org ai
1.0.0
Mode mineur pour le mode org EMACS qui donne accès aux modèles d'IA génératifs. Sont actuellement pris en charge
À l'intérieur d'un tampon en mode org, vous pouvez
Remarque: Afin d'utiliser l'API OpenAI, vous aurez besoin d'un compte OpenAI et vous devez obtenir un jeton API. Pour autant que je sache, les limites d'utilisation actuelles du niveau gratuit vous mènent assez loin.
#+begin_ai...#+end_ai blocs spéciaux #+begin_ai
Is Emacs the greatest editor?
#+end_ai
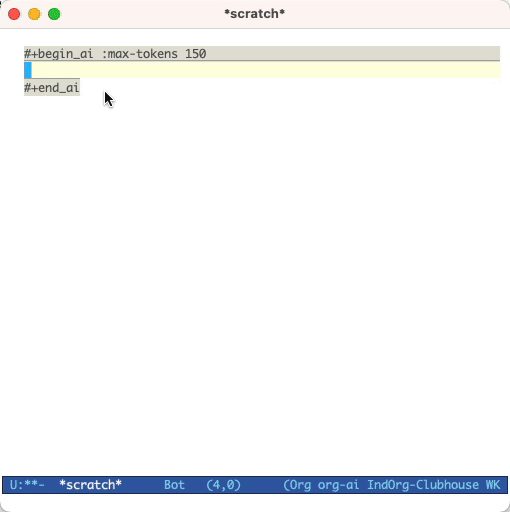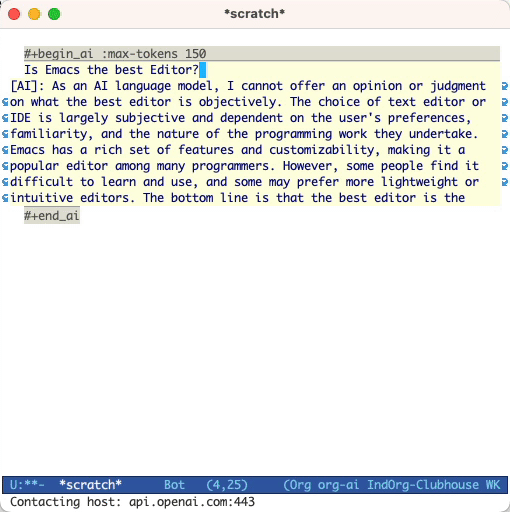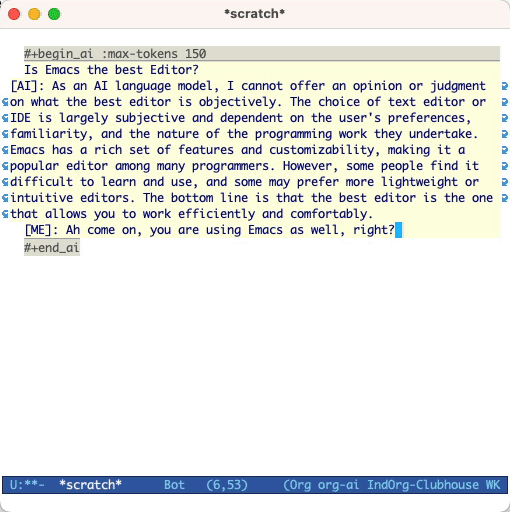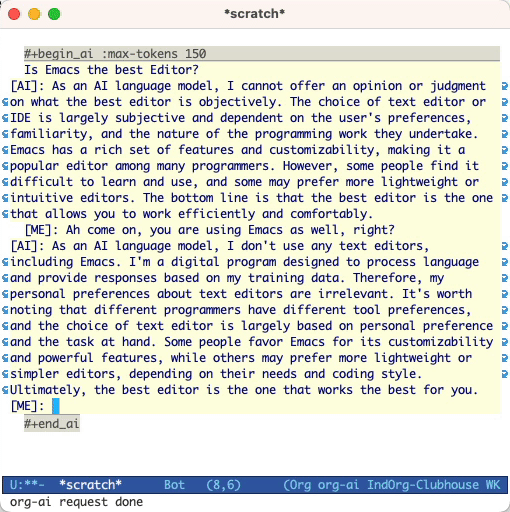
Vous pouvez continuer à taper et appuyer sur Cc Cc pour créer une conversation. Cg interrompra une demande de course.
