org ai
1.0.0
Modo menor para o modo de organização EMACS que fornece acesso a modelos de IA generativos. Atualmente suportado são
Dentro de um buffer de modo de organização você pode
Nota: Para usar a API do OpenAI, você precisará de uma conta OpenAI e precisará obter um token da API. Até onde eu sei, os limites atuais de uso para a camada livre levam você muito longe.
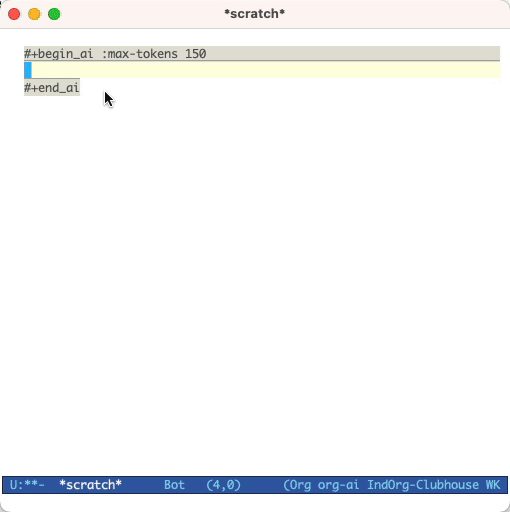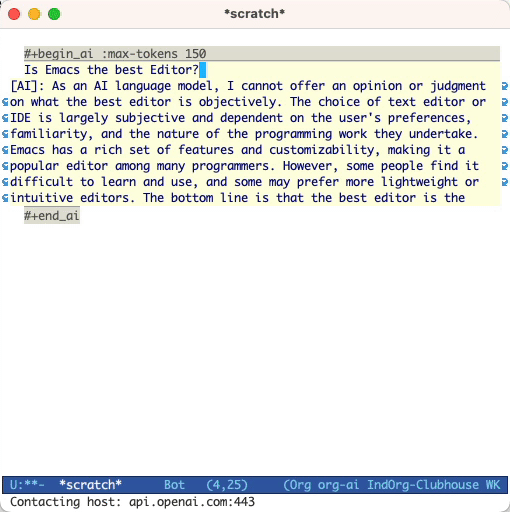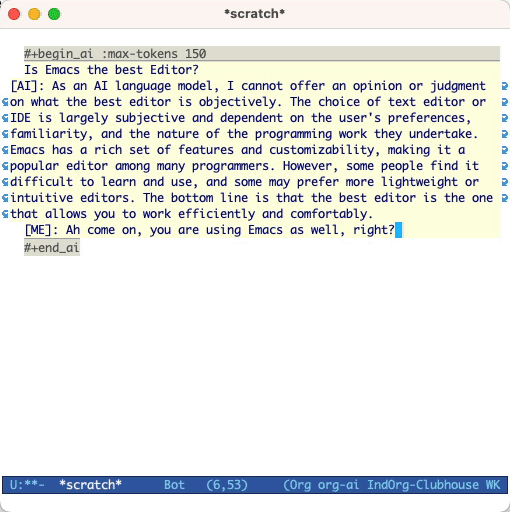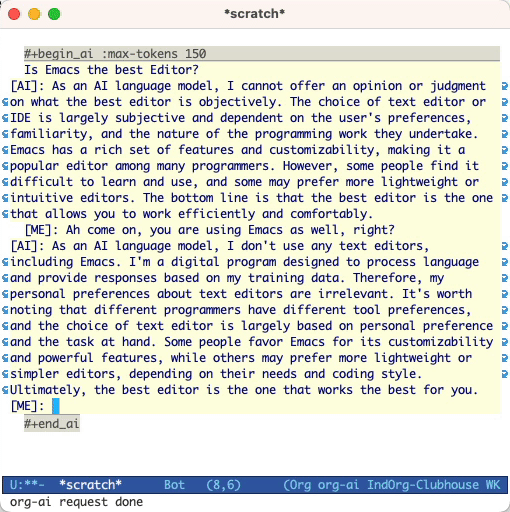
#+begin_ai...#+end_ai BLOCOS ESPECIAIS #+begin_ai
Is Emacs the greatest editor?
#+end_ai
Você pode continuar digitando e pressionando Cc Cc para criar uma conversa. Cg interromperá uma solicitação em execução.
