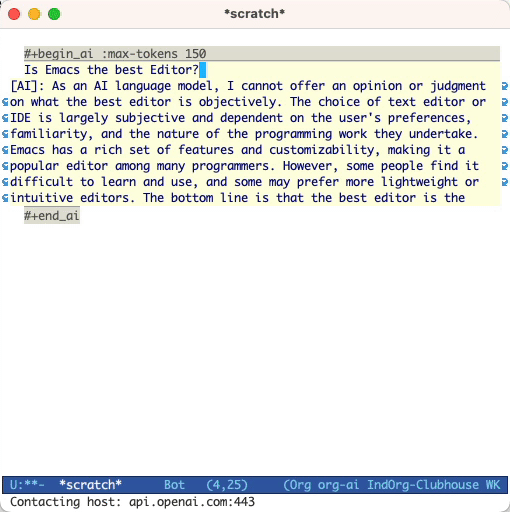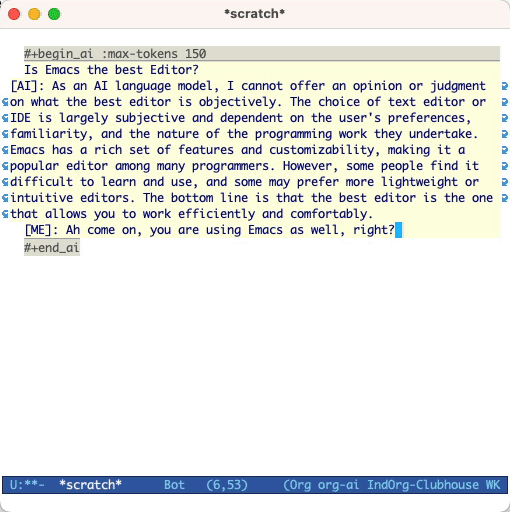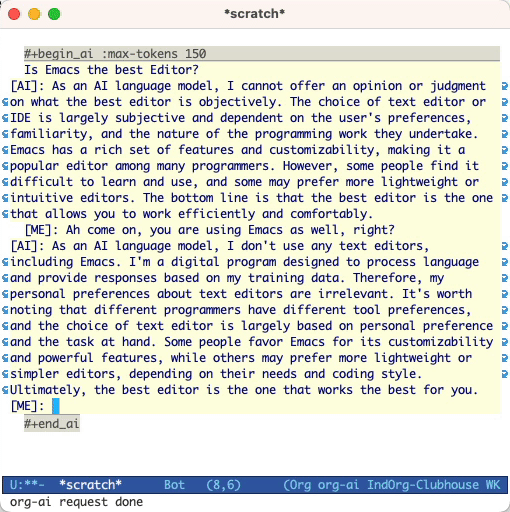
#+begin_ai...#+end_ai特殊块 #+begin_ai
Is Emacs the greatest editor?
#+end_ai
您可以继续键入并按Cc Cc来创建对话。 Cg将中断运行的请求。
使用:image关键字生成图像。默认情况下,这使用DALL·E-3。
#+begin_ai :image :size 1024x1024
Hyper realistic sci-fi rendering of super complicated technical machine.