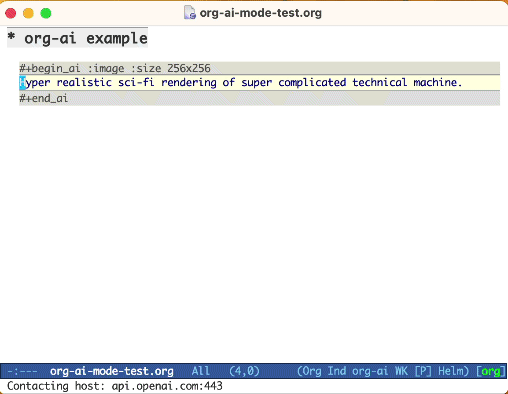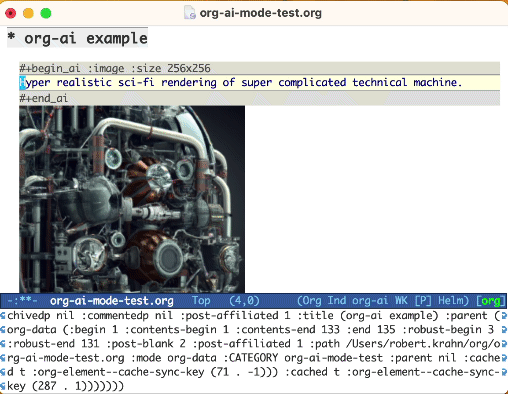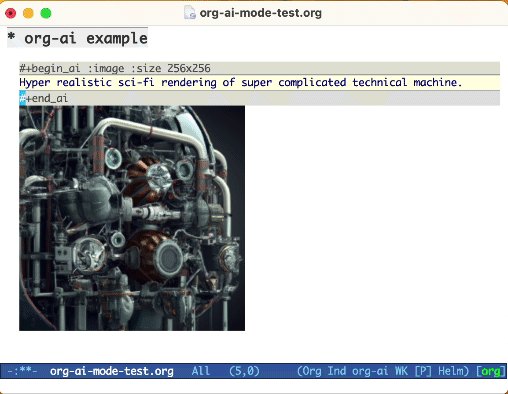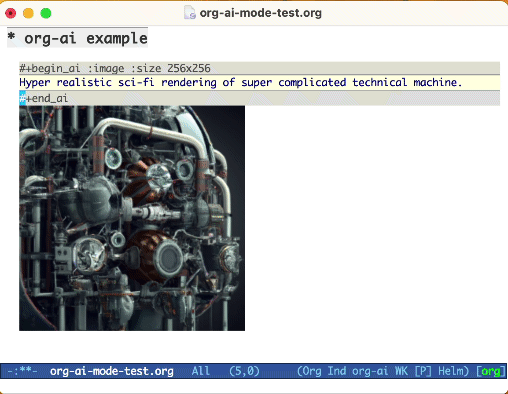
Utilisez le mot-clé :image pour générer une image. Cela utilise Dall · E-3 par défaut.
#+begin_ai :image :size 1024x1024
Hyper realistic sci-fi rendering of super complicated technical machine.
#+end_ai
Vous pouvez utiliser les mots clés suivants pour contrôler la génération d'images:
:size <width>x<height> - La taille de l'image à générer (par défaut: 1024x1024):model <model> - le modèle à utiliser (par défaut: "dall-e-3" ):quality <quality> - La qualité de l'image (choix: hd , standard ):style <style> - Le style à utiliser (choix: vivid , natural )(Pour plus d'informations sur ces paramètres, consultez cet article de blog OpenAI.
Vous pouvez personnaliser les valeurs par défaut pour ces variables avec customize-variable ou en les définissant dans votre configuration:
( setq org-ai-image-model " dall-e-3 " )
( setq org-ai-image-default-size " 1792x1024 " )
( setq org-ai-image-default-count 2 )
( setq org-ai-image-default-style 'vivid )
( setq org-ai-image-default-quality 'hd )
( setq org-ai-image-directory ( expand-file-name " org-ai-images/ " org-directory))
#+begin_ai...#+end_ai blocs spéciauxSemblable à Org-Babel, ces blocs délimitent l'entrée (et pour le chatppt également sur le modèle AI. Vous pouvez l'utiliser pour le chat IA, la complétion du texte et le texte -> Génération d'images. Voir les options ci-dessous pour plus d'informations.
Créer un bloc comme
#+begin_ai
Is Emacs the greatest editor?