Use a palavra -chave :image para gerar uma imagem. Isso usa Dall · E-3 por padrão.
#+begin_ai :image :size 1024x1024
Hyper realistic sci-fi rendering of super complicated technical machine.
#+end_ai
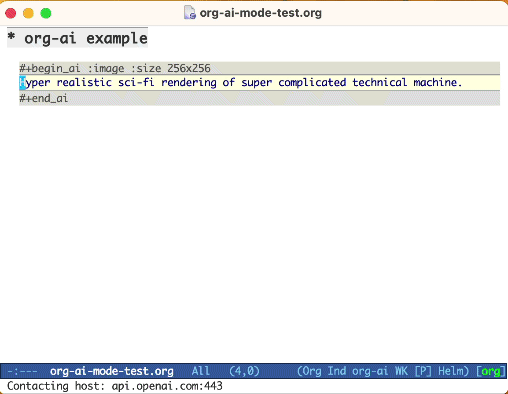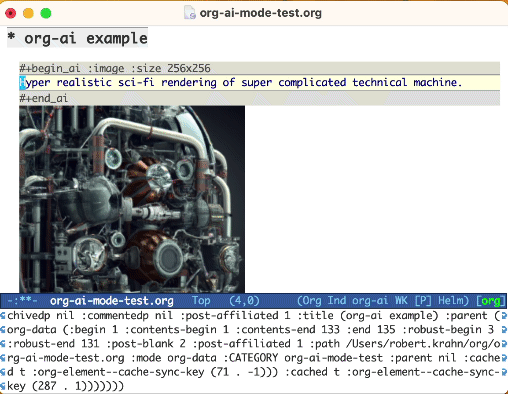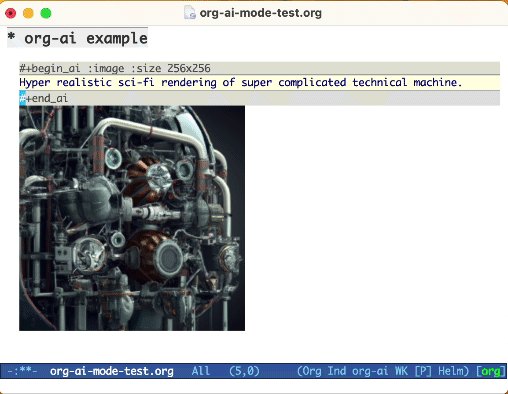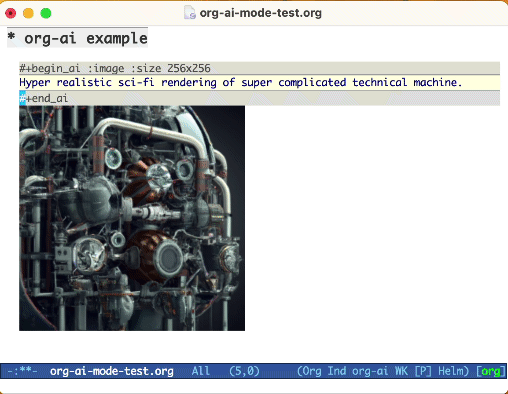
Você pode usar as seguintes palavras -chave para controlar a geração de imagens:
:size <width>x<height> - O tamanho da imagem a gerar (Padrão: 1024x1024):model <model> -O modelo a ser usado (padrão: "dall-e-3" ):quality <quality> - A qualidade da imagem (opções: hd , standard ):style <style> - o estilo a usar (opções: vivid , natural )(Para obter mais informações sobre essas configurações, consulte esta postagem no blog Openai.
Você pode personalizar os padrões para essas variáveis com customize-variable ou definindo-as em sua configuração:
( setq org-ai-image-model " dall-e-3 " )
( setq org-ai-image-default-size " 1792x1024 " )
( setq org-ai-image-default-count 2 )
( setq org-ai-image-default-style 'vivid )
( setq org-ai-image-default-quality 'hd )
( setq org-ai-image-directory ( expand-file-name " org-ai-images/ " org-directory))
#+begin_ai...#+end_ai BLOCOS ESPECIAISSemelhante ao Org-Babel, esses blocos demarcaram a entrada (e para o ChatGPT também a saída) para o modelo de IA. Você pode usá -lo para chat da IA, conclusão de texto e texto -> geração de imagens. Veja as opções abaixo para obter mais informações.