#+end_ai
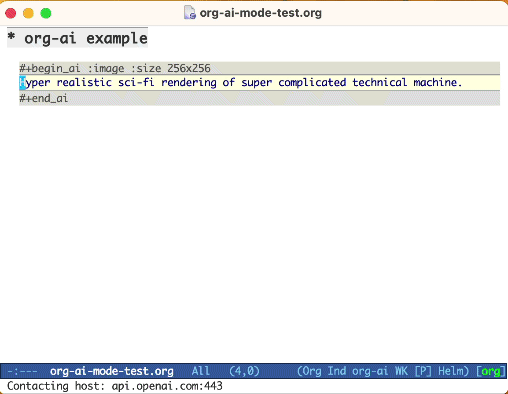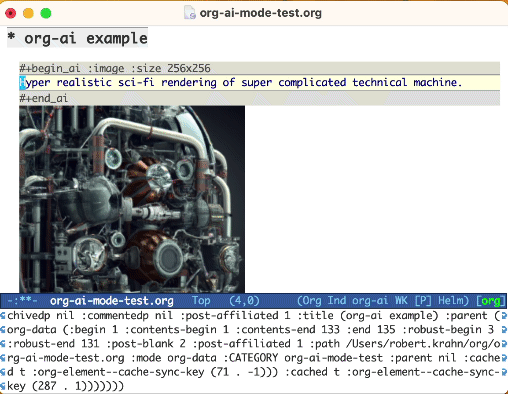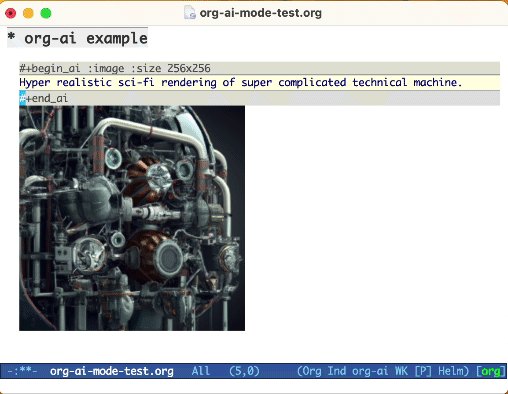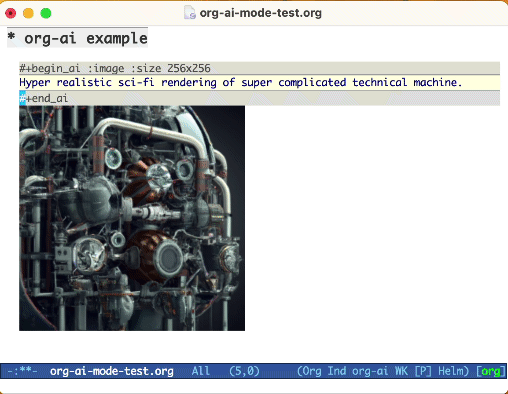
您可以使用以下关键字来控制图像生成:
:size <width>x<height> - 要生成的图像的大小(默认:1024x1024):model <model> - 要使用的模型(默认: "dall-e-3" ):quality <quality> - 图像的质量(选择: hd , standard ):style <style> - 使用的样式(选择: vivid , natural )(有关这些设置的更多信息,请参见此OpenAI博客文章。
您可以使用自customize-variable变量的这些变量自定义默认值,也可以通过在配置中设置它们:
( setq org-ai-image-model " dall-e-3 " )
( setq org-ai-image-default-size " 1792x1024 " )
( setq org-ai-image-default-count 2 )
( setq org-ai-image-default-style 'vivid )
( setq org-ai-image-default-quality 'hd )
( setq org-ai-image-directory ( expand-file-name " org-ai-images/ " org-directory))
#+begin_ai...#+end_ai特殊块与Org-Babel类似,这些障碍物划定了AI模型的输入(以及ChatGpt的输出)。您可以将其用于AI聊天,文本完成和文本 - >图像生成。有关更多信息,请参见下面的选项。
创建一个像
#+begin_ai
Is Emacs the greatest editor?
#+end_ai
并按Cc Cc 。聊天输入将显示内联,一旦响应完成,您就可以输入回复等等。请参阅下面的演示。您可以在AI请求运行以取消它时按Cg 。
您还可以修改系统提示和所使用的其他参数。在用户的输入之前注入系统提示,并以某种样式的方式“ primes”“素数”。例如,您可以做:
#+begin_ai :max-tokens 250
[SYS]: Act as if you are a powerful medival king.
[ME]: What will you eat today?