#+end_ai
et appuyez sur Cc Cc . L'entrée de chat apparaîtra en ligne et une fois la réponse terminée, vous pouvez saisir votre réponse et ainsi de suite. Voir la démo ci-dessous. Vous pouvez appuyer sur Cg pendant que la demande d'IA est en cours d'exécution pour l'annuler.
Vous pouvez également modifier l'invite système et les autres paramètres utilisés. L'invite du système est injectée avant l'entrée de l'utilisateur et «lit» le modèle à répondre dans un certain style. Par exemple, vous pouvez faire:
#+begin_ai :max-tokens 250
[SYS]: Act as if you are a powerful medival king.
[ME]: What will you eat today?
#+end_ai
Cela se traduira par une charge utile API comme
{
"messages" : [
{
"role" : " system " ,
"content" : " Act as if you are a powerful medival king. "
},
{
"role" : " user " ,
"content" : " What will you eat today? "
}
],
"model" : " gpt-4o-mini " ,
"stream" : true ,
"max_tokens" : 250 ,
"temperature" : 1.2
}Pour certaines idées rapides, voir par exemple des invites de chatppt impressionnantes.
Lors de la génération d'images à l'aide de l'indicateur :image , les images apparaîtront sous le bloc AI en ligne. Les images seront stockées (avec leur invite) à l'intérieur org-ai-image-directory qui par défaut qui est par défaut à ~/org/org-ai-images/ .
Vous pouvez également utiliser l'entrée de la parole pour transcrire l'entrée. Appuyez sur Cc r pour org-ai-talk-capture-in-org pour commencer l'enregistrement. Notez que cela vous obligera à configurer la reconnaissance de la parole (voir ci-dessous). La sortie de la parole peut être activée avec org-ai-talk-output-enable .
À l'intérieur d'un #+begin_ai...#+end_ai vous pouvez modifier et sélectionner les parties du chat avec ces commandes:
Cc <backspace> ( org-ai-kill-region-at-point ) pour supprimer la pièce de chat sous le point.org-ai-mark-region-at-point marquera la région au point.org-ai-mark-last-region marquera la dernière partie de chat. Pour appliquer la syntaxe mise en évidence à votre #+begin_ai ... les blocs ajoutent simplement un nom de mode majeur en langue après _ai . EG #+begin_ai markdown . Pour Markdown en particulier, pour ensuite également mettre en surbrillance correctement le code dans BackTicks, vous pouvez définir (setq markdown-fontify-code-blocks-natively t) . Assurez-vous que vous avez également installé le package Markdown en mode. Merci @tavisrudd pour cette astuce!
Ce comportement est activé par défaut afin que l'interaction soit plus similaire à un chat. Il peut être ennuyeux lorsque la sortie longue est présente et que le tampon défile pendant que vous lisez. Vous pouvez donc désactiver cela avec:
( setq org-ai-jump-to-end-of-block nil ) Set (setq org-ai-auto-fill t) pour "remplir" (envelopper automatiquement les lignes en fonction de fill-column ) le texte inséré. Fondamentalement, comme auto-fill-mode mais pour l'IA.
Le bloc #+begin_ai...#+end_ai peut prendre les options suivantes.
Par défaut, le contenu des blocs AI est interprété comme des messages pour chatgpt. Le texte suivant [ME]: est associé à l'utilisateur, le texte suivant [AI]: est associé comme réponse du modèle. Facultativement, vous pouvez démarrer le bloc avec une entrée [SYS]: <behavior> pour amorcer le modèle (voir org-ai-default-chat-system-prompt ci-dessous).
:max-tokens number - Nombre de jetons maximaux à générer (par défaut: nil, utilisez la valeur par défaut d'Openai):temperature number - température du modèle (par défaut: 1):top-p number - TOP_P du modèle (par défaut: 1):frequency-penalty number - pénalité de fréquence du modèle (par défaut: 0):presence-penalty - Panne de présence du modèle (par défaut: 0):sys-everywhere - répétez l'invite système pour chaque message utilisateur (par défaut: nil) Si vous avez beaucoup de threads de conversation différents concernant le même sujet et les mêmes paramètres (invite du système, température, etc.) et que vous ne souhaitez pas répéter toutes les options, vous pouvez définir les propriétés de la portée du fichier Org ou créer un titre d'org avec une propriété Diroir, tel que tous les blocs #+begin_ai...#+end_ai sous cette rubrique hériteront des paramètres.
Exemples:
* Emacs (multiple conversations re emacs continue in this subtree)
:PROPERTIES:
:SYS: You are a emacs expert. You can help me by answering my questions. You can also ask me questions to clarify my intention.