Crie um bloco como
#+begin_ai
Is Emacs the greatest editor?
#+end_ai
e pressione Cc Cc . A entrada de bate -papo aparecerá embutida e, assim que a resposta estiver concluída, você poderá inserir sua resposta e assim por diante. Veja a demonstração abaixo. Você pode pressionar Cg enquanto a solicitação de IA estiver em execução para cancelá -la.
Você também pode modificar o prompt do sistema e outros parâmetros usados. O prompt do sistema é injetado antes da entrada do usuário e "primos" o modelo a responder em um determinado estilo. Por exemplo, você pode fazer:
#+begin_ai :max-tokens 250
[SYS]: Act as if you are a powerful medival king.
[ME]: What will you eat today?
#+end_ai
Isso resultará em uma carga útil da API como
{
"messages" : [
{
"role" : " system " ,
"content" : " Act as if you are a powerful medival king. "
},
{
"role" : " user " ,
"content" : " What will you eat today? "
}
],
"model" : " gpt-4o-mini " ,
"stream" : true ,
"max_tokens" : 250 ,
"temperature" : 1.2
}Para algumas idéias imediatas, veja, por exemplo, incríveis solicitações de chatgpt.
Ao gerar imagens usando o sinalizador :image , as imagens aparecerão embaixo do bloco AI em linha. As imagens serão armazenadas (juntamente com o seu prompt) dentro do org-ai-image-directory que padronizam para ~/org/org-ai-images/ .
Você também pode usar a entrada de fala para transcrever a entrada. Pressione Cc r para org-ai-talk-capture-in-org para começar a gravar. Observe que isso exigirá que você configure o reconhecimento de fala (veja abaixo). A saída da fala pode ser ativada com org-ai-talk-output-enable .
Dentro de um #+begin_ai...#+end_ai você pode modificar e selecionar as partes do bate -papo com estes comandos:
Cc <backspace> ( org-ai-kill-region-at-point ) para remover a parte do bate-papo em Point.org-ai-mark-region-at-point marcará a região no ponto.org-ai-mark-last-region marcará a última parte do bate-papo. Para aplicar a sintaxe destacada aos seus blocos #+begin_ai ... Basta adicionar um nome de modo principal de idioma após _ai . Por exemplo, #+begin_ai markdown . Para o Markdown, em particular, para destacar corretamente o código em backsticks, você pode definir (setq markdown-fontify-code-blocks-natively t) . Certifique-se de que você também tenha o pacote de modo de marcação instalado. Obrigado @tavisrudd por este truque!
Esse comportamento é ativado por padrão para que a interação seja mais semelhante a um bate -papo. Pode ser irritante quando a saída longa estiver presente e o buffer rolam enquanto você está lendo. Então você pode desativar isso com:
( setq org-ai-jump-to-end-of-block nil ) Set (setq org-ai-auto-fill t) para "preencher" (embrulhar automaticamente as linhas de acordo com a fill-column ) o texto inserido. Basicamente, como auto-fill-mode mas para a IA.
O bloqueio #+begin_ai...#+end_ai pode tomar as seguintes opções.
Por padrão, o conteúdo dos blocos de IA é interpretado como mensagens para o chatgpt. Texto a seguir [ME]: está associado ao usuário, o texto seguindo [AI]: está associado como a resposta do modelo. Opcionalmente, você pode iniciar o bloco com uma entrada [SYS]: <behavior> para iniciar o modelo (consulte org-ai-default-chat-system-prompt abaixo).
:max-tokens number - Número de tokens máximos para gerar (padrão: nil, use o padrão do OpenAi):temperature number - temperatura do modelo (Padrão: 1):top-p number - top_p do modelo (padrão: 1):frequency-penalty number - Penalidade de frequência do modelo (Padrão: 0):presence-penalty - Penalidade de presença do modelo (Padrão: 0):sys-everywhere - repita o prompt do sistema para cada mensagem do usuário (padrão: nil) Se você tiver muitos tópicos diferentes de conversa sobre o mesmo tópico e configurações (prompt do sistema, temperatura etc.) e não deseja repetir todas as opções, você pode definir propriedades de escopo de arquivos org ou criar um cabeçalho de organização com a propriedade A gaveta, de modo que todos #+begin_ai...#+end_ai blocos sob esse título herdarão as configurações.