#+end_ai
这将导致API有效载荷
{
"messages" : [
{
"role" : " system " ,
"content" : " Act as if you are a powerful medival king. "
},
{
"role" : " user " ,
"content" : " What will you eat today? "
}
],
"model" : " gpt-4o-mini " ,
"stream" : true ,
"max_tokens" : 250 ,
"temperature" : 1.2
}有关一些及时的想法,请参见例如很棒的chatgpt提示。
使用:image标志生成图像时,图像将出现在AI块内联的下方。图像将在org-ai-image-directory中存储(以及它们的提示),默认为~/org/org-ai-images/ 。
您也可以使用语音输入来转录输入。按Cc r供org-ai-talk-capture-in-org开始录制。请注意,这将需要您设置语音识别(请参见下文)。可以使用org-ai-talk-output-enable启用语音输出。
在一个#+begin_ai...#+end_ai您可以修改并使用以下命令选择聊天部分:
Cc <backspace> ( org-ai-kill-region-at-point )删除点下的聊天部分。org-ai-mark-region-at-point将在点标记该区域。org-ai-mark-last-region将标志着最后一个聊天部分。 要应用于#+begin_ai ...块在_ai之后添加语言主要模式名称。例如#+begin_ai markdown 。特别是对于降压,要在Backticks中正确强调代码,您可以设置(setq markdown-fontify-code-blocks-natively t) 。确保还安装了Markdown-Mode软件包。感谢@tavisrudd的这个技巧!
默认情况下启用了此行为,以使互动更像聊天。当您阅读时出现长输出和缓冲卷轴时,这可能会很烦人。因此,您可以通过以下方式禁用此功能:
( setq org-ai-jump-to-end-of-block nil )set (setq org-ai-auto-fill t)以“填充”(根据fill-column自动包裹线)。基本上像auto-fill-mode但适用于AI。
#+begin_ai...#+end_ai块可以采用以下选项。
默认情况下,AI块的内容被解释为chatgpt的消息。以下文本[ME]:与用户关联,文本下面的[AI]:与模型的响应相关联。您可以选择地使用[SYS]: <behavior>输入来启动模型的块(请参见下面的org-ai-default-chat-system-prompt )。
:max-tokens number - 要生成的最大令牌数(默认值:nil,使用OpenAI的默认值):temperature number - 模型的温度(默认:1):top-p number - 模型的top_p(默认:1):frequency-penalty number - 模型的频率惩罚(默认值:0):presence-penalty - 模型的存在惩罚(默认:0):sys-everywhere重复每个用户消息的系统提示(默认:nil)如果您对同一主题和设置(系统提示,温度等)有很多不同的对话线程,并且您不想重复所有选项,则可以设置ORG文件范围属性或使用属性创建一个org标题抽屉,使得所有#+begin_ai...#+end_ai块下方都将继承设置。
示例:
* Emacs (multiple conversations re emacs continue in this subtree)
:PROPERTIES:
:SYS: You are a emacs expert. You can help me by answering my questions. You can also ask me questions to clarify my intention.
:temperature: 0.5
:model: gpt-4o-mini
:END:
** Web programming via elisp
#+begin_ai
How to call a REST API and parse its JSON response?
#+end_ai
** Other emacs tasks
#+begin_ai...#+end_ai
* Python (multiple conversations re python continue in this subtree)
:PROPERTIES:
:SYS: You are a python programmer. Respond to the task with detailed step by step instructions and code.
:temperature: 0.1
:model: gpt-4
:END:
** Learning QUIC
#+begin_ai
How to setup a webserver with http3 support?
#+end_ai
** Other python tasks
#+begin_ai...#+end_ai
以下自定义变量可用于配置聊天:
org-ai-default-chat-model (默认: "gpt-4o-mini" )org-ai-default-max-tokens响应应该多长时间。目前不能超过4096。如果此值太小,则可能会切断答案(默认:nil)org-ai-default-chat-system-prompt如何“启用”模型。这是在用户输入之前注入的提示。 (默认: "You are a helpful assistant inside Emacs." )org-ai-default-inject-sys-prompt-for-all-messages dether dether以重复每个用户消息的系统提示。有时,该模型会“忘记”其底漆。这可以帮助提醒它。 (默认: nil ) 当您在AI块中添加一个:image选项时,该提示将用于图像生成。
:image - 生成图像而不是文本:size - 要生成的图像的大小(默认:256x256,可以是512x512或1024x1024):n要生成的图像数(默认:1)以下自定义变量可用于配置图像生成:
org-ai-image-directory在哪里存储生成的图像(默认值: ~/org/org-ai-images/ ) 类似于dall-e,但使用
#+begin_ai :sd-image
<PROMPT>
#+end_ai
您可以通过标记#+名称的组织图像并将其引用以下方式来运行IMG2IMG,并从您的org-ai块中引用image-ref。
#+begin_ai :sd-image :image-ref label1
forest, Gogh style
#+end_ai
mx org-ai-sd-clip通过剪辑审讯器猜测上一个图像在org模式上的提示,并将其保存在杀戮环中。
MX org-ai-sd-deepdanbooru通过DeepDanbooru询问器猜测上一个图像的提示,并将其保存在杀戮环中。
为了要求使用Oobabooga/text-generation-webui提供的本地模型完成,请浏览下面描述的设置步骤
然后启动API服务器:
cd ~ /.emacs.d/org-ai/text-generation-webui
conda activate org-ai
python server.py --api --model SOME-MODEL当您在ORG-AI块中添加A :local密钥并使用Cc Cc请求完成时,该块将发送到本地API服务器而不是OpenAI API。例如:
#+begin_ai :local
...