:temperature: 0.5
:model: gpt-4o-mini
:END:
** Web programming via elisp
#+begin_ai
How to call a REST API and parse its JSON response?
#+end_ai
** Other emacs tasks
#+begin_ai...#+end_ai
* Python (multiple conversations re python continue in this subtree)
:PROPERTIES:
:SYS: You are a python programmer. Respond to the task with detailed step by step instructions and code.
:temperature: 0.1
:model: gpt-4
:END:
** Learning QUIC
#+begin_ai
How to setup a webserver with http3 support?
#+end_ai
** Other python tasks
#+begin_ai...#+end_ai
Les variables personnalisées suivantes peuvent être utilisées pour configurer le chat:
org-ai-default-chat-model (par défaut: "gpt-4o-mini" )org-ai-default-max-tokens combien de temps la réponse doit durer. Actuellement, ne peut pas dépasser 4096. Si cette valeur est trop petite, une réponse peut être coupée (par défaut: nil)org-ai-default-chat-system-prompt Comment "Prime" le modèle. Il s'agit d'une invite qui est injectée avant l'entrée de l'utilisateur. (Par défaut: "You are a helpful assistant inside Emacs." )org-ai-default-inject-sys-prompt-for-all-messages wether pour répéter l'invite système pour chaque message utilisateur. Parfois, le modèle "oublie" comment il a été amorcé. Cela peut aider à le rappeler. (par défaut: nil ) Lorsque vous ajoutez une option :image au bloc AI, l'invite sera utilisée pour la génération d'images.
:image - Générez une image au lieu du texte:size - taille de l'image à générer (par défaut: 256x256, peut être 512x512 ou 1024x1024):n - le nombre d'images à générer (par défaut: 1)Les variables personnalisées suivantes peuvent être utilisées pour configurer la génération d'images:
org-ai-image-directory - où stocker les images générées (par défaut: ~/org/org-ai-images/ ) Similaire à Dall-E mais utilisez
#+begin_ai :sd-image
<PROMPT>
#+end_ai
Vous pouvez exécuter IMG2IMG en étiquetant votre image en mode org avec le nom # + et en le faisant référence avec: Ref d'image à partir de votre bloc org-ai.
#+begin_ai :sd-image :image-ref label1
forest, Gogh style
#+end_ai
MX Org-AI-SD-CLIP devine l'invite de l'image précédente sur le mode org par l'interrogateur de clip et l'enregistre dans l'anneau de mise à mort.
MX Org-AI-SD-Deepdanbooru devine l'invite de l'image précédente sur le mode org par l'interrogateur Deepdanbooru et le sauve dans l'anneau de mise à mort.
Pour demander les compléments d'un modèle local servi avec oobabooga / génération de texte-webui, passez par les étapes de configuration décrites ci-dessous
Puis démarrez un serveur API:
cd ~ /.emacs.d/org-ai/text-generation-webui
conda activate org-ai
python server.py --api --model SOME-MODEL Lorsque vous ajoutez une clé :local à un bloc org-ai et demandez des compléments avec Cc Cc , le bloc sera envoyé au serveur API local au lieu de l'API OpenAI. Par exemple:
#+begin_ai :local
...
#+end_ai
Cela enverra une demande à org-ai-oobabooga-websocket-url et diffuse la réponse dans le tampon org.
Les modèles d'achèvement plus anciens peuvent également être invités en ajoutant l'option :completion au bloc AI.
:completion - Au lieu d'utiliser le modèle Chatgpt, utilisez le modèle d'achèvement:model - Quel modèle à utiliser, voir https://platform.openai.com/docs/models pour une liste de modèlesPour la signification détaillée de ces paramètres, consultez la documentation de l'API OpenAI.
Les variables personnalisées suivantes peuvent être utilisées pour configurer la génération de texte:
org-ai-default-completion-model (par défaut: "text-davinci-003" ) Vous pouvez également utiliser une image existante en entrée pour générer des images plus similaires. La commande org-ai-image-variation provoquera un chemin de fichier vers une image, une taille et un décompte et générera ensuite autant d'images et inséra les liens vers eux dans le tampon org-mode actuel. Les images seront stockées à l'intérieur org-ai-image-directory . Voir la démo ci-dessous.