Exemplos:
* Emacs (multiple conversations re emacs continue in this subtree)
:PROPERTIES:
:SYS: You are a emacs expert. You can help me by answering my questions. You can also ask me questions to clarify my intention.
:temperature: 0.5
:model: gpt-4o-mini
:END:
** Web programming via elisp
#+begin_ai
How to call a REST API and parse its JSON response?
#+end_ai
** Other emacs tasks
#+begin_ai...#+end_ai
* Python (multiple conversations re python continue in this subtree)
:PROPERTIES:
:SYS: You are a python programmer. Respond to the task with detailed step by step instructions and code.
:temperature: 0.1
:model: gpt-4
:END:
** Learning QUIC
#+begin_ai
How to setup a webserver with http3 support?
#+end_ai
** Other python tasks
#+begin_ai...#+end_ai
As seguintes variáveis personalizadas podem ser usadas para configurar o bate -papo:
org-ai-default-chat-model (Padrão: "gpt-4o-mini" )org-ai-default-max-tokens quanto tempo deve levar a resposta. Atualmente, não pode exceder 4096. Se esse valor for muito pequeno, uma resposta poderá ser cortada (padrão: NIL)org-ai-default-chat-system-prompt como "preparar" o modelo. Este é um prompt que é injetado antes da entrada do usuário. (Padrão: "You are a helpful assistant inside Emacs." )org-ai-default-inject-sys-prompt-for-all-messages Wether para repetir o prompt do sistema para cada mensagem do usuário. Às vezes, o modelo "esquece" como foi preparado. Isso pode ajudar a lembrá -lo. (Padrão: nil ) Quando você adiciona uma opção :image ao bloco AI, o prompt será usado para geração de imagens.
:image - gerar uma imagem em vez de texto:size - Tamanho da imagem a gerar (Padrão: 256x256, pode ser 512x512 ou 1024x1024):n - o número de imagens a serem geradas (padrão: 1)As seguintes variáveis personalizadas podem ser usadas para configurar a geração de imagens:
org-ai-image-directory -onde armazenar as imagens geradas (padrão: ~/org/org-ai-images/ ) Semelhante a Dall-e, mas use
#+begin_ai :sd-image
<PROMPT>
#+end_ai
Você pode executar o img2Img rotulando sua imagem de modo de organização com #+nome e referenciando-o com: imagem-ref do seu bloco org-ai.
#+begin_ai :sd-image :image-ref label1
forest, Gogh style
#+end_ai
O MX Org-AI-SD-Clip adivinha o prompt da imagem anterior no modo de organização pelo interrogador do clipe e o salva no anel de matança.
MX Org-AI-SD-Deepdanbooru adivinha o prompt da imagem anterior no modo de organização pelo interrogador Deepdanbooru e o salva no anel de matança.
Para solicitar conclusões de um modelo local servido com oobabooga/geração de texto-webui, siga as etapas de configuração descritas abaixo
Em seguida, inicie um servidor de API:
cd ~ /.emacs.d/org-ai/text-generation-webui
conda activate org-ai
python server.py --api --model SOME-MODEL Quando você adiciona uma chave :local a um bloco Org-AI e solicita as conclusões do Cc Cc , o bloco será enviado ao servidor API local em vez da API do OpenAI. Por exemplo:
#+begin_ai :local
...
#+end_ai
Isso enviará uma solicitação para org-ai-oobabooga-websocket-url e transmitirá a resposta para o buffer org.
Os modelos de conclusão mais antigos também podem ser solicitados adicionando a opção :completion ao bloco AI.
:completion - Em vez de usar o modelo ChatGPT, use o modelo de conclusão:model - Qual modelo usar, consulte https://platform.openai.com/docs/models para uma lista de modelosPara o significado detalhado desses parâmetros, consulte a documentação da API OpenAI.
As seguintes variáveis personalizadas podem ser usadas para configurar a geração de texto:
org-ai-default-completion-model (Padrão: "text-davinci-003" ) Você também pode usar uma imagem existente como entrada para gerar imagens de aparência mais semelhante. O comando org-ai-image-variation solicitará um caminho de arquivo para uma imagem, um tamanho e uma contagem e, em seguida, gerará tantas imagens e inserirá links para eles dentro do buffer atual org-mode . As imagens serão armazenadas dentro do org-ai-image-directory . Veja a demonstração abaixo.