#+end_ai
这将向org-ai-oobabooga-websocket-url发送请求,然后将响应流式传输到ORG缓冲区中。
还可以通过在AI块中添加:completion选项来提示较旧的完成模型。
:completion - 而不是使用ChatGPT模型,而是使用完成模型:model要使用的模型,请参阅https://platform.openai.com/docs/models有关模型的列表有关这些参数的详细含义,请参见OpenAI API文档。
以下自定义变量可用于配置文本生成:
org-ai-default-completion-model (默认: "text-davinci-003" )您还可以使用现有图像作为输入来生成更相似的图像。 org-ai-image-variation命令将提示通往图像,大小和计数的文件路径,然后在当前的org-mode缓冲区中生成尽可能多的图像并插入到它们的链接。图像将存储在org-ai-image-directory中。请参阅下面的演示。
有关更多信息,请参见OpenAI文档。输入图像必须为正方形,其大小需要小于4MB。目前,您需要用作命令行工具1的卷发。
org-ai也可以在org-mode缓冲区外使用。当您启用org-ai-global-mode时,前缀Cc Ma将绑定到许多命令:
| 命令 | 钥匙扣 | 描述 |
|---|---|---|
org-ai-on-region | Cc Ma r | 询问有关选定文本的问题,或告诉AI对此做些事情。响应将在组织模式缓冲区中打开,以便您可以继续对话。设置可变org-ai-on-region-file (setq org-ai-on-region-file (expand-file-name "org-ai-on-region.org" org-directory)) )带有该缓冲区的文件。 |
org-ai-summarize | Cc Ma s | 总结所选文本。 |
org-ai-refactor-code | Cc Ma c | 告诉AI如何更改选定的代码,更改将出现DIFF缓冲区。 |
org-ai-on-project | Cc Ma p | 运行提示并修改 /重构多个文件。如果有的话,将使用弹丸,如果不是,请返回当前目录。 |
org-ai-prompt | Cc Ma P | 提示用户获取文本,然后在当前缓冲区中打印AI的响应。 |
org-ai-switch-chat-model | Cc Ma m | 交互式更改org-ai-default-chat-model |
org-ai-open-account-usage-page | Cc Ma $ | 打开https://platform.openai.com/account/usage,以了解您燃烧了多少钱。 |
org-ai-open-request-buffer | Cc Ma ! | 打开url请求缓冲区。如果某件事不起作用,那么看看可能会有所帮助。 |
org-ai-talk-input-toggle | Cc Ma t | 通常,为不同的提示命令启用语音输入。 |
org-ai-talk-output-toggle | Cc Ma T | 通常启用语音输出。 |
使用org-ai-on-promoject缓冲区可以使您可以在项目中的文件上运行命令,或者仅在这些文件中的选定文本上运行命令。您可以选择项目的回教徒,然后询问“这是什么意思?”或向您解释了代码。您还可以要求更改代码,这将产生差异。如果您知道只有启用Copilot的VS代码的人可以做到这一点,请在此处指向它们。
运行org-ai-on-project命令将打开一个单独的缓冲区,该缓冲区允许您选择多个文件(并选择地选择文件中的子区域),然后在其上运行提示。
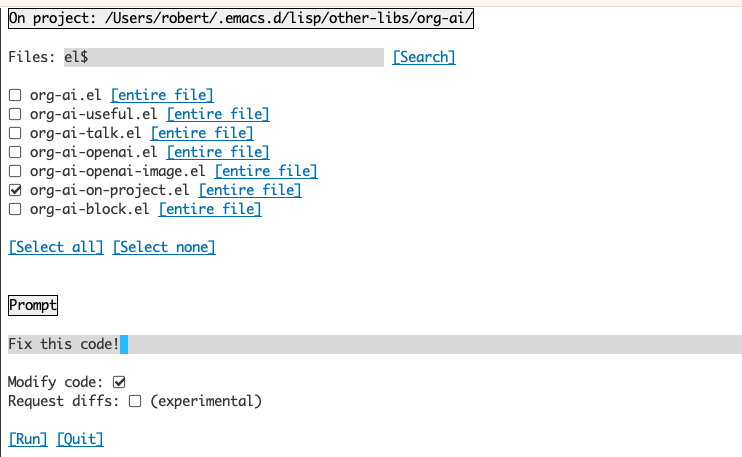
如果您停用“修改代码”,则该效果类似于运行org-ai-on-region on-of the File内容都出现在提示符中。
通过激活“修改代码”,您可以要求AI修改或重构代码。默认情况下(“请求diffs”)已停用,我们将提示为所有选定的文件/区域生成新代码,然后您可以看到每个文件的diff并决定应用它。使用“请求差异”活动,将要求AI直接创建一个可以应用的统一差异。
给定一个命名源块
#+name: sayhi
#+begin_src shell
echo "Hello there"
#+end_src
我们可以尝试通过名称引用它,但它不起作用。
#+begin_ai
[SYS]: You are a mimic. Whenever I say something, repeat back what I say to you. Say exactly what I said, do not add anything.
[ME]: <<sayhi()>>
[AI]: <<sayhi()>>
[ME]:
#+end_ai