Pour plus d'informations, consultez la documentation OpenAI. L'image d'entrée doit être carrée et sa taille doit être inférieure à 4 Mo. Et vous avez actuellement besoin de boucles disponibles en tant qu'outil de ligne de commande 1 .
org-ai peut également être utilisé en dehors des tampons org-mode . Lorsque vous activez org-ai-global-mode , le préfixe Cc Ma sera lié à un certain nombre de commandes:
| commande | embound | description |
|---|---|---|
org-ai-on-region | Cc Ma r | Posez une question sur le texte sélectionné ou dites à l'AI d'en faire quelque chose. La réponse sera ouverte dans un tampon en mode org afin que vous puissiez continuer la conversation. Définition de la variable org-ai-on-region-file (par exemple (setq org-ai-on-region-file (expand-file-name "org-ai-on-region.org" org-directory)) un fichier avec ce tampon. |
org-ai-summarize | Cc Ma s | Résumez le texte sélectionné. |
org-ai-refactor-code | Cc Ma c | Dites à l'IA comment modifier le code sélectionné, un tampon Diff apparaîtra avec les modifications. |
org-ai-on-project | Cc Ma p | Exécutez les invites et modifiez / refacteur plusieurs fichiers à la fois. Utilisera le projectile si disponible, retombe dans le répertoire actuel sinon. |
org-ai-prompt | Cc Ma P | Invitez l'utilisateur à un texte, puis imprimez la réponse de l'IA dans le tampon actuel. |
org-ai-switch-chat-model | Cc Ma m | Changer org-ai-default-chat-model |
org-ai-open-account-usage-page | Cc Ma $ | Ouvre https://platform.openai.com/account/usage pour voir combien d'argent vous avez brûlé. |
org-ai-open-request-buffer | Cc Ma ! | Ouvre le tampon de demande url . Si quelque chose ne fonctionne pas, il peut être utile de jeter un œil. |
org-ai-talk-input-toggle | Cc Ma t | Activez généralement l'entrée de la parole pour les différentes commandes d'invite. |
org-ai-talk-output-toggle | Cc Ma T | Activez généralement la sortie de la parole. |
L'utilisation du tampon org-ai-on-project vous permet d'exécuter des commandes sur des fichiers dans un projet, alternativement également sur le texte sélectionné dans ces fichiers. Vous pouvez sélectionner la lecture d'un projet et demander "De quoi s'agit-il?" Ou faites-vous expliquer le code. Vous pouvez également demander des modifications de code, ce qui générera un DIFF. Si vous savez d'une manière ou d'une autre qui pense que seul le code VS avec Copilot a activé peut le faire, pointez-les ici.
L'exécution de la commande org-ai-on-project ouvrira un tampon séparé qui vous permet de choisir de choisir plusieurs fichiers (et de sélectionner éventuellement une sous-région dans un fichier), puis d'exécuter une invite dessus.
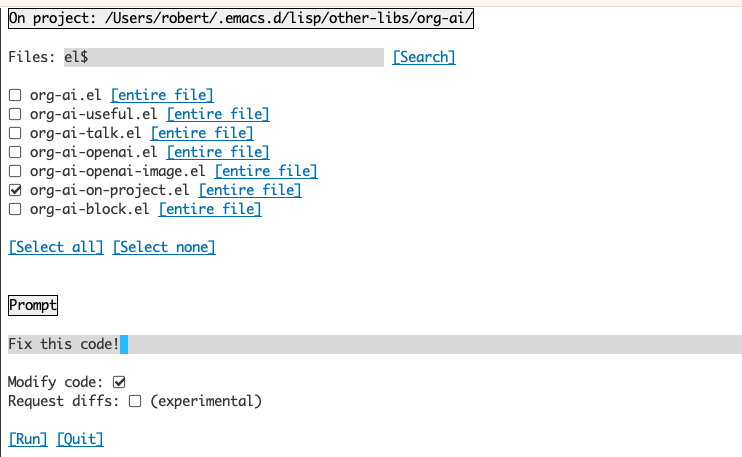
Si vous désactivez "Modifier le code", l'effet est similaire à l'exécution de org-ai-on-region juste que le contenu du fichier apparaît tous dans l'invite.
Avec "Modifier le code" activé, vous pouvez demander à l'IA de modifier ou de refactor le code. Par défaut ("Demander Diffs") désactivé, nous inviterons à générer le nouveau code pour tous les fichiers / régions sélectionnés et vous pouvez ensuite voir un diff par fichier et décider de l'appliquer ou non. Avec "Demande Diffs" actif, l'IA sera invitée à créer directement un Diff unifié qui peut ensuite être appliqué.