Para mais informações, consulte a documentação do OpenAI. A imagem de entrada precisa ser quadrada e seu tamanho precisa ser menor que 4 MB. E você precisa atualmente o CLL disponível como uma ferramenta de linha de comando 1 .
org-ai pode ser usado fora dos buffers org-mode também. Quando você habilita org-ai-global-mode , o prefixo Cc Ma estará vinculado a vários comandos:
| comando | Keybinding | descrição |
|---|---|---|
org-ai-on-region | Cc Ma r | Faça uma pergunta sobre o texto selecionado ou diga à IA para fazer algo com ele. A resposta será aberta em um buffer de modo de organização para que você possa continuar a conversa. Definir a variável org-ai-on-region-file (por exemplo (setq org-ai-on-region-file (expand-file-name "org-ai-on-region.org" org-directory)) ) Associará um arquivo com esse buffer. |
org-ai-summarize | Cc Ma s | Resuma o texto selecionado. |
org-ai-refactor-code | Cc Ma c | Diga à IA Como alterar o código selecionado, um buffer Diff aparecerá com as alterações. |
org-ai-on-project | Cc Ma p | Execute instruções e modifique / refactor vários arquivos de uma só vez. Usará o projétil, se disponível, volta ao diretório atual, se não. |
org-ai-prompt | Cc Ma P | Solicite um texto ao usuário e imprima a resposta da IA no buffer atual. |
org-ai-switch-chat-model | Cc Ma m | Altere interativamente org-ai-default-chat-model |
org-ai-open-account-usage-page | Cc Ma $ | Abre https://platform.openai.com/account/usage para ver quanto dinheiro você queimou. |
org-ai-open-request-buffer | Cc Ma ! | Abre o buffer de solicitação url . Se algo não funcionar, pode ser útil dar uma olhada. |
org-ai-talk-input-toggle | Cc Ma t | Geralmente, ativar a entrada de fala para os diferentes comandos de prompt. |
org-ai-talk-output-toggle | Cc Ma T | Geralmente ativam a saída da fala. |
O uso do buffer org-ai-on-Project permite executar comandos em arquivos em um projeto, alternativamente também apenas em texto selecionado nesses arquivos. Você pode, por exemplo, selecionar o ReadMe de um projeto e perguntar "O que se trata?" ou tenha o código explicado a você. Você também pode solicitar alterações de código, que gerarão um diferencial. Se você sabe algum tipo que pensa que apenas o código com o Copilot habilitado pode fazer isso, aponte -os aqui.
A execução do comando org-ai-on-project abrirá um buffer separado que permite selecionar escolher vários arquivos (e opcionalmente selecione uma sub-região dentro de um arquivo) e execute um prompt nele.
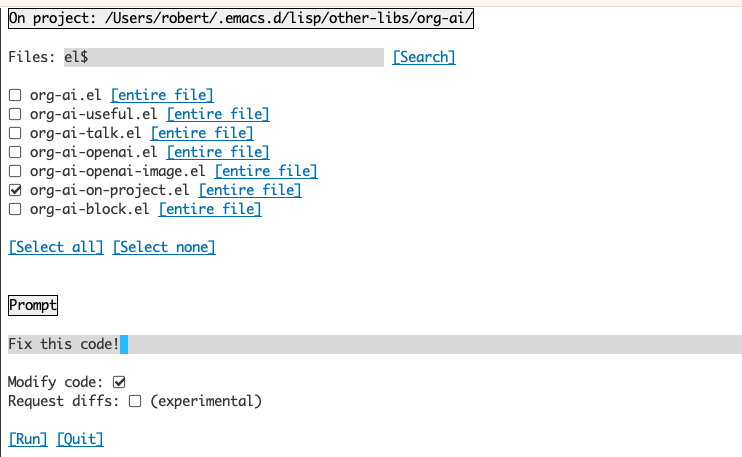
Se você desativar "código de modificar", o efeito será semelhante à execução org-ai-on-region apenas que o conteúdo do arquivo aparece no prompt.