与:noweb yes
#+begin_ai :noweb yes
[SYS]: You are a mimic. Whenever I say something, repeat back what I say to you. Say exactly what I said, do not add anything.
[ME]: <<sayhi()>>
[AI]: Hello there.
[ME]:
#+end_ai
您还可以使用org-ai-noweb: yes在父级标题中的任何位置,标题是特有的(Header Args优先)。
要查看发送到API时您的文档将扩展到的内容,请运行org-ai-expand-block 。
这是一个黑客,但效果很好。
创建一个块
#+name: identity
#+begin_src emacs-lisp :var x="fill me in"
(format "%s" x)
#+end_src
我们可以调用它,并让Noweb参数(支持LISP)评估为代码
#+begin_ai :noweb yes
Tell me some 3, simple ways to improve this dockerfile
<<identity(x=(quelpa-slurp-file "~/code/ibr-api/Dockerfile"))>>
[AI]: 1. Use a more specific version of Python, such as "python:3.9.6-buster" instead of "python:3.9-buster", to ensure compatibility with future updates.
2. Add a cleanup step after installing poetry to remove any unnecessary files or dependencies, thus reducing the size of the final image.
3. Use multi-stage builds to separate the build environment from the production environment, thus reducing the size of the final image and increasing security. For example, the first stage can be used to install dependencies and build the code, while the second stage can contain only the final artifacts and be used for deployment.
[ME]:
#+end_ai
org-ai在Melpa上:https://melpa.org/#/org-ai。如果您已将Melpa添加到包装档案中
( require 'package )
( add-to-list 'package-archives '( " melpa " . " http://melpa.org/packages/ " ) t )
( package-initialize )您可以安装它:
( use-package org-ai
:ensure t
:commands (org-ai-mode
org-ai-global-mode)
:init
( add-hook 'org-mode-hook # 'org-ai-mode ) ; enable org-ai in org-mode
(org-ai-global-mode) ; installs global keybindings on C-c M-a
:config
( setq org-ai-default-chat-model " gpt-4 " ) ; if you are on the gpt-4 beta:
(org-ai-install-yasnippets)) ; if you are using yasnippet and want `ai` snippets
( straight-use-package
'(org-ai :type git :host github :repo " rksm/org-ai "
:local-repo " org-ai "
:files ( " *.el " " README.md " " snippets " )))结帐此存储库。
git clone
https://github.com/rksm/org-ai然后,如果您使用use-package :
( use-package org-ai
:ensure t
:load-path ( lambda () " path/to/org-ai " ))
; ; ...rest as above...