Étant donné un bloc de source nommé
#+name: sayhi
#+begin_src shell
echo "Hello there"
#+end_src
Nous pouvons essayer de le référencer par nom, mais cela ne fonctionne pas.
#+begin_ai
[SYS]: You are a mimic. Whenever I say something, repeat back what I say to you. Say exactly what I said, do not add anything.
[ME]: <<sayhi()>>
[AI]: <<sayhi()>>
[ME]:
#+end_ai
Avec :noweb yes
#+begin_ai :noweb yes
[SYS]: You are a mimic. Whenever I say something, repeat back what I say to you. Say exactly what I said, do not add anything.
[ME]: <<sayhi()>>
[AI]: Hello there.
[ME]:
#+end_ai
Vous pouvez également déclencher une extension NowEB avec un org-ai-noweb: yes en tête du prix du groupe dans les titres parent (les args d'en-tête ont la priorité).
Pour voir à quoi votre document se développera lorsque vous envoyez à l'API, exécutez org-ai-expand-block .
C'est un piratage mais cela fonctionne très bien.
Créer un bloc
#+name: identity
#+begin_src emacs-lisp :var x="fill me in"
(format "%s" x)
#+end_src
Nous pouvons l'invoquer et laisser les paramètres NOWEB (qui prennent en charge LISP) évaluer en tant que code
#+begin_ai :noweb yes
Tell me some 3, simple ways to improve this dockerfile
<<identity(x=(quelpa-slurp-file "~/code/ibr-api/Dockerfile"))>>
[AI]: 1. Use a more specific version of Python, such as "python:3.9.6-buster" instead of "python:3.9-buster", to ensure compatibility with future updates.
2. Add a cleanup step after installing poetry to remove any unnecessary files or dependencies, thus reducing the size of the final image.
3. Use multi-stage builds to separate the build environment from the production environment, thus reducing the size of the final image and increasing security. For example, the first stage can be used to install dependencies and build the code, while the second stage can contain only the final artifacts and be used for deployment.
[ME]:
#+end_ai
Org-ai est sur Melpa: https://melpa.org/#/org-ai. Si vous avez ajouté Melpa à vos archives
( require 'package )
( add-to-list 'package-archives '( " melpa " . " http://melpa.org/packages/ " ) t )
( package-initialize )Vous pouvez l'installer avec:
( use-package org-ai
:ensure t
:commands (org-ai-mode
org-ai-global-mode)
:init
( add-hook 'org-mode-hook # 'org-ai-mode ) ; enable org-ai in org-mode
(org-ai-global-mode) ; installs global keybindings on C-c M-a
:config
( setq org-ai-default-chat-model " gpt-4 " ) ; if you are on the gpt-4 beta:
(org-ai-install-yasnippets)) ; if you are using yasnippet and want `ai` snippets
( straight-use-package
'(org-ai :type git :host github :repo " rksm/org-ai "
:local-repo " org-ai "
:files ( " *.el " " README.md " " snippets " )))Découvrez ce référentiel.
git clone
https://github.com/rksm/org-ai Ensuite, si vous utilisez use-package :
( use-package org-ai
:ensure t
:load-path ( lambda () " path/to/org-ai " ))
; ; ...rest as above...
ou juste avec require :
( package-install 'websocket )
( add-to-list 'load-path " path/to/org-ai " )
( require 'org )
( require 'org-ai )
( add-hook 'org-mode-hook # 'org-ai-mode )
(org-ai-global-mode)
( setq org-ai-default-chat-model " gpt-4 " ) ; if you are on the gpt-4 beta:
(org-ai-install-yasnippets) ; if you are using yasnippet and want `ai` snippetsVous pouvez soit définir directement votre jeton API dans votre configuration:
( setq org-ai-openai-api-token " <ENTER YOUR API TOKEN HERE> " )
Alternativement, org-ai prend en charge auth-source pour récupérer votre clé API. Vous pouvez stocker un secret dans le format
machine api.openai.com login org-ai password <your-api-key>
Dans votre fichier ~/authinfo.gpg . Si cela est présent, Org-AI utilisera ce mécanisme pour récupérer le jeton lorsqu'une demande est faite. Si vous ne voulez pas que org-ai essaie de récupérer la clé de auth-source , vous pouvez définir org-ai-use-auth-source à nil avant de charger org-ai .