Com o "código modificado" ativado, você pode solicitar à IA que modifique ou refator o código. Por padrão ("DIFFS DESPOLHADO") Desativado, solicitaremos gerar o novo código para todos os arquivos/regiões selecionados e você poderá ver um diff por arquivo e decidir aplicá -lo ou não. Com o "Solicitação Diffs", a IA será solicitada a criar diretamente um diferencial unificado que pode ser aplicado.
Dado um bloco de origem nomeado
#+name: sayhi
#+begin_src shell
echo "Hello there"
#+end_src
Podemos tentar fazer referência ao nome, mas não funciona.
#+begin_ai
[SYS]: You are a mimic. Whenever I say something, repeat back what I say to you. Say exactly what I said, do not add anything.
[ME]: <<sayhi()>>
[AI]: <<sayhi()>>
[ME]:
#+end_ai
Com :noweb yes
#+begin_ai :noweb yes
[SYS]: You are a mimic. Whenever I say something, repeat back what I say to you. Say exactly what I said, do not add anything.
[ME]: <<sayhi()>>
[AI]: Hello there.
[ME]:
#+end_ai
Você também pode desencadear a expansão do Noweb com um org-ai-noweb: yes cabeçalho de cabeça em qualquer lugar nos títulos dos pais (o cabeçalho args tem precedência).
Para ver para que seu documento se expandirá quando enviado para a API, execute org-ai-expand-block .
Este é um hack, mas funciona muito bem.
Crie um bloco
#+name: identity
#+begin_src emacs-lisp :var x="fill me in"
(format "%s" x)
#+end_src
Podemos invocar e deixar os parâmetros Noweb (que suportam o LISP) avaliam como código
#+begin_ai :noweb yes
Tell me some 3, simple ways to improve this dockerfile
<<identity(x=(quelpa-slurp-file "~/code/ibr-api/Dockerfile"))>>
[AI]: 1. Use a more specific version of Python, such as "python:3.9.6-buster" instead of "python:3.9-buster", to ensure compatibility with future updates.
2. Add a cleanup step after installing poetry to remove any unnecessary files or dependencies, thus reducing the size of the final image.
3. Use multi-stage builds to separate the build environment from the production environment, thus reducing the size of the final image and increasing security. For example, the first stage can be used to install dependencies and build the code, while the second stage can contain only the final artifacts and be used for deployment.
[ME]:
#+end_ai
Org-ai está no melpa: https://melpa.org/#/org-ai. Se você adicionou Melpa aos seus arquivos de pacotes com
( require 'package )
( add-to-list 'package-archives '( " melpa " . " http://melpa.org/packages/ " ) t )
( package-initialize )Você pode instalá -lo com:
( use-package org-ai
:ensure t
:commands (org-ai-mode
org-ai-global-mode)
:init
( add-hook 'org-mode-hook # 'org-ai-mode ) ; enable org-ai in org-mode
(org-ai-global-mode) ; installs global keybindings on C-c M-a
:config
( setq org-ai-default-chat-model " gpt-4 " ) ; if you are on the gpt-4 beta:
(org-ai-install-yasnippets)) ; if you are using yasnippet and want `ai` snippets
( straight-use-package
'(org-ai :type git :host github :repo " rksm/org-ai "
:local-repo " org-ai "
:files ( " *.el " " README.md " " snippets " )))Confira este repositório.
git clone
https://github.com/rksm/org-ai Então, se você usar use-package :
( use-package org-ai
:ensure t
:load-path ( lambda () " path/to/org-ai " ))
; ; ...rest as above...
ou apenas com require :
( package-install 'websocket )
( add-to-list 'load-path " path/to/org-ai " )
( require 'org )
( require 'org-ai )
( add-hook 'org-mode-hook # 'org-ai-mode )
(org-ai-global-mode)
( setq org-ai-default-chat-model " gpt-4 " ) ; if you are on the gpt-4 beta:
(org-ai-install-yasnippets) ; if you are using yasnippet and want `ai` snippetsVocê pode definir diretamente seu token da API em sua configuração:
( setq org-ai-openai-api-token " <ENTER YOUR API TOKEN HERE> " )
Como alternativa, org-ai suporta auth-source para recuperar sua chave da API. Você pode armazenar um segredo no formato
machine api.openai.com login org-ai password <your-api-key>
no seu arquivo ~/authinfo.gpg . Se isso estiver presente, o Org-AI usará esse mecanismo para recuperar o token quando uma solicitação for feita. Se você não deseja que org-ai tente recuperar a chave do auth-source , poderá definir org-ai-use-auth-source como nil antes de carregar org-ai .