或仅与require :
( package-install 'websocket )
( add-to-list 'load-path " path/to/org-ai " )
( require 'org )
( require 'org-ai )
( add-hook 'org-mode-hook # 'org-ai-mode )
(org-ai-global-mode)
( setq org-ai-default-chat-model " gpt-4 " ) ; if you are on the gpt-4 beta:
(org-ai-install-yasnippets) ; if you are using yasnippet and want `ai` snippets您可以在配置中直接设置API令牌:
( setq org-ai-openai-api-token " <ENTER YOUR API TOKEN HERE> " )
另外, org-ai支持auth-source检索API密钥。您可以以格式存储一个秘密
machine api.openai.com login org-ai password <your-api-key>
在您的~/authinfo.gpg文件中。如果存在,则ORG-AI将使用此机制在提出请求时检索令牌。如果您不希望org-ai尝试从auth-source检索钥匙,则可以在加载org-ai之前将org-ai-use-auth-source设置为nil 。
您可以通过自定义这些变量来切换到Azure,即与Mx customize-variable进行交互性或将其添加到您的配置中:
( setq org-ai-service 'azure-openai
org-ai-azure-openai-api-base " https://your-instance.openai.azure.com "
org-ai-azure-openai-deployment " azure-openai-deployment-name "
org-ai-azure-openai-api-version " 2023-07-01-preview " )要存储API凭据,请按照上面的Authinfo说明进行操作,但使用org-ai-azure-openai-api-base作为机器名称。
有关可用模型的列表,请参见Perplexity.ai文档。
要么在配置中切换默认服务:
( setq org-ai-service 'perplexity .ai)
( setq org-ai-default-chat-model " llama-3-sonar-large-32k-online " )或每个块:
#+begin_ai :service perplexity.ai :model llama-3-sonar-large-32k-online
[ME]: Tell me fun facts about Emacs.
#+end_ai
对于身份验证,在您的authinfo.gpg中或设置org-ai-openai-api-token中的machine api.perplexity.ai login org-ai password pplx-*** 。
注意:当前,Perplexity.ai无法通过API访问参考/链接,因此Emacs将无法显示参考。他们有一个用于该跑步的Beta程序,我肯定希望这将很快能够提供。
类似于上述。例如
#+begin_ai :service anthropic :model claude-3-opus-20240229
[ME]: Tell me fun facts about Emacs.
#+end_ai
人类模型在这里。目前,只有一个通过org-ai-anthropic-api-version设置的API版本。如果其他版本出现,您可以在这里找到它们。
对于API令牌使用machine api.anthropic.com login org-ai password sk-ant-***在您的authinfo.gpg中。
这些设置步骤是可选的。如果您不想使用语音输入 /输出,则可以跳过此部分。
注意:我可以在此要旨中找到我的org-ai的个人配置。它包含一个工作的耳语设置。
这已在MacOS和Linux上进行了测试。有人使用Windows计算机,请测试一下,让我知道需要做些什么才能使其正常工作(谢谢!)。
语音输入使用hisper.el和ffmpeg 。您需要直接克隆回购或使用driew.el安装。
brew install ffmpeg )或在Linux上sudo apt install ffmpeg 。git clone https://github.com/natrys/whisper.el path/to/whisper.el现在,您应该能够将其加载到Emacs中:
( use-package whisper
:load-path " path/to/whisper.el "
:bind ( " M-s-r " . whisper-run))现在也加载:
( use-package greader :ensure )
( require 'whisper )
( require 'org-ai-talk )
; ; macOS speech settings, optional
( setq org-ai-talk-say-words-per-minute 210 )
( setq org-ai-talk-say-voice " Karen " )在MacOS上,您需要再做两件事:
您可以使用Tccutil助手:
git clone https://github.com/DocSystem/tccutil
cd tccutil
sudo python ./tccutil.py -p /Applications/Emacs.app -e --microphone现在,当您从emacs shell中运行ffmpeg -f avfoundation -i :0 output.mp3时,应该没有abort trap: 6错误。