Vous pouvez passer à Azure en personnalisant ces variables, soit de manière interactive avec Mx customize-variable , soit en les ajoutant à votre configuration:
( setq org-ai-service 'azure-openai
org-ai-azure-openai-api-base " https://your-instance.openai.azure.com "
org-ai-azure-openai-deployment " azure-openai-deployment-name "
org-ai-azure-openai-api-version " 2023-07-01-preview " ) Pour stocker les informations d'identification de l'API, suivez les instructions Authinfo ci-dessus mais utilisez org-ai-azure-openai-api-base comme nom de machine.
Pour une liste des modèles disponibles, voir la documentation Perplexity.ai.
Soit changer le service par défaut dans votre configuration:
( setq org-ai-service 'perplexity .ai)
( setq org-ai-default-chat-model " llama-3-sonar-large-32k-online " )ou par bloc:
#+begin_ai :service perplexity.ai :model llama-3-sonar-large-32k-online
[ME]: Tell me fun facts about Emacs.
#+end_ai
Pour l'authentification, ayez une entrée comme machine api.perplexity.ai login org-ai password pplx-*** dans votre authinfo.gpg ou définissez org-ai-openai-api-token .
Remarque: Actuellement, la perplexité.ai ne donne pas accès aux références / liens via l'API afin que Emacs ne puisse pas afficher des références. Ils ont un programme bêta pour cette course et j'espère que cela sera bientôt disponible.
Similaire à ce qui précède. Par exemple
#+begin_ai :service anthropic :model claude-3-opus-20240229
[ME]: Tell me fun facts about Emacs.
#+end_ai
Les modèles anthropes sont là. Il n'y a actuellement qu'une seule version API définie via org-ai-anthropic-api-version . Si une autre version sort, vous pouvez les trouver ici.
Pour le jeton API Utilisez machine api.anthropic.com login org-ai password sk-ant-*** Dans votre authinfo.gpg .
Ces étapes de configuration sont facultatives. Si vous ne souhaitez pas utiliser l'entrée / sortie de la parole, vous pouvez ignorer cette section.
Remarque: ma configuration personnelle pour org-ai peut être trouvée dans cet GIST. Il contient une configuration de chuchotement qui fonctionne.
Cela a été testé sur macOS et Linux. Quelqu'un avec un ordinateur Windows, veuillez tester ceci et faites-moi savoir ce qui doit être fait pour le faire fonctionner (merci!).
L'entrée de la parole utilise Whisper.el et ffmpeg . Vous devez cloner directement le repo ou utiliser Straight.el pour l'installer.
brew install ffmpeg sur macOS) ou sudo apt install ffmpeg sur Linux.git clone https://github.com/natrys/whisper.el path/to/whisper.elVous devriez maintenant pouvoir le charger à l'intérieur d'Emacs:
( use-package whisper
:load-path " path/to/whisper.el "
:bind ( " M-s-r " . whisper-run))Maintenant aussi chargement:
( use-package greader :ensure )
( require 'whisper )
( require 'org-ai-talk )
; ; macOS speech settings, optional
( setq org-ai-talk-say-words-per-minute 210 )
( setq org-ai-talk-say-voice " Karen " )Sur macOS, vous devrez faire deux autres choses:
Vous pouvez utiliser l'assistance TCCUTIL:
git clone https://github.com/DocSystem/tccutil
cd tccutil
sudo python ./tccutil.py -p /Applications/Emacs.app -e --microphone Lorsque vous exécutez maintenant ffmpeg -f avfoundation -i :0 output.mp3 à partir d'un shell EMACS, il ne devrait pas y avoir abort trap: 6 erreur.
(En tant qu'alternative à Tccutil.py, voir la méthode mentionnée dans ce numéro.)
Vous pouvez utiliser la sortie de ffmpeg -f avfoundation -list_devices true -i "" pour répertorier les périphériques d'entrée audio, puis parler de Whisper.el à ce sujet: (setq whisper--ffmpeg-input-device ":0") . :0 est l'indice de microphone, voir la sortie de la commande ci-dessus pour en utiliser une autre.
J'ai créé une aide EMACS qui vous permet de sélectionner le microphone de manière interactive. Voir ce gist.
Ma configuration complexe complexe est alors à ressembler:
( use-package whisper
:load-path ( lambda () ( expand-file-name " lisp/other-libs/whisper.el " user-emacs-directory))
:config
( setq whisper-model " base "
whisper-language " en "
whisper-translate nil )
( when *is-a-mac*
(rk/select-default-audio-device " Macbook Pro Microphone " )
( when rk/default-audio-device)
( setq whisper--ffmpeg-input-device ( format " : %s " rk/default-audio-device)))) Sur MacOS, au lieu de chuchoter, vous pouvez également utiliser la dictée Siri intégrée. Pour activer cela, accédez à Preferences -> Keyboard -> Dictation , activez-le et configurez un raccourci. La valeur par défaut est Ctrl-Ctrl.