Você pode mudar para o Azure, personalizando essas variáveis, interativamente com Mx customize-variable ou adicionando-as à sua configuração:
( setq org-ai-service 'azure-openai
org-ai-azure-openai-api-base " https://your-instance.openai.azure.com "
org-ai-azure-openai-deployment " azure-openai-deployment-name "
org-ai-azure-openai-api-version " 2023-07-01-preview " ) Para armazenar as credenciais da API, siga as instruções Authinfo acima, mas use org-ai-azure-openai-api-base como nome da máquina.
Para uma lista de modelos disponíveis, consulte a documentação Perplexity.Ai.
Alterne o serviço padrão em sua configuração:
( setq org-ai-service 'perplexity .ai)
( setq org-ai-default-chat-model " llama-3-sonar-large-32k-online " )ou por bloco:
#+begin_ai :service perplexity.ai :model llama-3-sonar-large-32k-online
[ME]: Tell me fun facts about Emacs.
#+end_ai
Para a autenticação, tenha uma entrada como machine api.perplexity.ai login org-ai password pplx-*** em seu authinfo.gpg ou defina org-ai-openai-api-token .
NOTA: Atualmente, o Perplexity.ai não fornece acesso a referências/links por meio da API, para que os emacs não possam exibir referências. Eles têm um programa beta para isso e espero que isso esteja disponível em breve.
Semelhante ao acima. Por exemplo
#+begin_ai :service anthropic :model claude-3-opus-20240229
[ME]: Tell me fun facts about Emacs.
#+end_ai
Modelos antrópicos estão aqui. Atualmente, existe apenas uma versão da API que é definida via org-ai-anthropic-api-version . Se outra versão sair, você poderá encontrá -los aqui.
Para o token da API, use machine api.anthropic.com login org-ai password sk-ant-*** em seu authinfo.gpg .
Essas etapas de configuração são opcionais. Se você não quiser usar a entrada / saída de fala, pode pular esta seção.
Nota: Minha configuração pessoal para Org-AI pode ser encontrada nesta essência. Ele contém uma configuração de sussurro de trabalho.
Isso foi testado em macOS e Linux. Alguém com um computador Windows, teste isso e deixe -me saber o que precisa ser feito para fazê -lo funcionar (obrigado!).
A entrada do discurso usa sussurro.el e ffmpeg . Você precisa clonar o repo diretamente ou usar reto.el para instalá -lo.
brew install ffmpeg no macOS) ou sudo apt install ffmpeg no linux.git clone https://github.com/natrys/whisper.el path/to/whisper.elAgora você deve ser capaz de carregá -lo dentro do Emacs:
( use-package whisper
:load-path " path/to/whisper.el "
:bind ( " M-s-r " . whisper-run))Agora também carregue:
( use-package greader :ensure )
( require 'whisper )
( require 'org-ai-talk )
; ; macOS speech settings, optional
( setq org-ai-talk-say-words-per-minute 210 )
( setq org-ai-talk-say-voice " Karen " )No macOS, você precisará fazer mais duas coisas:
Você pode usar o ajudante TCCUTIL:
git clone https://github.com/DocSystem/tccutil
cd tccutil
sudo python ./tccutil.py -p /Applications/Emacs.app -e --microphone Quando você agora executa ffmpeg -f avfoundation -i :0 output.mp3 de dentro de um shell do emacs, não deve haver um erro abort trap: 6 .
(Como alternativa ao tccutil.py, veja o método mencionado nesta edição.)
Você pode usar a saída de ffmpeg -f avfoundation -list_devices true -i "" para listar os dispositivos de entrada de áudio e depois dizer a Whisper.el sobre isso: (setq whisper--ffmpeg-input-device ":0") . :0 é o índice de microfone, consulte a saída do comando acima para usar outro.
Eu criei um ajudante do EMACS que permite selecionar o microfone interativamente. Veja esta essência.