(作为tccutil.py的替代方案,请参见本期中提到的方法。)
您可以使用ffmpeg -f avfoundation -list_devices true -i "" (setq whisper--ffmpeg-input-device ":0")输出列出音频输入设备,然后告诉Whisper.el。 :0是麦克风索引,请参见上面命令的输出以使用另一个。
我创建了一个Emacs助手,可以让您交互选择麦克风。看到这个要点。
我的完整演讲启用了配置,然后看起来像:
( use-package whisper
:load-path ( lambda () ( expand-file-name " lisp/other-libs/whisper.el " user-emacs-directory))
:config
( setq whisper-model " base "
whisper-language " en "
whisper-translate nil )
( when *is-a-mac*
(rk/select-default-audio-device " Macbook Pro Microphone " )
( when rk/default-audio-device)
( setq whisper--ffmpeg-input-device ( format " : %s " rk/default-audio-device))))在Macos上,您还可以使用内置的Siri Distation,而不是耳语。为此,请转到Preferences -> Keyboard -> Dictation ,启用它并设置快捷方式。默认值为ctrl-ctrl。
实现的方式(Defun Whisper-检查安装安装)在Win10上不起作用(请参阅#66)。
解决方法是安装hisper.cpp并手动型号和补丁:
( defun whisper--check-install-and-run ( buffer status )
(whisper--record-audio))非摩托马州系统上的语音输出默认用于使用Greader软件包,该程序包在下面使用以综合语音。您需要手动安装Greader(例如,通过Mx package-install )。从那时起,应该“工作”。您可以通过选择一些文本并调用Mx org-ai-talk-read-region进行测试。
稳定扩散的API可以通过稳定的扩散 - Webui项目托管。浏览平台的安装步骤,然后启动仅API的服务器:
cd path/to/stable-diffusion-webui
./webui.sh --nowebui默认情况下,这将在http://127.0.0.1:7861上启动服务器。为了与org-ai一起使用,您需要设置org-ai-sd-endpoint-base :
( setq org-ai-sd-endpoint-base " http://localhost:7861/sdapi/v1/ " )如果您使用托管在其他地方的服务器,请相应地更改该URL。
由于版本0.4 org-ai支持oobabooga/text-generation-webui的本地型号。请参阅安装说明以为您的系统设置。
这是在Ubuntu 22.04上测试的设置步行。它假设Miniconda或Anaconda以及要安装的Git-LFS。
conda create -n org-ai python=3.10.9
conda activate org-ai
pip3 install torch torchvision torchaudiomkdir -p ~ /.emacs.d/org-ai/
cd ~ /.emacs.d/org-ai/
git clone https://github.com/oobabooga/text-generation-webui
cd text-generation-webui
pip install -r requirements.txtoobabooga/text-generation-webui支持许多语言模型。通常,您会从拥抱面上安装它们。例如,安装CodeLlama-7b-Instruct模型:
cd ~ /.emacs.d/org-ai/text-generation-webui/models
git clone [email protected]:codellama/CodeLlama-7b-Instruct-hf cd ~ /.emacs.d/org-ai/text-generation-webui
conda activate org-ai
python server.py --api --model CodeLlama-7b-Instruct-hf根据您的硬件和使用的模型,您可能需要调整服务器参数,例如使用--load-in-8bit来减少内存使用情况或--cpu ,如果您没有合适的GPU。
现在,您应该能够通过在#+begin_ai块中添加:local选项:
#+begin_ai :local
Hello CodeLlama!
#+end_ai
不,OpenAI是最容易设置的(您只需要一个API键),但是您也可以使用本地型号。请参阅上面的Oobabooga/text-generation-webui使用稳定扩散和局部LLM。还支持拟人化的克劳德(Claude)和困惑。请为您希望看到的其他服务打开问题或公关。我的响应速度可能很慢,但是如果有足够的兴趣,我会增加支持。
GPTEL软件包提供了OpenAi Chatgpt API的替代界面:https://github.com/karthink/gptel
如果您发现此项目有用,请考虑赞助。谢谢你!
注意:弯曲的图像变化实现需要安装命令行卷曲。原因是OpenAI API期望多部分/form-data请求,而emacs内置的url-retrieve不支持这一点(至少我还没有弄清楚如何)。切换到request.el可能是更好的选择。如果您有兴趣贡献,则非常欢迎PR! ↩