La voie (Defun Whisper - Sicheck-stall-and-run) est mise en œuvre ne fonctionne pas sur Win10 (voir # 66).
Une solution de contournement consiste à installer Whisper.cpp et le modèle manuellement et le patch:
( defun whisper--check-install-and-run ( buffer status )
(whisper--record-audio)) La sortie de la parole sur les systèmes non-MACOS par défaut utilise par défaut le package Greader qui utilise EspEak en dessous pour synthétiser la parole. Vous devrez installer Greader manuellement (par exemple via Mx package-install ). À partir de ce moment, il devrait "travailler". Vous pouvez le tester en sélectionnant du texte et en appelant Mx org-ai-talk-read-region .
Une API pour la diffusion stable peut être hébergée avec le projet stable-diffusion-webui. Passez par les étapes d'installation de votre plate-forme, puis démarrez un serveur API uniquement:
cd path/to/stable-diffusion-webui
./webui.sh --nowebui Cela démarrera un serveur sur http://127.0.0.1:7861 par défaut. Pour l'utiliser avec Org-AI, vous devez définir org-ai-sd-endpoint-base :
( setq org-ai-sd-endpoint-base " http://localhost:7861/sdapi/v1/ " )Si vous utilisez un serveur hébergé ailleurs, modifiez cette URL en conséquence.
Étant donné que la version 0.4 Org-AI prend en charge les modèles locaux servis avec Oobabooga / Génération de texte-Web. Voir les instructions d'installation pour le configurer pour votre système.
Voici une procédure de configuration qui a été testée sur Ubuntu 22.04. Il suppose que MiniConda ou Anaconda ainsi que GIT-LFS à installer.
conda create -n org-ai python=3.10.9
conda activate org-ai
pip3 install torch torchvision torchaudiomkdir -p ~ /.emacs.d/org-ai/
cd ~ /.emacs.d/org-ai/
git clone https://github.com/oobabooga/text-generation-webui
cd text-generation-webui
pip install -r requirements.txt Oobabooga / Génération de texte-webui prend en charge un certain nombre de modèles de langue. Normalement, vous les installeriez à HuggingFace. Par exemple, pour installer le modèle CodeLlama-7b-Instruct :
cd ~ /.emacs.d/org-ai/text-generation-webui/models
git clone [email protected]:codellama/CodeLlama-7b-Instruct-hf cd ~ /.emacs.d/org-ai/text-generation-webui
conda activate org-ai
python server.py --api --model CodeLlama-7b-Instruct-hf Selon votre matériel et le modèle utilisé, vous devrez peut-être ajuster les paramètres du serveur, par exemple Utiliser --load-in-8bit pour réduire l'utilisation de la mémoire ou --cpu si vous n'avez pas de GPU approprié.
Vous devriez maintenant pouvoir utiliser le modèle local avec Org-AI en ajoutant l'option :local au bloc #+begin_ai :
#+begin_ai :local
Hello CodeLlama!
#+end_ai
Non, Openai est le plus facile à configurer (vous n'avez besoin que d'une clé API) mais vous pouvez également utiliser des modèles locaux. Voir comment utiliser la diffusion stable et les LLM locaux avec oobabooga / génération de texte-webui ci-dessus. Claude et perplexité anthropiques. Sont également soutenues. Veuillez ouvrir un problème ou un PR pour d'autres services que vous souhaitez voir pris en charge. Je peux être lent à répondre, mais j'ajouterai un soutien s'il y a suffisamment d'intérêt.
Le package GPTEL fournit une interface alternative à l'API Openai Chatgpt: https://github.com/karthink/gptel
Si vous trouvez ce projet utile, veuillez envisager de parrainer. Merci!
Remarque: Currenly L'implémentation de la variation de l'image nécessite une boucle de ligne de commande à installer. La raison en est que l'API OpenAI s'attend à ce que les demandes de données multipart / formulaires et que l' url-retrieve intégrée EMAC ne le soutienne pas (au moins je n'ai pas compris comment). Le changement à request.el pourrait être une meilleure alternative. Si vous êtes intéressé à contribuer, les PR sont les bienvenus! ↩