Minha configuração completa habilitada para o discurso se parece:
( use-package whisper
:load-path ( lambda () ( expand-file-name " lisp/other-libs/whisper.el " user-emacs-directory))
:config
( setq whisper-model " base "
whisper-language " en "
whisper-translate nil )
( when *is-a-mac*
(rk/select-default-audio-device " Macbook Pro Microphone " )
( when rk/default-audio-device)
( setq whisper--ffmpeg-input-device ( format " : %s " rk/default-audio-device)))) No MacOS, em vez de sussurrar, você também pode usar o ditado de Siri embutido. Para ativar isso, vá para Preferences -> Keyboard -> Dictation , ative -o e configure um atalho. O padrão é Ctrl-Ctrl.
O caminho (Defun Whisper-Check-Install-and Run) é implementado não funciona no Win10 (ver #66).
Uma solução alternativa é instalar o sussurro.cpp e o modelo manualmente e patch:
( defun whisper--check-install-and-run ( buffer status )
(whisper--record-audio)) A saída da fala em sistemas não-MACOS padroniza o uso do pacote Greader, que usa Espeak por baixo para sintetizar a fala. Você precisará instalar o Greader manualmente (por exemplo, via Mx package-install ). A partir desse ponto, deve "apenas trabalhar". Você pode testá-lo selecionando algum texto e chamando Mx org-ai-talk-read-region .
Uma API para difusão estável pode ser hospedada com o projeto estável-difusão-webui. Analise as etapas de instalação da sua plataforma e inicie um servidor API-Only:
cd path/to/stable-diffusion-webui
./webui.sh --nowebui Isso iniciará um servidor em http://127.0.0.1:7861 por padrão. Para usá-lo com org-ai, você precisa definir org-ai-sd-endpoint-base :
( setq org-ai-sd-endpoint-base " http://localhost:7861/sdapi/v1/ " )Se você usar um servidor hospedado em outro lugar, altere esse URL de acordo.
Como a versão 0.4 Org-AI suporta modelos locais servidos com oobabooga/geração de texto-webui. Consulte as instruções de instalação para configurá -lo para o seu sistema.
Aqui está uma apresentação de configuração que foi testada no Ubuntu 22.04. Ele assume que Miniconda ou Anaconda, bem como o Git-LFS a ser instalado.
conda create -n org-ai python=3.10.9
conda activate org-ai
pip3 install torch torchvision torchaudiomkdir -p ~ /.emacs.d/org-ai/
cd ~ /.emacs.d/org-ai/
git clone https://github.com/oobabooga/text-generation-webui
cd text-generation-webui
pip install -r requirements.txt Oobabooga/geração de texto-webui suporta vários modelos de idiomas. Normalmente, você os instalaria no Huggingface. Por exemplo, para instalar o modelo CodeLlama-7b-Instruct :
cd ~ /.emacs.d/org-ai/text-generation-webui/models
git clone [email protected]:codellama/CodeLlama-7b-Instruct-hf cd ~ /.emacs.d/org-ai/text-generation-webui
conda activate org-ai
python server.py --api --model CodeLlama-7b-Instruct-hf Dependendo do seu hardware e do modelo usado, pode ser necessário ajustar os parâmetros do servidor, por exemplo, use --load-in-8bit para reduzir o uso da memória ou --cpu se você não tiver uma GPU adequada.
Agora você deve poder usar o modelo local com Org-AI, adicionando a :local ao bloco #+begin_ai :
#+begin_ai :local
Hello CodeLlama!
#+end_ai
Não, o OpenAI é o mais fácil de configurar (você só precisa de uma chave da API), mas também pode usar modelos locais. Veja como usar a difusão estável e os LLMs locais com oobabooga/geração de texto-webui acima. Claude e perplexidade antrópicos também são suportados. Abra um problema ou PR para outros serviços que você gostaria de ver suportado. Posso demorar a responder, mas adicionarei suporte se houver interesse suficiente.
O pacote GPTEL fornece uma interface alternativa à API do OpenAi ChatGPT: https://github.com/karthink/gptel
Se você achar esse projeto útil, considere patrocinar. Obrigado!
NOTA: Currenly A implementação da variação da imagem requer que um enrolamento da linha de comando seja instalado. A razão para isso é que a API do OpenAI espera solicitações de multipart/dados de formulários e o EMACS embutido url-retrieve não suporta isso (pelo menos eu não descobri como). Mudar para request.el pode ser uma alternativa melhor. Se você estiver interessado em contribuir, os PRs são muito bem -vindos! ↩


